background
ziplist is a data structure developed to save memory. Its essence is a byte array.
ziplist is one of the underlying implementations of list keys and hash keys, and is also used for the implementation of quicklist.
Problem thinking
The bidirectional linked list structure has serious memory waste when the length of the stored data itself is much smaller than the size of the linked list node. In view of this situation, Redis designed ziplist, a memory saving data structure. The following gives the related thinking problems of ziplost to understand the implementation principle and design idea of ziplost.
- Data structure of ziplost
- Ziplost node composition
- Why design a ziplost
- Ziplost related operations
- Data structure of quicklist
- Why design quicklist
- Adding, deleting, modifying and querying quicklist
Data structure of ziplost
Redis does not specifically define a structure to represent ziplost, because ziplost is essentially a spatially continuous byte array.
The zip list contains multiple entries. Each node stores a string value or integer value. Each node is represented by a struct zlentry structure.
The components of ziplost are referenced as follows:
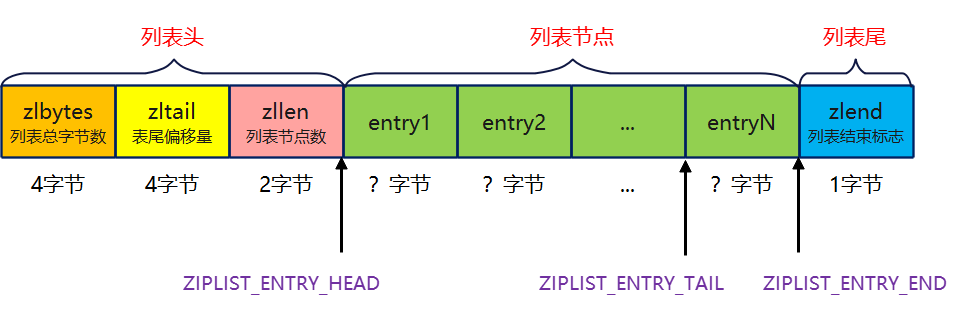
It can be seen that ziplost consists of three parts: column header + list node + list footer. The functions of each component are described as follows:
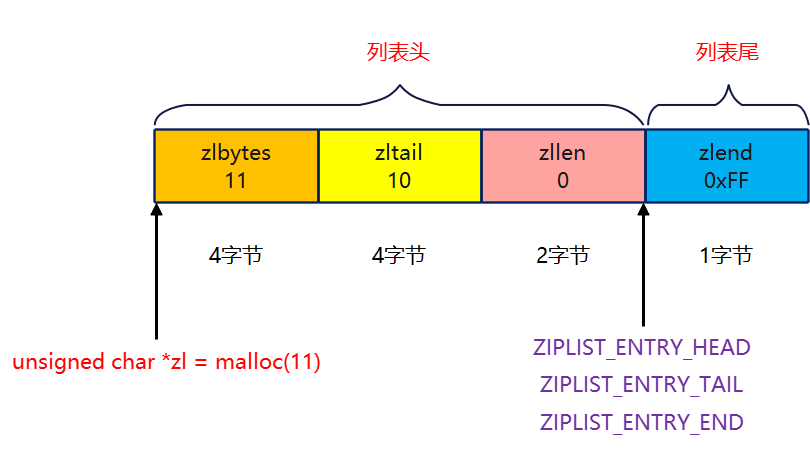
- Zlbytes accounts for 4 bytes, which is used to record the total number of bytes of memory occupied by the whole ziplost. For an empty table, zlbytes is equal to 11. Refer to ziplist new for the source code
#define ZIPLIST_ HEADER_ Size (sizeof (uint32_t) * 2 + sizeof (uint16_t)) / / 8 + 2 = 10 bytes
#define ZIPLIST_ END_ Size (sizeof (uint8_t)) / / 1 byte
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) // zlbytes
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE; // zlbytes = 10 + 1 = 11
unsigned char *zl = zmalloc(bytes); // As you can see, the empty table allocates 11 bytes of space
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
The memory space when the ziplost is empty is shown in the following figure:
- zltail occupies 4 bytes and is used to record the number of bytes between the first address of the tail node and the starting address of the ziplost. This field is designed to quickly locate the footer node address (ZIPLIST_ENTRY_TAIL).
- Zllen occupies 2 bytes and is used to record the total number of list nodes. Note that when zllen is equal to 65535, it means that the length of the list is too large. You must traverse the whole ziplost to get the real length. Refer to ziplist len implementation:
#define UINT16_MAX 65535
unsigned int ziplistLen(unsigned char *zl) {
unsigned int len = 0;
if (intrev16ifbe(ZIPLIST_LENGTH(zl)) < UINT16_MAX) {
len = intrev16ifbe(ZIPLIST_LENGTH(zl)); // When zllen < 65535, the O(1) complexity obtains the length of the ziplost
} else {
unsigned char *p = zl+ZIPLIST_HEADER_SIZE;
while (*p != ZIP_END) { // When zllen = 65535, the O(N) complexity obtains the length of the ziplost
p += zipRawEntryLength(p);
len++;
}
/* Re-store length if small enough */
if (len < UINT16_MAX) ZIPLIST_LENGTH(zl) = intrev16ifbe(len);
}
return len;
}
- zlend takes up 1 byte and is used to mark the end of ziplost. The content is fixed to 0xFF(255 in decimal)
Ziplost node composition
The zip list contains multiple entries. Each node stores a string value or integer value. Each node is represented by a struct zlentry structure.
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
As mentioned earlier, ziplost is essentially a byte array. Redis specifically defines the zlentry structure for easy operation and parses the information of an entry into zlentry. Note that ziplost byte array itself does not store zlentry; Each entry structure of ziplist consists of three parts:
- Previous node length information: previous_entry_length
- Current node code information: encoding
- Current node content: content
Schematic diagram of each component of the ziplost node:

These three components are described below:
1. Previous node length information_ entry_ length
previous_entry_length itself accounts for 1 byte or 5 bytes. It is used to record the length of the previous node. The unit is bytes:
- If the length of the previous node is less than 254 bytes, previous_entry_length only takes up 1 byte and directly saves the length of the previous node.
- If the length of the previous node is greater than or equal to 254 bytes, previous_entry_length takes up 5 bytes, of which the first byte is fixed as 0xFE, and the last 4 bytes save the length of the previous node.
Source code reference ZIP_DECODE_PREVLENSIZE. This macro returns previous according to the length of the previous node_ entry_ Bytes occupied by length:
#define ZIP_BIG_PREVLEN 254
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \
if ((ptr)[0] < ZIP_BIG_PREVLEN) { \
(prevlensize) = 1; \
} else { \
(prevlensize) = 5; \
} \
} while(0)
Q: Why design previous_ entry_ What is the function of the length field?
A: Used to support traversal from the end of the table to the header. For example, we have a pointer p to the starting address of a node, and use p to subtract the previous address of the node_ entry_ Length, you can get the starting address of the previous node.
Access the previous node of the current node of the ziplist. Refer to the implementation of the source ziplistPrev:
/* Return pointer to previous entry in ziplist. */
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p) {
unsigned int prevlensize, prevlen = 0;
if (p[0] == ZIP_END) { // p points to ZIPLIST_ENTRY_END, the previous node is the last node, that is, ZIPLIST_ENTRY_TAIL
p = ZIPLIST_ENTRY_TAIL(zl);
return (p[0] == ZIP_END) ? NULL : p;
} else if (p == ZIPLIST_ENTRY_HEAD(zl)) { // p is the header, indicating that the previous node is NULL
return NULL;
} else {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); // p minus the previous of this node_ entry_ length
assert(prevlen > 0);
return p-prevlen;
}
}
2. encoding information of current node, content of current node
encoding is used to record the actual type (string or integer) and length of the current node content:
- The encoding length can be 1 byte, 2 bytes, or 5 bytes. When the highest two digits of encoding are 00, 01, or 10, it means that the stored value type is string; The highest two digits of encoding are 11, indicating that the stored value type is an integer.
For the encoding length and content type corresponding to each encoding, refer to the following source code:
// ziplist.c
/* Different encoding/length possibilities */
#define ZIP_STR_MASK 0xc0 // 11000000
#define ZIP_INT_MASK 0x30 // 00110000
#define ZIP_ STR_ 06B (0 << 6) // 00bb (length ≤ 63)
#define ZIP_ STR_ 14B (1 << 6) // 01bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
#define ZIP_ STR_ 32B (2 << 6) // 10______ Bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
#define ZIP_ INT_ 16B (0xc0 | 0<<4) // 11000000 16 bit integer
#define ZIP_ INT_ 32B (0xc0 | 1<<4) // 11010000 32-bit integer
#define ZIP_ INT_ 64B (0xc0 | 2<<4) // 11100000 64 bit integer
#define ZIP_ INT_ 24B (0xc0 | 3<<4) // 11110000 24 bit integer
#define ZIP_INT_8B 0xfe // 11111110 8-bit integer
/* 4 bit integer immediate encoding |1111xxxx| with xxxx between
* 0001 and 1101. */
#define ZIP_INT_IMM_MASK 0x0f /* Mask to extract the 4 bits value. To add
one is needed to reconstruct the value. */
#define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */
#define ZIP_INT_IMM_MAX 0xfd /* 11111101 */
#define INT24_MAX 0x7fffff
#define INT24_MIN (-INT24_MAX - 1)
/* Macro to determine if the entry is a string. String entries never start
* with "11" as most significant bits of the first byte. */
#define ZIP_ IS_ STR(enc) (((enc) & ZIP_ STR_ MASK) < ZIP_ STR_ Mask) / / judge whether it is byte array encoding!!!
/* Extract the encoding from the byte pointed by 'ptr' and set it into
* 'encoding' field of the zlentry structure. */
#define ZIP_ENTRY_ENCODING(ptr, encoding) do { \
(encoding) = (ptr[0]); \
if ((encoding) < ZIP_STR_MASK) (encoding) &= ZIP_STR_MASK; \
} while(0)
/* Decode the entry encoding type and data length (string length for strings,
* number of bytes used for the integer for integer entries) encoded in 'ptr'.
* The 'encoding' variable will hold the entry encoding, the 'lensize'
* variable will hold the number of bytes required to encode the entry
* length, and the 'len' variable will hold the entry length. */
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
if ((encoding) < ZIP_STR_MASK) { \
if ((encoding) == ZIP_STR_06B) { \
(lensize) = 1; \
(len) = (ptr)[0] & 0x3f; \
} else if ((encoding) == ZIP_STR_14B) { \
(lensize) = 2; \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \
} else if ((encoding) == ZIP_STR_32B) { \
(lensize) = 5; \
(len) = ((ptr)[1] << 24) | \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
panic("Invalid string encoding 0x%02X", (encoding)); \
} \
} else { \
(lensize) = 1; \
(len) = zipIntSize(encoding); \
} \
} while(0)
Integer encoding:
| encoding | encoding length | content length |
|---|---|---|
| 11111110 (ZIP_INT_8B) | 1 byte | 8-bit integer |
| 11000000 (ZIP_INT_16B) | 1 byte | 16 bit integer |
| 11110000(ZIP_INT_24B) | 1 byte | 24 bit integer |
| 11010000(ZIP_INT_32B) | 1 byte | 32-bit integer |
| 11100000(ZIP_INT_64B) | 1 byte | 64 bit integer |
| 1111xxxx | 1 byte | An integer between 0 and 12. At this time, there is no content part, and the value is stored in the xxxx four bits of encoding |
Byte array encoding:
| encoding | encoding description | encoding length | content length |
|---|---|---|---|
| 00xxxxxx (ZIP_STR_06B) | The last 6 bits represent the length of the byte array | 1 byte | Save a byte array with a length less than or equal to 63 bytes |
| 01xxxxxx xxxxxxxx (ZIP_STR_14B) | The last 14 bits represent the length of the byte array | 2 bytes | Save a byte array with a length greater than 63 and less than or equal to 16383 bytes |
| 10______ xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx (ZIP_STR_32B) | The last 24 bits represent the length of the byte array, and bits 3-8 are left blank | 5 bytes | Save a byte array with a length greater than 16384 and less than 2 ^ 32 - 1 bytes |
Summary: Redis uses different codes according to the type and size of the content stored in the ziplost node, in order to save space to the greatest extent.
Thinking: create a ziplost encoded empty list key, and add two values "hello" and "10086" in turn. What is the length and content of ziplost at this time?
127.0.0.1:6379> info # Redis version must be before 3.2, otherwise the default code of the list key is quicklist, not ziplist! # Server redis_version:3.0.0 127.0.0.1:6379> flushdb 127.0.0.1:6379> rpush key hello 10086 # Add a new list key, and insert two keys "hello" and "10086" successively (integer) 2 127.0.0.1:6379> object encoding key # Confirm that the list key is encoded as ziplist "ziplist"
If you really know the composition of the ziplost node, you don't need to run Redis. You can also get the answer: the ziplost occupies 22 bytes, as shown in the following figure:
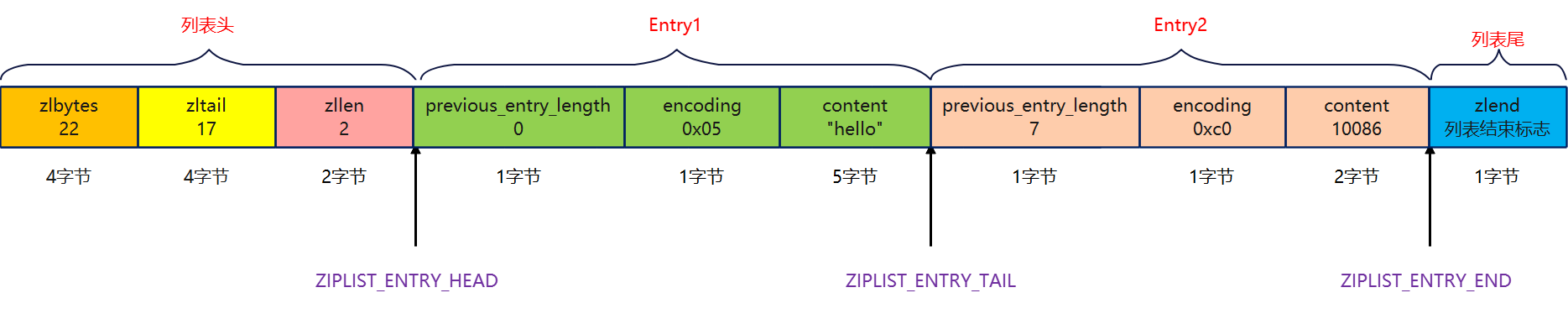
The verification methods and results of GDB are given below. Those interested can refer to:
// 0. Confirm the first address of the ziplost
(gdb) p (sds)server.db[0].dict.ht[0].table[3].key
$1 = (sds) 0x7fc6ac086288 "key" // key
(gdb) p *(robj *)server.db[0].dict.ht[0].table[3].v
$2 = {type = 1, encoding = 5, lru = 13392586, refcount = 1, ptr = 0x7fc6ac035d60} // ptr is the first address of ziplost!
// 1. Print zlbytes, zltail, zllen
(gdb) p *(int *)0x7fc6ac035d60
$3 = 22 // zlbytes = 22
(gdb) p *(int *)0x7fc6ac035d64
$4 = 17 // zltail = 17
(gdb) p *(short *)0x7fc6ac035d68
$5 = 2 // zlen = 2
// 2. Start printing the first node below
(gdb) x/xb 0x7fc6ac035d6a
0x7fc6ac035d6a: 0x00 // previous_entry_length itself occupies 1 byte, and the length is 0
(gdb) x/xb 0x7fc6ac035d6b
0x7fc6ac035d6b: 0x05 // encoding is 00000101, which occupies 1 byte and represents a byte array with a length of 5
(gdb) x/5c 0x7fc6ac035d6c
0x7fc6ac035d6c: 104 'h' 101 'e' 108 'l' 108 'l' 111 'o' // content takes up 5 bytes and stores "hello"
// The total length of the first node is 1 + 1 + 5 = 7 bytes
// 3. Start printing the second node below
(gdb) x/xb 0x7fc6ac035d71
0x7fc6ac035d71: 0x07 // previous_entry_length itself occupies 1 byte, and the length is 7
(gdb) x/xb 0x7fc6ac035d72
0x7fc6ac035d72: 0xc0 // encoding is 11000000, which accounts for 1 byte and represents a 16 bit integer
(gdb) p *(short *) 0x7fc6ac035d73
$6 = 10086 // Content itself occupies 2 bytes, and the stored content is 10086
// 4. Flag zlend, 1 byte
(gdb) x/xb 0x7fc6ac035d75
0x7fc6ac035d75: 0xff
Why design a ziplost
Or consider this list key: "hello" - > "10086"
- If you encode with ziplist, you only need 22 bytes to store.
- If you use linkedlist coding, take the 64 bit environment as an example, the optical linked list node needs 2 * sizeof(listNode) = 48 bytes, which far exceeds the size of the data itself, resulting in serious memory waste.
It can be seen that the design idea of ziplist is to trade time for space in order to save valuable memory resources.
In Redis, ziplist is one of the underlying implementations of list key and hash key, and is also used for the implementation of quicklist.
Ziplost related operations
The API for adding, deleting, modifying and querying the compressed list is as follows:
| API | function | Time complexity |
|---|---|---|
| ziplistPush | Inserts the specified node into the header or footer | Average O(N), chain update scenario is O(N^2) |
| ziplistDelete | Delete specified node | Average O(N), continuous update scenario is O(N^2) |
| ziplistFind | Find the specified node | O(N^2), because the node value may be a string, and the complexity of the string is O(N) |
| ziplistNext | Returns the next node of a given node | O(1) |
| ziplistPrev | Returns the previous node of a given node | O(1) |
Find the specified node
The source code refers to ziplistFind. The time complexity is O(N^2), because the node value may be a string, and the string comparison complexity is O(N)
// Function: find the node with the same node value as vstr in ziplost and return it
// skip indicates the number of nodes skipped
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0;
unsigned char vencoding = 0;
long long vll = 0;
while (p[0] != ZIP_END) { // If you don't reach the end of the list, you'll go through the loop all the time!
unsigned int prevlensize, encoding, lensize, len;
unsigned char *q;
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
q = p + prevlensize + lensize; // At this time, q points to the content of node p
if (skipcnt == 0) {
/* Compare current entry with specified entry */
if (ZIP_IS_STR(encoding)) { // If it is a string, memcmp compares whether it is equal, complexity O(N)
if (len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
} else {
/* Find out if the searched field can be encoded. Note that
* we do it only the first time, once done vencoding is set
* to non-zero and vll is set to the integer value. */
// For the incoming vstr, the decoding action only needs to be done once, and vencoding is equivalent to a flag
if (vencoding == 0) {
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
/* If the entry can't be encoded we set it to
* UCHAR_MAX so that we don't retry again the next
* time. */
vencoding = UCHAR_MAX;
}
/* Must be non-zero by now */
assert(vencoding);
}
/* Compare current entry with specified entry, do it only
* if vencoding != UCHAR_MAX because if there is no encoding
* possible for the field it can't be a valid integer. */
// If the decoding is successful, compare whether the integer values are equal
if (vencoding != UCHAR_MAX) {
long long ll = zipLoadInteger(q, encoding);
if (ll == vll) {
return p;
}
}
}
/* Reset skip count */
skipcnt = skip;
} else {
/* Skip entry */
skipcnt--;
}
/* Move to next entry */
// q points to content, and Len is the length of content, so q + len is the first address of the next node!!
p = q + len;
}
return NULL;
}
Chain update problem
As mentioned earlier, the previous of each node in the zip list_ entry_ Length records the length of the previous node. Consider the scenario of inserting a node in the header:
If the length of all nodes in the list is before 250-253 bytes, and the inserted node is greater than or equal to 254 bytes, the previous of all nodes will be caused_ entry_ The length must be expanded from 1 byte to 5 bytes, that is, a chain update is triggered.
The following example illustrates this problem: given a ziplost with a length of 3 and a size of 253 bytes for each node, insert a node with a size of 300 bytes into the header.
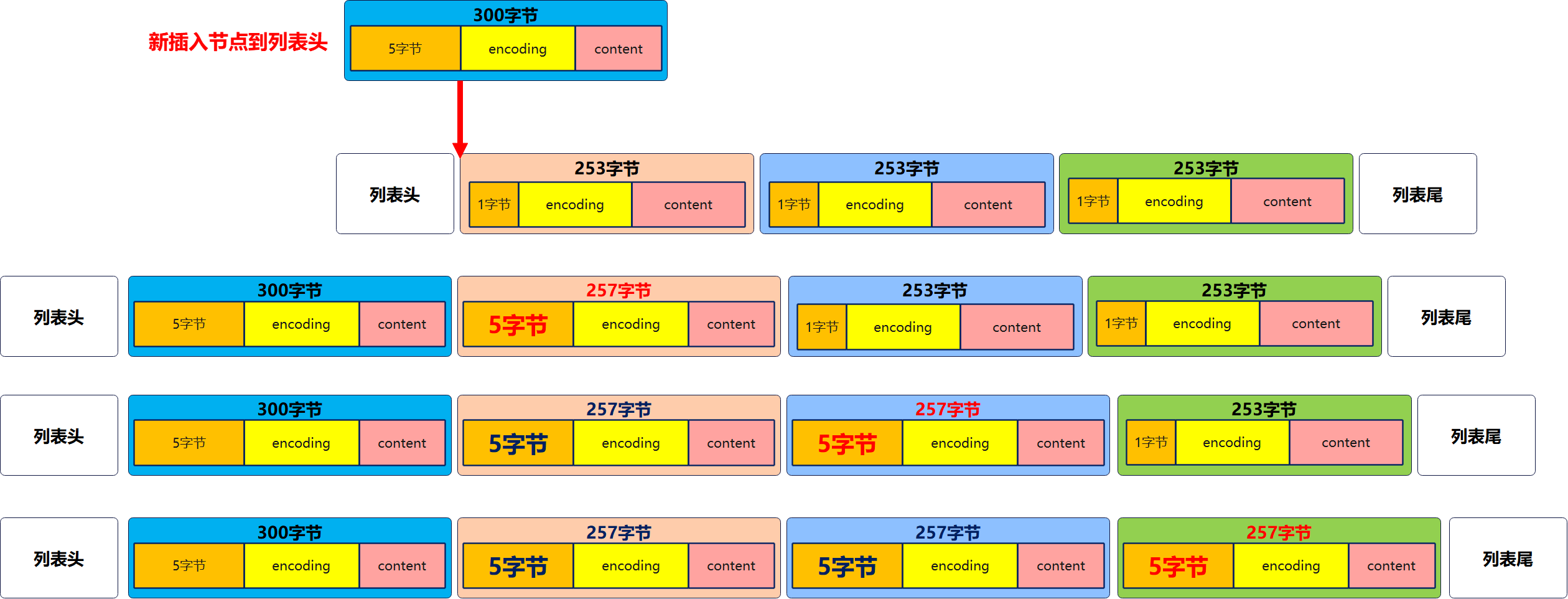
Note: in addition to adding a node will trigger a chain update, deleting a node may also trigger a chain update, which will not be repeated here.
Thinking question: since the worst complexity of chain update is O(n^2), why does Redis still use ziplost?
- Because the triggering conditions of chain update are harsh, it can only be triggered if there are multiple nodes with continuous length of 250-253.
- ziplist is only used in scenarios with a small number of nodes and small data. Even if continuous updates occur, the number of nodes that need to be updated is small, and there will be no performance problems.
reference material
[1] Redis design and implementation Chapter 7 compressed list
[2] [Redis source code analysis - basic data - ziplist (compressed list)](