summary
The dict dictionary in Redis can be understood as a hash linked list of an upgraded version of the mapping relationship between key and value. The emergence of dict dictionary is to solve the search problem in the algorithm. In the actual development, the search mainly makes two structures: the tree using Map structure and hash table. The advantage of using hash table is that the lookup performance can reach O(1) without hash collision, and its internal implementation is relatively simple. Dict dictionary uses several classical algorithms for reference to realize hash key calculation. Dict dictionary adopts the zipper method to solve conflicts when conflicts occur. It maintains two hash tables internally. When the loading factor (the ratio between the number of nodes and the size of the dictionary is close to 1:1, and the ratio between the number of used nodes and the size of the dictionary exceeds 5), incremental re hashing will occur, migrate the data of Table 1 to table 2, and point table 1 to the address of Table 2 after migration.
In order to support lazy deletion, Antirez in version 3.0 executes rehash in the main thread, but this will make the function implementation cumbersome. Each addition, deletion, modification and query must be equipped with a rehash, which will also lead to excessive CPU resources and even block the main thread. In the latest version, Antirez uses the best scheme - asynchronous thread to free memory without adapting to each data structure A set of progressive release strategies.
structural morphology
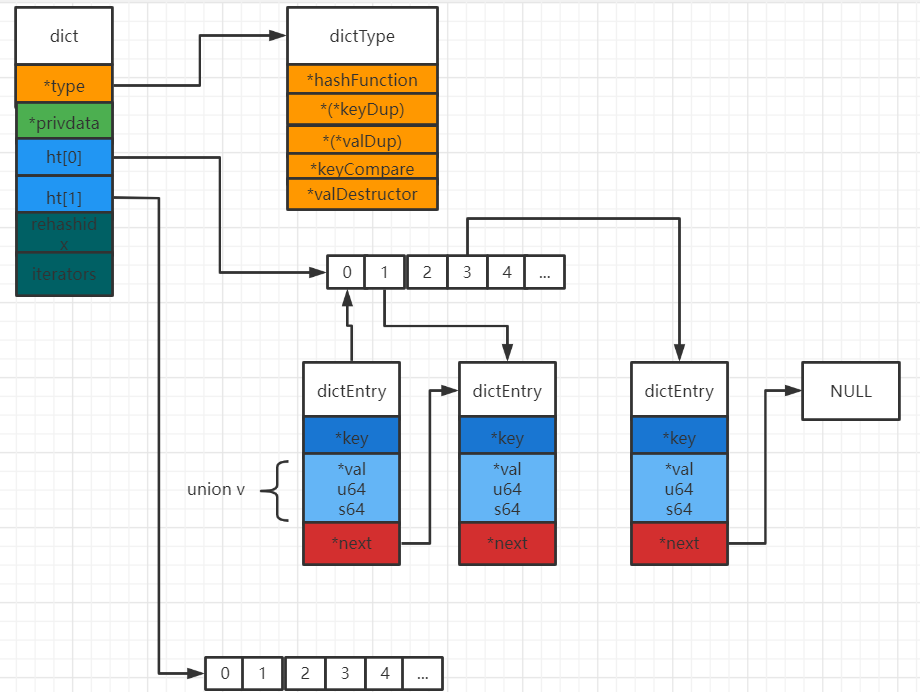
It can be seen that dict dictionary implements many nested structures. In dict structure, dictType is the pointer function of dictionary, and some definitions of node universal operations are included in it; privdata is the attribute that saves the optional parameters that need to be passed to those type specific functions; dictht is the Hash table, which has two Hash tables, and table 1 is the source table. When certain conditions are met, the data will migrate Table 1 To table 2; the rehashidx attribute is used to determine whether data migration is currently in progress; iterators indicates the number of iterators currently being traversed. In the dictht structure, * * table is an array, each element of which is of type dictEntry, which contains k and v key value pairs and the next pointer of the next node. Value is a union union, which is in memory and has an address Value can store three types of data, namely, string of void type, uint64_t (typedef unsigned long type defined in c99 specification), int64_tc (typedef signed long type defined in 99 specification).
typedef struct dictEntry {
// key
void *key;
// value
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// Point to the next hash table node to form a linked list
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
// Function to calculate hash value
unsigned int (*hashFunction)(const void *key);
// Copy key function
void *(*keyDup)(void *privdata, const void *key);
// Functions that copy values
void *(*valDup)(void *privdata, const void *obj);
// Function of comparison key
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// Function to destroy key
void (*keyDestructor)(void *privdata, void *key);
// Function to destroy values
void (*valDestructor)(void *privdata, void *obj);
} dictType;
typedef struct dictht {
// Hash table array
dictEntry **table;
// Hash table size
unsigned long size;
// The hash table size mask is used to calculate the index value. If the current hash table size is 16, its mask is the binary value 1111
// Always equal to size - 1
unsigned long sizemask;
// The number of existing nodes in the hash table
unsigned long used;
} dictht;
typedef struct dict {
// Type specific function
dictType *type;
// Private data
void *privdata;
// Hashtable
dictht ht[2];
// rehash index
// When rehash is not in progress, the value is - 1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// Number of security iterators currently running
int iterators; /* number of iterators currently running */
} dict;
Memory map
This figure shows the memory structure without rehash
Macro definition
Traversal dictionary callback
This function is a callback function. When traversing the dictionary, this function will be executed every time the key is matched.
typedef void (dictScanFunction)(void *privdata, const dictEntry *de);
Initialization size
The initial size macro of the hash table is defined as 4
#define DICT_HT_INITIAL_SIZE 4
Macro definition function
Macros use do/while(0) to surround the execution logic, because it can ensure that the behavior of macros is always the same, regardless of how many semicolons and braces are used in the calling code
// Releases the value of the given dictionary node
#define dictFreeVal(d, entry) \
if ((d)->type->valDestructor) \
(d)->type->valDestructor((d)->privdata, (entry)->v.val)
// Sets the value of the given dictionary node
#define dictSetVal(d, entry, _val_) do { \
if ((d)->type->valDup) \
entry->v.val = (d)->type->valDup((d)->privdata, _val_); \
else \
entry->v.val = (_val_); \
} while(0)
// Sets a signed integer to the value of the node
#define dictSetSignedIntegerVal(entry, _val_) \
do { entry->v.s64 = _val_; } while(0)
// Sets an unsigned integer to the value of the node
#define dictSetUnsignedIntegerVal(entry, _val_) \
do { entry->v.u64 = _val_; } while(0)
// Releases the key for the given dictionary node
#define dictFreeKey(d, entry) \
if ((d)->type->keyDestructor) \
(d)->type->keyDestructor((d)->privdata, (entry)->key)
// Sets the key for the given dictionary node
#define dictSetKey(d, entry, _key_) do { \
if ((d)->type->keyDup) \
entry->key = (d)->type->keyDup((d)->privdata, _key_); \
else \
entry->key = (_key_); \
} while(0)
// Compare two keys
#define dictCompareKeys(d, key1, key2) \
(((d)->type->keyCompare) ? \
(d)->type->keyCompare((d)->privdata, key1, key2) : \
(key1) == (key2))
// Calculates the hash value for the given key
#define dictHashKey(d, key) (d)->type->hashFunction(key)
// Returns the key to get the given node
#define dictGetKey(he) ((he)->key)
// Returns the value of the given node
#define dictGetVal(he) ((he)->v.val)
// Returns the signed integer value that gets the given node
#define dictGetSignedIntegerVal(he) ((he)->v.s64)
// Returns an unsigned integer value for a given node
#define dictGetUnsignedIntegerVal(he) ((he)->v.u64)
// Returns the size of the given dictionary
#define dictSlots(d) ((d)->ht[0].size+(d)->ht[1].size)
// Returns the number of existing nodes in the dictionary
#define dictSize(d) ((d)->ht[0].used+(d)->ht[1].used)
// Check whether the dictionary is rehash
#define dictIsRehashing(ht) ((ht)->rehashidx != -1)
Hash table type
Use the keyword extern to make an "external variable declaration" for this variable. If the marked storage space is loaded during execution and initialized to 0, the external variable can be used legally from the "Declaration". These three global variables are used by Redis when building object storage from external files
extern dictType dictTypeHeapStringCopyKey; extern dictType dictTypeHeapStrings; extern dictType dictTypeHeapStringCopyKeyValue;
Method implementation
global variable
dict_can_resize is used to determine whether a rehash is currently being performed. Rehash generally occurs when Redis uses child processes to save. This can effectively use the copy on write mechanism. If the ratio between the number of used nodes and the dictionary size is greater than 5, rehash will be (forced) in any case.
// An identifier indicating whether the dictionary enables rehash static int dict_can_resize = 1; // Ratio of forced rehash static unsigned int dict_force_resize_ratio = 5;
Hash algorithm
Hash algorithm is widely used in academic and application circles. The idea of the algorithm seems ordinary, but it realizes very magical functions. This paper only describes the application process of dict in detail. For the specific implementation of the algorithm, please see the relevant papers.
dictIntHashFunction Thomas Wang's algorithm
Thomas Wang's algorithm is used for reference in dict.c file. It is the implementation method for calculating the Key of dict. I found that it is described as follows: the integer Hash algorithm uses Thomas Wang's 32 Bit / 64 Bit Mix Function, which is a Hash method based on displacement operation. The shift based Hash uses the Key value for shift operation. It is usually combined with shift left And right shift, the results of each shift process are accumulated, and the final shift result is the final result. The advantage of this method is to avoid multiplication, so as to improve the performance of Hash function itself.
unsigned int dictIntHashFunction(unsigned int key)
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}
dictGenHashFunction MurmurHash2, by Austin Appleby algorithm
This algorithm makes some assumptions about the current machine behavior: it can read a 4-byte value from any address without crashing; sizeof(int) == 4. It has two limitations: it will not work incrementally; in little endian (low order bytes are placed at the low address end of memory, high order bytes are placed at the high address end of memory) and big endian (the low order of data is stored in the high address of memory, while the high order of data is stored in the low address of memory) the same results will not be generated on the machine.
static uint32_t dict_hash_function_seed = 5381;
void dictSetHashFunctionSeed(uint32_t seed) {
dict_hash_function_seed = seed;
}
uint32_t dictGetHashFunctionSeed(void) {
return dict_hash_function_seed;
}
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
dictGenCaseHashFunction is based on djb hash
Case insensitive hash function based on djb hash
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) {
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}
_dictReset initializes the Hash table
_dictReset is a global function that resets (or initializes) the attribute values of a given hash table. It can also be used when dict is called externally.
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
Dictcreate _dictinitcreate dictionary
Initialize a dictionary and create a space with zmalloc. You can see that instead of using sizeof to calculate dict, it directly calls * d to calculate the size of the structure_ The dictInit function first initializes the properties of two Hash tables, and then initializes the dictType function. privDataPtr is an optional parameter to be passed to a specific function in dictType. Set the status of rehash to stop and the number of traversers to 0.
Return value: DICT_OK=0; DICT_ERR=1.
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
// Initialize the attribute values of two hash tables
// However, memory is not allocated to the hash table array for the time being
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
// Set type specific functions
d->type = type;
// Set private data
d->privdata = privDataPtr;
// Set hash table rehash status
d->rehashidx = -1;
// Sets the number of safe iterators for the dictionary
d->iterators = 0;
return DICT_OK;
}
dictResize reduces dictionary space
If Dict_ can_ If resize is false or D - > rehashidx = - 1, the dictionary cannot be reduced, and the function will exit directly. If the number of nodes used by the dictionary is less than the minimum dictionary space (DICT_HT_INITIAL_SIZE=4), the minimum will be set to 4.
int dictResize(dict *d)
{
int minimal;
// Cannot be called when rehash is closed or rehash is in progress
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
// Calculate the minimum number of nodes required to make the ratio close to 1:1
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
// Resize dictionary
// T = O(N)
return dictExpand(d, minimal);
}
dictExpand creates a new hash table
_ dictNextPower calculates the first N-th power greater than or equal to size 2 to make the size of the new Hash table. When the length of the node used in the re Hash or Hash table 1 is greater than size, the function will exit incorrectly. If Hash table 0 is empty, give the address of the newly created Hash table to Hash table 0. If it is not empty, it means that the re Hash ends at this time, and give the address of the newly created Hash table to Hash table 1.
int dictExpand(dict *d, unsigned long size)
{
// New hash table
dictht n; /* the new hash table */
// Calculate the size of the hash table according to the size parameter
// T = O(1)
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
// Cannot be performed while the dictionary is rehash
// The value of size cannot be less than the currently used node of hash table No. 0
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
// Allocate space for the hash table and point all pointers to NULL
n.size = realsize;
n.sizemask = realsize-1;
// T = O(N)
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
// If hash table No. 0 is empty, this is an initialization:
// The program assigns the new hash table to the pointer of hash table No. 0, and then the dictionary can start processing key value pairs.
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
// If the hash table No. 0 is not empty, this is a rehash:
// The program sets the new hash table to hash table No. 1,
// And open the rehash ID of the dictionary, so that the program can start rehash the dictionary
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
dictRehash rehash (table 0 migrated to table 1)
Before re executing the hash, first modify the status of D - > rehashidx to being executed. N can be understood as the number of steps (execution times), de is the hash node currently traversed, and nextde is the next hash node. Its implementation does not use recursion, because Redis generally uses sub threads to execute this function, and new nodes may be added continuously, resulting in stack overflow. used==0 is the boundary of the loop. It indicates the end of the re hash execution. It will release the originally allocated space, give the address of the space of the new table 1 to table 0, and finally reset Table 1 to close the re hash. assert is the assertion processing of C language, which is somewhat similar to the object-oriented manual exception throwing. Rehashidx is used to record the number of traversal nodes during the loop. When the size is greater than rehashidx, the current traversal is out of bounds, and the program is interrupted. Before traversing the linked list, the while loop will find the first node. This is because the hash table is hash. The address obtained by the calculated hash value cannot exist continuously in memory. It may be the 10th and 100th nodes. The dictHashKey function calculates the hash value. The hash value performs bit operation with the sizemask of the node to calculate the index position inserted by the node. Finally, the used usage of each hash table is updated. After the loop is completed, table 0 will be set to NULL and rehashidx will increase by 1. In the next while(n –) loop, two hash tables will be replaced, and finally Table 1 will be reset to exit.
int dictRehash(dict *d, int n) {
// Can only be executed while rehash is in progress
if (!dictIsRehashing(d)) return 0;
// N-step migration
// T = O(N)
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
// If the hash table No. 0 is empty, the rehash execution is completed
// T = O(1)
if (d->ht[0].used == 0) {
// Release hash table No. 0
zfree(d->ht[0].table);
// Set the original hash table No. 1 to the new hash table No. 0
d->ht[0] = d->ht[1];
// Reset old hash table No. 1
_dictReset(&d->ht[1]);
// Turn off rehash ID
d->rehashidx = -1;
// Return 0 to indicate to the caller that rehash has been completed
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
// Make sure rehashidx is not out of bounds
assert(d->ht[0].size > (unsigned)d->rehashidx);
// Skip the empty index in the array and find the next non empty index
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
// The linked list header node that points to the index
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
// Migrate all nodes in the linked list to the new hash table
// T = O(1)
while(de) {
unsigned int h;
// Save pointer to next node
nextde = de->next;
/* Get the index in the new hash table */
// Calculate the hash value of the new hash table and the index position of the node insertion
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// Insert node into new hash table
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
// Update counter
d->ht[0].used--;
d->ht[1].used++;
// Proceed to the next node
de = nextde;
}
// Set the pointer of the hash table index just migrated to null
d->ht[0].table[d->rehashidx] = NULL;
// Update rehash index
d->rehashidx++;
}
return 1;
}
timeInMilliseconds gets the current time
Gets the UNIX timestamp in milliseconds
long long timeInMilliseconds(void) {
struct timeval tv;
gettimeofday(&tv,NULL);
return (((long long)tv.tv_sec)*1000)+(tv.tv_usec/1000);
}
dictRehashMilliseconds performs rehash within a time period
The start variable obtains the current time. Within ms time, the Hash is repeated in 100 steps each time, and finally the execution step is returned.
int dictRehashMilliseconds(dict *d, int ms) {
// Record start time
long long start = timeInMilliseconds();
int rehashes = 0;
// When the hash table No. 0 is empty, the loop is terminated, indicating that rehash execution is completed
while(dictRehash(d,100)) {
rehashes += 100;
// If the time has passed, jump out
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
_ dictRehashStep execute rehash with absolute condition
rehash cannot be performed when the dictionary has a secure iterator, because different iterations and modification operations may confuse the dictionary. It will be called in addition, deletion, modification and query of dict.
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
dictAdd dictAddRaw add node
dictAdd function will call dictAddRaw function to add nodes. If D - > rehashidx is true, rehash will be performed once. In the Hash table, the key is the only existing key. If the key exists, NULL will be returned. If the dictionary is rehash, add the new key to Hash table 1, otherwise add the new key to Hash table 0. Insert the newly created dictEntry into the header of the Hash table, call the macro function dictSetKey and set the key of the node. Finally, return the dictEntry pointer and set val to the node of the Hash table when the pointer is not empty.
int dictAdd(dict *d, void *key, void *val)
{
// Try adding a key to the dictionary and return the new hash node that contains the key
// T = O(N)
dictEntry *entry = dictAddRaw(d,key);
// Key already exists, failed to add
if (!entry) return DICT_ERR;
// Key does not exist, set the value of node
// T = O(1)
dictSetVal(d, entry, val);
// Added successfully
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
// If conditions permit, perform one-step rehash
// T = O(1)
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
// Calculates the index value of the key in the hash table
// If the value is - 1, the key already exists
// T = O(N)
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
// T = O(1)
/* Allocate the memory and store the new entry */
// If the dictionary is rehash, add a new key to hash table 1
// Otherwise, add the new key to hash table No. 0
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// Allocate space for new nodes
entry = zmalloc(sizeof(*entry));
// Insert the new node into the linked list header
entry->next = ht->table[index];
ht->table[index] = entry;
// Update the number of nodes used by the hash table
ht->used++;
/* Set the hash entry fields. */
// Set key for new node
// T = O(1)
dictSetKey(d, entry, key);
return entry;
}
dictReplace adds a node and deletes the old node if it exists
The process is relatively simple. First, the key value is added to the dictionary. If it exists, the node entry will be found, the new value will be set, and finally the old auxentry will be released.
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will suceed. */
// Try adding key value pairs directly to the dictionary
// If the key does not exist, the addition will succeed
// T = O(N)
if (dictAdd(d, key, val) == DICT_OK)
return 1;
/* It already exists, get the entry */
// Run here to indicate that the key already exists. Then find the node containing the key
// T = O(1)
entry = dictFind(d, key);
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
// Save the pointer of the original value first
auxentry = *entry;
// Then set the new value
// T = O(1)
dictSetVal(d, entry, val);
// Then release the old value
// T = O(1)
dictFreeVal(d, &auxentry);
return 0;
}
dictReplaceRaw finds or adds a node
Call the dictFind function, pass dict and key, and find the node in the dictionary. If it is found, it will return the node. If it is not found, it will return a node with key set but no value.
dictEntry *dictReplaceRaw(dict *d, void *key) {
// Use key to find nodes in the dictionary
// T = O(1)
dictEntry *entry = dictFind(d,key);
// If the node finds a direct return node, otherwise a new node is added and returned
// T = O(N)
return entry ? entry : dictAddRaw(d,key);
}
dictGenericDelete deletes nodes according to the key
h is the calculated hash value, IDX is the index of the hash table node array, he is the current node, prevHe is the previous node pointing to he, and table is the subscript of the current hash table. Calculate the hash value through * key and traverse two hash tables. h & D - > HT [table]. Sizemask is equivalent to intercepting the hash value and taking only the following bits. After locating IDX, traverse the linked list of hash nodes and compare whether the keys are equal through the dictCompareKeys function. If the previous node has a value, the pointer of the previous node will point to the next address of the current node. If the previous node has no value, it means that the node is not in the linked list, The node with index idx will directly point to the next node of the current node. nofree negates to true to free the memory space of the node. If the key is not found after the traversal, judge whether it is re hashing at this time. If there is no re hashing, it means that there is no data in hash table 1 at this time, and the second for (table = 0; table < = 1; Table + +) will not be traversed.
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
unsigned int h, idx;
dictEntry *he, *prevHe;
int table;
// The dictionary (hash table of) is empty
if (d->ht[0].size == 0) return DICT_ERR; /* d->ht[0].table is NULL */
// Perform one-step rehash, T = O(1)
if (dictIsRehashing(d)) _dictRehashStep(d);
// DP Hash
h = dictHashKey(d, key);
// Traversal hash table
// T = O(1)
for (table = 0; table <= 1; table++) {
// Calculate index value
idx = h & d->ht[table].sizemask;
// Points to the linked list on the index
he = d->ht[table].table[idx];
prevHe = NULL;
// Traverse all nodes on the linked list
// T = O(1)
while(he) {
if (dictCompareKeys(d, key, he->key)) {
// Over find target node
/* Unlink the element from the list */
// Delete from linked list
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
// Release functions that call keys and values?
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
}
// Release the node itself
zfree(he);
// Update the number of nodes used
d->ht[table].used--;
// Return found signal
return DICT_OK;
}
prevHe = he;
he = he->next;
}
// If this is done, the given key cannot be found in the hash table No. 0
// Then decide whether to look up hash table 1 according to whether the dictionary is rehash
if (!dictIsRehashing(d)) break;
}
// Can't find
return DICT_ERR; /* not found */
}
dictDelete dictDeleteNoFree delete node
dictDelete: deletes nodes and frees up space
dictDeleteNoFree: deletes nodes and frees up space
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0);
}
int dictDeleteNoFree(dict *ht, const void *key) {
return dictGenericDelete(ht,key,1);
}
_ dictClear deletes all nodes in a Hasn table
This function will first traverse the dictEntry **table Hash array in dictht. If the callback callback function is passed in, and the current i is not out of range, the private data field will be passed into the callback. (i & 65535) the range of int in this command is greater than 65535, but such a long range is not required for cyclic shift, so 65535 is used to trim the high position after shift. If the linked list in the index is not empty, the key value will be deleted, and finally the allocated space of the whole Hash table will be released and reset to initialization.
int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {
unsigned long i;
/* Free all the elements */
// Traverse the entire hash table
// T = O(N)
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (callback && (i & 65535) == 0) callback(d->privdata);
// Skip empty index
if ((he = ht->table[i]) == NULL) continue;
// Traverse the entire linked list
// T = O(1)
while(he) {
nextHe = he->next;
// Delete key
dictFreeKey(d, he);
// Delete value
dictFreeVal(d, he);
// Release node
zfree(he);
// Update used node count
ht->used--;
// Process next node
he = nextHe;
}
}
/* Free the table and the allocated cache structure */
// Release hash table structure
zfree(ht->table);
/* Re-initialize the table */
// Reset hash table properties
_dictReset(ht);
return DICT_OK; /* never fails */
}
dictRelease release dictionary
Free the memory space of the two Hash tables without passing the callback function. Finally, release the dict dictionary.
void dictRelease(dict *d)
{
// Delete and empty two hash tables
_dictClear(d,&d->ht[0],NULL);
_dictClear(d,&d->ht[1],NULL);
// Release node structure
zfree(d);
}
dictFind returns the node containing the key in the dictionary
The search logic of this function is consistent with that of dictGenericDelete function. See the interpretation of dictGenericDelete for details.
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
// The dictionary (hash table of) is empty
if (d->ht[0].size == 0) return NULL; /* We don't have a table at all */
// If conditions permit, perform one-step rehash
if (dictIsRehashing(d)) _dictRehashStep(d);
// Calculate the hash value of the key
h = dictHashKey(d, key);
// Look up this key in the hash table of the dictionary
// T = O(1)
for (table = 0; table <= 1; table++) {
// Calculate index value
idx = h & d->ht[table].sizemask;
// Traverse all nodes of the linked list on the given index and find the key
he = d->ht[table].table[idx];
// T = O(1)
while(he) {
if (dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
// If the program traverses the hash table No. 0, it still cannot find the node of the specified key
// Then the program will check whether the dictionary is rehash,
// Then decide whether to return NULL directly or continue to look up hash table No. 1
if (!dictIsRehashing(d)) return NULL;
}
// At this point, it means that neither hash table is found
return NULL;
}
dictFetchValue gets the value through the key
This function calls the dictFind function to locate the node through the key. If the node he is not empty, it returns value. Otherwise, it returns NULL.
void *dictFetchValue(dict *d, const void *key) {
dictEntry *he;
// T = O(1)
he = dictFind(d,key);
return he ? dictGetVal(he) : NULL;
}
dictFingerprint get unique fingerprint
A fingerprint is a 64 bit number that represents the state of the dictionary at a given time. It is just an exclusive or of several dictionary attributes. When an unsafe iterator is initialized, we get the dict fingerprint. When the iterator is released, we check the fingerprint again. If the two fingerprints are different, it means that the user of the iterator has forbidden the dictionary during iteration.
This algorithm is used to calculate dict twice at the beginning and end of the iteration. The Hash algorithm is calculated through the size and usage of tables 1 and 2 and the first address to judge whether the illegal operation of modification and deletion is carried out during the iteration.
long long dictFingerprint(dict *d) {
long long integers[6], hash = 0;
int j;
integers[0] = (long) d->ht[0].table;
integers[1] = d->ht[0].size;
integers[2] = d->ht[0].used;
integers[3] = (long) d->ht[1].table;
integers[4] = d->ht[1].size;
integers[5] = d->ht[1].used;
/* We hash N integers by summing every successive integer with the integer
* hashing of the previous sum. Basically:
*
* Result = hash(hash(hash(int1)+int2)+int3) ...
*
* This way the same set of integers in a different order will (likely) hash
* to a different number. */
for (j = 0; j < 6; j++) {
hash += integers[j];
/* For the hashing step we use Tomas Wang's 64 bit integer hash. */
hash = (~hash) + (hash << 21); // hash = (hash << 21) - hash - 1;
hash = hash ^ (hash >> 24);
hash = (hash + (hash << 3)) + (hash << 8); // hash * 265
hash = hash ^ (hash >> 14);
hash = (hash + (hash << 2)) + (hash << 4); // hash * 21
hash = hash ^ (hash >> 28);
hash = hash + (hash << 31);
}
return hash;
}
dictGetIterator dictGetSafeIterator creates an iterator
The creation of iterators is relatively simple. First, use zmalloc to allocate space, and point ITER - > d to the first address of the dictionary to be iterated. Table is used to identify table 0 or table 1. The index position is set to - 1. The address of the current iteration and the address of the next node are set to be empty. The dictGetSafeIterator function calls dictGetIterator to create. After creation, set the safe state to 1. The value of fingerprintd calls dictFingerprint to obtain the fingerprint (key).
typedef struct dictIterator {
// Iterated dictionary
dict *d;
// Table: the hash table number being iterated. The value can be 0 or 1.
// Index: the hash table index location that the iterator is currently pointing to.
// Safe: identifies whether the iterator is safe
int table, index, safe;
// entry: pointer to the node to which the current iteration is applied
// nextEntry: the next node of the current iteration node
// Because the node pointed to by the entry may be modified during the operation of the security iterator,
// Therefore, an additional pointer is required to save the position of the next node,
// This prevents pointer loss
dictEntry *entry, *nextEntry;
long long fingerprint; /* unsafe iterator fingerprint for misuse detection */
} dictIterator;
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
// Set security iterator ID
i->safe = 1;
return i;
}
dictNext gets the next node pointed to by the iterator
This function uses the while true loop to traverse. If the current node entry pointed to by the current iterator is empty, the address of the current table is given to * ht. If the index is equal to - 1 and the table is table 0 at this time, this is the first iteration. It will judge whether the current iterator is safe (read-only and not write), and increase the value of iterators by 1, If not, calculate the fingerprint value and use it as the end of traversal to judge whether it is traversed by danger. If the size of the index value exceeds the size of the current hash table (signed unsigned) ht - > size, judge whether the hash is being re hashed and the current traversal is table 0, then the iterator address will be given to ht. If not, the loop will end. Finally, set the address pointed to by the entry to determine whether the entry is empty. If not, record the next address to be traversed by the iterator.
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
// There are two possibilities to enter this cycle:
// 1) This is the first time the iterator has run
// 2) The nodes in the current index linked list have been iterated (NULL is the end of the linked list)
if (iter->entry == NULL) {
// Points to the hash table being iterated
dictht *ht = &iter->d->ht[iter->table];
// Execute on first iteration
if (iter->index == -1 && iter->table == 0) {
// If it is a secure iterator, update the secure iterator counter
if (iter->safe)
iter->d->iterators++;
// If it is an unsafe iterator, the fingerprint is calculated
else
iter->fingerprint = dictFingerprint(iter->d);
}
// Update index
iter->index++;
// If the iterator's current index is larger than the size of the hash table currently being iterated
// This means that the hash table has been iterated
if (iter->index >= (signed) ht->size) {
// If rehash is in progress, it indicates that hash table 1 is also in use
// Then continue to iterate over hash table 1
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
// If there is no rehash, the iteration is complete
} else {
break;
}
}
// If this is the case, the hash table has not been iterated
// Update node pointer to the header node of the next index linked list
iter->entry = ht->table[iter->index];
} else {
// Execution here shows that the program is iterating over a linked list
// Point the node pointer to the next node in the linked list
iter->entry = iter->nextEntry;
}
// If the current node is not empty, the next node of the node is also recorded
// Because the security iterator may delete the current node returned by the iterator
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
// Iteration complete
return NULL;
}
dictReleaseIterator destroys iterators
The implementation of destroying iterators is relatively simple. First, judge whether the iterator has been used. If it has been used, it will judge whether it is a safe iterator. If it is safe, it will first reduce the number of safe iterators by one. If not, use the DEBUG assertion mechanism to judge whether the fingerprint is consistent, that is, judge whether the dictionary has been modified. If it has been modified, the program will terminate abnormally. Finally, call zfree to destroy the iterator.
void dictReleaseIterator(dictIterator *iter) {
if (!(iter->index == -1 && iter->table == 0)) {
// When the security iterator is released, the security iterator counter is decremented by one
if (iter->safe) {
iter->d->iterators--;
// When releasing an unsafe iterator, verify that the fingerprint has changed
} else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
dictGetRandomKey randomly returns a node
If the size of the dictionary is 0, NULL will be returned, and rehash will be performed once in a single step at the lookup node. If rehash is performed, table 1 will be used, otherwise only table 0 will be queried. random() is a macro definition in stdlib.h. After a dictEntry *he node is randomly located, calculate the length of the linked list, and then use random() to calculate the remainder of the length to calculate the index of the node to be returned.
dictEntry *dictGetRandomKey(dict *d) {
dictEntry *he, *orighe;
unsigned int h;
int listlen, listele;
// The dictionary is empty
if (dictSize(d) == 0) { return NULL; }
// One step rehash
if (dictIsRehashing(d)) { _dictRehashStep(d); }
// If rehash is in progress, hash table No. 1 is also used as the target of random lookup
if (dictIsRehashing(d)) {
// T = O(N)
do {
h = random() % (d->ht[0].size + d->ht[1].size);
he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :
d->ht[0].table[h];
} while (he == NULL);
// Otherwise, only the node is looked up from the hash table No. 0
} else {
// T = O(N)
do {
h = random() & d->ht[0].sizemask;
he = d->ht[0].table[h];
} while (he == NULL);
}
/* Now we found a non empty bucket, but it is a linked
* list and we need to get a random element from the list.
* The only sane way to do so is counting the elements and
* select a random index. */
// At present, he has pointed to a non empty node linked list
// The program will randomly return a node from the linked list
listlen = 0;
orighe = he;
// Calculate the number of nodes, T = O(1)
while (he) {
he = he->next;
listlen++;
}
// Take the module and get the index of random nodes
listele = random() % listlen;
he = orighe;
// Find nodes by index
// T = O(1)
while (listele--) { he = he->next; }
// Return random node
return he;
}
dictGetRandomKeys get random keys
This is a version of dictGetRandomKey(), which is modified to return multiple entries by jumping at random positions in the hash table and linearly scanning the entries. The return pointer to the hash table entry is stored in "des" pointing to the dictEntry pointer array. The array must have a space of at least 'count' elements. This is the parameter we pass to the function to tell us how many random elements we need. This function returns the number of items stored in 'des'. If the elements in the hash table are less than' count ', the number may be less than' count '. Note that this function is not appropriate when you need to well distribute the returned items, but only when you need to "sample" a given number of consecutive elements to run an algorithm or generate statistics. However, this function generates N elements much faster than dictGetRandomKey(), and these elements are guaranteed not to be repeated.
int dictGetRandomKeys(dict *d, dictEntry **des, int count) {
int j; /* internal hash table id, 0 or 1. */
int stored = 0;
if (dictSize(d) < count) { count = dictSize(d); }
while (stored < count) {
for (j = 0; j < 2; j++) {
/* Pick a random point inside the hash table 0 or 1. */
unsigned int i = random() & d->ht[j].sizemask;
int size = d->ht[j].size;
/* Make sure to visit every bucket by iterating 'size' times. */
while (size--) {
dictEntry *he = d->ht[j].table[i];
while (he) {
/* Collect all the elements of the buckets found non
* empty while iterating. */
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) { return stored; }
}
i = (i + 1) & d->ht[j].sizemask;
}
/* If there is only one table and we iterated it all, we should
* already have 'count' elements. Assert this condition. */
assert(dictIsRehashing(d) != 0);
}
}
return stored; /* Never reached. */
}
rev bitwise inversion
In Redis, this algorithm comes from the edu website of Stanford University, and I admire it very much.
http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel
static unsigned long rev(unsigned long v) {
unsigned long s = 8 * sizeof(v); // bit size; must be power of 2
unsigned long mask = ~0;
while ((s >>= 1) > 0) {
mask ^= (mask << s);
v = ((v >> s) & mask) | ((v << s) & ~mask);
}
return v;
}
dictScan iterative dictionary
The dictScan() function iterates over the elements in a given dictionary. The description of this paragraph is explained with notes: the algorithm used for iteration is designed by Pieter Noordhuis. The main idea of the algorithm is to add the cursor on the high binary bit, that is, instead of adding the cursor according to the normal method, the binary bit of the cursor is reverse d first, Then add and calculate the flipped value, and finally flip the result of the addition calculation again. This design is because in a complete iteration, the size of the hash table may change between two iterations. The size of the hash table is always to the power of 2, and the hash table uses a linked list to resolve conflicts. Therefore, the position of a given element in a given table can always be calculated by the hash (key) & SIZE-1 formula, where SIZE-1 is the maximum index value of the hash table, and the maximum index value is the mask (mask) of the hash table, for example, If the size of the current hash table is 16, its mask is the binary value 1111. All positions of the hash table can be recorded with the last four binary bits of the hash value.
Because two hash tables will appear during rehash, its defects are:
(1) The function may return duplicate elements, but this problem can be easily solved at the application layer
(2) In order not to miss any elements, the iterator needs to return all the keys on the given dictionary and the new table generated by expanding the hash table, so the iterator must return multiple elements in one iteration.
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata) {
dictht *t0, *t1;
const dictEntry *de;
unsigned long m0, m1;
// Skip empty dictionary
if (dictSize(d) == 0) { return 0; }
// Iterates over a dictionary with only one hash table
if (!dictIsRehashing(d)) {
// Point to hash table
t0 = &(d->ht[0]);
// Record mask
m0 = t0->sizemask;
/* Emit entries at cursor */
// Point to hash bucket
de = t0->table[v & m0];
// Traverse all nodes in the bucket
while (de) {
fn(privdata, de);
de = de->next;
}
// Iterates over a dictionary with two hash tables
} else {
// Point to two hash tables
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
// Make sure t0 is smaller than t1
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
// Record mask
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
// Point to the bucket and iterate over all nodes in the bucket
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
// Iterate over indexes in large table / / iterate over buckets in large table
// that are the expansion of the index pointed to / / these buckets are pointed to by the expansion of the index
// by the cursor in the smaller table //
do {
/* Emit entries at cursor */
// Point to the bucket and iterate over all nodes in the bucket
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits of the smaller table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
}
Private method
_ dictExpandIfNeeded initializes or extends the dictionary
If the number of nodes used is greater than or equal to the size of table 0, or re hashing is in progress (dict_can_resize is true), or the number of nodes used exceeds dict_ force_ resize_ If ratio = 5, the capacity will be doubled based on the existing nodes.
static int _dictExpandIfNeeded(dict *d) {
/* Incremental rehashing already in progress. Return. */
// Progressive rehash is already in progress. Return directly
if (dictIsRehashing(d)) { return DICT_OK; }
/* If the hash table is empty expand it to the initial size. */
// If the dictionary (hash table No. 0 of) is empty, a hash table No. 0 of initialization size is created and returned
// T = O(1)
if (d->ht[0].size == 0) { return dictExpand(d, DICT_HT_INITIAL_SIZE); }
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
// Expand the dictionary when one of the following two conditions is true
// 1) The ratio between the number of nodes used by the dictionary and the dictionary size is close to 1:1
// And dict_can_resize true
// 2) The ratio between the number of nodes used and the dictionary size exceeds dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used / d->ht[0].size > dict_force_resize_ratio)) {
// The size of the new hash table is at least twice the number of nodes currently in use
// T = O(N)
return dictExpand(d, d->ht[0].used * 2);
}
return DICT_OK;
}
_ dictNextPower calculates the power of 2
static unsigned long _dictNextPower(unsigned long size) {
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) { return LONG_MAX; }
while (1) {
if (i >= size) {
return i;
}
i *= 2;
}
}
_ dictKeyIndex calculates the index value based on the key
This function returns - 1 if the key already exists in the hash table. Note that if the dictionary is rehashing, the index of hash table 1 is always returned, because when the dictionary rehash, the new node is always inserted into hash table 1. The search logic of this function is consistent with the implementation of the search logic of dictGenericDelete function. We won't elaborate on it. See the interpretation of dictGenericDelete for details.
static int _dictKeyIndex(dict *d, const void *key) {
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
// Single step rehash
// T = O(N)
if (_dictExpandIfNeeded(d) == DICT_ERR) {
return -1;
}
/* Compute the key hash value */
// Calculate the hash value of the key
h = dictHashKey(d, key);
// T = O(1)
for (table = 0; table <= 1; table++) {
// Calculate index value
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
// Check whether the key exists
// T = O(1)
he = d->ht[table].table[idx];
while (he) {
if (dictCompareKeys(d, key, he->key)) {
return -1;
}
he = he->next;
}
// When running here, it means that all nodes in hash table No. 0 do not contain key s
// If rehahs is in progress at this time, continue rehash hash table 1
if (!dictIsRehashing(d)) { break; }
}
// Return index value
return idx;
}
dictEmpty empties the Hash table
Call_ The dictClear function deletes all nodes on the two Hash tables, and finally resets the rehashidx value of the rehash index to - 1 and the number of iterators in the dictionary to 0.
void dictEmpty(dict *d, void(callback)(void *)) {
// Delete all nodes on both hash tables
// T = O(N)
_dictClear(d, &d->ht[0], callback);
_dictClear(d, &d->ht[1], callback);
// Reset properties
d->rehashidx = -1;
d->iterators = 0;
}
dictEnableResize dictDisableResize turns on or off rehash
dict_can_resize is a static global variable. By default, re Hash is enabled. 0 means not enabled and 1 means start.
void dictEnableResize(void) {
dict_can_resize = 1;
}
void dictDisableResize(void) {
dict_can_resize = 0;
}