Redisjason Chinese full text retrieval
RedisJson
- Redisjason, which is popular on the Internet recently, I believe everyone is familiar with it. There is also a performance post that says yes Redisjason was born in the sky, with the performance of ES and Mongo! Of course, these hundreds of times improvements may be more objective. I am more concerned about redisjason's json support, full-text retrieval function and Chinese word segmentation
install
1. The official website has 30 days of free trial and 30M memory. You can create an instance for testing
- Redis cli can be used for connection test
[root@server bin]# ./redis-cli -h redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com -p 17137 -a 123456 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137>
2. You can install the reJson module yourself
Download path: https://redis.com/redis-enter...
Installation: https://oss.redis.com/redisjs...
[root@server bin]# ./redis-server --loadmodule /opt/thunisoft/redis/redisjson/rejson.so
82538:C 29 Dec 2021 18:41:09.585 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
82538:C 29 Dec 2021 18:41:09.585 # Redis version=6.2.6, bits=64, commit=00000000, modified=0, pid=82538, just started
82538:C 29 Dec 2021 18:41:09.585 # Configuration loaded
82538:M 29 Dec 2021 18:41:09.587 * monotonic clock: POSIX clock_gettime
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 6.2.6 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 82538
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | https://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
82538:M 29 Dec 2021 18:41:09.589 # Server initialized
82538:M 29 Dec 2021 18:41:09.589 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
82538:M 29 Dec 2021 18:41:09.591 * <ReJSON> version: 20006 git sha: db3329c branch: HEAD
82538:M 29 Dec 2021 18:41:09.591 * <ReJSON> Exported RedisJSON_V1 API
82538:M 29 Dec 2021 18:41:09.591 * <ReJSON> Enabled diskless replication
82538:M 29 Dec 2021 18:41:09.591 * <ReJSON> Created new data type 'ReJSON-RL'
82538:M 29 Dec 2021 18:41:09.591 * Module 'ReJSON' loaded from /opt/thunisoft/redis/redisjson/rejson.so
82538:M 29 Dec 2021 18:41:09.602 * Loading RDB produced by version 6.2.6
82538:M 29 Dec 2021 18:41:09.602 * RDB age 98297 seconds
82538:M 29 Dec 2021 18:41:09.603 * RDB memory usage when created 0.77 Mb
82538:M 29 Dec 2021 18:41:09.603 # Done loading RDB, keys loaded: 2, keys expired: 0.
82538:M 29 Dec 2021 18:41:09.603 * DB loaded from disk: 0.011 seconds
82538:M 29 Dec 2021 18:41:09.603 * Ready to accept connections
Modify redis conf
/opt/thunisoft/redis/bin/redis.conf --add to loadmodule /opt/thunisoft/redis/redisjson/rejson.so
Then restart redis and JSON Set is already available
[root@server bin]# sh start.sh
[root@server bin]# ./redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> JSON.SET jsonkey . '{"a":"b","c":["1","2","3"]}'
OK
127.0.0.1:6379> JSON.GET jsonkey
"{\"a\":\"b\",\"c\":[\"1\",\"2\",\"3\"]}"
127.0.0.1:6379> JSON.GET jsonkey .a
"\"b\""JSON usage
JSON.SET
127.0.0.1:6379> JSON.SET doc . '{"a":2, "b": 3}'
OK- SON.SET is the json setting command
- doc is key
- . Is the root of the json document, followed by a string of specific json data values
- If redisjson2 is used 0 + version, you can add Replace with JSON SET doc $ '{"a":2, "b": 3}'
JSON.GET
- JSON.GET json value
127.0.0.1:6379> JSON.GET doc
"{\"a\":2,\"b\":3}"
127.0.0.1:6379> JSON.GET doc a
"2"- Nested structure to get json value
127.0.0.1:6379> JSON.SET doc $ '{"a":2, "b": 3, "nested": {"a": 4, "b": null},"c":{"b":4}}'
OK
127.0.0.1:6379> JSON.GET doc b
"3"
-- $..b Can get all b Value of
127.0.0.1:6379> JSON.GET doc $..b
"[3,null,4]"JSON.STRAPPEND
- JSON.STRAPPEND <key> [path] <json-string>
- Append the JSON string value to the path in the string. If path is not provided, it defaults to root.
127.0.0.1:6379> JSON.SET doc $ '{"a":"foo", "nested": {"a": "hello"}, "nested2": {"a": 31}}'
OK
127.0.0.1:6379> JSON.GET doc $
"[{\"a\":\"foo\",\"nested\":{\"a\":\"hello\"},\"nested2\":{\"a\":31}}]"
127.0.0.1:6379>
127.0.0.1:6379> JSON.STRAPPEND doc $..a '"baz"'
1) (integer) 6
2) (integer) 8
3) (nil)
127.0.0.1:6379> JSON.GET doc $
"[{\"a\":\"foobaz\",\"nested\":{\"a\":\"hellobaz\"},\"nested2\":{\"a\":31}}]"
JSON.DEL
127.0.0.1:6379> JSON.SET doc $ '{"a": 1, "nested": {"a": 2, "b": 3}}'
OK
127.0.0.1:6379> JSON.get doc
"{\"a\":1,\"nested\":{\"a\":2,\"b\":3}}"
127.0.0.1:6379>
127.0.0.1:6379>
--delete
127.0.0.1:6379> JSON.DEL doc $..a
(integer) 2
127.0.0.1:6379>
127.0.0.1:6379> JSON.get doc
"{\"nested\":{\"b\":3}}"JSON.ARRAPPEND
Syntax: JSON ARRAPPEND <key> <path> <json> [json ...]
Append the json value after the last element of the path in the array.
127.0.0.1:6379> JSON.SET doc $ '{"a":[1], "nested": {"a": [1,2]}, "nested2": {"a": 42}}'
OK
127.0.0.1:6379> JSON.ARRAPPEND doc $..a 3 4
1) (integer) 3
2) (integer) 4
3) (nil)
127.0.0.1:6379> JSON.GET doc $
"[{\"a\":[1,3,4],\"nested\":{\"a\":[1,2,3,4]},\"nested2\":{\"a\":42}}]"A nested array in json contains multiple records, similar to a table
127.0.0.1:6379> JSON.SET testarray . '{"employees":[ {"name":"Alpha", "email":"alpha@gmail.com", "age":23}, {"name":"Beta", "email":"beta@gmail.com", "age":28}, {"name":"Gamma", "email":"gamma@gmail.com", "age":33}, {"name":"Theta", "email":"theta@gmail.com", "age":41} ]} ' OK 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> JSON.get testarray "{\"employees\":[{\"name\":\"Alpha\",\"email\":\"alpha@gmail.com\",\"age\":23},{\"name\":\"Beta\",\"email\":\"beta@gmail.com\",\"age\":28},{\"name\":\"Gamma\",\"email\":\"gamma@gmail.com\",\"age\":33},{\"name\":\"Theta\",\"email\":\"theta@gmail.com\",\"age\":41}]}"
JSON.ARRINSERT
Syntax: JSON ARRINSERT <key> <path> <index> <json> [json ...]
Inserts a value into an array
127.0.0.1:6379> JSON.SET doc $ '{"a":[3], "nested": {"a": [3,4]}}'
OK
127.0.0.1:6379> JSON.ARRINSERT doc $..a 0 1 2 5
1) (integer) 4
2) (integer) 5
127.0.0.1:6379> JSON.GET doc $
"[{\"a\":[1,2,5,3],\"nested\":{\"a\":[1,2,5,3,4]}}]"
There are many JSON operations available for reference: https://oss.redis.com/redisjs...
JSON full text retrieval
Working with documents: https://developer.redis.com/h...
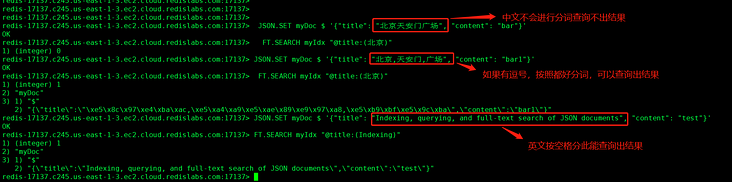
You can see that by default, Chinese is not segmented, but is segmented by comma by default. English supports full-text retrieval
Query the data to know that redisjson can specify word segmentation when creating the index
FT.CREATE {index}
[ON {data_type}]
[PREFIX {count} {prefix} [{prefix} ...]
[FILTER {filter}]
[LANGUAGE {default_lang}]
[LANGUAGE_FIELD {lang_attribute}]
[SCORE {default_score}]
[SCORE_FIELD {score_attribute}]
[PAYLOAD_FIELD {payload_attribute}]
[MAXTEXTFIELDS] [TEMPORARY {seconds}] [NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS] [SKIPINITIALSCAN]
[STOPWORDS {num} {stopword} ...]
SCHEMA {identifier} [AS {attribute}]
[TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] [CASESENSITIVE] [SORTABLE [UNF]] [NOINDEX]] |
[VECTOR {algorithm} {count} [{attribute_name} {attribute_value} ...]] ...- json create index
- ON JSON, specify TEXT if it is TEXT
--Create a new index: i_index1
redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.CREATE i_index1 ON JSON LANGUAGE chinese SCHEMA $.title TEXT
OK
--insert data
redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> JSON.SET myDoc $ '{"title": "Panlong District, Kunming City, Yunnan Province", "content": "bar1"}'
OK
--Query Kunming, you can find the results
redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Kunming" LANGUAGE chinese
1) (integer) 1
2) "myDoc"
3) 1) "$"
2) "{\"title\":\"\xe5\x9b\x9b\xe5\xb7\x9d\xe7\x9c\x81\xe6\x88\x90\xe9\x83\xbd\xe5\xb8\x82\xe6\x88\x90\xe5\x8d\x8e\xe5\x8c\xba\",\"content\":\"bar1\"}"- Word segmentation method
From the following results, you can query Yunnan Province, Kunming City and Panlong District, but you can't query Kunming, Yunnan and kunpan.
redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Yunnan Province" LANGUAGE chinese 1) (integer) 1 2) "myDoc" 3) 1) "$" 2) "{\"title\":\"\xe5\x9b\x9b\xe5\xb7\x9d\xe7\x9c\x81\xe6\x88\x90\xe9\x83\xbd\xe5\xb8\x82\xe6\x88\x90\xe5\x8d\x8e\xe5\x8c\xba\",\"content\":\"bar1\"}" redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "area" LANGUAGE chinese 1) (integer) 0 redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Yunnan Province" LANGUAGE chinese 1) (integer) 0 redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Kunming" LANGUAGE chinese 1) (integer) 1 2) "myDoc" 3) 1) "$" 2) "{\"title\":\"\xe5\x9b\x9b\xe5\xb7\x9d\xe7\x9c\x81\xe6\x88\x90\xe9\x83\xbd\xe5\xb8\x82\xe6\x88\x90\xe5\x8d\x8e\xe5\x8c\xba\",\"content\":\"bar1\"}" redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Kunming" LANGUAGE chinese 1) (integer) 0 redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Panlong District" LANGUAGE chinese 1) (integer) 1 2) "myDoc" 3) 1) "$" 2) "{\"title\":\"\xe5\x9b\x9b\xe5\xb7\x9d\xe7\x9c\x81\xe6\x88\x90\xe9\x83\xbd\xe5\xb8\x82\xe6\x88\x90\xe5\x8d\x8e\xe5\x8c\xba\",\"content\":\"bar1\"}" redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Panlong" LANGUAGE chinese 1) (integer) 0 redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "area" LANGUAGE chinese 1) (integer) 0- Test Nanjing Yangtze River Bridge
You can see that the Nanjing Yangtze River Bridge, the query Nanjing, the Yangtze River and the bridge have no results, the query Nanjing, the Yangtze River Bridge has results, and the wipe test may be divided into Nanjing and the Yangtze River Bridge
redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> JSON.SET myDoc $ '{"title": "Nanjing Yangtze River Bridge", "content": "bar1"}' OK redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Nanjing City" LANGUAGE chinese 1) (integer) 1 2) "myDoc" 3) 1) "$" 2) "{\"title\":\"\xe5\x8d\x97\xe4\xba\xac\xe5\xb8\x82\xe9\x95\xbf\xe6\xb1\x9f\xe5\xa4\xa7\xe6\xa1\xa5\",\"content\":\"bar1\"}" redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Yangtze River" LANGUAGE chinese 1) (integer) 0 redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Bridge" LANGUAGE chinese 1) (integer) 0 redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Yangtze River Bridge" LANGUAGE chinese 1) (integer) 1 2) "myDoc" 3) 1) "$" 2) "{\"title\":\"\xe5\x8d\x97\xe4\xba\xac\xe5\xb8\x82\xe9\x95\xbf\xe6\xb1\x9f\xe5\xa4\xa7\xe6\xa1\xa5\",\"content\":\"bar1\"}" redis-17137.c245.us-east-1-3.ec2.cloud.redislabs.com:17137> FT.SEARCH i_index1 "Nanjing" LANGUAGE chinese 1) (integer) 0
You need to specify LANGUAGE chinese when creating an index
redisjson: https://oss.redis.com/redisea...
- Supported languages for full-text retrieval:
arabic armenian danish dutch english finnish french german hungarian italian norwegian portuguese romanian russian serbian spanish swedish tamil turkish yiddish chinese (see below)
RediSearch uses Friso by default for Chinese word segmentation
Friso: Friso is an open source Chinese word splitter developed in ANSI C language, using the popular mmseg
Algorithm implementation. Completely based on modular design and implementation, it can be easily implanted into other programs, such as MySQL and PHP. The source code can be compiled and used on various platforms without modification. At the same time, it supports the segmentation of UTF-8/GBK coding.
Friso participle
- Install Friso participle, and the test shows that it is indeed true
[root@server friso-1.6.1-release]# ./src/friso -init ./friso.ini Initialized in 0.340000sec Mode: Complex +-Version: 1.6.1 (UTF-8) +-----------------------------------------------------------+ | friso - a chinese word segmentation writen by c. | | bug report email - chenxin619315@gmail.com. | | or: visit http://code.google.com/p/friso. | | java edition for http://code.google.com/p/jcseg | | type 'quit' to exit the program. | +-----------------------------------------------------------+ friso>> Nanjing Yangtze River Bridge Word segmentation result: Nanjing Yangtze River Bridge Done, cost < 0.000000sec friso>> Panlong District, Kunming City, Yunnan Province Word segmentation result: Panlong District, Kunming City, Yunnan Province Done, cost < 0.000000sec friso>>
Friso is implemented based on mmseg algorithm. It is mainly positive maximum matching, supplemented by a variety of disambiguation rules
mmseg participle: http://technology.chtsai.org/...
Each time from a complete sentence, identify a variety of different combinations of three words in the order from left to right; Then, according to the following four disambiguation rules, determine the best alternative word combination; Select the first word in the alternative word combination as the word segmentation result of one iteration; The remaining 2 words continue the next round of word segmentation. The advantage of this method is that the context information is added to the traditional forward maximum matching algorithm, which solves the problem that each word selection only considers the word itself and ignores the context related words. 4 Disambiguation rules include, 1)The sum of the lengths of alternative word combinations is the largest. 2)The average word length of alternative word combinations is the largest; 3)The change of word length of alternative word combination is the smallest; 4)In the combination of alternative words, the statistical value of the occurrence frequency of single word words is the highest.
Compare word segmentation of abase database (SCWS)
- scws word segmentation, will be divided into very fine, basically covering the splitting of all phrases
postgres=# select to_tsvector('testzhcfg ',' Nanjing Yangtze River Bridge ');
to_tsvector
----------------------------------------------------------------------------------------
'Nanjing':2 'Nanjing City':1 'large':9 'Bridge':6 'city':3 'Bridge':10 'river':8 'long':7 'Yangtze River':5 'Yangtze River Bridge':4
(1 row)
postgres=# select to_tsvector('testzhcfg ',' Panlong District, Kunming City, Yunnan Province ');
to_tsvector
-----------------------------------------------------------------------------------------------------
'area':12 'Loong':11 'Yunnan':2 'Yunnan Province':1 'city':7 'Kun':6,10 'Panlong':9 'Panlong District':8 'Kunming':5 'Kunming':4 'province':3
(1 row)
ES
es has a special word segmentation engine, supports a variety of word splitters, and often uses IK word segmentation
summary
1. Redisjason supports JSON full-text retrieval and uses Friso word segmentation. The word segmentation is not particularly detailed, which will lead to some binary phrases not being queried
2. Compared with JSON, the operation functions are relatively comprehensive. RedisJson has not been out for a long time, and there are few online application scenarios
This article is composed of blog one article multi posting platform OpenWrite release!