AI Studio project link https://aistudio.baidu.com/aistudio/projectdetail/3451057
This paper reproduces CVPR2021, rethinks void convolution, surpasses Deeplab and BiseNetv2, and enables segmentation to achieve real-time + high precision
1, The 17th National College Student smart car competition: Online qualification competition of complete model group!

Competition address: https://aistudio.baidu.com/aistudio/competition/detail/131/0/task-definition
1. Introduction to the competition
The popularity of vehicles and people's attention to travel experience put forward higher requirements for map navigation. The AR navigation system based on vehicle images can identify lane and driving area accurately and quickly. It can not only assist the driving system to make efficient decisions, but also provide more intelligent and precise navigation experience for users with the combination of terminal rendering and voice technology.
Baidu map, as a "new generation of Artificial Intelligence Map", adheres to the mission of "making travel easier with science and technology". With the help of artificial intelligence technologies such as image recognition, speech recognition and big data processing, baidu map has greatly improved the automation of map data acquisition and processing, achieved Road coverage of more than 10 million kilometers, and has become the highest AI level in the industry Equipped with the strongest AI technology and the richest map data manufacturer. The competition data is provided by Baidu map. It is required to quickly and accurately identify the real Lane crossing, virtual lane crossing and zebra crossing in the vehicle image under the unified computing resources.
The title and data of this competition are provided by Baidu map data engine department, the technical support related to model and baseline is provided by deep learning technology platform department, and the one-stop AI development platform AI Studio is provided by Baidu AI technology ecology department. It is expected that the contestants will take this opportunity to jointly promote the development of intelligent transportation.
2. Competition tasks
Participants are required to use the provided training data to realize a deep learning model that can identify the specific locations and categories of virtual lane crossing, real Lane crossing and zebra crossing under the unified computing resources, without limiting the deep learning tasks. Sample demonstration:

3. Competition data
Data set description the data set of this competition includes 16000 vehicle image data that can be directly used for training. The official adopts the segmentation connected domain labeling method to label the areas and categories of virtual lane crossing, real Lane crossing and zebra crossing on these image data, in which the labeled data is stored in the form of gray map. The annotation data is a single channel gray image with the same size as the original image, in which the gray value of the background pixel is 0 and the target pixels of different categories are different gray values. The category numbers of real Lane crossing, virtual lane crossing and zebra crossing are 1, 2 and 3 respectively. After registration, players can download the dataset in the "dataset introduction" tab.
The image and marked data correspond to the file name and number, and the organization structure is as follows:
| -- train | | -- image | | |-- 00001.jpg | | |-- ... | | |-- 08000.jpg | | -- label | | |-- 00001.png | | |-- ... | | | -- 08000.png
It should be noted that the low gray value only affects the visibility of the naked eye and does not affect the deep learning training. If you need to observe the annotation image, you can stretch it to an RGB image of 0 ~ 255.
4. Submission requirements
This competition requires players to use paddle paddlepaddle2 Version 1 or above generates an end-to-end deep learning model.
Players need to upload zip compressed packages of training model, prediction code and environment library (optional) to AI Studio platform for automatic evaluation. The prediction code should be named predict Py, the model directory shall not exceed 200M (not compressed), and the overall compressed package shall not exceed 1G. The directory structure is agreed as follows:
| -- model | | -- xxx.pb | | ... | -- env | | -- xxx.lib | |... | -- predict.py | -- ...
II Environmental preparation
# First, download the paddedetection and PaddleSeg programs from gitee # This step has been completed and does not need to be repeated in this baseline environment # Currently, paddleseg2.0 is provided for you Version 1 is used as the baseline, and users can also choose paddleseg2 2. 2.3 or develop ep version. %cd work/ !git clone https://gitee.com/paddlepaddle/PaddleSeg.git # Check whether the download is successful !ls /home/aistudio/work # Install related dependencies in the AIStudio environment !pip install paddleseg -i https://mirror.baidu.com/pypi/simple
III Data preparation
1. Decompress data
!unzip data/data125507/CM_data_2022.zip
2. Divide data sets
data_base_dir='/home/aistudio/work/data_2022_baseline/'
data_folader='JPEGImages'
label_folader='Annotations'
train_list='/home/aistudio/train_list.txt'
eval_list='/home/aistudio/eval_list.txt'
test_list='/home/aistudio/test_list.txt'
def split_eval_train_test(root:str,train_rate:float,eval_rate:float,test_rate:float,train_txt:str,eval_txt:str,test_txt:str):
image_folader_path=os.path.join(root,data_folader)
label_folader_path=os.path.join(root,label_folader)
data_list=[x for x in os.listdir(image_folader_path) ]
random.shuffle(data_list)
train_data=random.sample(data_list,k=int(len(data_list)*train_rate))
test_val_data=[]
for data in data_list:
if data not in train_data:
test_val_data.append(data)
random.shuffle(test_val_data)
test_data=random.sample(test_val_data,k=int(len(test_val_data)*(test_rate)/(test_rate+eval_rate)))
#Empty txt
files=open(train_txt,'w')
files=open(test_txt,'w')
files=open(eval_txt,'w')
for data in data_list:
if data in train_data:
files=open(train_txt,'a')
files.write(os.path.join(image_folader_path,data)+'\t'+os.path.join(label_folader_path,data[:-4]+'.png')+'\n')
elif data in test_data:
files=open(test_txt,'a')
files.write(os.path.join(image_folader_path,data)+'\t'+os.path.join(label_folader_path,data[:-4]+'.png')+'\n')
else:
files=open(eval_list,'a')
files.write(os.path.join(image_folader_path,data)+'\t'+os.path.join(label_folader_path,data[:-4]+'.png')+'\n')
print('The data set is divided')
split_eval_train_test(data_base_dir,0.6,0.2,0.2,train_list,eval_list,test_list)
IV model training
1. Model configuration
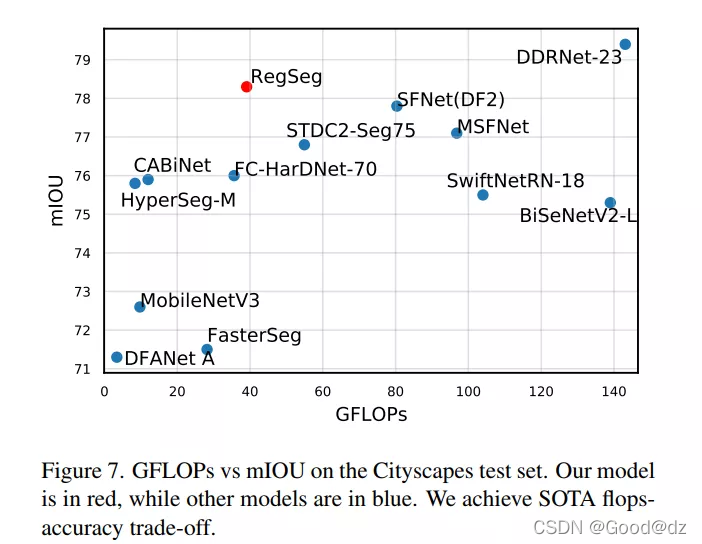
It can be seen from the above figure that the performance of RegSeg is much better than that of BiseNetv2_ The accuracy of L is better, and the amount of calculation is significantly less than that of BiseNetv2.
Before semantic segmentation, ImageNet's Backbone was usually used for feature extraction, and larger pool size (such as PPM) or larger expansion rate (such as ASPP) were usually used to improve the receptive field, but such operation cost was very high. And for the semantic segmentation task, the resolution of the input image has a certain relationship with the accuracy, and the resolution of ImageNet is obviously contrary to this principle.
ImageNet Backbone usually has a large number of channels in the last few convolution layers, but Mobilenetv3 found that halving the number of channels in the last convolution layer will not affect the semantic segmentation performance.
The ImageNet model obtains an input image with a resolution of about 224x224, but the semantically segmented image is much larger. For example, the image resolution of Cityscapes is 1024x2048 and that of camvid is 720x960
After my verification: under the same training conditions, the miou of BiseNetv2 can be improved by 0.0001 in the first round of verification
1. Type layer and depth separable convolution layer
import paddle
import paddle.nn as nn
import paddle.io as io
import numpy as np
import cv2
import os
import sys
#Please add the following line when putting paddleseg
#from paddleseg.cvlibs import manager
#from paddleseg.models import layers
#from paddleseg.utils import utils
class Stem(nn.Layer):
def __init__(self,in_dim=3,out_dim=32):
super(Stem,self).__init__()
self.conv_bn_relu=nn.Sequential(
nn.Conv2D(in_channels=in_dim,out_channels=out_dim,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2D(out_dim),
nn.ReLU()
)
def forward(self,inputs):
outputs=self.conv_bn_relu(inputs)
return outputs
class Conv_Bn_Relu(nn.Layer):
def __init__(self,in_dim,out_dim,kernel,stride,pad):
super(Conv_Bn_Relu,self).__init__()
self.conv_bn_relu=nn.Sequential(
nn.Conv2D(in_channels=in_dim,out_channels=out_dim,kernel_size=kernel,stride=stride,padding=pad),
nn.BatchNorm2D(out_dim),
nn.ReLU()
)
def forward(self,inputs):
outputs=self.conv_bn_relu(inputs)
return outputs
class DepthWise_Conv(nn.Layer):
def __init__(self,in_channels,kernel_size=3,stride=1,padding=1,groups=16,dilate=1):
super(DepthWise_Conv,self).__init__()
self.conv=nn.Sequential(
nn.Conv2D(in_channels=in_channels,out_channels=in_channels,kernel_size=kernel_size,stride=stride,padding=padding,dilation=dilate,groups=groups),
nn.BatchNorm2D(in_channels),
nn.ReLU()
)
def forward(self, inputs):
x=self.conv(inputs)
return x
2. Channel attention mechanism: SE
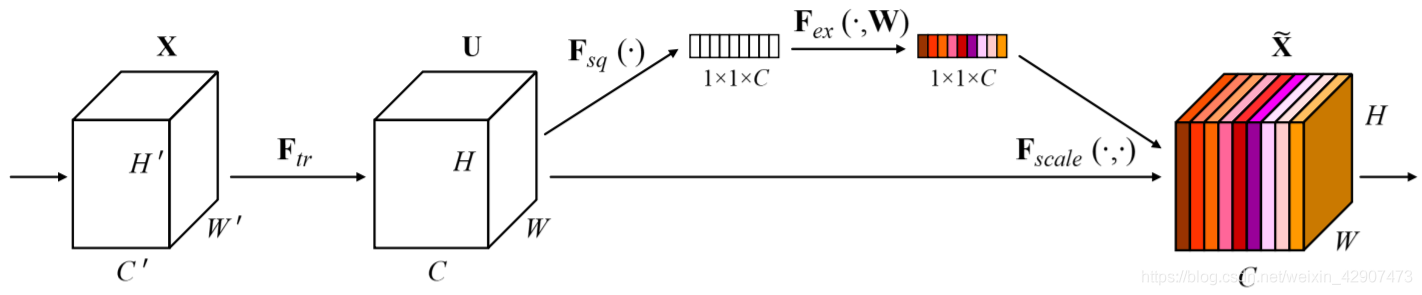
class SEBlock(nn.Layer):
'''
Attention module
'''
def __init__(self,in_channel,reduce=4):
super(SEBlock,self).__init__()
self.avg_pool=nn.AdaptiveAvgPool2D(output_size=1)#Average pooling
self.flatten=nn.Flatten()
self.fc1=nn.Linear(in_features=in_channel,out_features=in_channel//reduce) # global pooled full connection layer
#Scale the reduced fc layer back to the original dimension
self.fc2=nn.Linear(in_features=in_channel//reduce,out_features=in_channel)
self.relu=nn.ReLU()
self.hsigmoid=nn.Hardsigmoid()
def forward(self,inputs):
x=self.avg_pool(inputs)#B,C,1,1
x=self.flatten(x)#B C*1*1
x=self.fc1(x)
x=self.relu(x)
x=self.fc2(x)
x=self.hsigmoid(x)#Get attention value
x=x.reshape((inputs.shape[0],inputs.shape[1],1,1))
#print('x_shape:',x.shape,' inputs_shape',inputs.shape)
output=x*inputs
return output
3. Residual connection block DBlock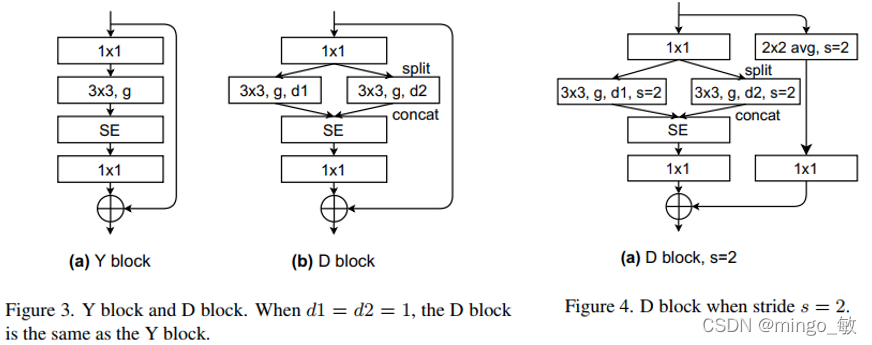
class DBlock(nn.Layer):
def __init__(self,in_dim,out_dim,stride,d2):
super(DBlock,self).__init__()
#all block g=16
self.g=16
self.stride=stride
self.conv_1x1_in=Conv_Bn_Relu(in_dim=in_dim,out_dim=out_dim,kernel=1,stride=1,pad=0)
dkernel=d2*2+1
same_pad=(dkernel-stride+1)//2
if self.stride==1:
self.split_DW1=DepthWise_Conv(in_channels=out_dim,kernel_size=3,stride=stride,padding=1,dilate=1,groups=self.g)
self.split_DW2=DepthWise_Conv(in_channels=out_dim,kernel_size=3,stride=stride,padding=same_pad,dilate=d2,groups=self.g)
elif self.stride==2:
self.split_DW1=DepthWise_Conv(in_channels=out_dim,kernel_size=3,stride=stride,padding=1,dilate=1,groups=self.g)
self.split_DW2=DepthWise_Conv(in_channels=out_dim,kernel_size=3,stride=stride,padding=same_pad,dilate=d2,groups=self.g)
self.se=SEBlock(in_channel=out_dim*2,reduce=4)
if stride==1:
self.conv_1x1_out=Conv_Bn_Relu(in_dim=out_dim*2,out_dim=in_dim,kernel=1,stride=1,pad=0)
else:
self.conv_1x1_out=Conv_Bn_Relu(in_dim=out_dim*2,out_dim=out_dim,kernel=1,stride=1,pad=0)
self.avgpool=nn.AvgPool2D(kernel_size=2,stride=2)
self.point_Conv=Conv_Bn_Relu(in_dim=in_dim,out_dim=out_dim,kernel=1,stride=1,pad=0)
def forward(self,inputs):
h=inputs
x=self.conv_1x1_in(inputs)
split=x
x1=self.split_DW1(split)
x2=self.split_DW2(x)
concat_=paddle.concat([x1,x2],axis=1)
se=self.se(concat_)
out1=self.conv_1x1_out(se)
if(self.stride==2):
h=self.avgpool(h)
h=self.point_Conv(h)
outputs=h+out1
return outputs
class DBlock_last(nn.Layer):
def __init__(self,in_dim,out_dim,stride=1,d2=14):
super(DBlock_last,self).__init__()
#all block g=16
self.g=16
self.stride=stride
self.conv_1x1_in=Conv_Bn_Relu(in_dim=in_dim,out_dim=out_dim,kernel=1,stride=1,pad=0)
dkernel=d2*2+1
same_pad=(dkernel-stride+1)//2
self.split_DW1=DepthWise_Conv(in_channels=out_dim,kernel_size=3,stride=stride,padding=1,dilate=1,groups=self.g)
self.split_DW2=DepthWise_Conv(in_channels=out_dim,kernel_size=3,stride=stride,padding=same_pad,dilate=d2,groups=self.g)
self.se=SEBlock(in_channel=out_dim*2,reduce=4)
self.conv_1x1_out=Conv_Bn_Relu(in_dim=out_dim*2,out_dim=out_dim,kernel=1,stride=1,pad=0)
self.conv=Conv_Bn_Relu(in_dim=in_dim,out_dim=out_dim,kernel=1,stride=1,pad=0)
def forward(self,inputs):
h=inputs
x=self.conv_1x1_in(inputs)
split=x
x1=self.split_DW1(split)
x2=self.split_DW2(x)
concat_=paddle.concat([x1,x2],axis=1)
se=self.se(concat_)
out1=self.conv_1x1_out(se)
h=self.conv(h)
outputs=h+out1
return outputs
#Please cancel the downward comment when putting paddleseg
#@manager.MODELS.add_component
class RegSeg(nn.Layer):
def __init__(self,num_classes=4,pretrained=None):
super(RegSeg,self).__init__()
self.out_dims=[32,48,128,256,256,256,256,320]
self.strides=[2,2,2,2,1,1,1,1]
self.repeat= [3,2,1,4,6]
self.dilate_rate=[1,1,1,2,4,14,14]
self.stem=Stem(in_dim=3,out_dim=self.out_dims[0])
self.dblock1=DBlock(in_dim=self.out_dims[0],out_dim=self.out_dims[1],stride=self.strides[1],d2=1)
self.dblock2=DBlock(in_dim=self.out_dims[1],out_dim=self.out_dims[2],stride=self.strides[2],d2=1)
self.dblock2_re=DBlock(in_dim=self.out_dims[2],out_dim=self.out_dims[2],stride=1,d2=1)
#1/4
self.dblock3=DBlock(in_dim=self.out_dims[2],out_dim=self.out_dims[3],stride=self.strides[3],d2=1)
self.dblock3_re=DBlock(in_dim=self.out_dims[3],out_dim=self.out_dims[3],stride=1,d2=1)
#1/8
self.dblock4=DBlock(in_dim=self.out_dims[3],out_dim=self.out_dims[4],stride=self.strides[4],d2=2)
self.dblock5=DBlock(in_dim=self.out_dims[4],out_dim=self.out_dims[5],stride=self.strides[5],d2=4)
self.dblock5_re=DBlock(in_dim=self.out_dims[5],out_dim=self.out_dims[5],stride=1,d2=4)
self.dblock6=DBlock(in_dim=self.out_dims[5],out_dim=self.out_dims[6],stride=self.strides[6],d2=14)
self.dblock6_re=DBlock(in_dim=self.out_dims[6],out_dim=self.out_dims[6],stride=1,d2=14)
self.dblock_last=DBlock_last(in_dim=self.out_dims[6],out_dim=self.out_dims[7],stride=1,d2=14)
self._16_dimconv=Conv_Bn_Relu(in_dim=320,out_dim=128,kernel=1,stride=1,pad=0)
self._8_dimconv=Conv_Bn_Relu(in_dim=256,out_dim=128,kernel=1,stride=1,pad=0)
self.conv2=Conv_Bn_Relu(in_dim=128,out_dim=64,kernel=3,stride=1,pad=1)
self._4_dimconv=Conv_Bn_Relu(in_dim=128,out_dim=8,kernel=1,stride=1,pad=0)
self.conv_last1=Conv_Bn_Relu(in_dim=72,out_dim=64,kernel=3,stride=1,pad=0)
self.conv_last2=nn.Conv2D(in_channels=64,out_channels=num_classes,kernel_size=1,stride=1,padding=0)
def forward(self,inps):
x=self.stem(inps)
x=self.dblock1(x)
x=self.dblock2(x)
for i in range(self.repeat[0]):
x=self.dblock2_re(x)
out1_4=x
x=self.dblock3(x)
for i in range(self.repeat[1]):
x=self.dblock3_re(x)
out2_8=x
x=self.dblock4(x)
x=self.dblock5(x)
for i in range(self.repeat[3]):
x=self.dblock5_re(x)
x=self.dblock6(x)
for i in range(self.repeat[4]):
x=self.dblock6_re(x)
x=self.dblock_last(x)
out_16=x
#1 / 16 and 1 / 8 variable dim
out_up_16=self._16_dimconv(out_16)
out_up_8=paddle.nn.functional.interpolate(out_up_16,size=[out2_8.shape[2],out2_8.shape[3]])
out_sum_8=self._8_dimconv(out2_8)
out_sum_8=out_sum_8+out_up_8
out_sum_8=self.conv2(out_sum_8)
out_sum_8=paddle.nn.functional.interpolate(out_sum_8,size=[out1_4.shape[2],out1_4.shape[3]])
out_4_dimconv=self._4_dimconv(out1_4)
concat_last=paddle.concat([out_sum_8,out_4_dimconv],axis=1)
outputs=self.conv_last1(concat_last)
outputs=self.conv_last2(outputs)
outputs=paddle.nn.functional.interpolate(outputs,size=[inps.shape[2],inps.shape[3]])
return [outputs]
def init_weight(self):
if self.pretrained is not None:
utils.load_entire_model(self, self.pretrained)
Test whether the network structure is correct
data=paddle.randn([1,3,480,480]) model=RegSeg() print(model(data)[0].shape)
[1, 4, 480, 480]
2. Training with paddleseg accessories
Use steps:
1. Create regseg. In the paddleseg/models subdirectory Py file
2. In__ init__. Add the following content under py file:
3. Add the yml file in the config subdirectory
_base_: '../_base_/car2022.yml'
model:
type: RegSeg
num_classes: 4
optimizer:
type: sgd
weight_decay: 0.0001
loss:
types:
- type: CrossEntropyLoss
coef: [1]
batch_size: 2
iters: 160000
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0.0
power: 0.9
Now you can train directly!
!!!!! Remember to uncomment the part in the code block when adding to paddleseg!!!
– config is followed by its own yml path, and the rest can not be changed
model training
%cd PaddleSeg
!python train.py \
--config configs/regseg/train.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
Model evaluation
!python val.py --config configs/regseg/train.yml --model_path output/best_model/model.pdparams
forecast
!python predict.py --config configs/regseg/train.yml --model_path output/best_model/model.pdparams --image_path ./../../data/data_2022_baseline/JPEGImages --save_dir output/result
About the author
- Name: Diana!NeuralNetwork
- 2019 bachelor degree in Intelligent Manufacturing Engineering of Wuhan University of Technology
- Interests: computer vision, reasoning deployment, transfer learning, reinforcement learning
- AIstudio homepage: Diana!NN
- You are welcome to exchange and discuss problems and make common progress~