1, Crawling through the Chinese poetry net
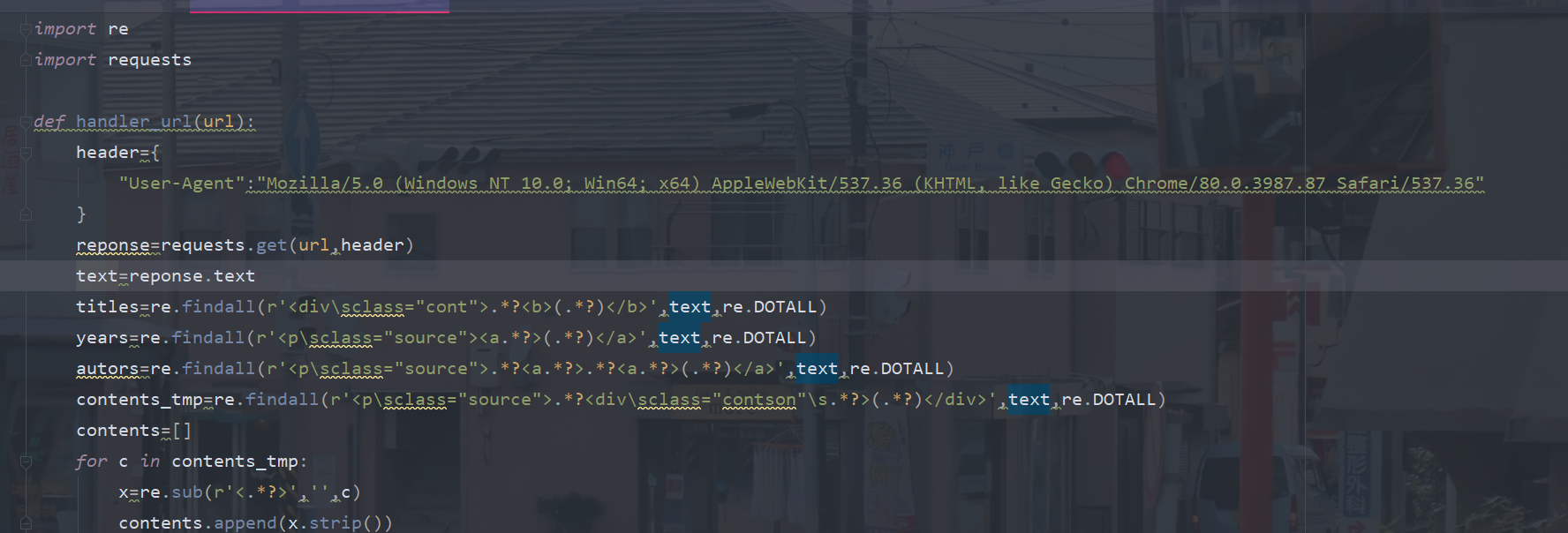
import re
import requests
def handler_url(url):
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}
reponse=requests.get(url,header)
text=reponse.text
titles=re.findall(r'<div\sclass="cont">.*?<b>(.*?)</b>',text,re.DOTALL)
years=re.findall(r'<p\sclass="source"><a.*?>(.*?)</a>',text,re.DOTALL)
autors=re.findall(r'<p\sclass="source">.*?<a.*?>.*?<a.*?>(.*?)</a>',text,re.DOTALL)
contents_tmp=re.findall(r'<p\sclass="source">.*?<div\sclass="contson"\s.*?>(.*?)</div>',text,re.DOTALL)
contents=[]
for c in contents_tmp:
x=re.sub(r'<.*?>','',c)
contents.append(x.strip())
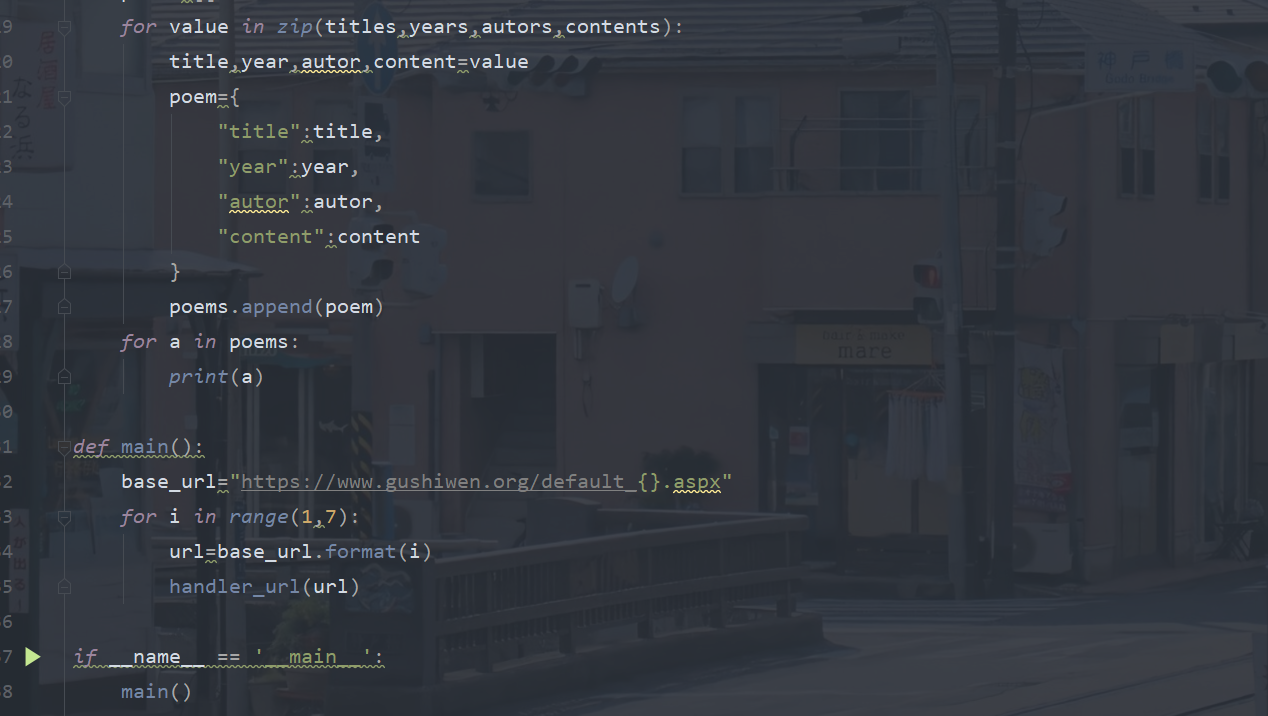
poems=[]
for value in zip(titles,years,autors,contents):
title,year,autor,content=value
poem={
"title":title,
"year":year,
"autor":autor,
"content":content
}
poems.append(poem)
for a in poems:
print(a)
def main():
base_url="https://www.gushiwen.org/default_{}.aspx"
for i in range(1,7):
url=base_url.format(i)
handler_url(url)
if __name__ == '__main__':
main()
2, Crawling popular books of Douban
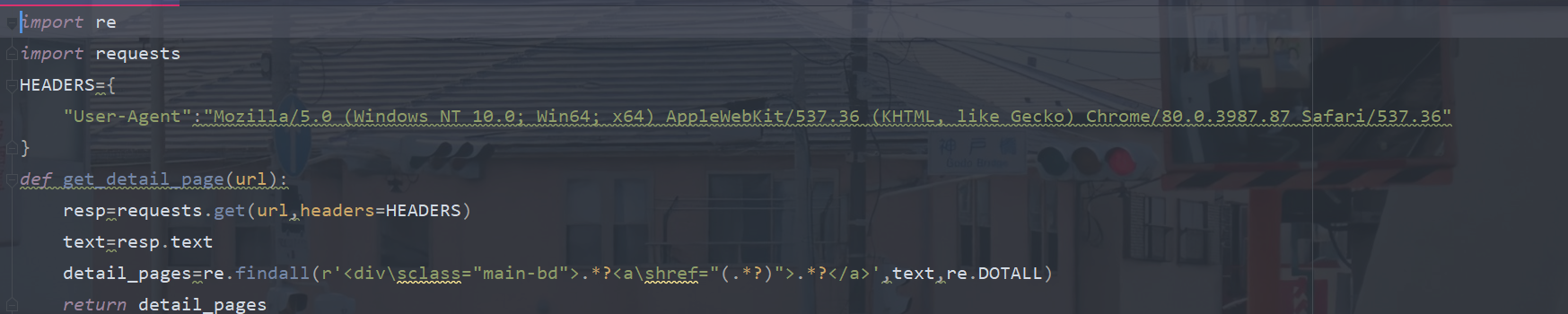
import re
import requests
HEADERS={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}
def get_detail_page(url):
resp=requests.get(url,headers=HEADERS)
text=resp.text
detail_pages=re.findall(r'<div\sclass="main-bd">.*?<a\shref="(.*?)">.*?</a>',text,re.DOTALL)
return detail_pages
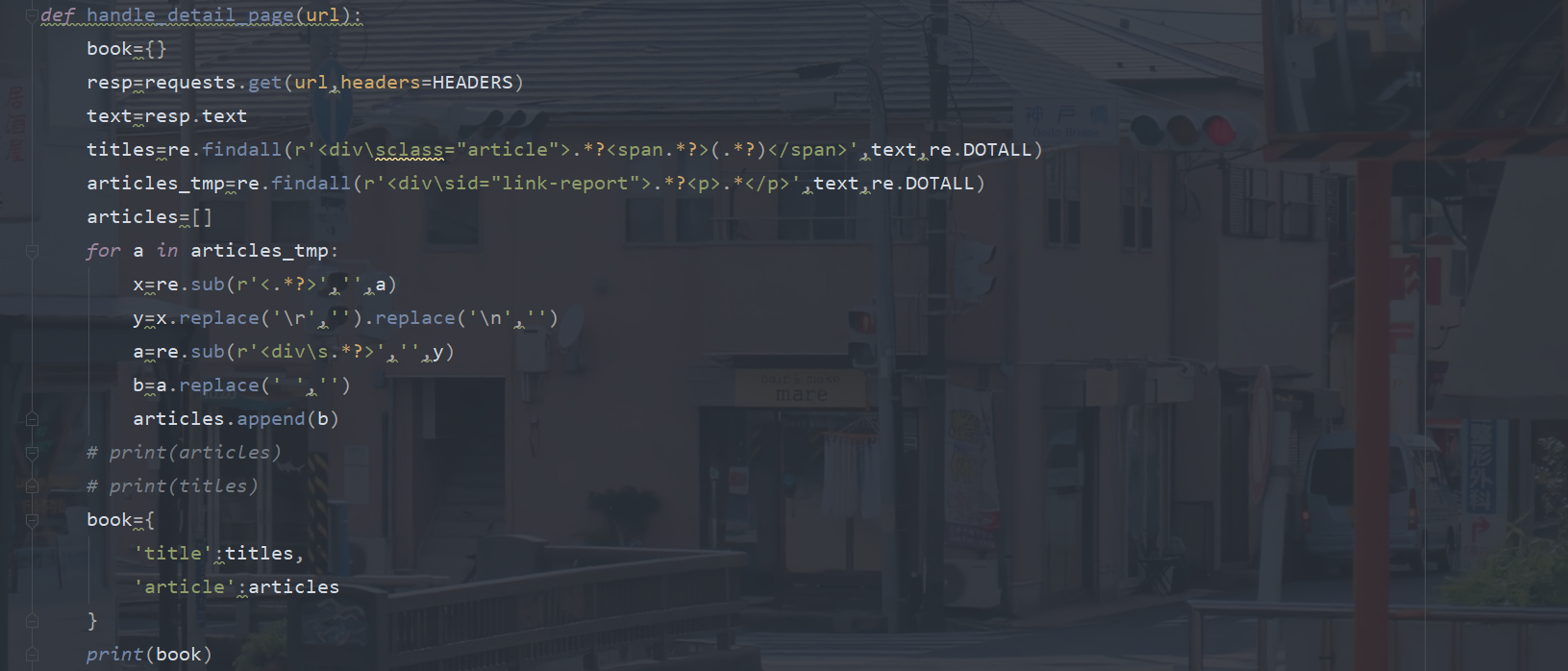
def handle_detail_page(url):
book={}
resp=requests.get(url,headers=HEADERS)
text=resp.text
titles=re.findall(r'<div\sclass="article">.*?<span.*?>(.*?)</span>',text,re.DOTALL)
articles_tmp=re.findall(r'<div\sid="link-report">.*?<p>.*</p>',text,re.DOTALL)
articles=[]
for a in articles_tmp:
x=re.sub(r'<.*?>','',a)
y=x.replace('\r','').replace('\n','')
a=re.sub(r'<div\s.*?>','',y)
b=a.replace(' ','')
articles.append(b)
# print(articles)
# print(titles)
book={
'title':titles,
'article':articles
}
print(book)
def main():
urls=[]
base_url="https://book.douban.com/review/best/?start={}"
for i in range(0,41,20):
url=base_url.format(i)
urls.append(url)
for a in urls:
detail_urls=get_detail_page(a)
for f in detail_urls:
handle_detail_page(f)
if __name__ == '__main__':
main()
Three. Conclusion
These two small crawler projects are not anti crawled on the website, so it is relatively simple for us to crawl out the page information. The key lies in how to parse the data. Recently, we have been looking at regular expressions, so we found two small projects to practice. These two small projects can also be performed using the beatifulsoup or xml library, and try other methods to parse again in time Data to ~