I regular expression
1. Concept of regular expression
Regular expression, also known as regular expression, is often abbreviated as regex, regexp or RE in code. It is a concept of computer science. Regular expressions are often used to retrieve and replace text that conforms to a pattern (rule).
There is not only one regular expression, and different programs in LINUX may use different regular expressions, such as: tool: grep sed awk egrep
There are two kinds of regular expression engine foundations commonly used in LINUX: regular expression: BRE # extended regular expression: ERE
Text processing tools in LINUX: grep, egrep, sed, awk
2. Regular expression tool grep
grep [options]... Find condition target file
-E: Turn on the regular expression of the extension
-c: Count the number of times' search string 'was found
-i: The case difference is ignored, so the case is considered the same
-o: Only the strings that are matched by the pattern are displayed
-v: Reverse selection, that is, the line without 'search string' content is displayed! (reverse search, output lines that do not match the search criteria)
--color=auto: you can add the color display to the key words you find!
-n: Output line number
Case list
① Count the total number of root characters; Then use cat /etc/passwd | grep root to check whether it is correct.
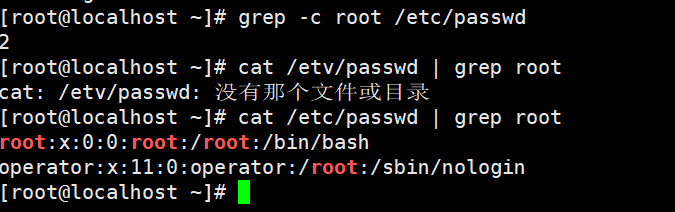
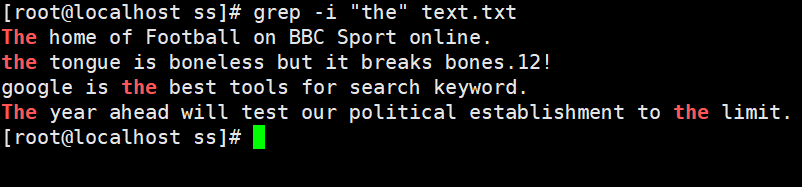
② find all the rows case insensitive.
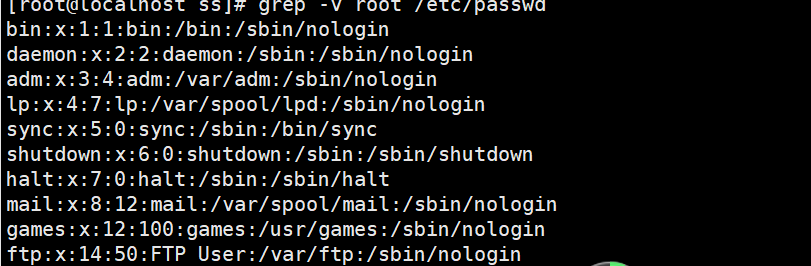
③ set / etc/passwd to take out the line without root.
④ The web Non empty lines in the SH file are written to test Txt file.
cat web.sh | grep -v '^$' > test.txt
⑤ Filter the local ip address.

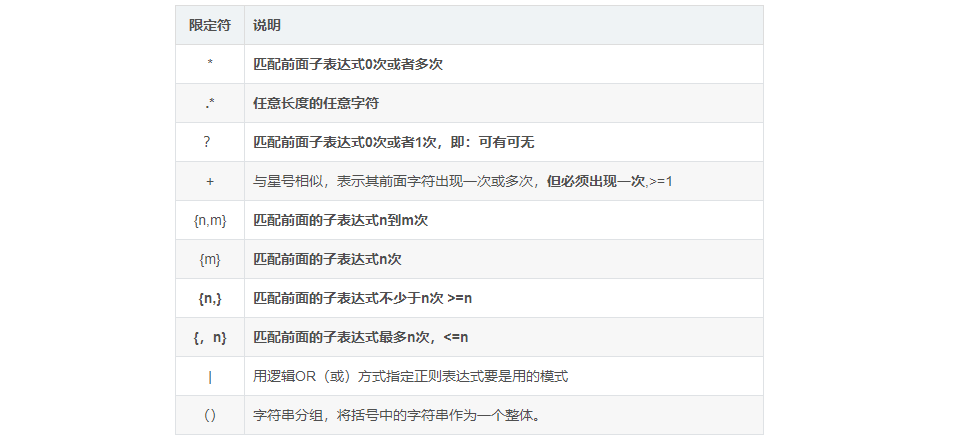
3. Common metacharacters (supported tools: find, grep, egrep, sed and awk)
| Metacharacter | effect |
| \ | Escape character, used to cancel the meaning of special symbols Example: \!, \n. \ $etc |
| ^ | Start of matching string Example: ^ a, "the,^#,^[a-z] |
| $ | Matches the end of the string Example: word $, ^ $matches blank lines |
| . | Match any character other than \ n Example: go d.g.. d |
| * | Match the front sub expression o times or more Example: goo * D, go* d |
| [list] | Match a character in the list Example: go[loa]d,[a-z],[o-9] matches any digit |
| [^list] | Match a character in any non list list Example: [^ 0-9] [^ A-Z] matches any non lowercase letter |
| \{n\} | Match the front sub expression n times Example: gol{2}d. '[0-9] \ {2}' matches two digits |
| \{n,\} | The matching front sub expression shall not be less than n times Example: gol {2,} d, '[O-9] \{2, good' matches two or more digits |
| \{n,m\} | Match the front sub expression n to m times Example: go\{2,3\}d,'[o-9] \ {2,3 \}' matches two to three digits |
| Note: when egrep and awk use {n]}, {n,}, {n, m} to match, there is no need to add "" \ "before" {} " | |
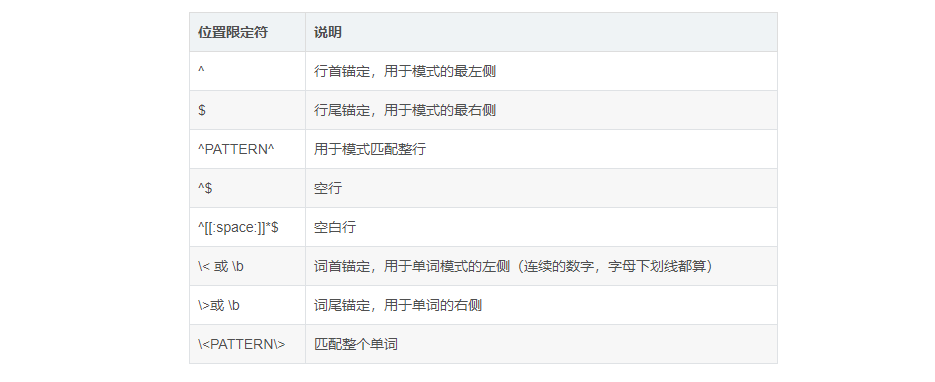
Locator ^ Matches the beginning of the input string $ Matches the position at the end of the input string Non printing character \n Match a newline character \r Match a carriage return \t Match a tab
Note: when egrep and awk use {n}, {n,}, {n,m} to match, "}" does not need to be added before "\“
egrep -E -n 'wo{2}d' test.txt1/-E is used to display qualified characters in the file
egrep -E -n 'wo{2,3}d' test.txt
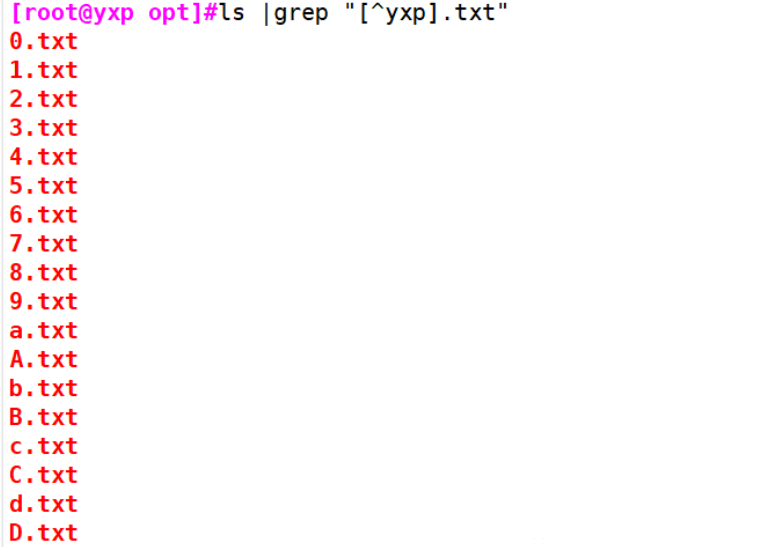
Example 1: [^]: indicates negative. Characters in the character class appear in parentheses and are reversed
[root@yxp opt]#ls |grep "[^yxp].txt" 0.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt a.txt .........Omitted later [root@yxp opt]#echo 12txt|grep "[^az].txt" 12txt

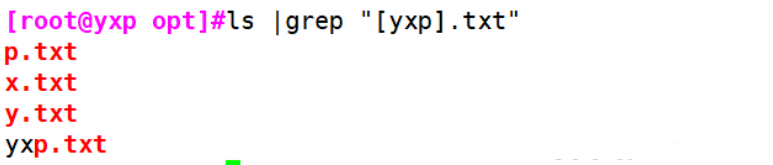
Example 2: [] matches a character in parentheses
#[yxp]
[root@yxp opt]#ls |grep "[yxp].txt"
p.txt
x.txt
y.txt
yxp.txt
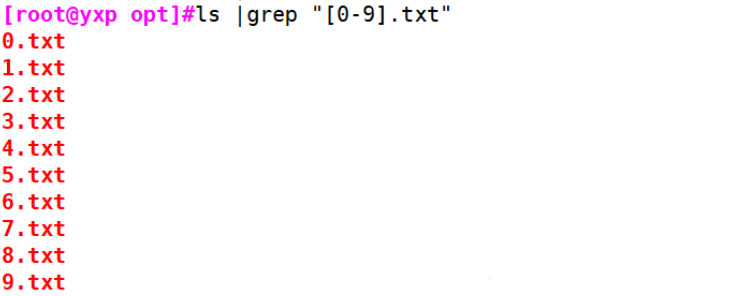
#[0-9]
[root@yxp opt]#ls |grep "[0-9].txt"
0.txt
1.txt
2.txt
3.txt
4.txt
5.txt
6.txt
7.txt
8.txt
9.txt
#{a..d}
[root@yxp aa]#touch {a..z}.txt
[root@yxp aa]#ls
a.txt e.txt i.txt m.txt q.txt u.txt y.txt
b.txt f.txt j.txt n.txt r.txt v.txt z.txt
c.txt g.txt k.txt o.txt s.txt w.txt
d.txt h.txt l.txt p.txt t.txt x.txt
#{A..Z}
[root@yxp bb]#touch {A..Z}.txt
[root@yxp bb]#ls
A.txt E.txt I.txt M.txt Q.txt U.txt Y.txt
B.txt F.txt J.txt N.txt R.txt V.txt Z.txt
C.txt G.txt K.txt O.txt S.txt W.txt
D.txt H.txt L.txt P.txt T.txt X.txt
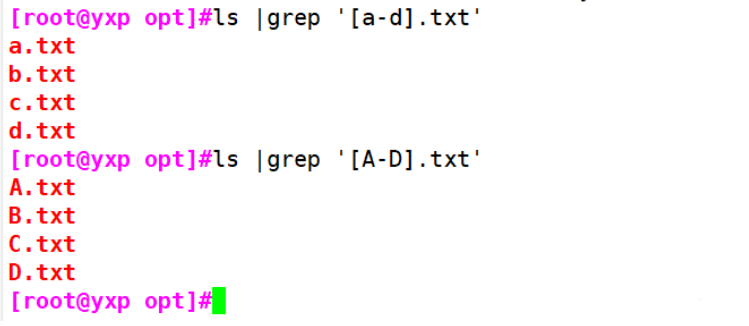
#[a-d]: including small a to small D, and capital words, except D
[root@yxp opt]#ls [a-d].txt
a.txt A.txt b.txt B.txt c.txt C.txt d.txt
##Just want to match lowercase (need to combine grep)
[root@yxp opt]#ls |grep '[a-d].txt'
a.txt
b.txt
c.txt
d.txt
#[A-D]: excluding small a
[root@yxp opt]#ls [A-D].txt
A.txt b.txt B.txt c.txt C.txt d.txt D.txt
##[A-D] just want to match uppercase
[root@yxp opt]#ls |grep '[A-D].txt'
A.txt
B.txt
C.txt
D.txt

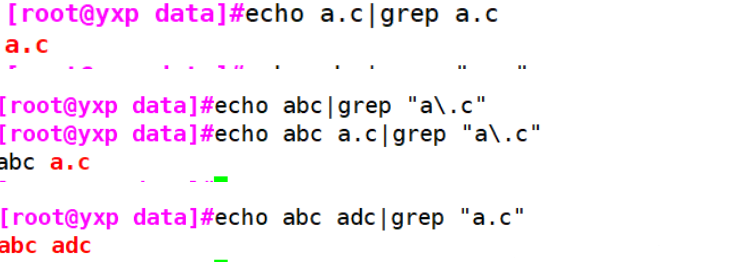
Example 3: Represents any character
#Represents any character [root@yxp data]#echo abc|grep "a.c" abc #The original point needs to be added \ escaped [root@yxp data]#echo abc|grep "a\.c" #Standard format needs to add '' or '' [root@yxp data]#echo abc a.c|grep "a\.c" abc a.c [root@yxp data]#echo abc adc|grep "a.c" abc adc
Example 4: [: alnum:] matches any letter and number
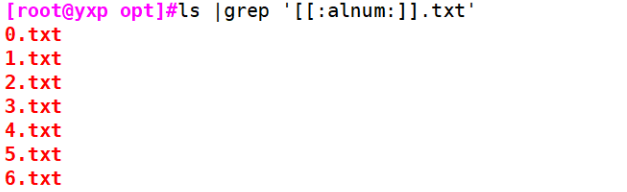
##Note: be sure to put another [] on the outside [root@yxp opt]#ls |grep '[[:alnum:]].txt' 0.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt
Example 5: metacharacter: (.)
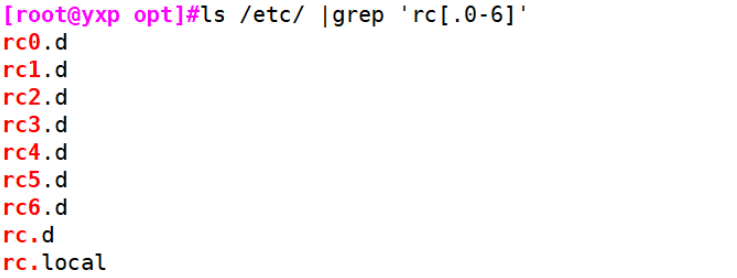
#//Indicates RC rc0 ... rc6 [root@yxp opt]#ls /etc/ |grep 'rc[.0-6]' rc0.d rc1.d rc2.d rc3.d rc4.d rc5.d rc6.d rc.d rc.local #r..t .. Represents any two characters [root@yxp opt]#grep "r..t" /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin

4. Extended regular expression
Supported tools: egrep, awk or grep -E and sed -r
Example 1: * match the front sub expression 0 or more times
[root@yxp opt]#echo google ggle|grep "go*gle" google ggle [root@yxp opt]#echo google ggle gggle|grep "go*gle" google ggle gggle
Example 2: {n,m} matches the previous subexpression n to m times
[root@yxp opt]#echo goooogle goole gggle|egrep "go{3,5}gle"
goooogle goole gggleThe preceding sub expression does not match less than n times, {n:}
[root@yxp opt]#echo goooogle gooogle gggle|egrep "go{3,}gle"
goooogle gooogle gggleExample 4: {, n} matches the previous subexpression up to N times, < = n
[root@yxp opt]#echo goooogle gooogle gggle|egrep "go{,3}gle"
goooogle gooogle gggleExample 5: * match the front sub expression 0 or more times
[root@yxp opt]#echo gggggggggggdadasgle|grep 'g*gle' gggggggggggdadasgle
Example 6:* Any character of any length
[root@yxp opt]#echo gggggggggggdadasgle|grep '.*gle' gggggggggggdadasgle
Example 7:? Match the front sub expression 0 or 1 times, that is, it is optional
[root@yxp opt]#echo goole gogle ggle|egrep "go?gle" goole gogle ggle
Example 8: + is similar to the asterisk, indicating that the character before it appears one or more times, but it must appear once, > = 1
[root@yxp opt]#echo google gogle ggle gooogle|egrep "go+gle" google gogle ggle gooogle
Example 9: | the logical OR (OR) method specifies the mode to be used by the regular expression
[root@yxp opt]#echo 1ee 1abc 2abc|egrep "1|2abc" 1ee 1abc 2abc
Example 10: () string grouping, taking the string in parentheses as a whole.
[root@yxp opt]#echo 1ee 1abc 2abc|egrep "(1|2)abc" 1ee 1abc 2abc
Example 11: extract ip address
#FA Yi
[root@yxp opt]#ifconfig ens33|grep "netmask"|grep -o -E "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}"|head -1
192.168.59.102
#Method 2: grouping is used
[root@yxp opt]#ifconfig ens33|grep "netmask"|egrep -o '([0-9]{1,3}.){3}[0-9]{1,3}'|head -1
192.168.59.102
5. Position anchoring
Example 1: end of line anchor for the rightmost side of the pattern
[root@yxp opt]#grep "bash$" /etc/passwd root:x:0:0:root:/root:/bin/bash yxp:x:1000:1000:yxp:/home/yxp:/bin/bash
Example 2: row head anchor, used for the leftmost side of the pattern
[root@yxp opt]#grep "^root" /etc/passwd root:x:0:0:root:/root:/bin/bash
Example 3: for pattern matching, the whole line is used, and the matching content is in a single line
[root@yxp opt]#echo root|grep "^root$" root
Example 4: \ <: match only the words on the right
[root@yxp opt]#echo hello-123|grep "\<123" hello-123
Example 5: \ >: match only the words on the left
[root@yxp opt]#echo hello-123 222|grep "hello\>" hello-123 222
Example 6: filter out non empty lines that do not start with #
[root@yxp opt]#grep "^[^#]" /etc/fstab /dev/mapper/centos-root / xfs defaults 0 0 UUID=183ca7c7-1989-4f43-9e81-d2676192f5a4 /boot xfs defaults 0 0 /dev/mapper/centos-home /home xfs defaults 0 0 /dev/mapper/centos-swap swap swap defaults 0 0 /dev/sdb1 /mnt xfs defaults 0 0
II Common pipeline commands
1.sort command
The sort command sorts the contents of a text file in behavioral units.
Format: sort [options] parameter
Common options:
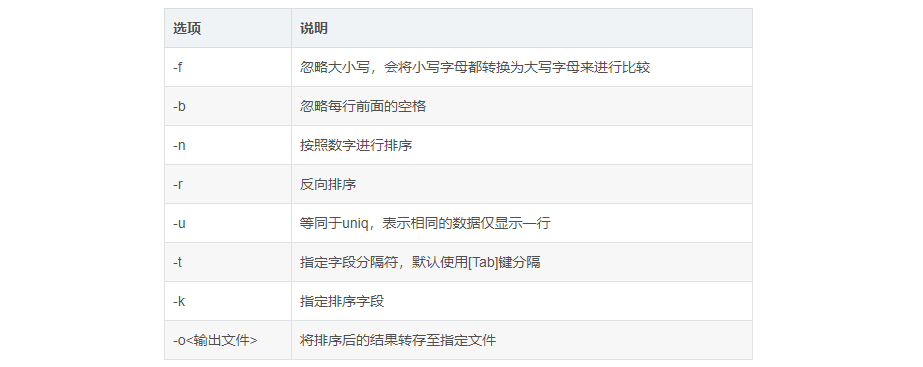
2.uniq command
The uniq command is used to check and delete repeated rows and columns in text files. It is generally used in combination with the sort command
Format: uniq [options] parameter
Common options:
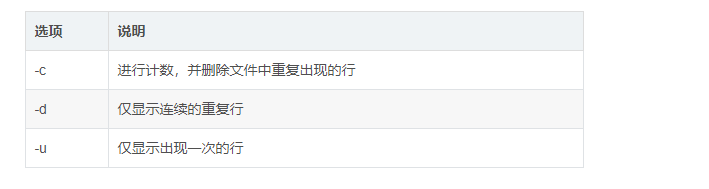
3.tr command
Commonly used to replace, compress, and delete characters from standard input.
Common options
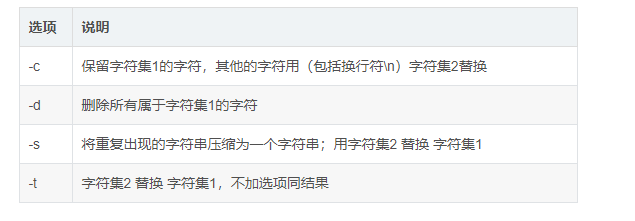
Common options
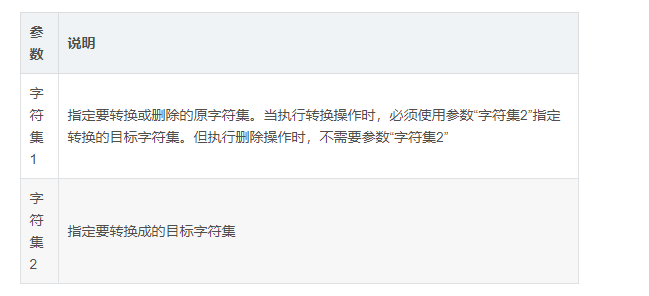
4.cut command
Displays the specified part of the line and deletes the specified field in the file
Format: cut [options] parameter
Common options
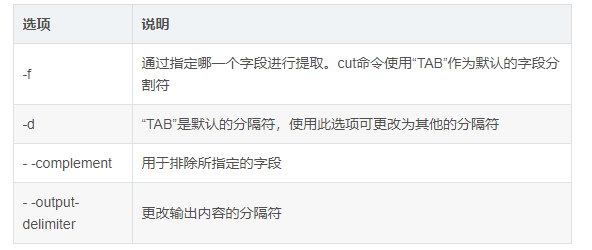
5. Examples
1. Count the current host connection status
[root@yxp data]#ss -ant|cut -d " " -f1|sort -n|uniq -c|head -2
2 ESTAB
13 LISTEN2. Count the number of currently connected hosts
[root@yxp opt]#ss -ant|tr -s " "|cut -d" " -f5|cut -d":" -f1|sort|uniq -c|tail -n +3
3 192.168.59.1
1 192.168.59.118
1 Address