gym is a toolkit for developing and comparing reinforcement learning algorithms under openAI. It internally provides the environment needed for reinforcement learning.
Official documents: https://gym.openai.com/docs/
gym library installation
I installed it under window
conda create -n gym pip install gym pip install pyglet
gym--hello world code
We refer to the official documentation to execute gym's "hello world" code.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
# take a random action
env.step(env.action_space.sample())
env.close()Run the above code. If there is an animation of the inverted pendulum problem, it shows that the gym library has been installed successfully, and we have run through the simplest hello world Code of gym.
Briefly introduce the main functions of the above code:
- env = gym.make('CartPole-v0 ') creates an environment for the cartpole problem, which will be described in detail below.
- env.reset() resets the environment to get the initial observation
- env.render() renders the UI of the object state. Here we call the rendering interface of gym, so we won't go into it
- env.action_space.sample() refers to randomly selecting an action from the action space
- env.step () refers to the action of selecting in the environment, where information such as reward will be returned
That is, first create an environment and reset the environment. Then cycle and iterate 1000 times. In each iteration, we select an action from the action space of the environment to execute and enter the next state.
When we implement our own algorithm, the most important thing is to select the action and strategy, that is, how to select the next action according to the current state.
gym instance -- CartPole
Through the above simple demo, you may not understand the whole environment, state space, state space and step return. This section will explain the demo in more detail.
Introduction to CartPole
First, we need to know what problem CartPole is trying to solve. CartPole is a problem of a trolley inverted pendulum. As shown in the figure below:
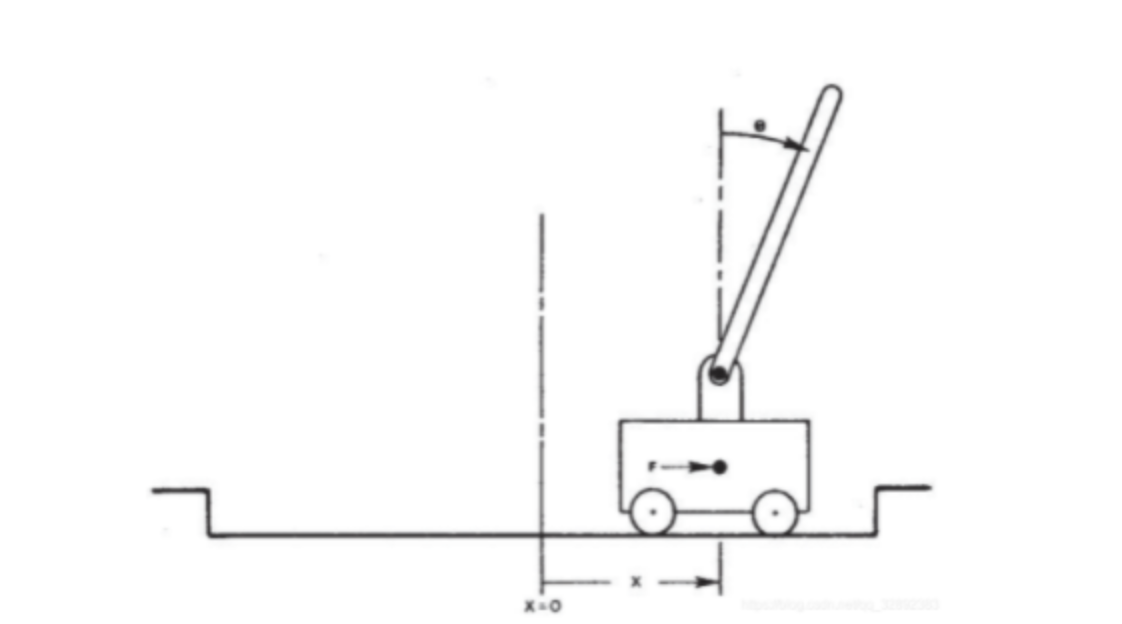
There is a rod on a trolley. With the movement of the trolley, the rod will tilt. When it tilts to a certain extent, the rod will fall due to gravity. Our goal is to keep the pole up and not fall. Therefore, it is necessary to give an execution action in each state of the rod to move the trolley to the left or right, so that the rod can maintain balance.
Introduction to CartPole environment
The state space and action space in the CartPole environment can be understood through the source code combined with our logs in the code.
CartPole class source code:
Print in the demo code to understand the data form:
print("env.action_space", env.action_space)
>> Discrete(2)The action space is a discrete data: the state space value {0,1}, 0 -- represents moving left, and 1 -- represents moving right
print("env.observation_space", env.observation_space)
>>Box(4,) The state space is a multi-dimensional space. The four dimensions respectively represent the position of the trolley on the track, the angle between the pole and the vertical direction, the trolley speed and the angle change rate.
Four values are returned for each step():
observation, reward, done, info = env.step(sample_action)
observation: current status value
Reward: reward 1 for each step
done: is this round of exploration over
info: debugging information
To re understand the demo logic, first initialize the environment observation (state), select an action, and then return to the observation after executing the action in the environment. The backward of each step is 1. When the rod falls down, done is False. The longer the rod goes up, the greater the backward.
The goal of our study is to keep the rod upright all the time. The rod will always tilt due to gravity. When the rod tilts to a certain extent, it will fall down. At this time, we need to move the rod to the left or right to ensure that it will not fall down.
The following code is a log expansion of the demo code to give us a fuller understanding of the CartPole-v0 environment.
import gym
# Create a CartPole-v0 (trolley inverted pendulum model)
env = gym.make('CartPole-v0')
for i_episode in range(1000):
# The environment is reset to get an initial observation
observation = env.reset()
for t in range(1000):
# The rendering engine displays the state of the object
env.render()
# Action space, {0,1} 0-move left, 1-move right
print("env.action_space", env.action_space)
# >>Discrete (2) a discrete space
# state space
print("env.observation_space", env.observation_space)
# >>Box (4,) multidimensional space
# Reward range and status space range
# print("env.reward_range", env.reward_range)
# print("env.observation_space.high", env.observation_space.high)
# print("env.observation_space.low", env.observation_space.low)
# print("env.observation_space.bounded_above", env.observation_space.bounded_above)
# print("env.observation_space.bounded_below", env.observation_space.bounded_below)
# Random selection action
sample_action = env.action_space.sample()
"""
observation: Currently observed object Status value of
Position of trolley on track, angle between pole and vertical direction, trolley speed, angle change rate)
reward: Execute previous action Post Award,Reward 1 for each step
done: Is this round of exploration over and needed reset environment
The segment ends when one of the following conditions is met:
The angle between the pole and the vertical direction is more than 12 degrees
The trolley position is more than 2 meters away from the center.4(Trolley Center (beyond the picture)
Consider fragment length over 200
Consider that the average reward for 100 consecutive attempts is greater than or equal to 195.
info: debug information
"""
observation, reward, done, info = env.step(sample_action)
print('observation:{}, reward:{}, done:{}, info:{}'.format(observation, reward, done, info))
# If it ends, exit the loop
if done:
print("Episode finished after {} timesteps".format(t + 1))
break
env.close()CartPole problem -- random guessing algorithm & Hill clipping algorithm
In the above code, the most important thing is how to use the sample in the learning process_ Action is modified to determine an appropriate action through policy. This paper introduces the simple strategy of random guessing algorithm & Hill clipping algorithm.
The value of the action selected by the policy is 0 or 1. observation is a four-dimensional vector. If the weighted sum of this vector is obtained, a value can be obtained, and then the action is determined according to the symbol of the weighted sum.
Random Guessing Algorithm is the value given randomly each time.
Hill clipping algorithm is to update the best weight obtained last time with a small random change.
The main process and logic are explained in the following code comments.
The main codes are as follows:
import numpy as np
import gym
import time
def get_action(weights, observation):
""" according to weights,yes observation Conduct weighted summation and determine the action strategy according to the value
"""
wxb = np.dot(weights[:4], observation) + weights[4]
if wxb >= 0:
return 1
else:
return 0
def get_sum_reward_by_weights(env, weights):
""" Calculate the cumulative cost of this exploration according to the current strategy reward
"""
observation = env.reset()
sum_reward = 0
for t in range(1000):
# time.sleep(0.01)
# env.render()
action = get_action(weights, observation)
observation, reward, done, info = env.step(action)
sum_reward += reward
if done:
break
return sum_reward
def get_weights_by_random_guess():
""" use Random Guessing Algorithm return weights, No round of random weight
"""
return np.random.rand(5)
def get_weights_by_hill_climbing(best_weights):
""" use hill_climbing Algorithm return weights, Add a little random change to the best weight each time
"""
return best_weights + np.random.normal(0, 0.1, 5)
def get_best_result(algo="random_guess"):
env = gym.make("CartPole-v0")
np.random.seed(10)
best_reward = 0
best_weights = np.random.rand(5)
# Conduct 100 rounds of exploration
for iter in range(10000):
# Selection strategy algorithm
if algo == "hill_climbing":
cur_weights = get_weights_by_hill_climbing(best_weights)
else:
cur_weights = get_weights_by_random_guess()
# Use the strategy weight obtained in this round of exploration to obtain the cumulative reward
cur_sum_reward = get_sum_reward_by_weights(env, cur_weights)
# Save the weight value corresponding to the best reward in the exploration process
if cur_sum_reward > best_reward:
best_reward = cur_sum_reward
best_weights = cur_weights
if best_reward >= 200:
break
print(iter, best_reward, best_weights)
return best_reward, best_weights
if __name__ == '__main__':
get_best_result("hill_climbing")reference material:
https://www.fashici.com/tech/836.html
Chinese women's football is awesome