Thanks hhh5460, the main code of this article refers to his blog, address: https://www.cnblogs.com/hhh5460/p/10143579.html
1. Problem setting
An 8x8 maze, compared with the original 6x6, has made a simple improvement.
The upper left corner entrance, the lower right corner exit (yellow square), the Red Square is the player, and the black square is the obstacle.

2. Train of thought analysis
The essence of reinforcement learning is to describe and solve the problem that agents learn strategies to maximize returns or achieve specific goals in the process of interacting with the environment. The interaction between agent and environment follows Markov decision.
The framework of agent reinforcement learning is:
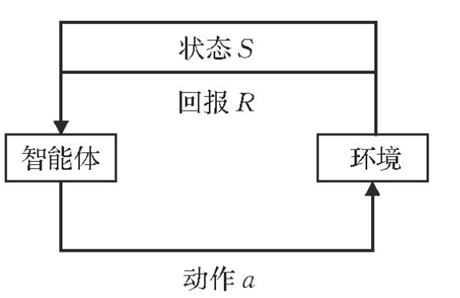
Therefore, we need to propose the definition of three sets:
State set (S): a set representing the state of an agent. In this paper, the state of an agent is the location of the agent. Specifically: [0,1,..., 63], a total of 64 states (positions).
Action set (A): represents the set of agent actions. In this paper, the action of agent only includes up, down, left and right. Specifically: ['u','d','l','r'], there are four actions in total.
R eward set: each location has a reward value. The agent needs to calculate the optimal path according to the sum of reward values reaching the end point. The reward value of blank grid is 0, the reward value of obstacle is - 10, and the end point reward is 10 Specifically: [0, - 10,0,0,..., 10], 64 in total.
3. Complete code
import pandas as pd
import random
import time
import pickle
import pathlib
import os
import tkinter as tk
'''
8*8 Maze of:
---------------------------------------------------------
| entrance | trap | | | | | | trap |
---------------------------------------------------------
| | trap | | | trap | | | trap |
---------------------------------------------------------
| | trap | | trap | | | | |
---------------------------------------------------------
| | trap | | trap | | | | |
---------------------------------------------------------
| | trap | | trap | | | trap | |
---------------------------------------------------------
| | | | | | | trap | |
---------------------------------------------------------
| | | | | | trap | trap | |
---------------------------------------------------------
| | trap | | | | trap | trap | Export |
---------------------------------------------------------
'''
class Maze(tk.Tk):
'''Environment class( GUI)'''
UNIT = 40 # pixels
MAZE_H = 8 # grid height
MAZE_W = 8 # grid width
def __init__(self):
'''initialization'''
super().__init__()
self.title('maze')
h = self.MAZE_H * self.UNIT
w = self.MAZE_W * self.UNIT
self.geometry('{0}x{1}'.format(h, w)) # Window size
self.canvas = tk.Canvas(self, bg='white', height=h, width=w)
# Draw grid
for c in range(0, w, self.UNIT):
self.canvas.create_line(c, 0, c, h)
for r in range(0, h, self.UNIT):
self.canvas.create_line(0, r, w, r)
# Draw obstacles
self._draw_rect(1, 0, 'black')
self._draw_rect(1, 1, 'black')
self._draw_rect(1, 2, 'black')
self._draw_rect(1, 3, 'black')
self._draw_rect(1, 4, 'black')
self._draw_rect(3, 2, 'black')
self._draw_rect(3, 3, 'black')
self._draw_rect(3, 4, 'black')
self._draw_rect(5, 6, 'black')
self._draw_rect(5, 7, 'black')
self._draw_rect(6, 4, 'black')
self._draw_rect(6, 5, 'black')
self._draw_rect(6, 6, 'black')
self._draw_rect(6, 7, 'black')
self._draw_rect(4, 1, 'black')
self._draw_rect(1, 7, 'black')
self._draw_rect(7, 0, 'black')
self._draw_rect(7, 1, 'black')
# Painting reward
self._draw_rect(7, 7, 'yellow')
# Draw player (save!!)
self.rect = self._draw_rect(0, 0, 'red')
self.canvas.pack() # Show painting!
def _draw_rect(self, x, y, color):
'''Draw a rectangle, x,y Horizontal representation,Vertical grid'''
padding = 5 # Inner margin 5px, see CSS
coor = [self.UNIT * x + padding, self.UNIT * y + padding, self.UNIT * (x + 1) - padding,
self.UNIT * (y + 1) - padding]
return self.canvas.create_rectangle(*coor, fill=color)
def move_to(self, state, delay=0.01):
'''The player moves to a new location according to the incoming status'''
coor_old = self.canvas.coords(self.rect) # Such as [5.0, 5.0, 35.0, 35.0] (upper left and lower right coordinates of the first grid)
x, y = state % 8, state // 8 # horizontal and vertical grids
padding = 5 # Inner margin 5px, see CSS
coor_new = [self.UNIT * x + padding, self.UNIT * y + padding, self.UNIT * (x + 1) - padding,
self.UNIT * (y + 1) - padding]
dx_pixels, dy_pixels = coor_new[0] - coor_old[0], coor_new[1] - coor_old[1] # Difference of vertex coordinates in the upper left corner
self.canvas.move(self.rect, dx_pixels, dy_pixels)
self.update() # tkinter built-in update!
time.sleep(delay)
class Agent(object):
'''Individual class'''
def __init__(self, alpha=0.1, gamma=0.9):
'''initialization'''
self.states = range(64) # State set. 0 ~ 35, 36 states in total
self.actions = list('udlr') # Action set. Up, down, left and right
self.rewards = [0, -10, 0, 0, 0, 0, 0, -10,
0, -10, 0, 0, -10, 0, 0, -10,
0, -10, 0, -10, 0, 0, 0, 0,
0, -10, 0, -10, 0, 0, 0, 0,
0, -10, 0, -10, 0, 0, -10, 0,
0, 0, 0, 0, 0, 0, -10, 0,
0, 0, 0, 0, 0, -10, -10, 0,
0, -10, 0, 0, 0, -10, -10, 10] # Reward set. Export reward 10, trap reward - 10.
self.hell_states = [1, 7, 9, 12, 15, 17, 19, 25, 27, 33, 35, 38, 46, 53, 54, 57, 61, 62] # Trap location
self.alpha = alpha
self.gamma = gamma
self.q_table = pd.DataFrame(data=[[0 for _ in self.actions] for _ in self.states],
index=self.states,
columns=self.actions) # Define Q-table
def save_policy(self):
'''preservation Q table'''
with open('q_table.pickle', 'wb') as f:
# Pickle the 'data' dictionary using the highest protocol available.
pickle.dump(self.q_table, f, pickle.HIGHEST_PROTOCOL)
def load_policy(self):
'''Import Q table'''
with open('q_table.pickle', 'rb') as f:
self.q_table = pickle.load(f)
def choose_action(self, state, epsilon=0.8):
'''Select the appropriate action. According to the current state, random or greedy, according to the parameters epsilon'''
# if (random.uniform(0,1) > epsilon) or ((self.q_table.ix[state] == 0).all()): # explore
if random.uniform(0, 1) > epsilon: # explore
action = random.choice(self.get_valid_actions(state))
else:
# action = self.q_table.ix[state].idxmax() # When there are multiple maximum values, the first one will be locked!
# action = self.q_table.ix[state].filter(items=self.get_valid_actions(state)).idxmax() # Major improvements! But the goose is the same as above
s = self.q_table.loc[state].filter(items=self.get_valid_actions(state))
action = random.choice(s[s == s.max()].index) # Select one randomly from the maximum values that may have multiple values!
return action
def get_q_values(self, state):
'''Take the given state state All of Q value'''
q_values = self.q_table.loc[state, self.get_valid_actions(state)]
return q_values
def update_q_value(self, state, action, next_state_reward, next_state_q_values):
'''to update Q value,According to Behrman equation'''
self.q_table.loc[state, action] += self.alpha * (
next_state_reward + self.gamma * next_state_q_values.max() - self.q_table.loc[state, action])
def get_valid_actions(self, state):
'''
Get the legal action set in the current state
global reward
valid_actions = reward.ix[state, reward.ix[state]!=0].index
return valid_actions
'''
valid_actions = set(self.actions)
if state % 8 == 7: # Last column, then
valid_actions -= set(['r']) # No right movement
if state % 8 == 0: # The first column, then
valid_actions -= set(['l']) # Remove the action to the left
if state // 8 = = 7: # last line, then
valid_actions -= set(['d']) # No down
if state // 8 = = 0: # the first line, then
valid_actions -= set(['u']) # No upward
return list(valid_actions)
def get_next_state(self, state, action):
'''After the action is performed on the state, the next state is obtained'''
# u,d,l,r,n = -6,+6,-1,+1,0
if state % 8 != 7 and action == 'r': # Right (+ 1) except the last column
next_state = state + 1
elif state % 8 != 0 and action == 'l': # All but the first column can be left (- 1)
next_state = state - 1
elif state // 8 != 7 and action = ='d ': # except the last line, it can be down (+ 2)
next_state = state + 8
elif state // 8 != 0 and action == 'u': # except the first line, you can go up (- 2)
next_state = state - 8
else:
next_state = state
return next_state
def learn(self, env=None, episode=1000, epsilon=0.8):
'''q-learning algorithm'''
print('Agent is learning...')
for i in range(episode):
"""Start from the leftmost position"""
current_state = self.states[0]
if env is not None: # If an environment is provided, reset it!
env.move_to(current_state)
while current_state != self.states[-1]: # Randomly (or greedily) select one of the current legal actions as the current action
current_action = self.choose_action(current_state, epsilon) # Choose randomly or greedily according to a certain probability
'''Execute the current action to get the next status (position)'''
next_state = self.get_next_state(current_state, current_action)
next_state_reward = self.rewards[next_state]
'''Remove all the in a state Q-value,The maximum value to be taken'''
next_state_q_values = self.get_q_values(next_state)
'''Updated according to Behrman equation Q-table Current status in-Action corresponding Q-value'''
self.update_q_value(current_state, current_action, next_state_reward, next_state_q_values)
'''Enter the next state (position'''
current_state = next_state
# if next_state not in self.hell_states: # If it is not a trap, move forward; Otherwise stay in place
# current_state = next_state
if env is not None: # If the environment is provided, update it!
env.move_to(current_state)
print(i)
print('\nok')
def test(self):
'''test agent Is smart already available'''
count = 0
current_state = self.states[0]
while current_state != self.states[-1]:
current_action = self.choose_action(current_state, 1.) # 1. Greed
next_state = self.get_next_state(current_state, current_action)
current_state = next_state
count += 1
if count > 64: # If you don't get out of the maze within 36 steps
return False # No intelligence
return True # Intelligent
def play(self, env=None, delay=0.5):
'''Play games and use strategies'''
assert env != None, 'Env must be not None!'
if not self.test(): # If there is no intelligence, then
if pathlib.Path("q_table.pickle").exists():
self.load_policy()
else:
print("I need to learn before playing this game.")
self.learn(env, episode=1000, epsilon=0.8)
self.save_policy()
print('Agent is playing...')
current_state = self.states[0]
env.move_to(current_state, delay)
while current_state != self.states[-1]:
current_action = self.choose_action(current_state, 1.) # 1. Greed
next_state = self.get_next_state(current_state, current_action)
current_state = next_state
env.move_to(current_state, delay)
print('\nCongratulations, Agent got it!')
if __name__ == '__main__':
env = Maze() # environment
agent = Agent() # Individual (agent)
agent.learn(env, episode=100, epsilon=0.8) # Learn first
agent.save_policy()
agent.load_policy()
agent.play(env) # outro
# env.after(0, agent.learn, env, 1000, 0.8) # Learn first
# env.after(0, agent.save_policy) # Save what you have learned
# env.after(0, agent.load_policy) # Import what you have learned
# env.after(0, agent.play, env) # Play again
# env.mainloop()4. summary
Compared with the reference articles, there are still some problems when running the code directly.
Question 1: jump out error:
Solution: Baidu learned that after pandas version 1.0.0, the function has been upgraded and reconstructed. Change ix to loc.
Question 2: when solving question 1, baidu got the wrong answer. At that time, it changed ix to iloc and jumped out of the error
Solution: change iloc to loc ~ the reason for this problem is the problem of index function. The specific reason is in https://blog.csdn.net/weixin_35888365/article/details/113986290
Question 3: when modifying the 6 * 6 maze, I modified the size of the state set, get_ valid_ The actions function modifies the corresponding value. When running, it is found that the agent frantically hits the wall when exploring, ignores the obstacles, directly passes through, and "crosses the end point but does not enter" in the final real maze process. It keeps passing by the end point but turns back and starts wandering around the map.
Solution: at this time, I found that due to my negligence, I wrote several more zeros in the reward set in the article, resulting in the non-standard writing of the reward set. Moreover, the obstacle location is not modified with the update of the map.
Question 4: in the final maze walking process, the intelligent experience moves forward a few steps and then reverses, which is similar to wandering like walking 4 and retreating 3
Solution: after troubleshooting, it is found that the number of explorations is too small and the experience value is insufficient. After changing the exploration value to 100 or more, the effect is significantly improved.