Python wechat ordering applet course video
https://edu.csdn.net/course/detail/36074
Python actual combat quantitative transaction financial management system
https://edu.csdn.net/course/detail/35475
background
Recently, a self-developed Dubbo registration center in charge often received alarms about CPU utilization, so it carried out a wave of optimization with good results. Therefore, it plans to share the thinking and optimization process, hoping to help you.
I'll draw a sketch of what the Dubbo registration center is. Just feel it a little. It doesn't matter if you can't understand it. It doesn't affect the subsequent understanding.
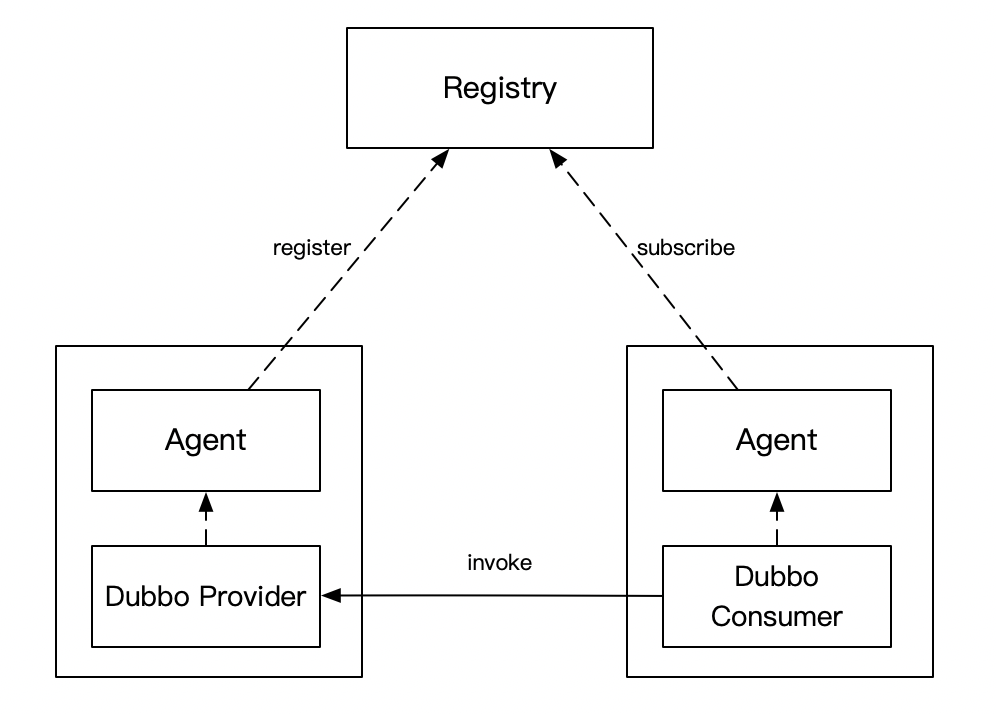
- The service discovery requests (registration, logout and subscription) of the Consumer and Provider are sent to the Agent, which is the sole Agent
- Registry and Agent maintain a long Grpc link. The purpose of the long link is to push the change of the Provider to the corresponding Consumer in time. In order to ensure the correctness of the data, a push-pull mechanism is adopted. The Agent will pull the subscribed service list from the registry at regular intervals
- Agent s and business services are deployed on the same machine, similar to the idea of Service Mesh, to minimize business intrusion, so that they can iterate quickly
Back to today's focus, the CPU utilization of this registry has been at a medium high level for a long time. Occasionally, applications are released, and the CPU will even be full when there is a large amount of push.
I didn't feel it before because there are not many connected applications. In recent months, more and more applications have been connected, and slowly reached the alarm threshold.
Find optimization points
Since this project was written by Go (it doesn't matter if you don't understand Go. This article focuses on algorithm optimization, not on the use of tools), it's still very simple to find out where to consume CPU: open pprof and Go online to collect for a period of time.
Please refer to my previous for specific operation This article , the knowledge and tools used in today's article can be found in this article.
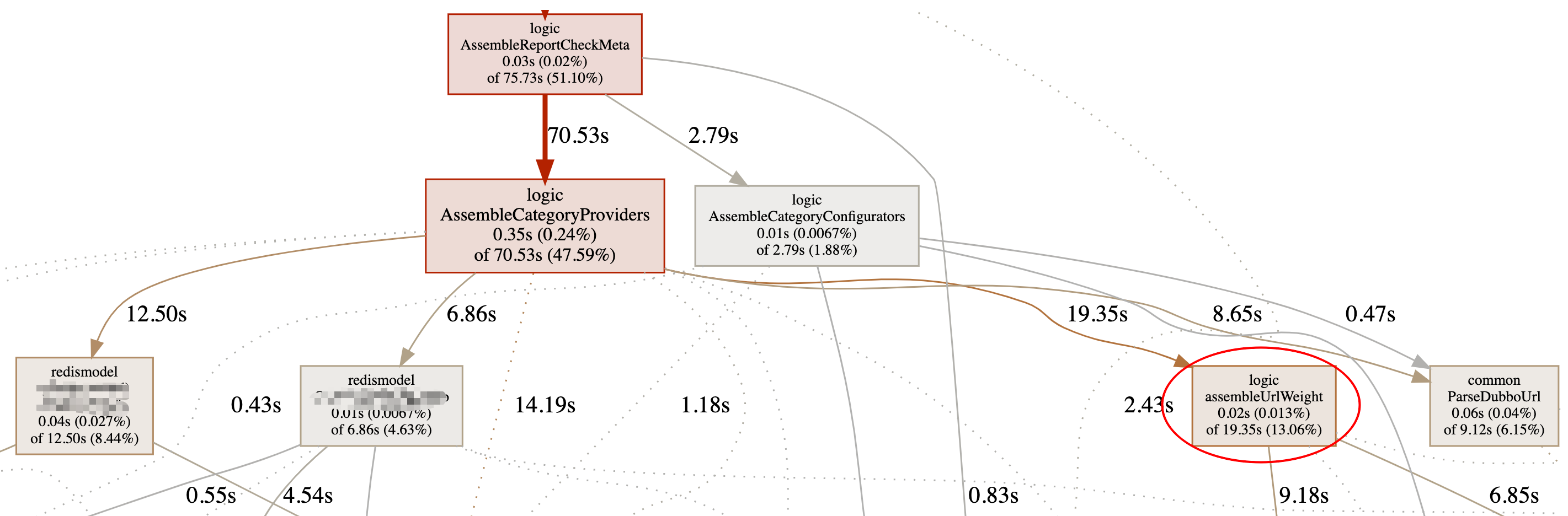
The CPU profile cuts a part of the diagram, and others are not very important. You can see that the assemblycategoryproviders method consumes more CPU, which is directly related to it
- 2 redis related methods
- A method called assemblyurlweight
For a little explanation, the assemblycategoryproviders method is to construct the url that returns the Dubbo provider. Because some processing will be done on the url when it is returned (such as adjusting the weight, etc.), it will involve the parsing of the Dubbo url. In addition, due to the push-pull mode, the more online service users, the larger the QPS of this process, so it is not surprising that it occupies most of the CPU.
These two redis operations may be that serialization takes up CPU. The larger part is in assemblyurlweight, which is a little unclear.
Next, let's analyze how to optimize assemblyurlweight. Because it occupies the most CPU, the optimization effect must be the best.
The following is the pseudo code of assemblyurlweight:
func AssembleUrlWeight(rawurl string, lidcWeight int) string {
u, err := url.Parse(rawurl)
if err != nil {
return rawurl
}
values, err := url.ParseQuery(u.RawQuery)
if err != nil {
return rawurl
}
if values.Get("lidc\_weight") != "" {
return rawurl
}
endpointWeight := 100
if values.Get("weight") != "" {
endpointWeight, err = strconv.Atoi(values.Get("weight"))
if err != nil {
endpointWeight = 100
}
}
values.Set("weight", strconv.Itoa(lidcWeight*endpointWeight))
u.RawQuery = values.Encode()
return u.String()
}
The parameter rawurl is the url of the Dubbo provider, and lidcWeight is the weight of the computer room. According to the configured machine room weight, recalculate the weight in the url to realize the distribution of multi machine room traffic according to the weight.
This process involves the resolution of url parameters, the calculation of weight, and finally restore to a url
Dubbo's url structure is consistent with the ordinary url structure, which is characterized by many parameters without # subsequent fragments.

The CPU is mainly consumed in these two parsing and the final restore. We see that the purpose of these two parsing is to get the LIDC in the url_ Weight and weight parameters.
url.Parse and URL Parsequery is an official library provided by Go and implemented in various languages. Its core is to parse the URL into an object to easily obtain all parts of the URL.
If you understand the concept of information entropy, in fact, you probably know that it must be optimized. Shannon referred to the concept of thermodynamics and called the average amount of information after eliminating redundancy in information as information entropy.

url.Parse and URL Parsequery must have redundancy in parsing in this scenario, which means that the CPU is doing redundant things.
Because there are usually many parameters for a Dubbo url, we only need to take these two parameters, and the URL Parse parses all the parameters.
For example, given an array, find the maximum value. If you sort the array first and then get the maximum value, it is obvious that there is redundant operation.
The sorted array can not only take the maximum value, but also take the second largest value, the third largest value... The minimum value. There is redundancy in the information, so sorting first is definitely not the optimal solution for the maximum value.
optimization
Optimize the performance of obtaining url parameters
The first idea is not to parse all URLs, but only take the corresponding parameters, which is very similar to the algorithm problem we wrote, such as obtaining the weight parameter. It can only be in these two cases (it doesn't exist #, so it's much simpler):
- dubbo://127.0.0.1:20880/org.newboo.basic.MyDemoService?weight=100&...
- dubbo://127.0.0.1:20880/org.newboo.basic.MyDemoService?xx=yy&weight=100&...
Either & weight =, or? Weight =, the end is either &, or directly to the end of the string. The code is easy to write. First write an algorithm for parsing parameters:
func GetUrlQueryParam(u string, key string) (string, error) {
sb := strings.Builder{}
sb.WriteString(key)
sb.WriteString("=")
index := strings.Index(u, sb.String())
if (index == -1) || (index+len(key)+1 > len(u)) {
return "", UrlParamNotExist
}
var value = strings.Builder{}
for i := index + len(key) + 1; i < len(u); i++ {
if i+1 > len(u) {
break
}
if u[i:i+1] == "&" {
break
}
value.WriteString(u[i : i+1])
}
return value.String(), nil
}
The original method of obtaining parameters can be extracted:
func getParamByUrlParse(ur string, key string) string {
u, err := url.Parse(ur)
if err != nil {
return ""
}
values, err := url.ParseQuery(u.RawQuery)
if err != nil {
return ""
}
return values.Get(key)
}
First benchmark these two functions:
func BenchmarkGetQueryParam(b *testing.B) {
for i := 0; i < b.N; i++ {
getParamByUrlParse(u, "anyhost")
getParamByUrlParse(u, "version")
getParamByUrlParse(u, "not\_exist")
}
}
func BenchmarkGetQueryParamNew(b *testing.B) {
for i := 0; i < b.N; i++ {
GetUrlQueryParam(u, "anyhost")
GetUrlQueryParam(u, "version")
GetUrlQueryParam(u, "not\_exist")
}
}
Benchmark results are as follows:
BenchmarkGetQueryParam-4 103412 9708 ns/op BenchmarkGetQueryParam-4 111794 9685 ns/op BenchmarkGetQueryParam-4 115699 9818 ns/op BenchmarkGetQueryParamNew-4 2961254 409 ns/op BenchmarkGetQueryParamNew-4 2944274 406 ns/op BenchmarkGetQueryParamNew-4 2895690 405 ns/op
You can see that the performance has been improved by more than 20 times
The newly written method has two small details. First, whether the parameter exists is distinguished in the return value, which will be used later; The second is the string operation, which uses strings Builder, which is also the result of the actual test, uses + or FMT The performance of springf is not as good as this. If you are interested, you can test it.
Optimize url write parameter performance
After calculating the weight, write the weight into the url. Here is the optimized code:
func AssembleUrlWeightNew(rawurl string, lidcWeight int) string {
if lidcWeight == 1 {
return rawurl
}
lidcWeightStr, err1 := GetUrlQueryParam(rawurl, "lidc\_weight")
if err1 == nil && lidcWeightStr != "" {
return rawurl
}
var err error
endpointWeight := 100
weightStr, err2 := GetUrlQueryParam(rawurl, "weight")
if weightStr != "" {
endpointWeight, err = strconv.Atoi(weightStr)
if err != nil {
endpointWeight = 100
}
}
if err2 != nil { // weight does not exist in url
finUrl := strings.Builder{}
finUrl.WriteString(rawurl)
if strings.Contains(rawurl, "?") {
finUrl.WriteString("&weight=")
finUrl.WriteString(strconv.Itoa(lidcWeight * endpointWeight))
return finUrl.String()
} else {
finUrl.WriteString("?weight=")
finUrl.WriteString(strconv.Itoa(lidcWeight * endpointWeight))
return finUrl.String()
}
} else { // weight in url
oldWeightStr := strings.Builder{}
oldWeightStr.WriteString("weight=")
oldWeightStr.WriteString(weightStr)
newWeightStr := strings.Builder{}
newWeightStr.WriteString("weight=")
newWeightStr.WriteString(strconv.Itoa(lidcWeight * endpointWeight))
return strings.ReplaceAll(rawurl, oldWeightStr.String(), newWeightStr.String())
}
}
It is mainly divided into two cases to discuss whether there is weight in the url:
- If the weight parameter does not exist in the url itself, a weight parameter should be spliced directly after the url. Of course, pay attention to whether it exists?
- If the weight parameter exists in the url itself, the string is replaced directly
Careful, you must have found that when lidcWeight = 1, it returns directly, because when lidcWeight = 1, the subsequent calculations actually don't work (Dubbo weight is 100 by default). Simply don't operate and save CPU.
After all optimization, make a benchmark:
func BenchmarkAssembleUrlWeight(b *testing.B) {
for i := 0; i < b.N; i++ {
for _, ut := range []string{u, u1, u2, u3} {
AssembleUrlWeight(ut, 60)
}
}
}
func BenchmarkAssembleUrlWeightNew(b *testing.B) {
for i := 0; i < b.N; i++ {
for _, ut := range []string{u, u1, u2, u3} {
AssembleUrlWeightNew(ut, 60)
}
}
}
The results are as follows:
BenchmarkAssembleUrlWeight-4 34275 33289 ns/op BenchmarkAssembleUrlWeight-4 36646 32432 ns/op BenchmarkAssembleUrlWeight-4 36702 32740 ns/op BenchmarkAssembleUrlWeightNew-4 573684 1851 ns/op BenchmarkAssembleUrlWeightNew-4 646952 1832 ns/op BenchmarkAssembleUrlWeightNew-4 563392 1896 ns/op
The performance is improved by about 18 times, and this may still be relatively poor. If the incoming lidcWeight = 1, the effect is better.
effect
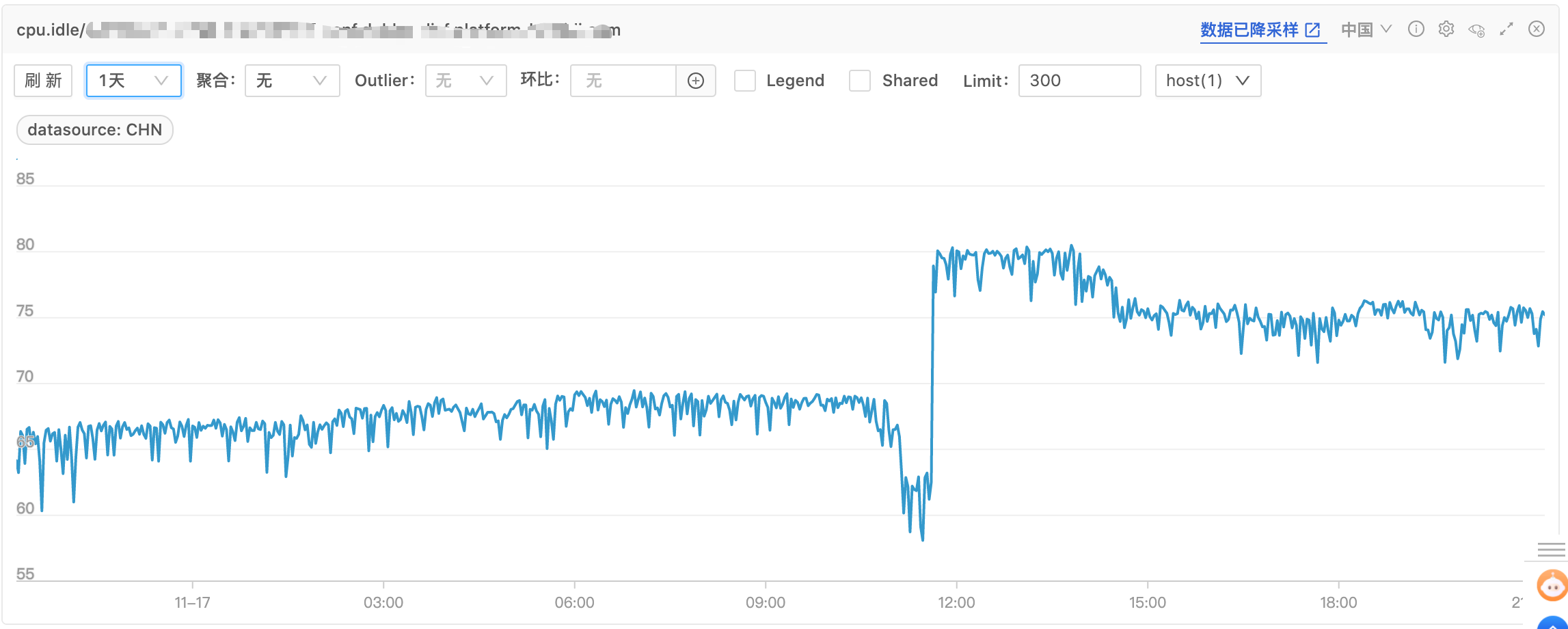
After the optimization, the corresponding unit test was written for the changed method. After confirming that there was no problem, the system went online for observation, and the CPU Idle rate increased by more than 10%
last
In fact, this article shows a very routine performance optimization of a Go program, which is relatively simple. After reading it, you may have some questions:
- Why parse URLs when pushing and pulling? Can't you calculate it in advance and save it?
- Why only this point is optimized? Can other points also be optimized?
For the first question, in fact, this is a historical problem. When you take over the system, it is like this. If there is a problem with the program, you can change the whole mechanism, which may take a long period and be prone to problems
The second question, in fact, has just been answered in passing. In this way, the change is the smallest and the income is the largest. Other points are not so easy to change. In the short term, the income is the most important. Of course, we plan to reconstruct the system later, but before reconstruction, such optimization is enough to solve the problem.