Recently, I wanted to change a couple's Avatar with my girlfriend. After looking around, I finally found some attractive ones in Xiaohong book. When saving the pictures, I found that there was no download button for a long time!!!
Can you share it? Copy the sharing link and open it in the browser. In this way, you can save the picture, but the picture is watermarked.
Can I download the watermarked image?
I went to the Internet for a simple search, but I found a lot of small programs to watermark, but almost all of them are limited to free use times. They are not allowed to be used after parsing several times. They have to be charged or something. As a crawler programmer, can I bear it?
Since they can directly analyze waterless pictures through the sharing link of Xiaohong book, theoretically speaking, I can also!
If you don't talk much, just do what you say.
1. Train of thought analysis
First, click share in xiaohongshu APP to get its link sharing, such as: https://www.xiaohongshu.com/discovery/item/60a5f16f0000000021034cb4
Then open it in the browser (I use chrome browser).
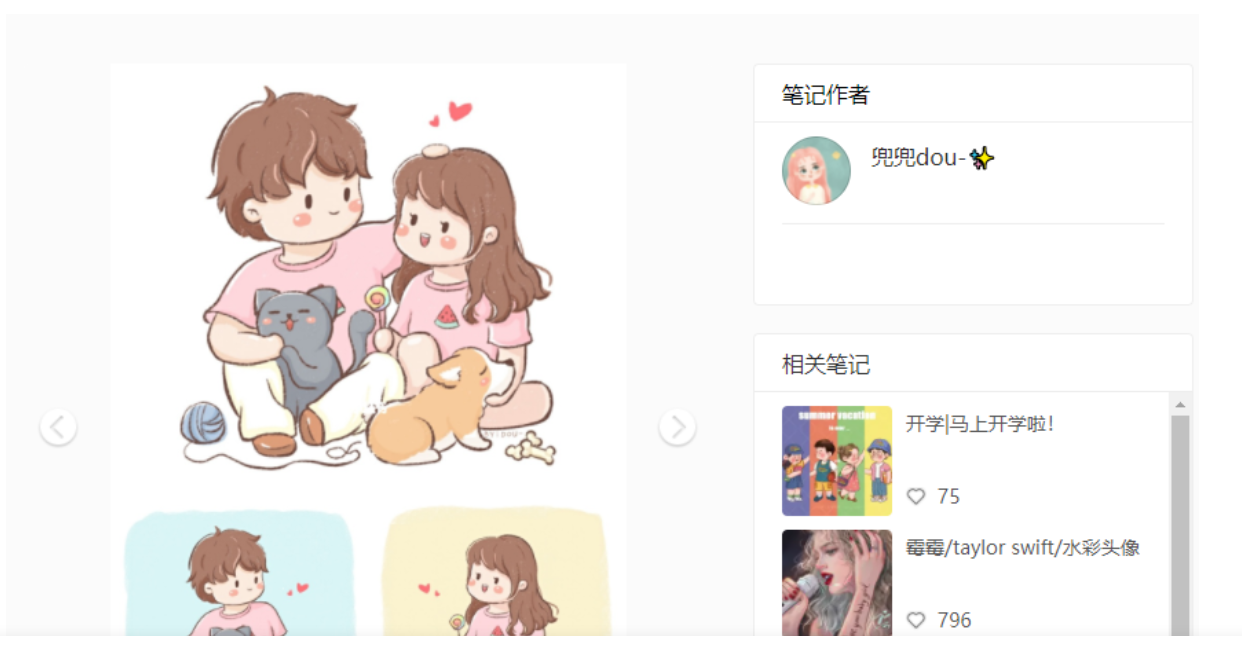
Press F12 or Ctrl + shift + i to open the developer tool, switch to the Network type, and select Img as the filter, as shown in the figure,
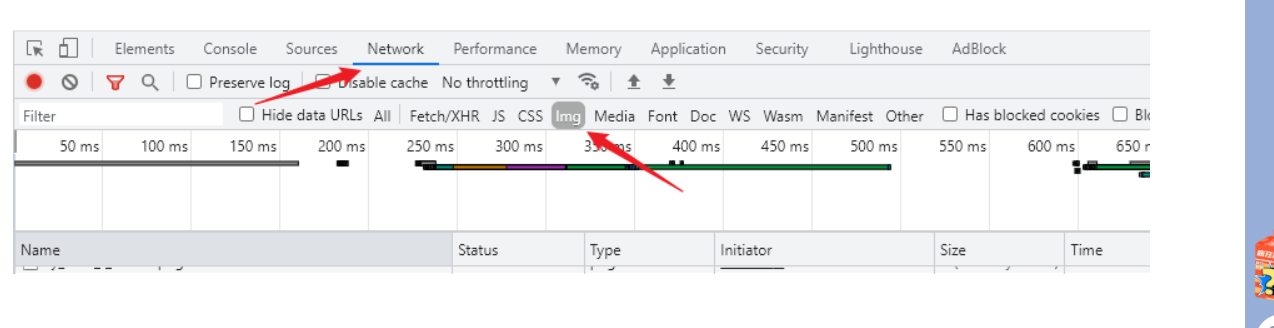
Refresh the web page, you can easily extract the links to the pictures we want.
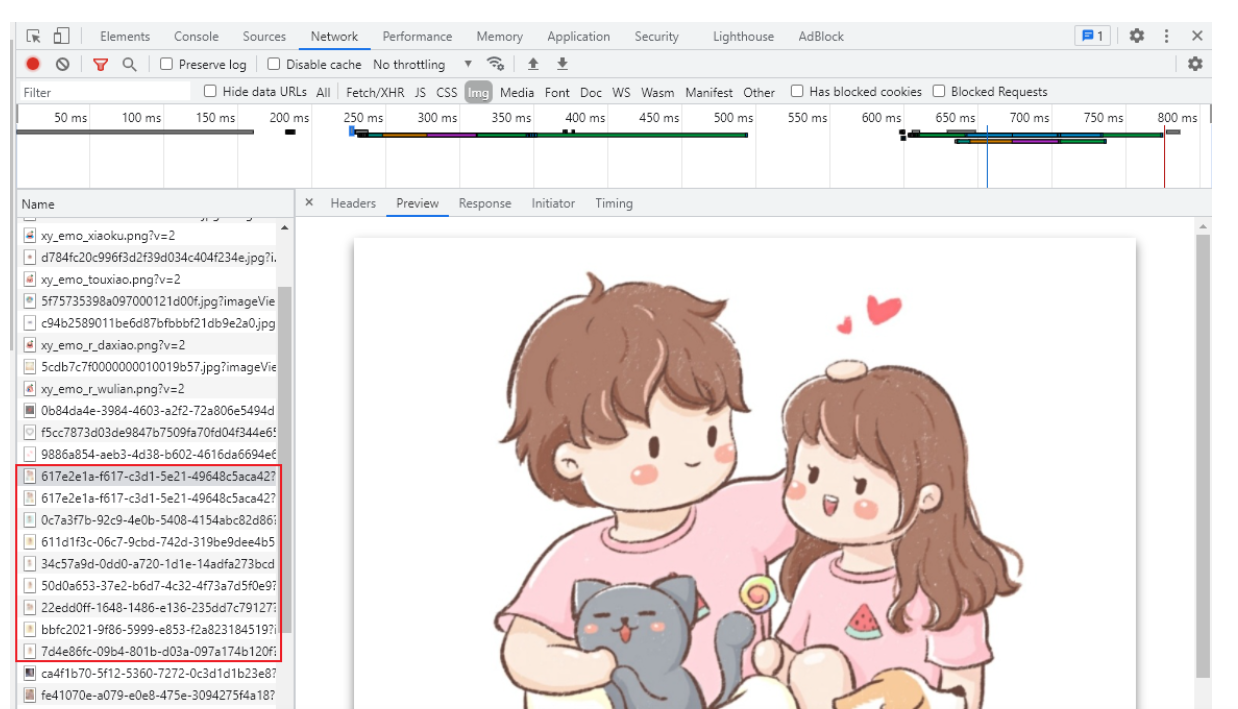
You can Preview the picture in Preview and view the request header information of the picture in Headers.
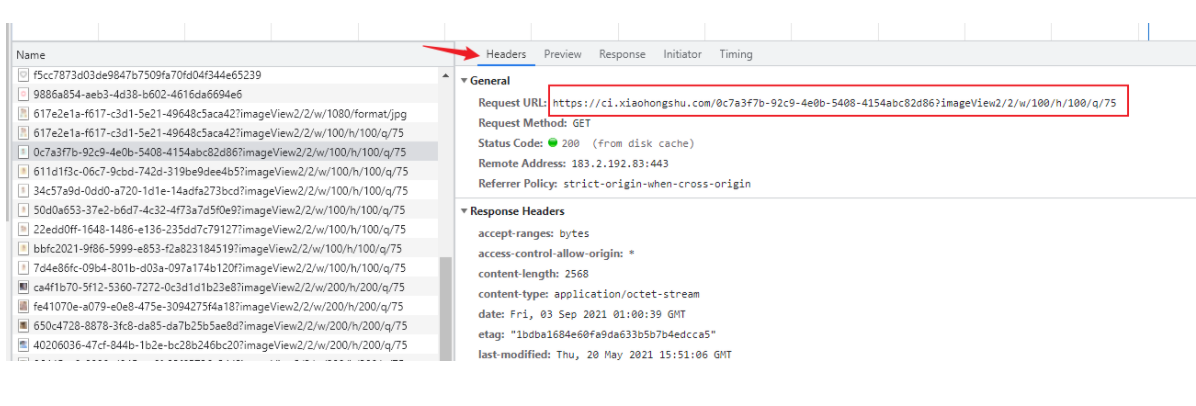
As shown in the figure above, you can know the download link of the picture.
https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86?imageView2/2/w/100/h/100/q/75
Simple analysis, the link consists of the following parts, domain name( https://ci.xiaohongshu.com/ )+ picture id(0c7a3f7b-92c9-4e0b-5408-4154abc82d86) ++ Compressed format (imageView2/2/w/100/h/100/q/75).
Tips: direct access in browser https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86?imageView2/2/w/100/h/100/q/75 The download interface will pop up; And get rid of it? Later, visit https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86 The picture opens in the browser.

Through the above link, we found that the pictures downloaded directly have watermarks. How can we get the pictures without watermarks?
Let's continue our analysis.
We already know that the image link is composed of domain name + ID + compression format, and the subsequent compression format field only affects the size and quality of the image, does not affect the presence or absence of watermark, and even does not matter if it is removed (it seems that the original image before compression is obtained after removal).
Therefore, watermarked images must be controlled by ID. Moreover, as a programmer's intuition, the watermark free image ID (if any) must be placed with the watermark image ID.
Next, we copy 0c7a3f7b-92c9-4e0b-5408-4154abc82d86 (image ID with watermark) to search in the web source code to see if there is any harvest.
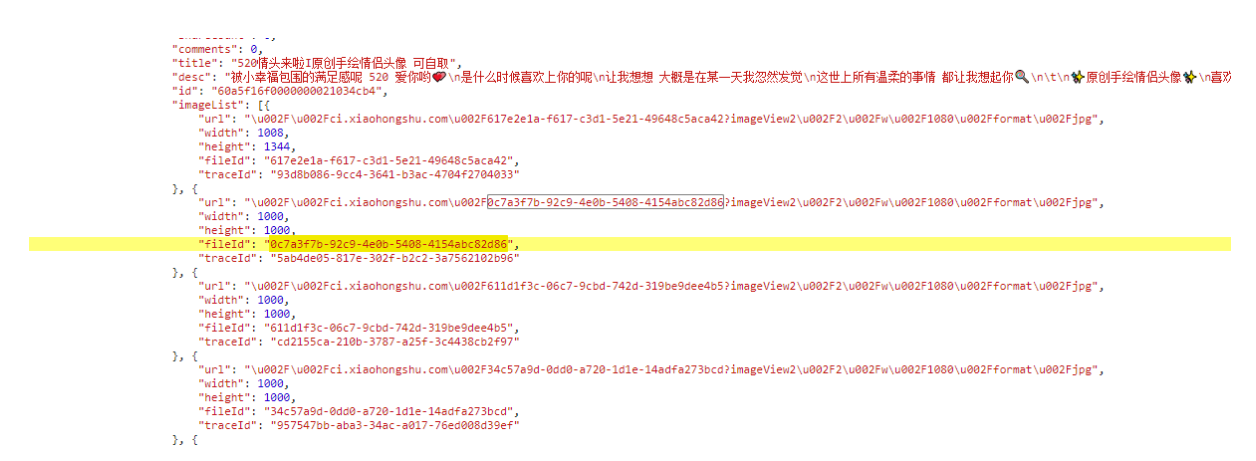
After some searching, I finally found a suspicious place, which is a text in json format. There are many elements under imageList, and each item has url, width, height, fieldId and traceId information.
We found that the URL is the picture link we just found (the \ u002F in it is the URL code of the slash /), and the fieldId is the ID of the picture we found.
At this time, a field is suspicious. What is traceId?
With a try attitude, I changed the image id in the url into the value of traceId, and copied it to the browser to check it
https://ci.xiaohongshu.com/5ab4de05-817e-302f-b2c2-3a7562102b96
Hey, guess what? The watermark is gone!! Ha ha ha ha

No more nonsense, just go to the code:
import requests
import os
'''https://ci.xiaohongshu.com / this is the watermark free splicing link of little red book. Just pass in the parameter in traceId ''
def fetchUrl(url):
'''
Initiate a network request to obtain the web page source code
'''
headers = {
'cookie': 'xhsTrackerId=fcfd14b6-1423-4943-c965-449b5af73f26; xhsuid=sYUSS950YirhWUTe; xhs_spid.5dde=6765b859633f726e.1616929773.1.1616929774.1616929773.a7f78109-ba33-4d1c-a05b-1ecc0fb27d3f; timestamp2=202201236d4f1ecf16d89af07c8fa410; timestamp2.sig=hekBnS5aa5fNTlR-WQj8S9O2ppnTJ_tGwG28sqLSOeM; extra_exp_ids=commentshow_clt1,gif_exp1,ques_clt2referer: https://link.csdn.net/?target=https%3A%2F%2Fwww.xiaohongshu.com%2Fdiscovery%2Fitem%2F60a5f16f0000000021034cb4',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
}
r = requests.get(url, headers=headers)
return r.text
def parsing_link(html):
'''
analysis html Text, extracting watermark free images url
'''
beginPos = html.find('imageList') + 11
endPos = html.find(',"cover"')
imageList = eval(html[beginPos: endPos])
for i in imageList:
picUrl = f"https://ci.xiaohongshu.com/{i['traceId']}"
yield picUrl, i['traceId']
def download(url, filename):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
}
with open(f'{filename}.jpg', 'wb') as v:
try:
r = requests.get(url, headers=headers)
v.write(r.content)
except Exception as e:
print('Picture download error!')
if __name__ == '__main__':
original_link = 'https://www.xiaohongshu.com/discovery/item/60a5f16f0000000021034cb4'
html = fetchUrl(original_link)
# print(html)
for url, traceId in parsing_link(html):
print(f"download image {url}", traceId)
# download(url, traceId)
print("Finished!")