preface
Set set: specifically reflected in the non repeatable nature. The feature of this set is that it will not store duplicate elements and will store unordered elements (the order of storage and retrieval is not necessarily the same)
hashset: it is a classic implementation class of set. The bottom layer is implemented by using the key value of hash table, which cannot be repeated. hashset has the following characteristics
- Empty data can be stored
- There is no guarantee that the data insertion and extraction sequence are consistent
- The collection is out of sync
example
public static void main(String[] args) {
HashSet hs=new HashSet<>();
hs.add("c");
hs.add("a");
hs.add("d");
hs.add(null);
hs.stream().forEach(e->{
System.out.println(e);
});
}
//output data
null
a
c
d

- From the above example, it is allowed to insert empty data
- Secondly, it is obvious that the inserted data is inconsistent with the extracted data, and the hash value is followed (there is no hash collision)
- When using it, it does not implement the get method. After insertion, it is either converted into an array or iterated to get the data, which is inconvenient to use
Implementation principle
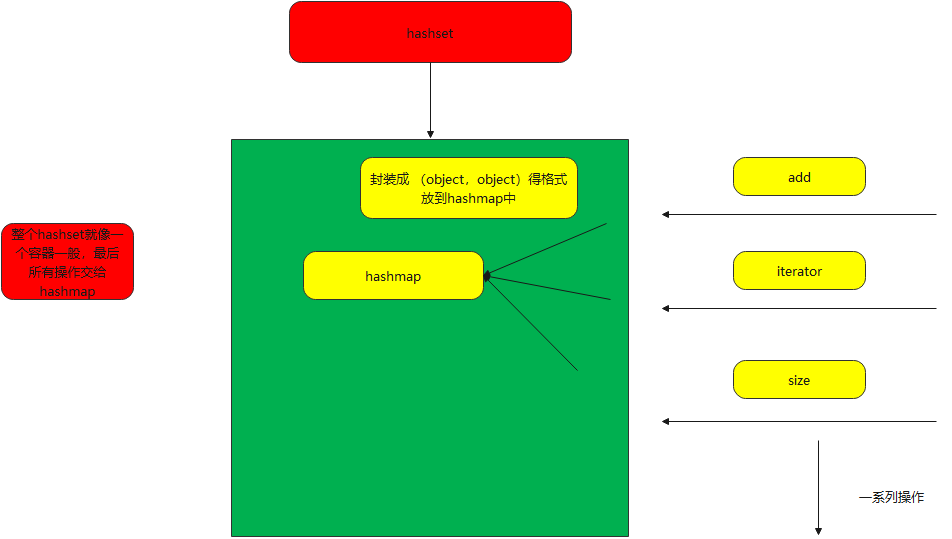
The whole hashset is like a container, which encapsulates the operation of hashmap. The actual operation is hashmap
Notes to the whole article
/**
*This class implements the < TT > set < / TT > interface and is supported by a hash table (actually an < TT > HashMap < / TT > instance). It does not guarantee the iterative order of * set; In particular, it cannot guarantee
*Over time, order will remain unchanged. This class allows < TT > null < / TT > elements.
*<p>This class provides constant time performance for basic operations (< TT > Add < / TT >, < TT > delete < / TT >, < TT > include < / TT > and < TT > size < / TT >), * assuming that the hash function disperses the elements correctly
*Bucket. The time required to iterate this set is the size (number of elements) of the < TT > hash set < / TT > instance plus the "capacity" (bucket) of the backing < TT > HashMap < / TT > instance. Therefore, it is very important not to set the initial capacity
*If iteration performance is important, it is high (or the load factor is too low)< p> < strong > Please note that this implementation is not synchronized</ Strong > If multiple threads access the hash set at the same time, the thread modifies the set and it must be synchronized externally. This is usually done by naturally encapsulating the collection at some point.
*
*If such an object does not exist, the {@ link Collections#synchronizedSet Collections.synchronizedSet} method should be used. This is best done at creation time to prevent accidental asynchronous access to the collection: < pre > set s = collections Synchronizedset (New HashSet (...) < / preprocessing >
*
*<p>The iterator returned by the < TT > iterator < TT > method of this class is < I > fast failure < / I >: if the collection is modified at any time after the iterator runs, it is created in any way, except through the iterator's own < TT > remove < / TT >
*Method, the iterator throws a {@ link ConcurrentModificationException}. Therefore, in the face of concurrent modification, the iterator will soon fail, rather than risking arbitrary and uncertain behavior at uncertain times in the future.
*<p>Note that fast failure behavior of iterators cannot be guaranteed. Generally speaking, it is impossible to make any hard guarantee that there are unsynchronized concurrent modifications in the future. The failed fast iterator throws the ConcurrentModificationException as best it can.
*Therefore, it is wrong to write a program that depends on this, with the exception of its correctness: < I > the fast failure behavior of the iterator should only be used to detect errors</ i>
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @param <E> the type of elements maintained by this set
*
* @author Josh Bloch
* @author Neal Gafter
* @see Collection
* @see Set
* @see TreeSet
* @see HashMap
* @since 1.2
*/The whole note must be understood
- This class implements the < TT > set < / TT > interface and is supported by a hash table (actually an < TT > HashMap < / TT > instance). It cannot guarantee that the order will remain unchanged, and empty elements are allowed
- The hash function correctly disperses the elements in the array (bucket). This class provides constant time performance for basic operations. The initial capacity is very important, which is emphasized in hashmap
- This implementation is out of sync and needs to be synchronized outside. Collections is recommended synchronizedSet
- There will be quick failures in the iterator to ensure the security of the data
Member properties
There are mainly two member attributes
private transient HashMap<E,Object> map;
// The virtual value associated with the object in the background image
private static final Object PRESENT = new Object();- First, you need to hold the hashmap object, and then perform various operations
- And the value in hashmap is an empty object by default
Constructor
Nonparametric structure
It provides us with a hashmap of default capacity and load factor
public HashSet() {
map = new HashMap<>();
}Parametric structure
When commenting, it is also suggested that we set the capacity according to the actual use
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}There is a doubt here. There is a class that can create LinkedHashMap. It can record the insertion order of data, but it is not a public method. We can't use it. This may be provided for internal use, but it doesn't realize the method of obtaining the order. We don't know what to do
add remove method
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
Here we have to use the add remove method. I'm sure you all know that if you need to study it deeply, you can take a look at the following article
Deep understanding of Java collection (11): implementation principle of HashMap and hash collision
summary
The implementation of the whole hashset is very simple. Basically, all operations are implemented in hashmap, and the key points of the whole data storage are also in hashmap. As for providing the construction method to create LinkedHashMap , I don't know where to use it, I still need to understand and communicate