Reverse crawler 08 concurrent asynchronous programming
I will review the content of this section by quoting my favorite teacher Lin Haifeng Egon of Luffy school city.
1. What is concurrent asynchronous programming?
***
To explain concurrent asynchronous programming, you need to understand the meaning of the following words, such as parallel, concurrent, synchronous, asynchronous, blocking and non blocking.
Parallel: multiple tasks are performed at the same time, which can be understood as Naruto learning spiral pills. After multiple shadow split, all split bodies rub pills together at the same time, that is, in the real sense, at the same time.
Concurrency: multiple tasks quickly switch and run in turn, which can be understood as time management masters. They communicate with multiple opposite sex at the same time, but there is no conflict in time. They can be carried out simultaneously in the macro sense through rapid switching.
Synchronization: traditional tasks are synchronized, which means that all tasks are lined up neatly, one by one into the CPU, and the next task can be executed only after the previous task is completed.
Asynchrony: compared with synchronization, multiple tasks can be performed at the same time. The asynchronous mode can be parallel or concurrent. As long as it is performed at the same time in the macro sense, it belongs to asynchrony.
Blocking: when a task containing IO operations needs to be executed, the operating system will block the task and continue to execute the task after the IO operation is completed. Blocking means that the operating system deprives the CPU use right of the task and allocates the CPU to other tasks.
Non blocking: as opposed to blocking, the operating system will not deprive the CPU of the task. If the IO is ready when executing the IO operation, the non blocking task will be executed successfully. If the IO is not ready, the caller will be directly informed of the execution failure.
After knowing these concepts, you should know what concurrent asynchronous programming is? It refers to a programming method in which multiple tasks are switched quickly on the micro level and multiple tasks are carried out simultaneously on the macro level, which can improve the operation efficiency of the program by N times. After talking about so many concepts, it should still be difficult for non professional Xiaobai to quickly accept and master them. Next, I will offer the classic von Neumann architecture diagram to explain what concurrent asynchronous programming is (in fact, I am also a wild child of non professional class, hehe).
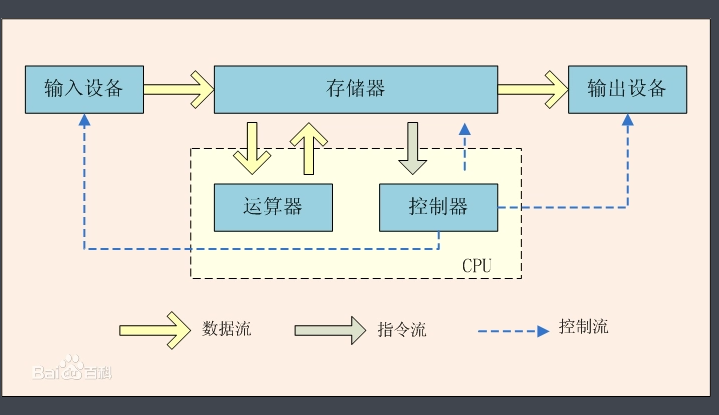
The figure above is the architecture diagram of von Neumann. It tells us that the computer is divided into five parts: arithmetic unit, controller, memory, input device and output device. In traditional synchronous programming, when the program enters IO operation, the operating system will block the program entering IO and allocate the CPU to other ready programs in order to improve the efficiency of hardware. Any program needs to input the data into the memory through the input device, calculate the input data by the arithmetic unit, and finally output the calculation results through the output device. The whole process is controlled by the controller. It can be seen from the above figure that IO operation is completed by input and output devices and calculation is completed by arithmetic unit. Therefore, theoretically, these three parts can work at the same time. Some programs are too simple and the three parts can only be carried out one by one. However, if a program contains multiple tasks, and each task contains certain IO and calculation operations, the three can be reasonably allocated to achieve the effect of running at the same time. Finally, from a macro point of view, many tasks are carried out at the same time. This reasonably allocated operation is concurrent asynchronous programming.
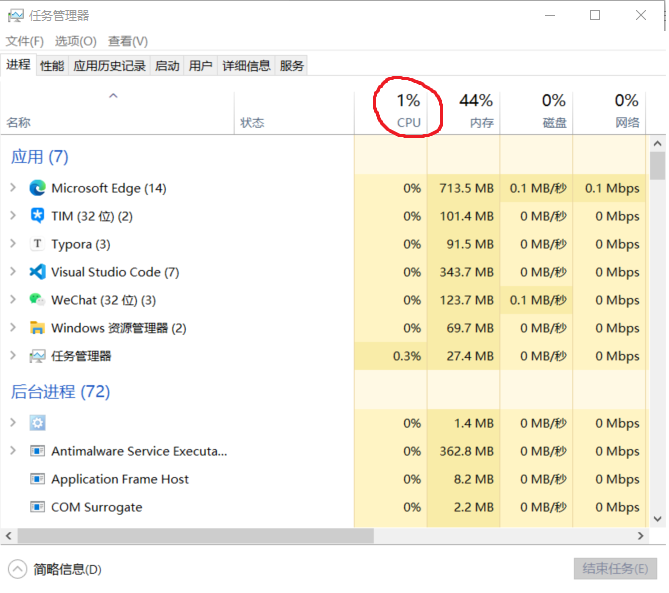
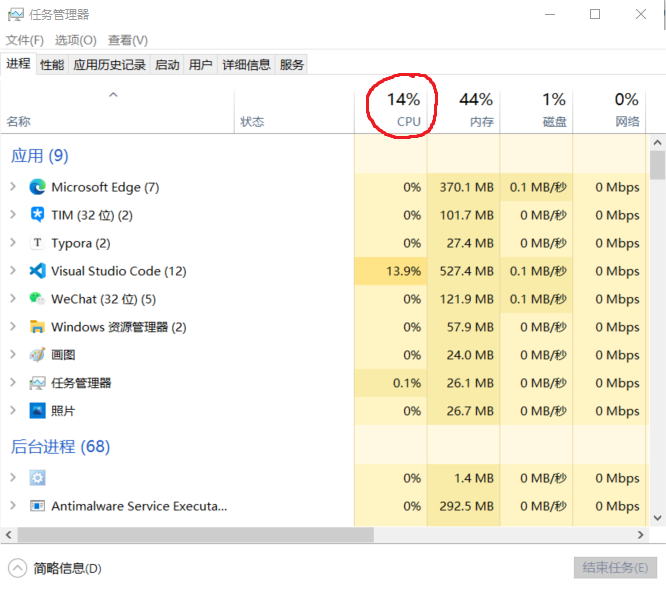
In fact, in addition to the above concepts, such as process, thread and co process, these concepts have been rotten. For example, process is the smallest unit of operating system resource allocation; Thread is the smallest unit of operating system task scheduling; Coprocessing is a task that is self scheduled by software without involving the operating system under a single thread. Because it does not involve the operating system, it is faster than thread scheduling. Here, I strengthen my understanding of the concept of process through experiments. At ordinary times, we have heard of 2-core 4-threaded, 4-core 8-threaded CPUs. The number of CPUs represents the number of tasks that can be run in real parallel. Generally, the python program we write has only one process, which will be allocated a CPU core, that is, the process is the smallest unit of resource allocation. My computer has 8 cores, so each core accounts for 12.5% of the CPU efficiency. Usually, the CPU utilization rate is 1% through the task manager. When I write a python program for dead cycle calculation, because there is no IO operation, the operating system will allocate a core to fully support it without blocking and switching. At this time, observe the task manager, You can see about 1% + 12.5% ≈ 14%. Therefore, if we open 7 sub processes to perform the same calculation operation, the system will allocate 7 additional cores to support, and the 8-core CPU will be allocated. The computer will be very stuck. You can do this experiment by yourself to learn more about CPU and processes. Experiments on threads and co processes can be explored by yourself. If you find suitable and interesting experiments, you can tell me.
i = 0
while True:
i += 1
2. Why concurrent asynchronous programming? When is it suitable for concurrent programming?
It goes without saying that, of course, the speed is fast. Under what circumstances is it suitable to improve the program speed through concurrent asynchronous programming? It can be seen from the previous description that concurrent asynchronous programming is to reasonably allocate different tasks to input and output devices and arithmetic units, so that these devices can respectively serve tasks running in different stages. The three serve a program at the same time, and the efficiency of the program will be improved. Therefore, when a program's task contains many discrete IO and computing operations, it is very suitable for concurrent asynchronous programming, such as crawler's multi URL network request, multi file read-write operation, etc.
3. How to program concurrently and asynchronously?
There are three kinds, 1 Thread 2 Process 3 For the collaborative process, first review the threads and processes here, and then review the collaborative process later.
Multithreading method I
"""
1. Create task
2. Instantiate thread object
3. Start task
"""
from threading import Thread
# Create task
def func(name):
for i in range(100):
print(f"{i}. My name is {name}")
if __name__ == "__main__":
# Instantiate thread object
t1 = Thread(target=func, args=("JayChou",))
t2 = Thread(target=func, args=("Apphao",))
# Start task
t1.start()
t2.start()
Multithreading method II
"""
1. Custom class inheritance Thread
2. adopt__init__Function parameter transfer
3. rewrite run method
"""
from threading import Thread
# Custom class inherits Thread
class MyThread(Thread):
# Pass__ init__ Function parameter transfer
def __init__(self, name):
# The initialization function of the parent class must be called before initialization
super(MyThread, self).__init__()
self.name = name
# Override run method
def run(self):
for i in range(100):
print(f"{i}. My name is {self.name}")
if __name__ == "__main__":
t1 = MyThread("JayChou")
t2 = MyThread("Apphao")
t1.start()
t2.start()
Thread pool
The advantage of thread pool is to protect the system and prevent the program from setting up threads without limit, resulting in the depletion of hardware resources.
Basic usage of thread pool
"""
1. Define task
2. Open thread pool
3. Submit task
"""
from concurrent.futures import ThreadPoolExecutor
# Define task
def func(name):
for i in range(10):
print(f"{i}. My name is {name}")
if __name__ == "__main__":
# Open thread pool
with ThreadPoolExecutor(10) as t:
for i in range(100):
# Submit task
t.submit(func, f"JayChou {i}")
You can get the writing method of thread execution results
"""
1. Define task
2. Open thread pool
3. Submit the task and add a callback function
4. Define callback function
"""
from concurrent.futures import ThreadPoolExecutor
import time
# Define task
def func(name, t):
print(f"My name is {name}")
time.sleep(t)
return name
# Define callback function
def fn(res):
print(res.result())
if __name__ == "__main__":
# Open thread pool
with ThreadPoolExecutor(3) as t:
# Submit the task and add a callback function
t.submit(func, "JayChou", 2).add_done_callback(fn)
t.submit(func, "Egon", 3).add_done_callback(fn)
t.submit(func, "Apphao", 1).add_done_callback(fn)
add_ done_ The callback function specified by callback() will be executed immediately after the thread completes execution. Since the execution time of each thread is uncertain, the execution order of the callback function is also uncertain, and the order of the return values is uncertain. If you want to determine the order of the return values, use the following method instead.
"""
1. Define task
2. Open thread pool
3. adopt map Submit the task and accept it map Return value of
4. for Cyclic acquisition map Return value of
"""
from concurrent.futures import ThreadPoolExecutor
import time
# Define task
def func(name, t):
print(f"My name is {name}")
time.sleep(t)
return name
if __name__ == "__main__":
# Open thread pool
with ThreadPoolExecutor(3) as t:
result = t.map(func, ["JayChou", "Egon", "Apphao"], [2, 3, 1])
# When the return value of map is, the generator takes out the contents through the for loop
for r in result:
print(r)
Multi process writing method 1: it is almost the same as multithreading
"""
1. Create task
2. Instantiate process object
3. Start task
"""
from multiprocessing import Process
# Create task
def func(name):
for i in range(100):
print(f"{i}. My name is {name}")
if __name__ == "__main__":
# Instantiate process object
p1 = Process(target=func, args=("JayChou",))
p2 = Process(target=func, args=("Apphao",))
# Start task
p1.start()
p2.start()
Multi process writing method 2: it is almost the same as multithreading
"""
1. Custom class inheritance Process
2. adopt__init__Function parameter transfer
3. rewrite run method
"""
from multiprocessing import Process
# Custom class inherits Process
class MyProcess(Process):
# Pass__ init__ Function parameter transfer
def __init__(self, name):
# The initialization function of the parent class must be called before initialization
super(MyProcess, self).__init__()
self.name = name
# Override run method
def run(self):
for i in range(100):
print(f"{i}. My name is {self.name}")
if __name__ == "__main__":
p1 = MyProcess("JayChou")
p2 = MyProcess("Apphao")
p1.start()
p2.start()
Process pool
The basic usage of as like as two peas is similar to the thread pool.
"""
1. Define task
2. Open process pool
3. Submit task
"""
from concurrent.futures import ProcessPoolExecutor
# Define task
def func(name):
for i in range(10):
print(f"{i}. My name is {name}")
if __name__ == "__main__":
# Open process pool
with ProcessPoolExecutor(10) as t:
for i in range(100):
# Submit task
t.submit(func, f"JayChou {i}")
Gets the return value as like as two peas.
"""
1. Define task
2. Open process pool
3. Submit the task and add a callback function
4. Define callback function
"""
from concurrent.futures import ProcessPoolExecutor
import time
# Define task
def func(name, t):
print(f"My name is {name}")
time.sleep(t)
return name
# Define callback function
def fn(res):
print(res.result())
if __name__ == "__main__":
# Open process pool
with ProcessPoolExecutor(3) as t:
# Submit the task and add a callback function
t.submit(func, "JayChou", 2).add_done_callback(fn)
t.submit(func, "Egon", 3).add_done_callback(fn)
t.submit(func, "Apphao", 1).add_done_callback(fn)
As like as two peas, the return value in the process pool is ordered almost the same as that of the thread pool.
"""
1. Define task
2. Open process pool
3. adopt map Submit the task and accept it map Return value of
4. for Cyclic acquisition map Return value of
"""
from concurrent.futures import ProcessPoolExecutor
import time
# Define task
def func(name, t):
print(f"My name is {name}")
time.sleep(t)
return name
if __name__ == "__main__":
# Open process pool
with ProcessPoolExecutor(3) as t:
result = t.map(func, ["JayChou", "Egon", "Apphao"], [2, 3, 1])
# When the return value of map is, the generator takes out the contents through the for loop
for r in result:
print(r)