Task parallelism and data parallelism
Task parallelism: divide many tasks that can solve the problem, and then distribute them on one or more cores for program execution.
Data parallelism: divide the data that can solve the problem, and execute the divided data on one or more cores; Each check of these data carries out a similar operation.
Bottleneck and improvement of von Neumann architecture
Bottleneck: separation of CPU and main memory (it can be compared to the separation of the factory responsible for production and the warehouse)
Improved (1) CPU cache
(2) Virtual memory
(3) Low level parallelism
Characteristics of cache
(1) Memory location set, which can have shorter access overhead than other memory.
(2) The CPU cache is usually located on the same chip as the CPU, and the memory access overhead is faster than ordinary memory
cache level
The cache can have multiple levels. The first level cache has a fast access speed but a small capacity. The second level cache has a slow speed but a large capacity. This is gradually the case downward
Cache missing and cache hit
When the cpu needs to access the main memory or data, it will query down the cache hierarchy, first L1cache and then L2cache. If the cache does not have the required information, it will access the main memory. When querying the cache for data, if there is data in the cache, it is called cache hit. If there is no data, it is called cache missing
Instruction parallelism improves processor performance by allowing multiple processor components or functional units to execute instructions at the same time. There are two main ways: pipeline and multi launch
Pipeline: pipeline: functional units are arranged in stages. A concrete example is the addition problem
Multiple instructions: multiple instructions are started and executed at the same time
Multi - transmit technology: the multi - processor copies the computing unit and executes different instructions in the program at the same time For example, when the first adder calculates z[1], the second adder calculates z[2], and so on.
When a functional unit is scheduled at compile time, it is called static multiple emission
When a functional unit is scheduled at runtime, it is called dynamic multi emission. A processor that supports dynamic multi emission is called superscalar
The system needs to find out the instructions that can be executed at the same time. This technology is called prediction.
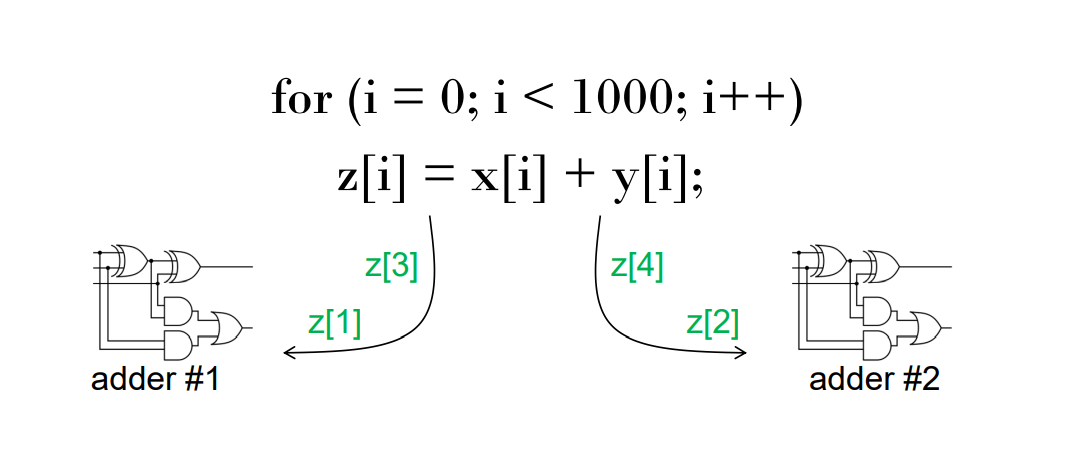
Generally, instruction parallelism is difficult to use, because there are dependencies between many programs, such as recursive programs, so hardware multithreading is introduced. Hardware multithreading provides a way for the system to continue to do other useful work when the currently executing task has stopped.
cache coherence
Directory based Cache consistency
A data structure called directory is used, which stores the status of each cache line When a variable is updated, it will query the directory and make all cache lines containing the variable illegal
Listen for Cache consistency
Multiple cores share the bus
Any signal transmitted on the bus can be connected to the master bus
All the cores of the line are "visible"
When core 0 updates the copy of x stored in its Cache
It also broadcasts the message over the bus
If core1 is "listening" to the bus, it will know that x has passed
Updated, it marks the x copy in its Cache as
Illegal
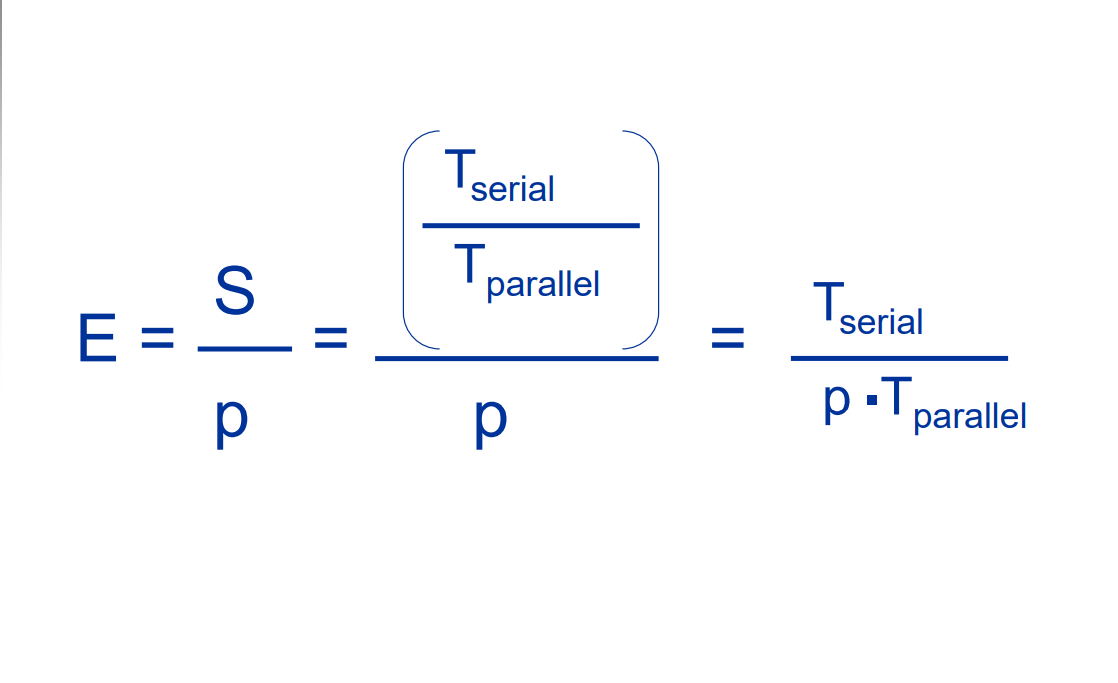
Calculation of acceleration ratio
Number of cores = p
Serial program run time = Tserial
Parallel program run time = Tparallel
Tparallel = Tserial / p
Acceleration ratio Y=Tparallel / Tserial
Efficiency:
Amdal's law
Unless all serial programs can be parallel, no matter how many cores are available, the acceleration will be very limited
Scalability
Roughly speaking, if a technology can handle problems with increasing scale, it is scalable. If it can maintain a fixed efficiency without increasing the problem scale when increasing the number of processes / threads, the program is called strongly scalable
If, while increasing the number of processes / threads, only increasing the problem size at the same rate can keep the efficiency value unchanged, the program is called weakly scalable
Dynamic thread
The main thread waits for the task and fork s the new thread. When the new thread completes the task, it ends the effective use of the new thread resources, but the creation and termination of the thread is very time-consuming
Static thread
Create a thread pool and assign tasks, but the thread is not terminated until it is cleaned up Better performance, but may waste system resources
Classification and characteristics of flynn
Single instruction stream single data stream (SISD) -- traditional computers contain a single CPU that obtains instructions from programs stored in memory and acts on a single data stream
Single instruction stream multiple data streams (SIMD) -- a single instruction stream acts on more than one data stream. It is called single instruction stream multiple data stream. An example of SIMD is an array or vector processing system,
advantage
Parallelism achieved by dividing data between processors applies the same instruction to multiple data items, which can perform the same operation on different data in parallel.
shortcoming
All ALUs need to execute the same instruction or remain idle In the classic design, they must also run synchronously ALU cannot store instructions It is effective for large data parallel problems, but not for other more complex parallel problems
Multiple instruction stream single data stream (MISD) -- it is actually rare to act on a single data stream with multiple instructions.
Multiple instruction streams multiple data streams (MIMD) - supports multiple instruction streams running simultaneously on multiple data streams It usually consists of a set of completely independent processing units or cores
, each core has its own control unit (CU)
And computing unit (ALU)
The following are common API s for several programming modes
int MPI_Reduce( void *input_data, /*Pointer to the memory block that sent the message */ void *output_data, /*Pointer to the memory block that receives (outputs) the message */ int count,/*Data volume*/ MPI_Datatype datatype,/*data type*/ MPI_Op operator,/*Protocol operation*/ int dest,/*The process number of the process to receive (output) the message*/ MPI_Comm comm);/*Communicator, specifying communication range*/
int MPI_Send( void* msg_buf_p, /* IN */ int msg_size, /* IN */ MPI_Datatype msg_type, /* IN */ int dest, /* IN */ int tag, /* IN */ MPI_Comm communicator /* IN */ );
int MPI_Recv( void* msg_buf_p, /* msg_buf_p Point to memory block */ int buf_size, /* I Number of stored objects*/ MPI_Datatype buf_type, /*data type */ int source, /* From which process */ int tag, /* tag It needs to match the parameter tag of the sending message */ MPI_Comm communicator, /* It needs to match the communication subsystem of the sending process */ MPI_Status* status_p /* OUT */ );
MPI_Sendrecv( void *sendbuf //initial address of send buffer
int sendcount //number of entries to send
MPI_Datatype sendtype //type of entries in send buffer
int dest //rank of destination
int sendtag //send tag
void *recvbuf //initial address of receive buffer
int recvcount //max number of entries to receive
MPI_Datatype recvtype //type of entries in receive buffer
MPI_BCAST(void* data_p,int count,datatype,source_proc,comm)
IN/OUT data_p t adopt data_p The referenced content sends the communication child to all processes
IN count Number of data in communication message buffer(integer)
IN datatype Data type in communication message buffer(handle)
IN source_proc The serial number of the process that sent the broadcast(integer)
IN comm Communication sub(handle)
MPI_Scatter(
void* send_data,//Data stored in process 0, array
int send_count,//The number of data to be sent to each process
//If send_ If count is 1, each process receives 1 data; If it is 2, each process receives 2 data
MPI_Datatype send_datatype,//Type of data sent
void* recv_data,//Receive cache_ Count data
int recv_count,
MPI_Datatype recv_datatype,
int root,//The number of the root process
MPI_Comm communicator)
int pthread_create(pthread_t *tidp, const pthread_attr_t *attr, ( void *)(*start_rtn)( void *), void *arg); The first parameter is a pointer to the thread identifier. The second parameter is used to set thread properties. The third parameter is the starting address of the thread running function. The last parameter is the parameter of the running function.```