Spark computing framework encapsulates three data structures to handle different application scenarios in order to process data with high concurrency and high throughput. The three data structures are:
RDD: elastic distributed data set
accumulator: distributed shared write only variables
Broadcast variable: distributed shared read-only variable
1, RDD
1. RDD concept and its characteristics
RDD (Resilient Distributed Dataset) is called elastic distributed dataset, which is the most basic data processing model in Spark. In the code, it is an abstract class, which represents an elastic, immutable, divisible and parallel computing set of elements.
elasticity
(1) storage elasticity: automatic switching between memory and disk;
(2) fault tolerant elasticity: data loss can be recovered automatically;
(3) elasticity of calculation: retry mechanism for calculation error;
(4) elasticity of slicing: it can be sliced again as needed.
Distributed: data is stored on different nodes of the big data cluster
Data set: RDD encapsulates the calculation logic and does not save data
Data abstraction: RDD is an abstract class, which needs the concrete implementation of subclasses
Invariable: RDD encapsulates the computing logic and cannot be changed. If you want to change it, you can only generate a new RDD. The computing logic is encapsulated in the new RDD
Partitioned and parallel computing
2. Five attributes of RDD
Internally, each RDD is characterized by five main properties: A list of partitions A function for computing each split A list of dependencies on other RDDs Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash- partitioned) Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
List of partitions
- There is a partition list in RDD data structure, which is used for parallel computing when executing tasks. It is an important attribute to realize distributed computing.
/**
* Implemented by subclasses to return the set of partitions in this RDD. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*
* The partitions in this array must satisfy the following property:
* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`
*/
protected def getPartitions: Array[Partition]
partition calculation function
- Spark uses partition function to calculate each partition during calculation
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T]
∙ dependencies between RDD S
- RDD is the encapsulation of computing models. When multiple computing models need to be combined in requirements, it is necessary to establish dependencies on multiple RDDS
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependency[_]] = deps
partition manager (optional)
- When the data is KV type data, you can customize the partition of the data by setting the divider
/** Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None
preferred location (optional)
- When calculating data, you can select different node locations for calculation according to the status of the calculation node
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil
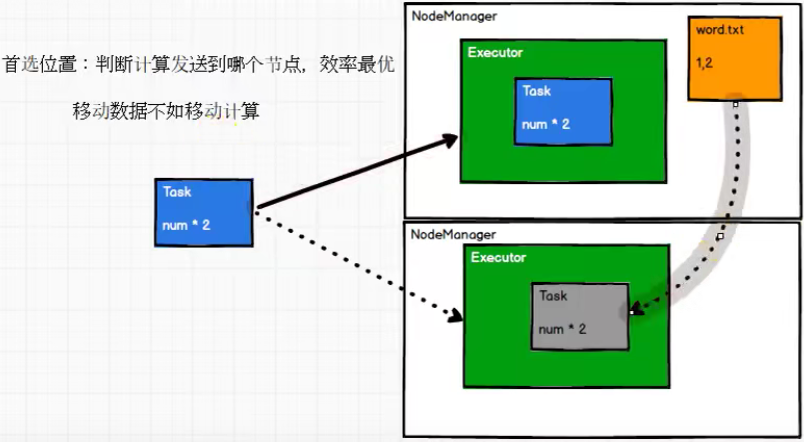
3. RDD vs IO
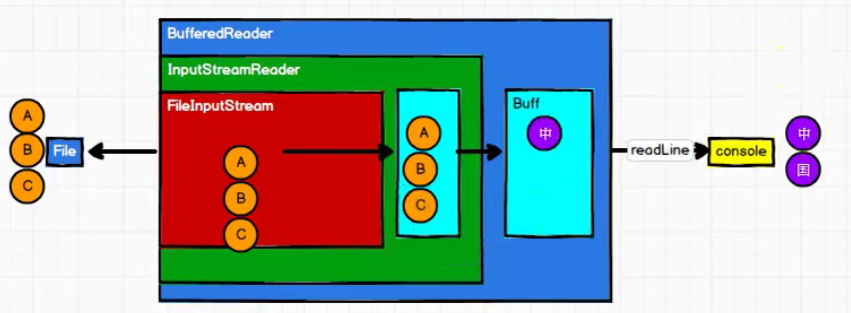
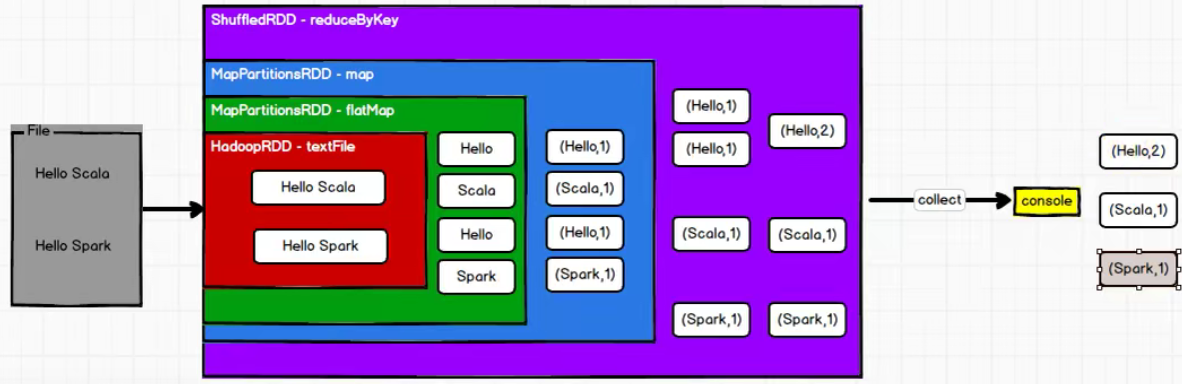
Summary:
- RDD data processing method is similar to IO stream, and there is also decorator design pattern.
- Only when the collect method is called can RDD data really perform business logic operations. The previous encapsulation is an extension of the function.
- RDD does not save data, but IO can temporarily save some data
4. Execution principle
From the perspective of computing, computing resources (memory & CPU) and computing model (logic) are required in the process of data processing. During execution, computing resources and computing model need to be coordinated and integrated.
When executing, Spark framework first applies for resources, and then decomposes the data processing logic of the application into computing tasks one by one. Then, the task is sent to the calculation node that has allocated resources, and the data is calculated according to the specified calculation model. Finally, the calculation results are obtained.
RDD is the core model for data processing in Spark framework. Next, let's take a look at the working principle of RDD in Yan environment:
1) Start the Yan cluster environment
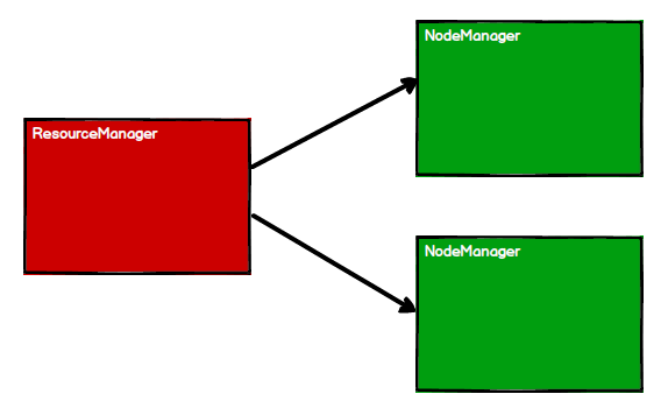
2) Spark creates scheduling nodes and computing nodes by applying for resources
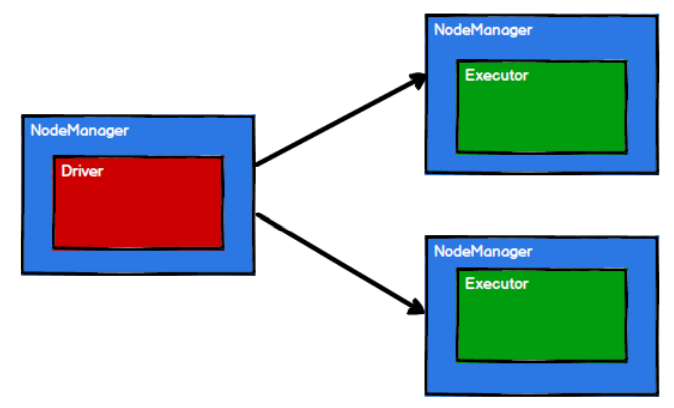
3) Spark framework divides computing logic into different tasks according to requirements
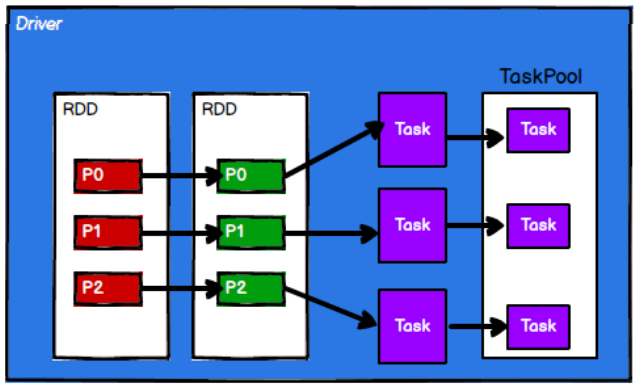
4) The scheduling node sends the task to the corresponding computing node for calculation according to the status of the computing node
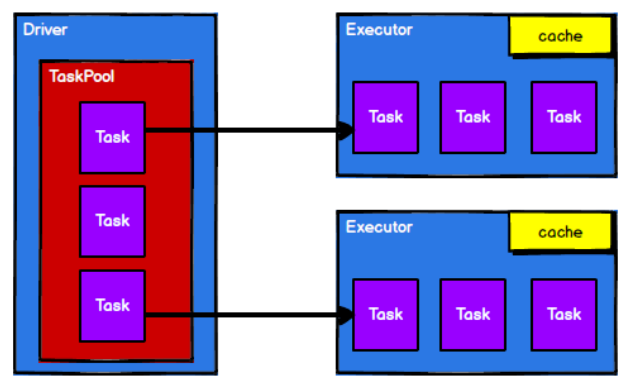
In the whole process, RDD is mainly used to encapsulate logic, generate tasks and send them to the Executor node for calculation.
5. Creation of RDD
1) Create RDD from collection (memory)
- Spark mainly provides two methods for creating RDD S from collections: parallelize and makeRDD. Parallelize is called at the bottom of makeRDD.

def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
2) Create RDD from external storage (file)
- The path path is based on the root path of the current environment; Absolute path and relative path can be written
- The path path can be specified to an explicit file or to a folder
- The path can use wildcards*
- The path can be a distributed storage system path: HDFS
- val data5:RDD[String] = sc.textFile(path:"hdfs://linux1:8080/*.txt")

- wholeTextFiles: read the text file directory from HDFS, local file system (available on all nodes) or any file system URI supported by Hadoop. Each file is read as a record and returned in the form of key value pairs, where the key is the path of each file and the value is the content of each file.

Back to top
3) Create from other RDD S
- After an RDD operation, a new RDD is generated.
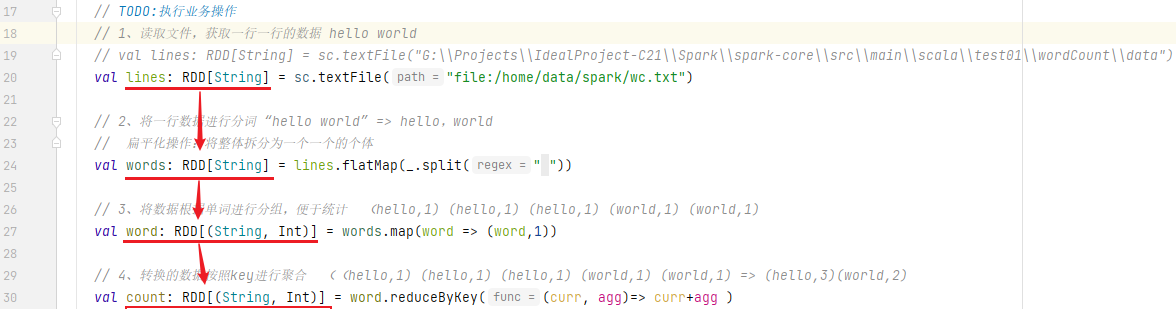
4) Create RDD directly (new)
- RDD is directly constructed by using new, which is generally used by Spark framework itself.
6. RDD parallelism and partitioning
By default, Spark can divide a job into multiple tasks and send it to the Executor node for parallel computing. The number of tasks that can be calculated in parallel is called parallelism. This number can be specified when building the RDD. Remember, the number here is the number of tasks executed in parallel, not the number of segmented tasks. Don't confuse it.
// Prepare environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
// Specify partition when creating RDD
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1,2,3,4),4)
val fileRDD: RDD[String] = sparkContext.textFile("input",2)
fileRDD.collect().foreach(println)
// Close sc
sparkContext.stop()
When reading memory data, the data can be partitioned according to the setting of parallelism. The Spark core source code of data partitioning rules is as follows:
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
When reading file data, the data is sliced and partitioned according to the Hadoop file reading rules, but there are some differences between the slicing rules and the data reading rules. The specific Spark core source code is as follows:
public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException {
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
...
for (FileStatus file: files) {
...
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
...
}
protected long computeSplitSize(long goalSize, long minSize,long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
The number of partitions can be set by ourselves when creating RDD or by default.
1) Partition of collection data
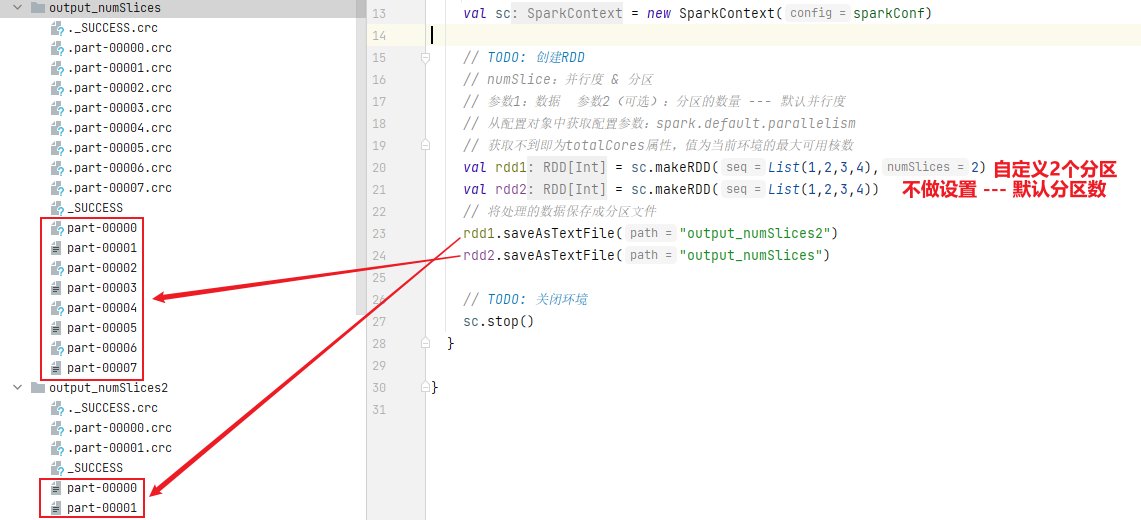
def makeRDD[T: ClassTag](seq: Seq[T],numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
def defaultParallelism: Int = {
assertNotStopped()
taskScheduler.defaultParallelism
}
override def defaultParallelism(): Int = backend.defaultParallelism()
// The default number of partitions for the underlying package is the maximum number of available cores in the current environment
override def defaultParallelism(): Int =
scheduler.conf.getInt("spark.default.parallelism", totalCores)
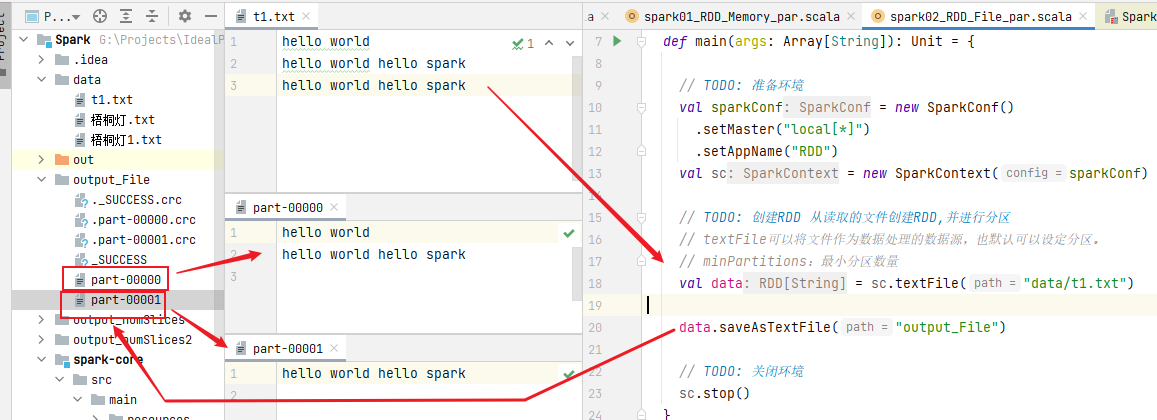
2) Partition of file data
def textFile(path: String,minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
// The smallest of the minimum number of partitions (defaultParallelism, 2)
def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
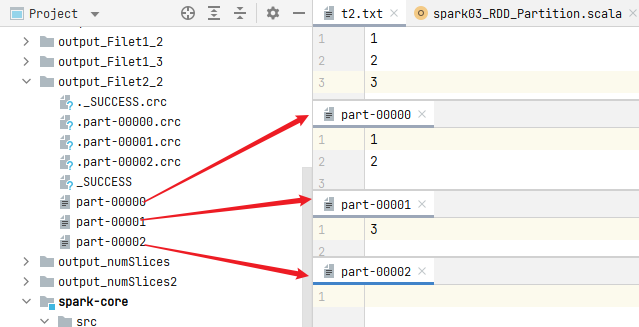
The default number of cores is 8 in the current environment, min (8,2) = 2, so the number of partition files stored by default is 2.
Modify: when reading a file, set the number of partitions to 3 and store it again. The result of file storage is the set number of partitions
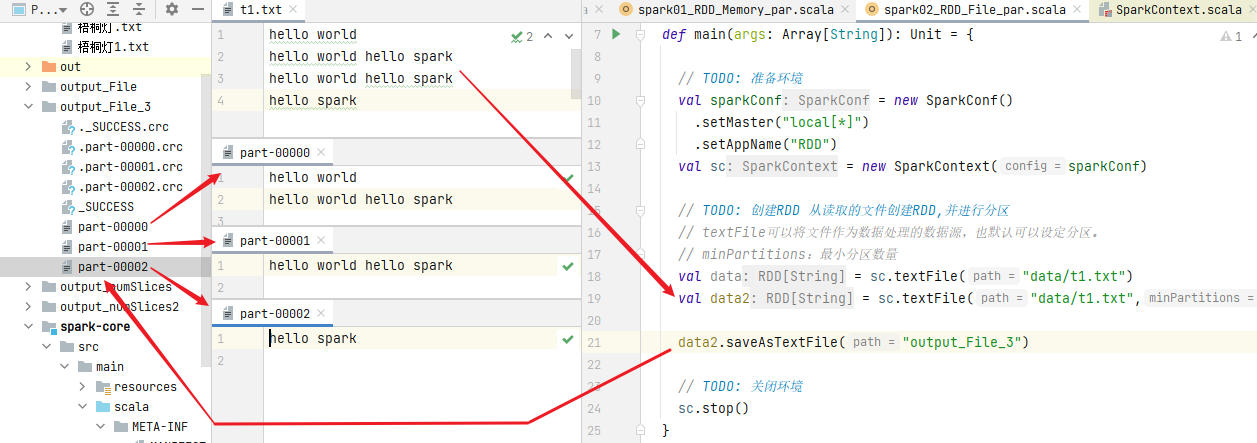
doubt:
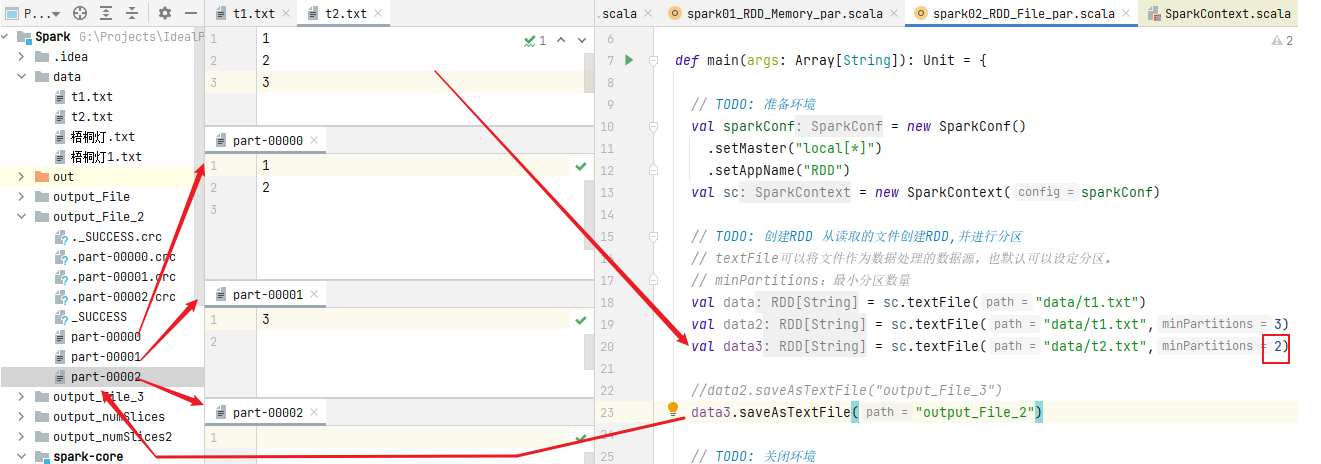
The partition is clearly set to 2, but the final number of files is 3?!
The way Spark reads files is actually the way Hadoop reads files:
How to calculate the number of partitions:
totalSize: total bytes of statistics file = > 7byte
globalSize: count the number of bytes per partition = > 7 / 2 = 3byte
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
Number of partitions: 7 / 3 = 2... 1 (1.1) + 1 = 3
(1.1) means that when the number of remaining bytes exceeds 10% of the number of bytes in a partition file, a new partition will be generated
There is one more byte, accounting for one third of the three bytes, and 33.3...%, more than 10%, so a new partition will be generated.
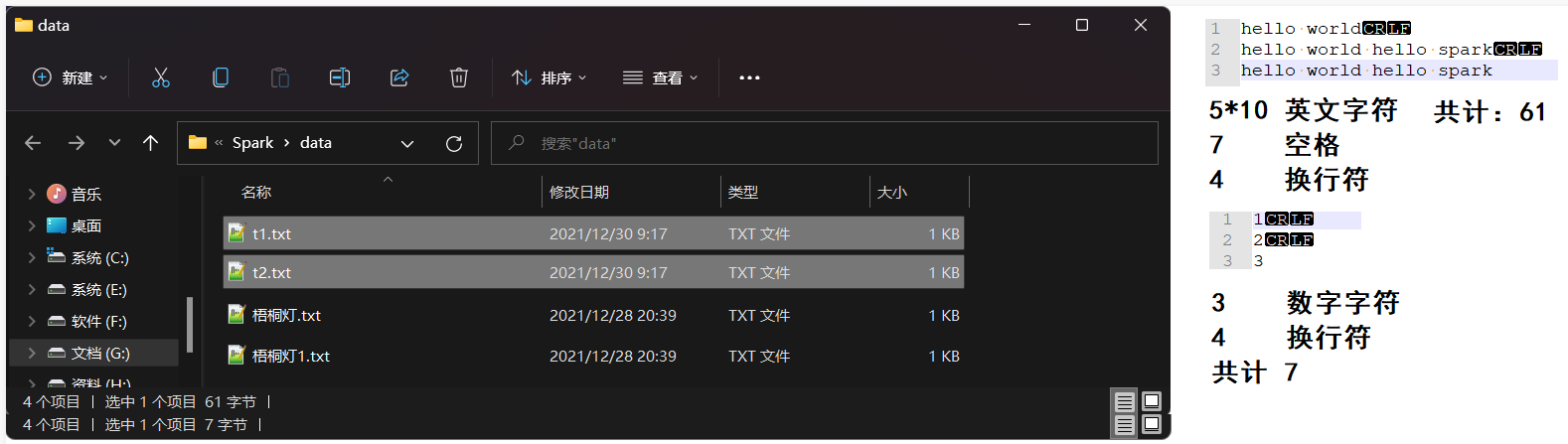
Note that the number of bytes of the file also contains spaces, line breaks and other special characters. It is recommended to use Notepad + + to view it.
In the same way, we can calculate T1 Txt file partition:
The custom partition is 2:
totalSize: total bytes of statistics file = > 61byte
globalSize: count the number of bytes per partition = > 61 / 2 = 30byte
Number of partitions: 61 / 30 = 2... 1 (1.1) = 2 (1 / 30 < 0.1)
The custom partition is 3:
totalSize: total bytes of statistics file = > 61byte
globalSize: count the number of bytes per partition = > 61 / 3 = 20byte
Number of partitions: 61 / 20 = 3... 1 (1.1) = 3 (1 / 20 < 0.1)
textFile file read related source code:
def textFile(path: String,minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
// TextInputFormat belongs to hadoop
package org.apache.hadoop.mapred;
import ...;
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextInputFormat extends FileInputFormat<LongWritable, Text>
implements JobConfigurable {...}
// FileInputFormat:
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
Stopwatch sw = new Stopwatch().start();
FileStatus[] files = listStatus(job);
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen(); // Gets the total number of bytes of the file
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); // Calculate the maximum number of bytes of partition file (rounded)
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
......
}
3) Allocation of data partitions
1. Data is read in behavioral units (one more line at a time)
spark reads files using hadoop heatstroke prevention, so it reads them line by line, which has nothing to do with the number of bytes
2. Data is read in units of offset
t1.txt:
1@@ => 012
2@@ => 345
3 => 6
3. The offset range of the data partition is calculated, and the offset will not be calculated repeatedly
minPartitions=2, 3 bytes per partition
0 => [0,3]
1 => [3,6]
2 => [6,total]
* interval is closed < = > read one more line
4. Partition
0 => [0,3] =>[1,2]
1 => [3,6] =>[3]
2 => [6,7] =>[]