1, Overview
In spark, many places involve network communication, such as message exchange between various components of spark, upload of user files and Jar packets, Shuffle process data transmission between nodes, copy and backup of Block data, etc. Spark1. Before 6, Spark Rpc was implemented based on Akka, which is an asynchronous message framework based on Scala, but Akka is not suitable for large file transmission; So, spark1 Before 6, Rpc was implemented through Akka, and large files were HttpFileServer based on Jetty. However, spark1 6 remove Akka( https://issues.apache.org/jira/plugins/servlet/mobile#issue/SPARK-5293 ), the reasons can be summarized as follows:
- There are many users who use Spark, but because different versions of Akka cannot communicate with each other, users must use the Akka version that exactly matches Spark, so users cannot upgrade Akka;
- Spark's Akka configuration is optimized for spark itself, which is likely to conflict with user-defined Akka configuration;
- Spark uses very few Akka features, which can be easily implemented by itself. At the same time, this part of the code is much less than Akka, and debugging is easier. If you encounter any Bug, you can Fix it yourself without waiting for Akka to release a new version upstream. Moreover, spark upgrades Akka itself, because the first point will force users to upgrade Akka, which is unrealistic for some users;
- In spark2 In 0.0, Jetty is removed, and based on Akka's design, the rty based Rpc framework system is reconstructed, in which both Rpc and large file transfer use Netty.
Note:
- [1] Akka is a concurrent distributed framework based on Actor concurrent programming model. Akka is written in Scala language. It provides API s in Java and scala to reduce developers' detailed handling of concurrency and ensure the final consistency of distributed calls;
- [2] Jetty is an open source Servlet container that provides a running environment for Java based Web containers, such as JSP and Servlet. Jetty is written in the Java language, and its API is published as a set of JAR packages. Developers can instantiate the jetty container into an object, which can quickly provide network and Web connections for some independent Java applications. There is a brief introduction to jetty in Appendix C. interested readers can choose to read it;
- [3] Netty is a NIO based client-side and server-side programming framework provided by Jboss. Using netty can ensure that you can quickly and simply develop a network application, such as a client and server-side application that implements a certain protocol.
Note: the source code version involved below is spark2 1.0, the following pictures are taken from the online boss blog.
2, RPC architecture
2.1 schematic class diagram
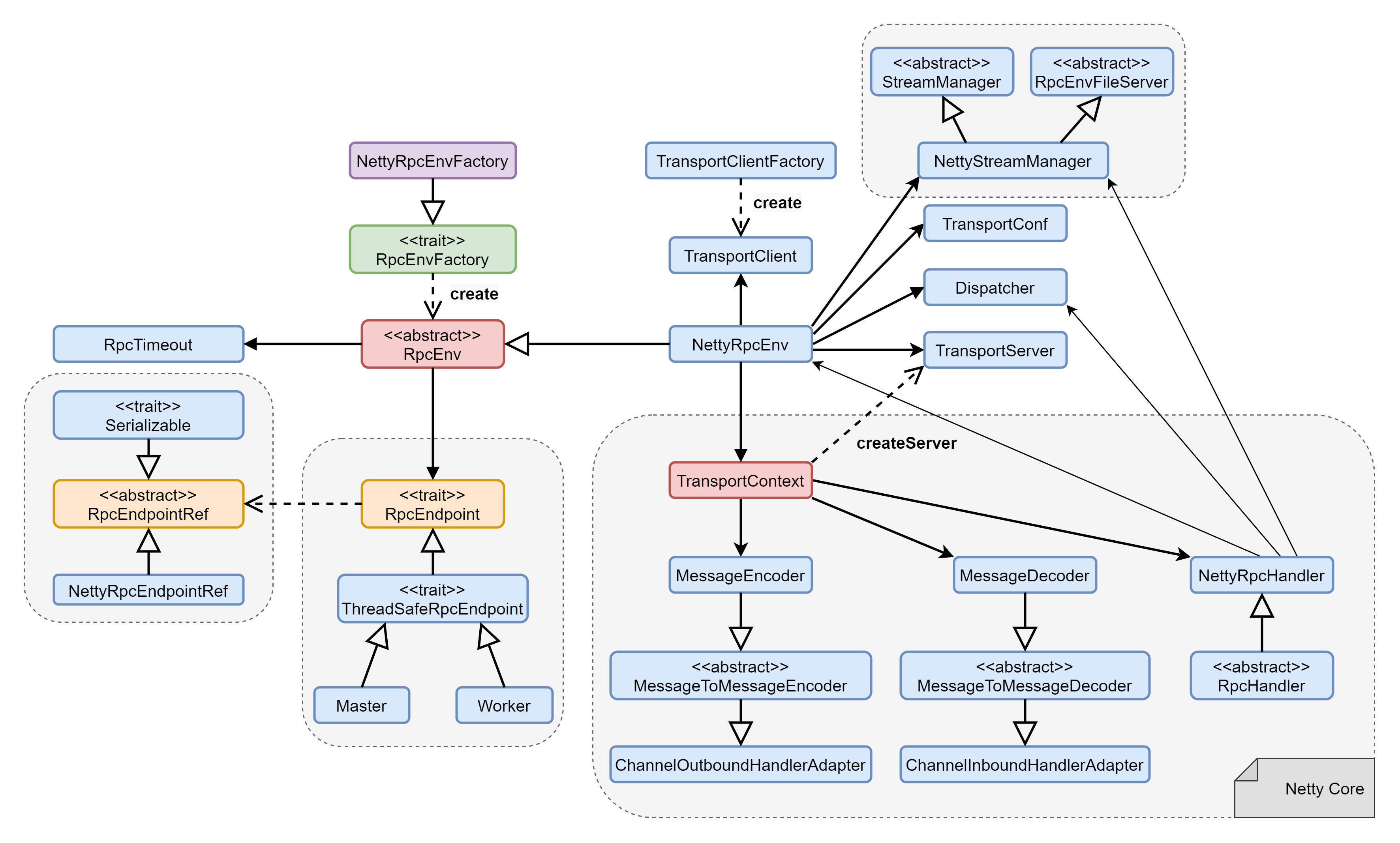
2.2 detailed class diagram
2.3 component introduction
| assembly | describe |
|---|---|
| RpcEnv | The full name is RPC Environment, which manages the life cycle of the entire RpcEndpoint, that is, the environment that each RpcEndpoint depends on when it runs |
| NettyRpcEnv | The only implementation class of RpcEnv, that is, Netty communication implementation |
| RpcEndpoint | RPC endpoint, that is, Spark communication entity. Each communication entity is a communication RPC endpoint. Moreover, it is necessary to implement RpcEndpoint interfaces, such as driverindpoint and masterendpoint. Different messages and different business processes are designed internally according to the needs of different endpoints |
| Dispatcher | The Message distributor (from the concept of netty) is responsible for distributing RpcMessage to the corresponding RpcEndpoint. The Dispatcher contains a MessageLoop, which reads the RpcMessage delivered by the LinkedBlockingQueue, finds the Endpoint Inbox according to the Endpoint ID specified by the client, and then delivers it. Because it is a blocking queue, it will block naturally when there is no Message. Once there is a Message, it will start working. The Dispatcher's ThreadPool is responsible for consuming these messages |
| EndpointData | Each endpoint has a corresponding EndpointData, which contains RpcEndpoint, NettyRpcEndpointRef information and an Inbox. There is an InboxMessage linked list inside the Inbox of the receiving mailbox. Messages sent to the endpoint are added to the linked list. At the same time, the entire EndpointData is added to the blocking queue receivers and processed asynchronously by the Dispatcher thread |
| Inbox | A local endpoint corresponds to an Inbox. There is a linked list of InboxMessage in the Inbox. InboxMessage has many subclasses, including RpcMessage remotely called, OneWayMessage remotely called fire and forget one-way Message, and messages such as service startup, link establishment and disconnection, These messages will be pattern matched in the Inbox internal method and call the corresponding RpcEndpoint function |
| RpcEndPointRef | RpcEndpointRef is a remote reference object to RpcEndpoint, through which messages can be sent to the remote RpcEndpoint for communication |
| NettyRpcEndpointRef | The only implementation class of rpcandpointref, the NettyRpcEnv version of rpcandpointref. The behavior of this class depends on where it was created. On the node that "owns" RpcEndpoint, it is a simple wrapper around the RpcEndpointAddress instance |
| RpcEndpointAddress | It mainly contains RpcAddress (host and port) and rpc endpoint name information |
| Outbox | A remote endpoint corresponds to a outbox. NettyRpcEnv contains a concurrent HashMap [rpcaddress, outbox]. After the message is put into the Outbox, it is sent out through the TransportClient |
| TransportContext | It is mainly used to create the context of TransportServer and TransportClientFactory, and to use TransportChannelHandler to establish the context of netty channel pipeline. TransportClient provides two communication protocols: RPC at the control level and chunk fetching at the data level. The rpcHandler passed in by the user through the constructor is responsible for processing RPC requests. In addition, rpcHandler is responsible for setting the stream, and can use zero copy IO to stream the stream in the form of data blocks. Both TransportServer and TransportClientFactory create a TransportChannelHandler object for each channel. Each TransportChannelHandler contains a TransportClient, which enables the server process to send messages back to the client on an existing channel |
| TransportServer | TransportServer is the server of RPC framework, which can provide efficient and low-level streaming services |
| TransportServerBootstrap | It defines the specification of the server-side boot program. The server-side boot program aims to execute the boot program on the client pipeline held by the server after the client establishes a connection with the server. Used to initialize TransportServer |
| TransportClientFactory | Create a transport client factory class for the transport client |
| TransportClient | The client of RPC framework is used to obtain continuous blocks in the pre negotiated stream. TransportClient is designed to allow efficient transmission of large amounts of data, which will be split into blocks of hundreds of KB to several MB. In short, TransportClient can be regarded as the lowest basic client class of Spark Rpc. The chunk block is mainly used to send RPC requests to the server and obtain streams from the server |
| TransportClientBootstrap | It is a client bootstrap program executed on the TransportClient. It mainly prepares for initialization (such as authentication and encryption) when establishing a connection. The operations performed by TransportClientBootstrap are often expensive. Fortunately, the established connections can be reused. Used to initialize TransportClient |
| TransportChannelHandler | The handler of the transport layer is responsible for delegating the request to the TransportRequestHandler and delegating the response to the TransportResponseHandler. All channels created in the transport layer are bidirectional. When the client uses the RequestMessage to start the Netty Channel (processed by the Server's RequestHandler), the Server will generate a ResponseMessage (processed by the client's ResponseHandler). However, the Server will also get the handle on the same Channel, so it may start sending RequestMessages to the client. This means that the client also needs a RequestHandler, while the Server needs a ResponseHandler for the client's response to the Server's request. This class also handles data from Io Netty. handler. timeout. Timeout for idlestatehandler. If there are outstanding extraction or RPC requests and the Channel is idle for more than requestTimeoutMs, we consider the connection timeout. When the request read by TransportChannelHandler is of RequestMessage type, the processing of this message will be further handed over to TransportRequestHandler. When the request is ResponseMessage, the processing of this message will be further handed over to TransportResponseHandler |
| TransportResponseHandler | It is used to process the response of the server and respond to the requesting client |
| TransportRequestHandler | It is used to process the request of the client and return after writing the block data |
| MessageEncoder | Before putting the message into the pipeline, encode the message content to prevent packet loss and parsing error when reading at the other end of the pipeline |
| MessageDecoder | Parse the ByteBuf read from the pipeline to prevent packet loss and parsing errors |
| TransportFrameDecoder | The ByteBuf read from the pipeline is parsed according to the data frame |
| StreamManager | Processing ChunkFetchRequest and StreamRequest requests |
| RpcHandler | Processing RpcRequest and OneWayMessage requests |
| Message | Message is the abstract interface of message. Message implementation classes implement RequestMessage or ResponseMessage interfaces directly or indirectly |
3, Component principle
3.1 Message
Protocol is the basis of application layer communication. It provides data representation, encoding and decoding capabilities of application layer communication. In Spark Network Common, it inherits the definition in Akka and names the protocol Message. It inherits encodeable and provides the ability of Encode.
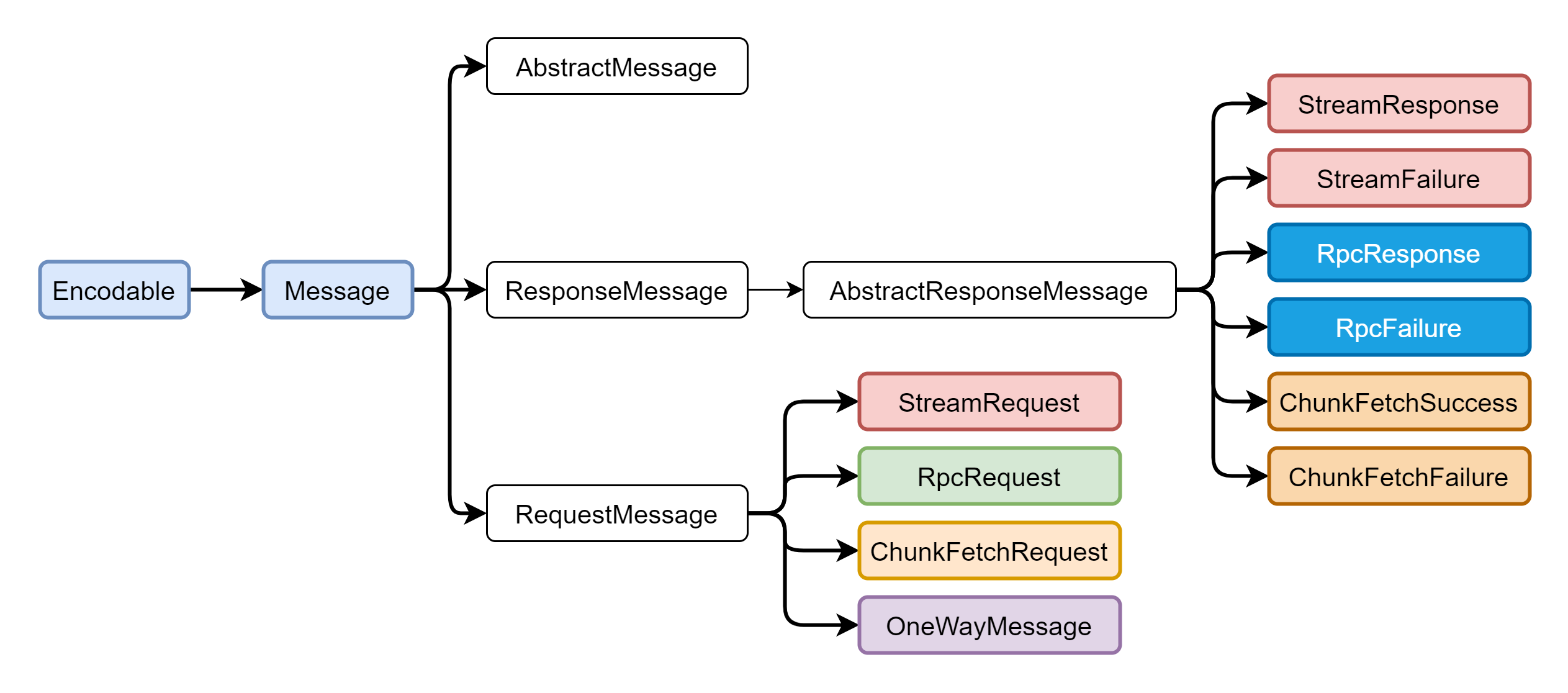
There are four specific implementations of RequestMessage:
- StreamRequest: this type of message indicates that a request is made to a remote service to obtain streaming data. Stream message is mainly used to transfer jar and file files from Driver to executor.
- RpcRequest: this kind of message is mainly the message that the remote Rpc server needs to process. It is a type of Rpc request information that the server needs to reply to the client.
- ChunkFetchRequest: request to get the sequence of a single block of the stream. ChunkFetch message is used to abstract all messages that need to be transmitted when data pull operations are involved in Spark.
- OneWayMessage: this kind of message also needs to be processed by the remote RPC server. Unlike RpcRequest, the server does not need to reply to the client.
Since OneWayMessage does not require a response, ResponseMessage has two implementations for success or failure status, namely:
- StreamResponse: the message returned after successfully processing StreamRequest;
- StreamFailure: the message returned after processing the StreamRequest failure;
- RpcResponse: the message returned after RpcRequest is processed successfully;
- RpcFailure: the message returned after processing RpcRequest failure;
- ChunkFetchSuccess: the message returned after processing the successful ChunkFetchRequest;
- ChunkFetchFailure: processing the messages returned after the ChunkFetchRequest fails;
3.2 communication architecture
Spark's Rpc framework is based on Actor model. Each component can be considered as an independent entity, and each entity communicates through messages. The relationship between specific components is as follows:
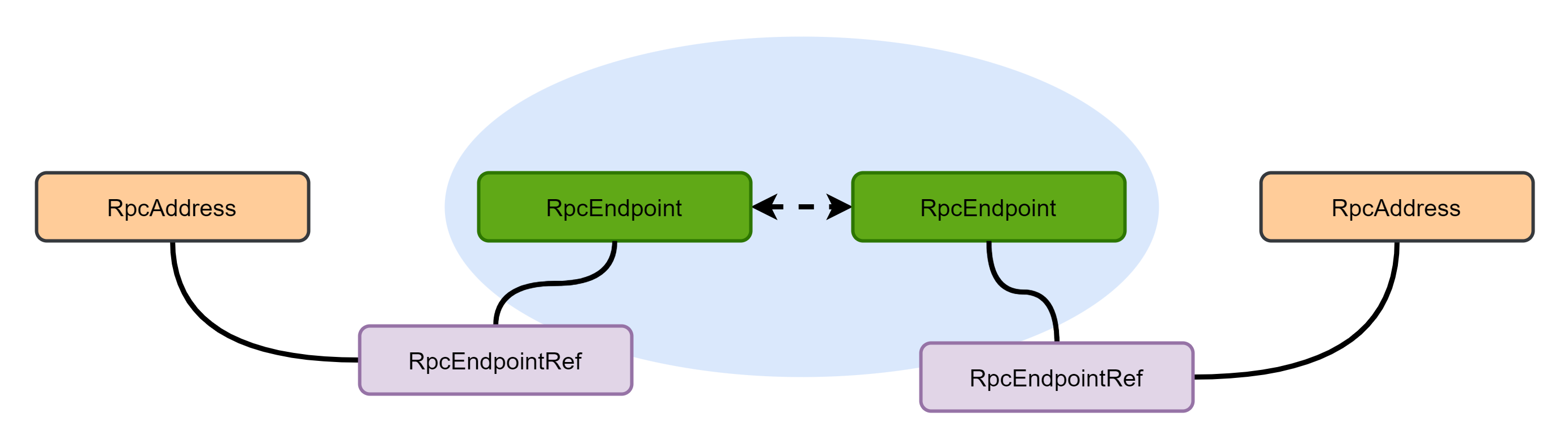
- RpcEnv: provides an environment for RpcEndpoint to process messages. RpcEnv is responsible for the management of the entire life cycle of RpcEndpoint, including Endpoint registration, message routing between endpoints, and Endpoint stop. NettyRpcEnv is currently its only implementation.
- RpcEndpoint: the server performs corresponding processing according to the received message type. The process of an RpcEndpoint is: create - > OnStart - > receive - > onstop. Among them, onStart calls before receiving the task message (when it is registered as the first self processing message call), receive and receiveAndReply are used to receive messages from send and ask respectively.
- RpcEndpointRef: client, which is a reference to a remote RpcEndpoint. When we need to send a message to a specific RpcEndpoint, we generally need to obtain the reference of the RpcEndpoint, and then send the message through the reference, providing the message sending methods of send (one-way sending, providing fire and forget semantics) and ask (with returned request, providing request response semantics). Among them, the ask method that needs to return the response is provided with a timeout mechanism, which can synchronously block the wait or return a Future handle without blocking the worker thread that initiated the request. In addition, rpcandpointref can automatically distinguish between local calls and remote Rpc calls.
- RpcAddress: indicates the address of the remote rpcandpointref, including host and port.
3.3 SparkEnv initialization
SparkEnv saves the environment information of Application runtime, including RpcEnv, Serializer, Block Manager and ShuffleManager, and provides different creation methods for Driver and Executor respectively. Among them, RpcEnv maintains the communication between Spark nodes and is responsible for forwarding the delivered messages to RpcEndpoint.
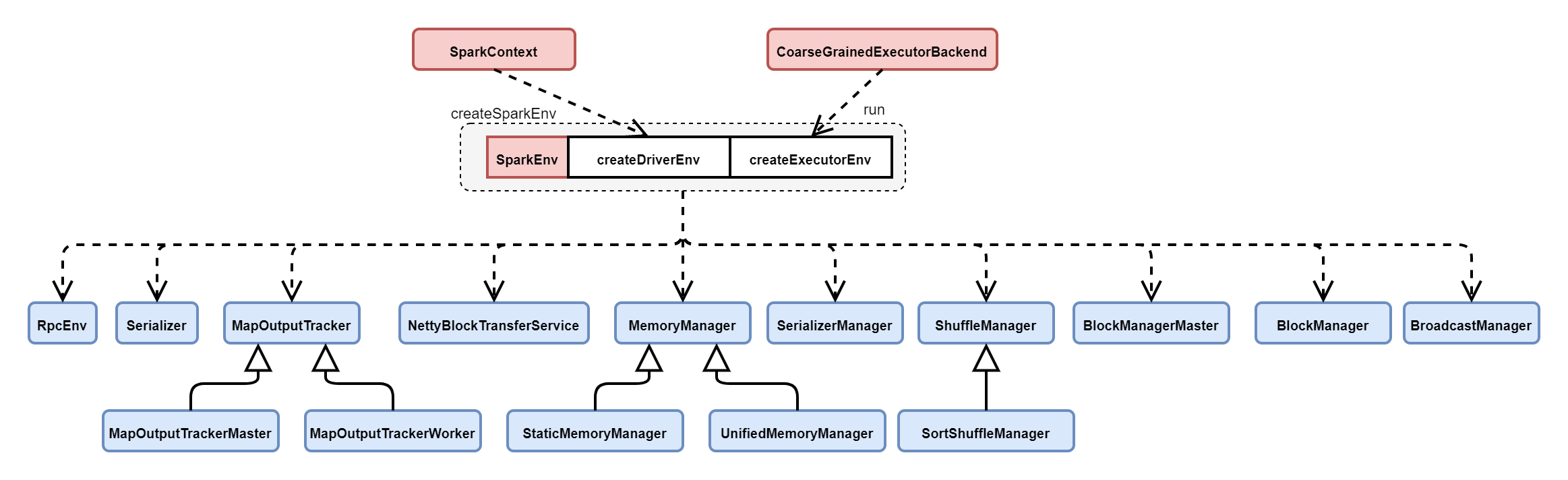
You can see that the CoarseGrainedExecutorBackend entry class is responsible for starting the Executor. Take the RpcEnv initialization description of sparkExecutor as an example to see the code logic of createExecutorEnv():
private[spark] object CoarseGrainedExecutorBackend extends Logging {
private def run(
driverUrl: String,
executorId: String,
hostname: String,
cores: Int,
appId: String,
workerUrl: Option[String],
userClassPath: Seq[URL]) {
...
// Create SparkEnv
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, port, cores, cfg.ioEncryptionKey, isLocal = false)
// Register CoarseGrainedExecutorBackend
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
// Register WorkerWatcher
workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
SparkHadoopUtil.get.stopCredentialUpdater()
}
}
def main(args: Array[String]) {
...
run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)
System.exit(0)
}
}
SparkEnv#createExecutorEnv code logic
object SparkEnv extends Logging {
private[spark] val driverSystemName = "sparkDriver"
private[spark] val executorSystemName = "sparkExecutor"
/**
* Create a coarse-grained Executor SparkEnv
*/
private[spark] def createExecutorEnv(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
numCores: Int,
ioEncryptionKey: Option[Array[Byte]],
isLocal: Boolean): SparkEnv = {
val env = create(
conf,
executorId,
hostname,
hostname,
port,
isLocal,
numCores,
ioEncryptionKey
)
SparkEnv.set(env)
env
}
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
// Determine whether it is a Driver
val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER
// Driver must have listener bus
if (isDriver) {
assert(listenerBus != null, "Attempted to create driver SparkEnv with null listener bus!")
}
// Create SecurityManager
val securityManager = new SecurityManager(conf, ioEncryptionKey)
ioEncryptionKey.foreach { _ =>
if (!securityManager.isSaslEncryptionEnabled()) {
logWarning("I/O encryption enabled without RPC encryption: keys will be visible on the " +
"wire.")
}
}
// Start app name
val systemName = if (isDriver) driverSystemName else executorSystemName
val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port, conf,
securityManager, clientMode = !isDriver)
// Specify the actual binding port number of RpcEnv to prevent the port from being 0 or occupied.
// In non drive mode, the RpcEnv address may be empty because it will not listen for incoming links.
if (isDriver) {
conf.set("spark.driver.port", rpcEnv.address.port.toString)
} else if (rpcEnv.address != null) {
conf.set("spark.executor.port", rpcEnv.address.port.toString)
logInfo(s"Setting spark.executor.port to: ${rpcEnv.address.port.toString}")
}
...
// Create serializer
val serializer = instantiateClassFromConf[Serializer](
"spark.serializer", "org.apache.spark.serializer.JavaSerializer")
logDebug(s"Using serializer: ${serializer.getClass}")
val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey)
val closureSerializer = new JavaSerializer(conf)
def registerOrLookupEndpoint(
name: String, endpointCreator: => RpcEndpoint):
RpcEndpointRef = {
if (isDriver) {
logInfo("Registering " + name)
rpcEnv.setupEndpoint(name, endpointCreator)
} else {
RpcUtils.makeDriverRef(name, conf, rpcEnv)
}
}
// Create BroadcastManager
val broadcastManager = new BroadcastManager(isDriver, conf, securityManager)
val mapOutputTracker = if (isDriver) {
new MapOutputTrackerMaster(conf, broadcastManager, isLocal)
} else {
new MapOutputTrackerWorker(conf)
}
// Have to assign trackerEndpoint after initialization as MapOutputTrackerEndpoint
// requires the MapOutputTracker itself
mapOutputTracker.trackerEndpoint = registerOrLookupEndpoint(MapOutputTracker.ENDPOINT_NAME,
new MapOutputTrackerMasterEndpoint(
rpcEnv, mapOutputTracker.asInstanceOf[MapOutputTrackerMaster], conf))
// Specify ShuffleManager
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
// Specify memory manager
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores)
} else {
UnifiedMemoryManager(conf, numUsableCores)
}
val blockManagerPort = if (isDriver) {
conf.get(DRIVER_BLOCK_MANAGER_PORT)
} else {
conf.get(BLOCK_MANAGER_PORT)
}
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, bindAddress, advertiseAddress,
blockManagerPort, numUsableCores)
// Create BlockManagerMaster
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
// NB: blockManager is not valid until initialize() is called later.
val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,
serializerManager, conf, memoryManager, mapOutputTracker, shuffleManager,
blockTransferService, securityManager, numUsableCores)
val metricsSystem = if (isDriver) {
// Don't start metrics system right now for Driver.
// We need to wait for the task scheduler to give us an app ID.
// Then we can start the metrics system.
MetricsSystem.createMetricsSystem("driver", conf, securityManager)
} else {
// We need to set the executor ID before the MetricsSystem is created because sources and
// sinks specified in the metrics configuration file will want to incorporate this executor's
// ID into the metrics they report.
conf.set("spark.executor.id", executorId)
val ms = MetricsSystem.createMetricsSystem("executor", conf, securityManager)
ms.start()
ms
}
// Create OutputCommitCoordinator
val outputCommitCoordinator = mockOutputCommitCoordinator.getOrElse {
new OutputCommitCoordinator(conf, isDriver)
}
val outputCommitCoordinatorRef = registerOrLookupEndpoint("OutputCommitCoordinator",
new OutputCommitCoordinatorEndpoint(rpcEnv, outputCommitCoordinator))
outputCommitCoordinator.coordinatorRef = Some(outputCommitCoordinatorRef)
// Create SparkEnv
val envInstance = new SparkEnv(
executorId,
rpcEnv,
serializer,
closureSerializer,
serializerManager,
mapOutputTracker,
shuffleManager,
broadcastManager,
blockManager,
securityManager,
metricsSystem,
memoryManager,
outputCommitCoordinator,
conf)
// Add a reference to tmp dir created by driver, we will delete this tmp dir when stop() is
// called, and we only need to do it for driver. Because driver may run as a service, and if we
// don't delete this tmp dir when sc is stopped, then will create too many tmp dirs.
if (isDriver) {
val sparkFilesDir = Utils.createTempDir(Utils.getLocalDir(conf), "userFiles").getAbsolutePath
envInstance.driverTmpDir = Some(sparkFilesDir)
}
envInstance
}
3.4 RpcEnv
RpcEnv is not only basically consistent with Akka from the external interface, but also basically similar in the internal implementation, which is implemented according to the design idea of MailBox;
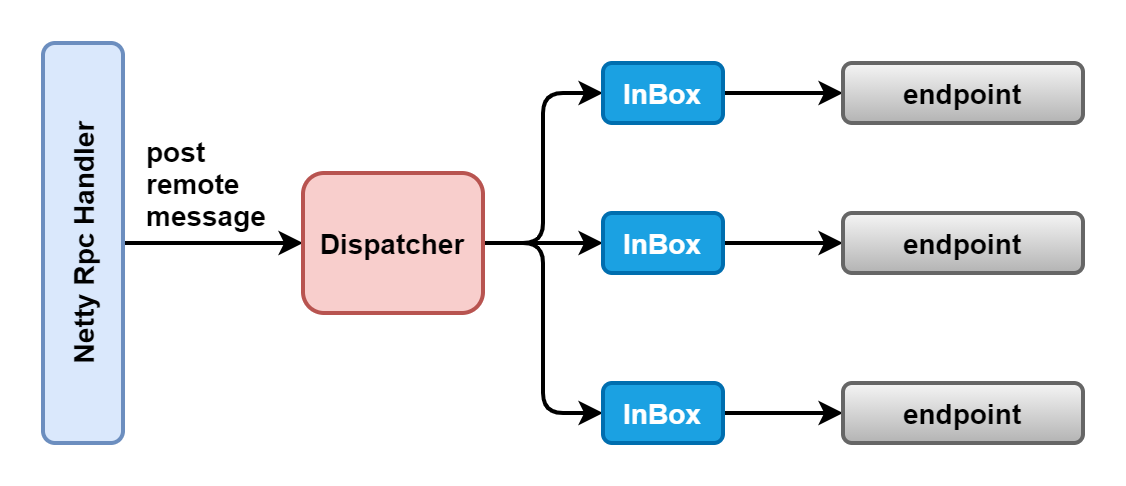
RpcEnv Server model:
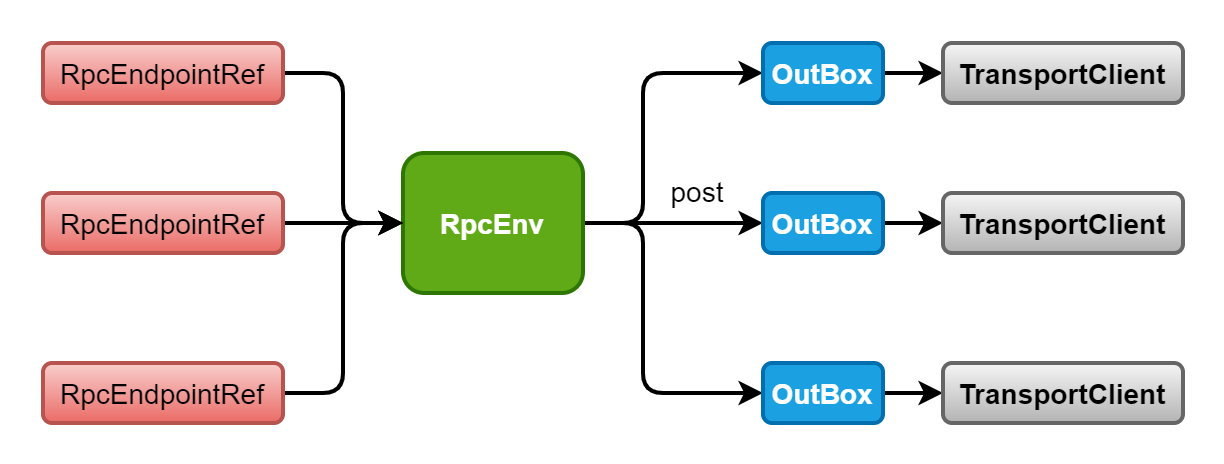
RpcEnv Client model:
As shown in the figure above, RpcEnv acts as a Server and also provides an internal implementation Client. When serving as a Server, RpcEnv initializes a Server and registers NettyRpcHandler. In general, simple services can directly process requests in RpcHandler. However, considering that many rpcendpoints are mounted on an RpcEnv Server, the RPC request frequency of each RpcEndpoint is uncontrollable, so it is necessary to maintain these requests with a certain distribution mechanism and queue, Dispatcher is the distributor and InBox is the request queue;
In the process of registering the RpcEndpoint with the RpcEnv, the RpcEnv is also indirectly registered with the Dispatcher distributor. The Dispatcher maintains an InBox for each RpcEndpoint and maintains a thread pool in the Dispatcher (the thread pool size is the number of cores available to the system by default. Of course, it can also be configured through spark.rpc.netty.dispatcher.numThreads), The thread processes the requests in each InBox. Of course, the actual processing process is completed by RpcEndpoint.
Secondly, RpcEnv also completes the function implementation of the Client. RpcEndpoint ref is based on RpcEndpoint, that is, if a process needs to communicate with N RpcEndpoint services on the remote machine, it corresponds to N RpcEndpoint refs (the actual network connection at the back end is public, which is realized by the connection pool provided in the TransportClient), When calling an ask/send interface of rpcandpointref, the message content + rpcandpointref + local address will be packaged into a RequestMessage and sent by RpcEnv. Note that it is important to include rpcandpointref in the packaged message, so that the Server can identify which rpcandpointref this message corresponds to.
Like the sender, in RpcEnv, a queue is maintained for the host:port of each remote end, that is, OutBox. The sending of RpcEnv only puts messages into the corresponding queue. However, unlike the sender, a so-called thread pool is not maintained in the OutBox to clean up the OutBox at fixed time, but is realized through a pile of synchronized
Let's take a look at the class diagram related to RpcEnv: