preface:
- I don't know when it came out that using try catch in Java will seriously affect performance.
However, is this really the case? Should we be afraid of try catch like tigers?
1, JVM exception handling logic
-
Explicit exception throwing in Java programs is supported by the arrow instruction. In addition to actively throwing exceptions through throw, the JVM specification also stipulates that many runtime exceptions will be thrown automatically when an exception condition is detected (the effect is the same as that of arrow). For example, exceptions will be thrown automatically when the divisor is 0, and the famous NullPointerException.
-
It should also be noted that the catch statement for exception handling in the JVM is no longer implemented by bytecode instructions (jsr and ret instructions were completed a long time ago, which were abandoned in the previous version). The current JVM completes the catch statement through the Exception table (its content can be found in the Exception table method body); Many people say that the impact of try catch on performance may be because the understanding still stays in ancient times.
- We write the following classes to calculate + + x in the add method; And catch exceptions.
public class TestClass {
private static int len = 779;
public int add(int x){
try {
// If x = 0 is detected at runtime, the jvm will automatically throw an exception (it can be understood that the jvm is responsible for calling the arrow instruction)
x = 100/x;
} catch (Exception e) {
x = 100;
}
return x;
}
}
-
Use the javap tool to view the compiled class file of the above class
# compile javac TestClass.java # Use javap to view the machine instructions after the add method is compiled javap -verbose TestClass.class
Ignoring the constant pool and other information, the machine instruction set compiled by the add method is posted below:
public int add(int);
descriptor: (I)I
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=2
0: bipush 100 // Load parameter 100
2: iload_1 // Push an int variable to the top of the stack
3: idiv // be divided by
4: istore_1 // The result value of division is pushed into the local variable
5: goto 11 // Jump to instruction: 11
8: astore_2 // Push reference type values into local variables
9: bipush 100 // Push the single byte constant to the top of the stack < this is related to the value 100. You can try to modify the compilation resu lt s after 100: iconst, bipush, LDC >
10: istore_1 // Push int type values into local variables
11: iload_1 // Push stack top of int variable
12: ireturn // return
// Pay attention to the from, to and starter, and then look at the above instructions against each other
Exception table:
from to target type
0 5 8 Class java/lang/Exception
LineNumberTable:
line 6: 0
line 9: 5
line 7: 8
line 8: 9
line 10: 11
StackMapTable: number_of_entries = 2
frame_type = 72 /* same_locals_1_stack_item */
stack = [ class java/lang/Exception ]
frame_type = 2 /* same */
Let's look at the Exception table:

from=0, to=5. Instructions 0 ~ 5 correspond to the contents of the try statement, and targer = 8 exactly corresponds to the internal operation of the catch statement block.
- Personally, from and to are equivalent to dividing an interval. As long as the "java/lang/Exception" exception corresponding to the type is thrown in this interval (active arrow or automatically thrown when the jvm runtime detects an exception), it will jump to the eighth line represented by the target.
If there is no exception during execution, jump directly from the 5th instruction to the 11th instruction and return. It can be seen that when there is no exception, the so-called performance loss hardly exists;
- If you insist, the length of the instructions becomes longer after compiling with try catch; Goto statements cost performance. When you write a method with hundreds of lines of code, hundreds of instructions will be compiled. At this time, the impact of this goto statement is minimal.
As shown in the figure, the length of the instruction after removing the try catch is almost the same as the first five of the above instructions.
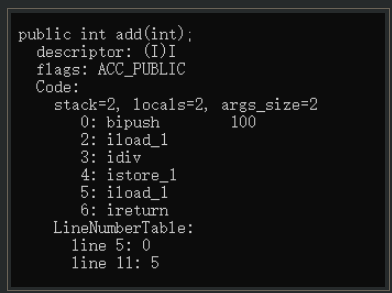
- To sum up, "using try catch in Java will seriously affect performance" is a folk saying, which is not true. If you don't believe it, go on to the following test.
2, Compilation optimization of JVM
In fact, it is not very difficult to write test cases. Here we need to focus on the automatic optimization of the compiler. Will we get different test results?
This section will briefly introduce some concepts related to JVM compiler, saying that it is only for more accurate test results. Through it, we can see whether try catch will affect the compilation optimization of JVM.
-
Front end compilation and Optimization: our most common front-end compiler is javac, and its optimization is more inclined to the optimization of code structure. It is mainly to improve the coding efficiency of programmers and does not pay much attention to the optimization of execution efficiency; For example, data flow and control flow analysis, parsing sugar, and so on.
-
Back end compilation and Optimization: back end compilation includes "just in time compilation [JIT]" and "early compilation [AOT]", which are different from the front-end compiler. Their final role is reflected in the runtime and are committed to optimizing the process of generating local machine code from bytecode (they optimize the execution efficiency of code).
1. Layered compilation
PS * the JVM determines its own operation mode according to the host, "JVM operation mode"; [Client mode client and Server mode Server], they represent two different real-time compilers, C1(Client Compiler) and C2 (Server Compiler).
PS * layered compilation is divided into: "interpretation mode", "compilation mode" and "mixed mode";
-
When running in interpretation mode, the compiler does not intervene;
-
Running in compilation mode, it will use the instant compiler to optimize hot code, with optional instant compiler [C1 or C2];
-
The mixed mode is the combination of interpretation mode and compilation mode.
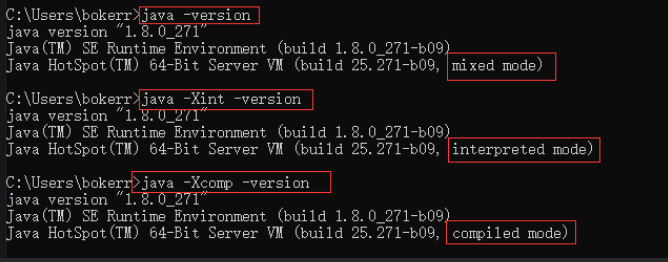
As shown in the figure, the JVM in my environment runs in Server mode. If instant compilation is used, it is the C2 instant compiler.
2. Just in time compiler
Understand the following concepts:
1. Interpretation mode
It does not use an immediate compiler for back-end optimization
-
Force the virtual machine to run in interpretation mode - Xint
-
Disable background compilation - XX:-BackgroundCompilation
2. Compilation mode
The real-time compiler will optimize the generated local machine code at runtime, focusing on the hot code.
# Force the virtual machine to run in compile mode
-Xcomp
# Method call count counter threshold, which is based on counter hotspot code detection basis [Client mode = 1500,Server mode = 10000]
-XX:CompileThreshold=10
# Turn off the heat attenuation of method call times, and use the absolute value of method call count, which is used with the previous configuration item
-XX:-UseCounterDecay
# In addition to the hot spot method, there is also the hot spot edge return code [loop]. The threshold calculation of the hot spot edge return code is as follows:
-XX:BackEdgeThreshold = Method counter threshold[-XX:CompileThreshold] * OSR ratio[-XX:OnStackReplacePercentage]
# Default value of OSR ratio: Client mode = 933, Server mode = 140
-XX:OnStackReplacePercentag=100
- The so-called "instant" occurs during operation, so its disadvantages are also obvious: it needs to spend resources to do performance analysis during operation, and it is not suitable to do some resource-consuming heavy load optimization operations during operation.
3. Advance compiler: jaotc
-
It is another protagonist of back-end compilation. It has two development routes. It is developed based on Graal [protagonist of the new era] compiler. Because this paper uses C2 compiler, we only know about it;
-
The first route: similar to the traditional C and C + + compilation, compile the program code into machine code before the program runs; The advantage is that it is fast enough and does not occupy runtime system resources. The disadvantage is that the "startup process" will be very slow;
-
The second route: given that the real-time compilation runtime takes up resources for performance statistical analysis, we can put some resource consuming compilation work into the early compilation stage, and finally use the real-time compiler at runtime, which can greatly save the overhead of real-time compilation; This branch can think of it as an instant compilation cache;
-
Unfortunately, it only supports G1 or Parallel garbage collectors, and only exists after JDK 9. You don't need to pay attention to it for the time being; JDK 9 and later versions can use this parameter to print relevant information: [- XX:PrintAOT].
3, Constraints on testing
Execution time statistics
- System. The output of naotime() is the elapsed time [microseconds: the negative 9th power of 10 seconds], which is not a completely accurate method for the total execution time. In order to ensure the accuracy of the results, the number of test operations will be extended to one million or even ten million times.
Compiler optimization factors
- In the previous section, I spent some time on compiler optimization. What I want to do here is to compare the performance impact of try catch without any compilation optimization with that of real-time compilation.
-
Disable the compilation optimization of the JVM through the command, let it run in the most original state, and then see if there is the impact of try catch.
-
By using real-time compilation of instructions, try to fill the back-end optimization as much as possible. See if try catch will affect the compilation optimization of the jvm.
About instruction reordering
At present, it is not known that the use of try catch affects instruction reordering;
Our discussion here has a premise: when the use of try catch cannot be avoided, how should we use try catch to deal with its possible impact on instruction reordering.
-
Instruction reordering occurs in the multithreading concurrent scenario. This is to make better use of CPU resources. It does not need to be considered in single thread testing. No matter how the instructions are reordered, the final execution result will be the same as that under single thread;
-
Although we don't test it, we can also make some inferences. Refer to volatile keyword to prohibit instruction reordering: insert memory barrier;
-
It is assumed that there is a barrier in try catch, resulting in code segmentation before and after; Then the least try catch represents the least segmentation.
-
Therefore, is there such a conclusion: can we reduce the barrier by combining multiple try catches in the method into one try catch? This is bound to increase the range of try catch.
Of course, the above discussion on instruction reordering is based on personal conjecture. It is still unknown whether try catch affects instruction reordering; This article focuses on the performance impact of the use of try catch in a single threaded environment.
4, Test code
-
The number of cycles is 100W, and the budget for 10 times in the cycle [the possibility of optimization is reserved for compiler optimization, and these instructions may be combined];
-
Each method will reach tens of millions of floating-point calculations.
-
Similarly, each method runs several times, and it is more convincing to finally take the mode.
public class ExecuteTryCatch {
// 100W
private static final int TIMES = 1000000;
private static final float STEP_NUM = 1f;
private static final float START_NUM = Float.MIN_VALUE;
public static void main(String[] args){
int times = 50;
ExecuteTryCatch executeTryCatch = new ExecuteTryCatch();
// Each method is executed 50 times
while (--times >= 0){
System.out.println("times=".concat(String.valueOf(times)));
executeTryCatch.executeMillionsEveryTryWithFinally();
executeTryCatch.executeMillionsEveryTry();
executeTryCatch.executeMillionsOneTry();
executeTryCatch.executeMillionsNoneTry();
executeTryCatch.executeMillionsTestReOrder();
}
}
/**
* Ten million floating-point operations do not use try catch
* */
public void executeMillionsNoneTry(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("noneTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* try catch is used for the outermost layer of ten million floating-point operations
* */
public void executeMillionsOneTry(){
float num = START_NUM;
long start = System.nanoTime();
try {
for (int i = 0; i < TIMES; ++i){
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
} catch (Exception e){
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("oneTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* try catch is used in ten million floating-point operation loops
* */
public void executeMillionsEveryTry(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {
}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("evertTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* try catch is used in ten million floating-point operation loops, and finally is used
* */
public void executeMillionsEveryTryWithFinally(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {
} finally {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("finalTry sum:" + num + " million:" + million + " nao: " + nao);
}
/**
* Ten million floating-point operations, multiple try catch es in the loop
* */
public void executeMillionsTestReOrder(){
float num = START_NUM;
long start = System.nanoTime();
for (int i = 0; i < TIMES; ++i){
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
} catch (Exception e) { }
try {
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e){}
try {
num = num + STEP_NUM + 1f;
num = num + STEP_NUM + 2f;
} catch (Exception e) { }
try {
num = num + STEP_NUM + 3f;
num = num + STEP_NUM + 4f;
num = num + STEP_NUM + 5f;
} catch (Exception e) {}
}
long nao = System.nanoTime() - start;
long million = nao / 1000000;
System.out.println("orderTry sum:" + num + " million:" + million + " nao: " + nao);
}
}
5, Performing tests in interpretation mode
-
Set the following JVM parameters to disable compilation optimization
-Xint -XX:-BackgroundCompilation
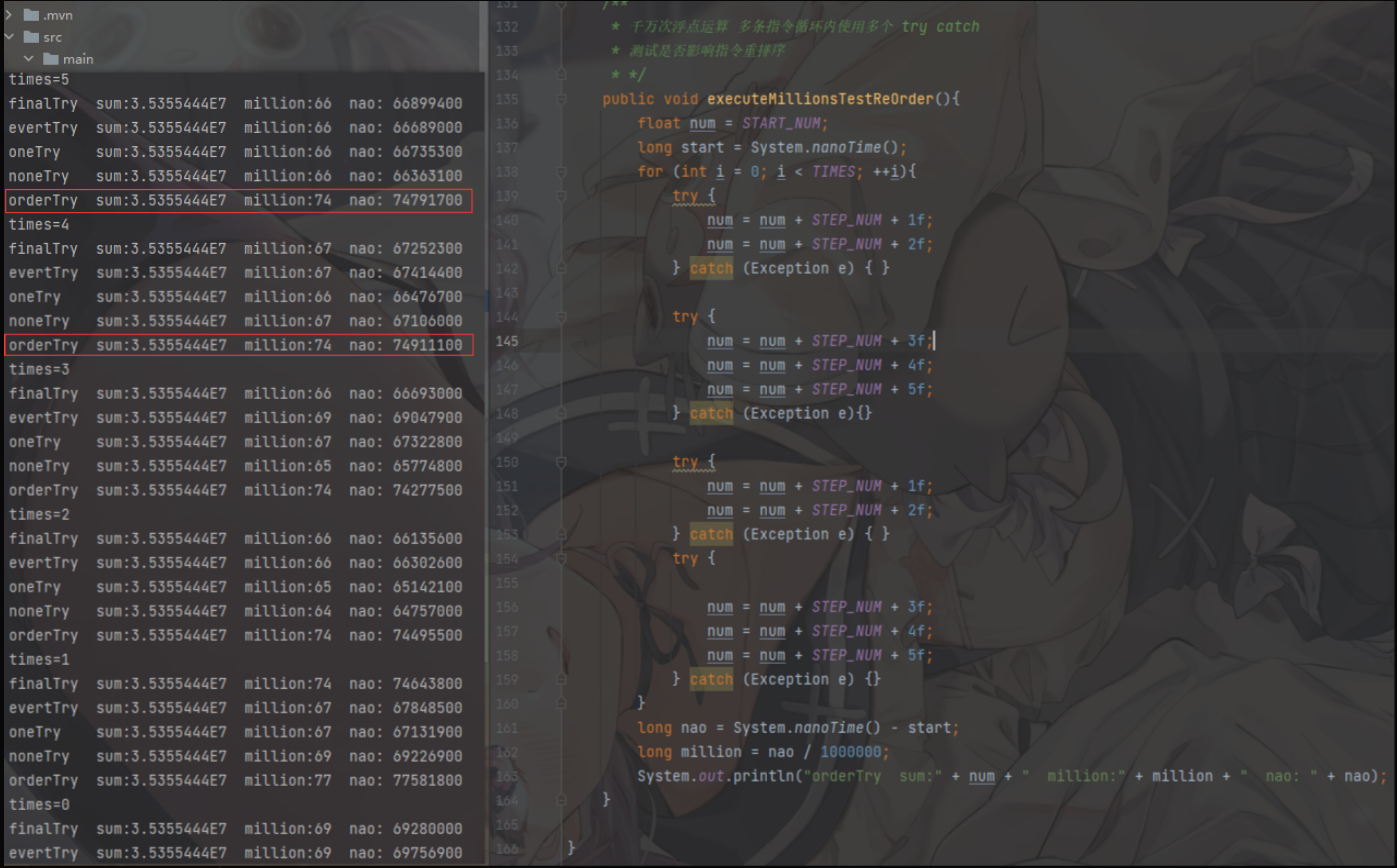
- Combined with the test code, it is found that even if millions of cycles are calculated, the use of try catch in each cycle is useless, which has a great impact on the.
The only problem found is that try catch is used multiple times in each loop. It is found that the performance is degraded, and the difference of ten million calculations is: 5 ~ 7 milliseconds; If there are four tries, there are at least four goto instructions executed. As explained earlier, the main reason for this difference is that the goto instructions account for too much, which amplifies the problem; When we use a small amount of try catch in hundreds of lines of code, the proportion of goto will be very low, and the test results will be more reasonable.
6, Compile mode test
-
Set the following test parameters and execute them 10 times, which is the hotspot code
-Xcomp -XX:CompileThreshold=10 -XX:-UseCounterDecay -XX:OnStackReplacePercentage=100 -XX:InterpreterProfilePercentage=33
-
The execution results are shown in the figure below. It is difficult to decide the outcome. The fluctuation is only at the microsecond level, and the execution speed is much faster. The compilation effect is outstanding. Even the problems caused by multiple try catches and multiple goto jumps during the "interpretation mode" operation have been optimized; It can also be concluded that try catch does not affect immediate compilation.
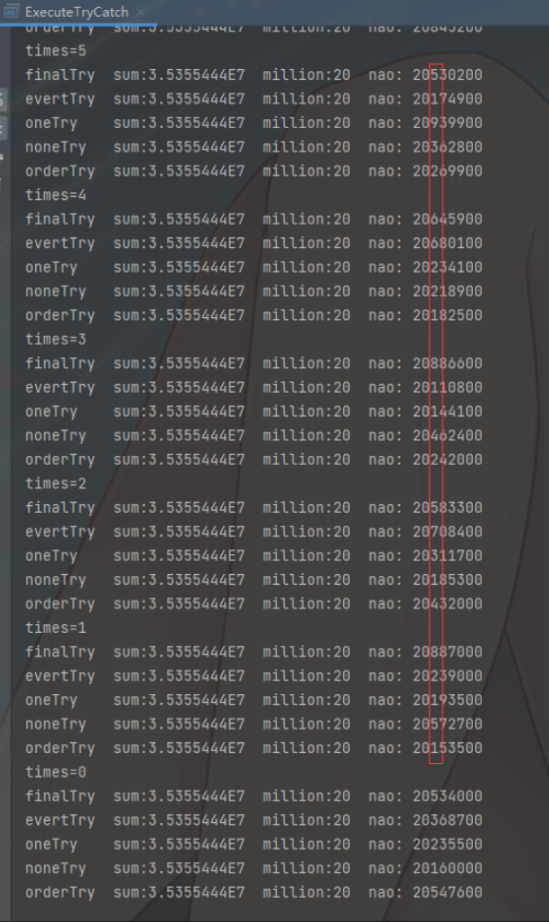
- We can rise to the billion level of calculation, and it is still difficult to win or lose. The fluctuation is on the millisecond level.
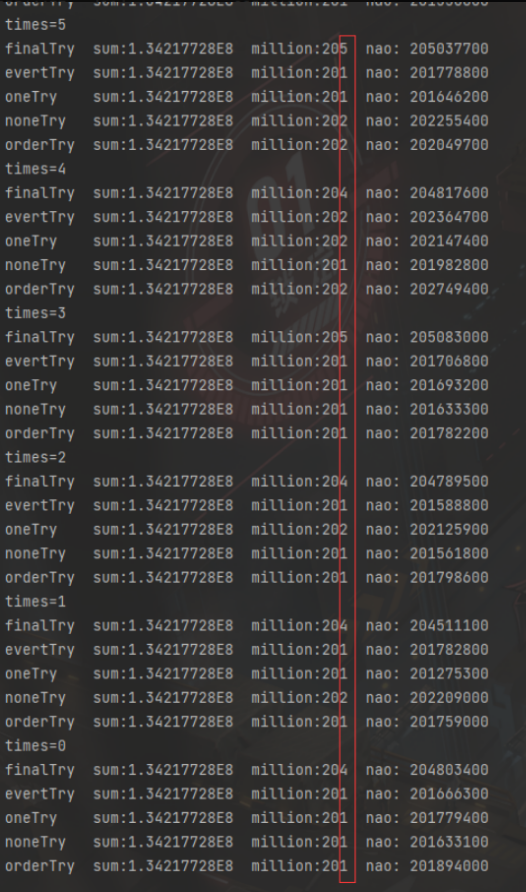
7, Conclusion
Try catch will not have a huge performance impact. In other words, the most priority we usually give to writing code is the robustness of the program. Of course, the bosses must know how to use try catch reasonably, but for Mengxin, if you are not sure, you can use try catch;
When no exception occurs, try catch on the external package of the code will not affect it.
Take chestnuts for example. I used urldecoder in my code Decode, so you have to catch exceptions.
private int getThenAddNoJudge(JSONObject json, String key){
if (Objects.isNull(json))
throw new IllegalArgumentException("Parameter exception");
int num;
try {
// Do not check whether the key is not null, directly call toString, and each time a null pointer exception is triggered and caught
num = 100 + Integer.parseInt(URLDecoder.decode(json.get(key).toString(), "UTF-8"));
} catch (Exception e){
num = 100;
}
return num;
}
private int getThenAddWithJudge(JSONObject json, String key){
if (Objects.isNull(json))
throw new IllegalArgumentException("Parameter exception");
int num;
try {
// Check whether the key is not null
num = 100 + Integer.parseInt(URLDecoder.decode(Objects.toString(json.get(key), "0"), "UTF-8"));
} catch (Exception e){
num = 100;
}
return num;
}
public static void main(String[] args){
int times = 1000000;// Million times
long nao1 = System.nanoTime();
ExecuteTryCatch executeTryCatch = new ExecuteTryCatch();
for (int i = 0; i < times; i++){
executeTryCatch.getThenAddWithJudge(new JSONObject(), "anyKey");
}
long end1 = System.nanoTime();
System.out.println("Time consuming for not throwing exception: millions=" + (end1 - nao1) / 1000000 + "millisecond nao=" + (end1 - nao1) + "Microsecond");
long nao2 = System.nanoTime();
for (int i = 0; i < times; i++){
executeTryCatch.getThenAddNoJudge(new JSONObject(), "anyKey");
}
long end2 = System.nanoTime();
System.out.println("Exceptions must be thrown each time: millions=" + (end2 - nao2) / 1000000 + "millisecond nao=" + (end2 - nao2) + "Microsecond");
}
The method is called millions of times, and the execution results are as follows:

After this example, I think you know how to write your code? The terrible thing is not try catch, but unskilled brick moving business.