1. Scrapy Crawler Framework
1. Scrapy is not a function library, but a crawler framework
A crawler framework is a collection of software structures and functional components that implement the crawler function
The crawler framework is a semi-finished product that helps users achieve professional web crawling
2.'5+2'structure
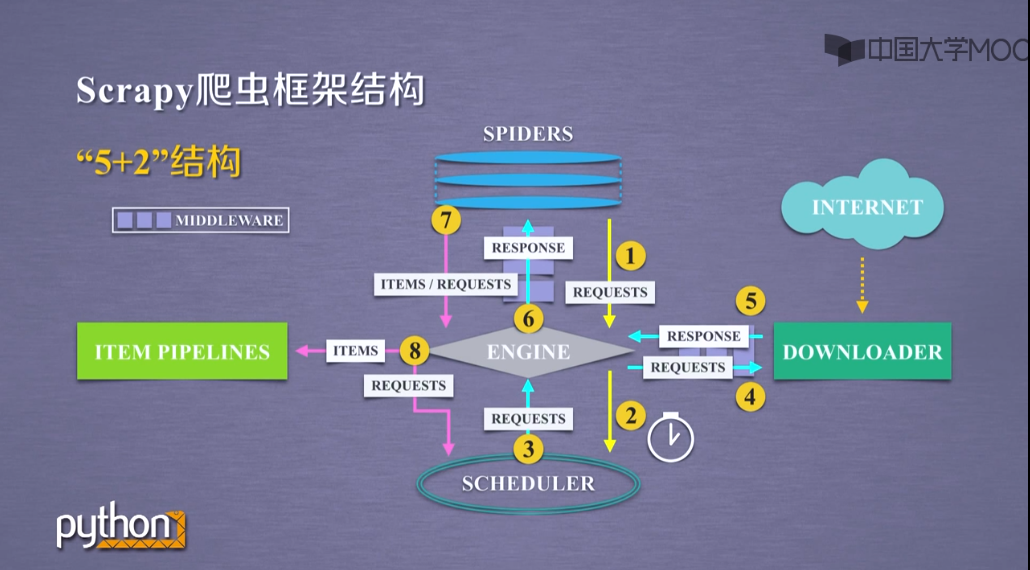
(1) Engine (no user modification required)
Controlling data flow between all modules
Trigger events based on conditions
(2) Downloader (no user modification required)
Download Web pages on request
Scheduler (no user modification required)
Schedule all crawl requests
(3)Downloader Middleware
Purpose: To implement user-configurable control between Engine, Scheduler, and Downloader
Functions: modify, discard, add requests or responses
Users can write configuration code
(4)Spider
Resolve the response returned by Downloader (Response)
Generate a scrapy item
Generate additional crawl requests
Require user to write configuration code
(5)Item Pipelines
Pipeline crawl items generated by Spider
It consists of a set of sequence operations, similar to pipelining, each of which is an Item Pipelines type
Possible operations include cleaning up, validating, and retrieving HTML data in crawled items, and storing the data in a database
(6)Spider Middleware
Purpose: Reprocessing requests and crawled items
Functions: modify, discard, add requests or crawl items
Users can write configuration code
2. Comparison of Request Library and Scrapy Crawlers
1. Identity
Both can make page requests and crawls, two important technical routes for Python Crawlers
Both are usable, documented and easy to get started
Neither handles JS, submits forms, copes with validation codes (extensible)
2. Differences
| Request | Scrapy |
| Page-level Crawlers | Site-level Crawlers |
| Functional Library | frame |
| Insufficient consideration of concurrency and poor performance | Good concurrency and high performance |
| Focus on page downloads | Focus on crawl structure |
| Customization flexibility | General customization flexibility, deep customization difficulties |
| Easy to start with | It's a little difficult to get started |
3. Scrapy command line
Scrapy is a professional crawler framework designed to run continuously, providing an operational Scrapy command line
1. Command Line Format
1 scrapy <command> [options] [args]
2. Common Scrapy Commands
| command | Explain | format |
| startproject | Create a new project | scrapy startproject<name>[dir] |
| genspider | Create a crawler | scrapy genspider[options]<name><domain> |
| settings | Get crawler configuration information | scrapy settings[options] |
| crawl | Run a crawler | scrapy crawl<spider> |
| list | List all crawlers in the project | scrapy list |
| shell | Launch URL Invoke Command Line | scrapy shell[url] |
4. Examples
1. Create a scrapy crawler project
Command Line Statements
1 scrapy startproject python123demo #Create a new " python123demo"Crawler Project for Project Name
The project directory is D:\Codes\Python>
1 D:\Codes\Python>scrapy startproject python123demo 2 New Scrapy project 'python123demo', using template directory 'd:\codes\python\venv\lib\site-packages\scrapy\templates\project', created in: 3 D:\Codes\Python\python123demo 4 5 You can start your first spider with: 6 cd python123demo 7 scrapy genspider example example.com
python123demo/ Outer directory
scrapy.cfg * Deploy configuration files for Scrapy Crawlers
python123demo/ * User-defined Python code for the Scrapy framework
Initialization script
Items.py * Items code template (inherited class)
middlewares.py) Middlewares code template (inherited class)
Pipelines Code Template (Inherited Class)
settings.py) Scrapy Crawler Configuration File
Spiders/ Spiders Code Template Directory (Inherited Classes)
_init_.py) Initial file, no modification required
_pycache_/ Cache directory, no modification required
2. Create a Scrapy crawl in the project
Command Line Statements
1 1 cd python123demo #open python123demo Folder 2 2 scrapy genspider demo python123.io #Create a crawler
Open the file directory before crawling
1 D:\Codes\Python>cd python123demo 2 3 (venv) D:\Codes\Python\python123demo>scrapy genspider demo python123.io 4 Created spider 'demo' using template 'basic' in module: 5 python123demo.spiders.demo
A demo.py file is generated in the spiders folder
Content is
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 5 class DemoSpider(scrapy.Spider): 6 name = 'demo' 7 allowed_domains = ['python123.io'] 8 start_urls = ['http://python123.io/'] 9 10 def parse(self, response): 11 pass
parse() is used to process responses, parse content to form a dictionary, and discover new URL crawl requests
3. Configured spider crawls
Modify demo.py content
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 5 class DemoSpider(scrapy.Spider): 6 name = 'demo' 7 #allowed_domains = ['python123.io'] 8 start_urls = ['http://python123.io/ws/demo.html'] 9 10 def parse(self, response): 11 fname = response.url.split('/')[-1] 12 with open(fname,'wb') as f: 13 f.write(response.body) #Save the returned content as a file 14 self.log('Saved file %s.'% fname)
4. Run crawlers to get web pages
command line
1 scrapy crawl demo
Running crawls
1 D:\Codes\Python\python123demo>scrapy crawl demo 2 2020-03-19 11:25:40 [scrapy.utils.log] INFO: Scrapy 2.0.0 started (bot: python123demo) 3 2020-03-19 11:25:40 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 22:39:24) [MSC v.1916 32 bit (Intel)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 4 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0 5 2020-03-19 11:25:40 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor 6 2020-03-19 11:25:41 [scrapy.crawler] INFO: Overridden settings: 7 {'BOT_NAME': 'python123demo', 8 'NEWSPIDER_MODULE': 'python123demo.spiders', 9 'ROBOTSTXT_OBEY': True, 10 'SPIDER_MODULES': ['python123demo.spiders']} 11 2020-03-19 11:25:41 [scrapy.extensions.telnet] INFO: Telnet Password: dbe958957137573b 12 2020-03-19 11:25:41 [scrapy.middleware] INFO: Enabled extensions: 13 ['scrapy.extensions.corestats.CoreStats', 14 'scrapy.extensions.telnet.TelnetConsole', 15 'scrapy.extensions.logstats.LogStats'] 16 2020-03-19 11:25:42 [scrapy.middleware] INFO: Enabled downloader middlewares: 17 ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 18 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 19 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 20 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 21 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 22 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 23 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 24 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 25 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 26 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 27 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 28 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 29 2020-03-19 11:25:42 [scrapy.middleware] INFO: Enabled spider middlewares: 30 ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 31 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 32 'scrapy.spidermiddlewares.referer.RefererMiddleware', 33 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 34 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 35 2020-03-19 11:25:42 [scrapy.middleware] INFO: Enabled item pipelines: 36 [] 37 2020-03-19 11:25:42 [scrapy.core.engine] INFO: Spider opened 38 2020-03-19 11:25:42 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 39 2020-03-19 11:25:42 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 40 2020-03-19 11:25:42 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/robots.txt> from <GET http://python123.io/robots.txt> 41 2020-03-19 11:25:42 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://python123.io/robots.txt> (referer: None) 42 2020-03-19 11:25:42 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/ws/demo.html> from <GET http://python123.io/ws/demo.html> 43 2020-03-19 11:25:42 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://python123.io/ws/demo.html> (referer: None) 44 2020-03-19 11:25:42 [demo] DEBUG: Saved file demo.html. 45 2020-03-19 11:25:42 [scrapy.core.engine] INFO: Closing spider (finished) 46 2020-03-19 11:25:42 [scrapy.statscollectors] INFO: Dumping Scrapy stats: 47 {'downloader/request_bytes': 892, 48 'downloader/request_count': 4, 49 'downloader/request_method_count/GET': 4, 50 'downloader/response_bytes': 1901, 51 'downloader/response_count': 4, 52 'downloader/response_status_count/200': 1, 53 'downloader/response_status_count/301': 2, 54 'downloader/response_status_count/404': 1, 55 'elapsed_time_seconds': 0.644698, 56 'finish_reason': 'finished', 57 'finish_time': datetime.datetime(2020, 3, 19, 3, 25, 42, 983695), 58 'log_count/DEBUG': 5, 59 'log_count/INFO': 10, 60 'response_received_count': 2, 61 'robotstxt/request_count': 1, 62 'robotstxt/response_count': 1, 63 'robotstxt/response_status_count/404': 1, 64 'scheduler/dequeued': 2, 65 'scheduler/dequeued/memory': 2, 66 'scheduler/enqueued': 2, 67 'scheduler/enqueued/memory': 2, 68 'start_time': datetime.datetime(2020, 3, 19, 3, 25, 42, 338997)} 69 2020-03-19 11:25:42 [scrapy.core.engine] INFO: Spider closed (finished)
Captured pages are stored in demo.html
5. Code understanding
1. demo.py full version code
1 import scrapy 2 3 class DemoSpider(scrapy.Spider): 4 name = 'demo' 5 6 def start_requests(self): 7 urls = [ 8 'http://python123.io/ws/demo.html' 9 ] 10 for url in urls: 11 yield scrapy.Request(url = url,callback = self.parse) 12 13 def parse(self, response): 14 fname = response.url.split('/')[-1] 15 with open(fname,'wb') as f: 16 f.write(response.body) 17 self.log('Saved file %s.'% fname)
The start_requests(self) function is a generator that can provide better resource utilization when there are too many URLs
2. yield keyword
Yield<--->generator
Generator is a function that constantly produces values
A function containing a yield statement is a generator
The generator produces one value at a time (yield statement), the function is frozen, and a value is generated after waking up
Generator Writing
1 def gen(n): #Definition gen()function 2 for i in range(n): 3 yield i**2 4 5 for i in gen(5): 6 print(i," ",end = "") 7 0 1 4 9 16
Generator saves storage space, responds faster, and is more flexible to use than listing everything at once
longhand
1 def square(n): #Definition square()function 2 ls = [i**2 for i in range(n)] 3 return ls 4 5 for i in range(5): 6 print(i," ",end = "") 7 0 1 2 3 4
Normal Writing puts all results in a list, which takes up a lot of space and time, and is not good for the program to run.
6. Summary of Scrapy Crawler Framework
1. Steps for using Scrapy Crawlers
(1) Create a project and a Spider template
(2) Writing Spider
(3) Writing Item Pipeline
(4) Configuration Policy
2. Data types of Scrapy Crawlers
(1) Request class
class scrapy.http.Request()
The Request object represents an HTTP request
Generated by Spider and executed by Downloader
| Property or method | Explain |
| .url | Request URL address |
| .method | Corresponding request method,'GET''POST', etc. |
| .headers | Dictionary Type Style Request Header |
| .body | Request Content Body, String Type |
| .meta | User-added extended information used to transfer information between crapy internal modules |
| .copy() | Copy the request |
(2) Response class
class scrapy.http.Response()
Response object represents an HTTP response
Generated by Downloader and processed by Spider
| Property or method | Explain |
| .url | URL Address for Response |
| .status | HTTP status code, default is 200 |
| .headers | Header information for Response |
| .body | Content information corresponding to Response, string type |
| .flags | A set of tags |
| .request | Generate Request object corresponding to Response type |
| .copy() | Copy the response |
(3) Item class
class scrapy.item.Item()
Item objects represent information content extracted from an HTML page
Generated by Spider and processed by Item Pipeline
Item type dictionary type, can operate according to dictionary type
3. Methods of extracting information by Scrapy Crawlers
Scrapy crawler supports multiple HTML information extraction methods
Beautiful Soup
lxml
re
XPath Selector
CSS Selector
Basic use of CSS Selector
1 <HTML>.css('a::attr(href)').extract()
CSS Selector is maintained and standardized by the W3C organization
Source: Beijing University of Technology, Songtian, MOOC