Although scrapy can do a lot of things, it is hard to achieve large-scale distributed applications. A capable person changes the queue scheduling of scrapy, separates the starting address from the start_urls and reads from redis, so that multiple clients can read the same redis at the same time, thus realizing distributed crawler. Even on the same computer, crawlers can run in multiple processes, which is very effective in the process of large-scale crawling.
Get ready:
1. windows (from scrapy)
2. linux (main: scrapy redis mongo)
ip:192.168.184.129
3,python3.6
Configuration steps of scrapy under linux:
1. Install Python 3.6 Yum install openssl-devel-y solves the problem that pip3 cannot be used (pip is configured with locations that require TLS/SSL, but the SSL module in Python is not available) Download the python package, Python-3.6.1.tar.xz, after decompression ./configure --prefix=/python3 make make install Add environmental variables: PATH=/python3/bin:$PATH:$HOME/bin export PATH pip3 is also installed by default (yum GCC is required before installation) 2. Installing Twisted Download Twisted-17.9.0.tar.bz2, decompressed CD Twisted-17.9.0, Python 3 setup.py install 3. Installation of scrapy pip3 install scrapy pip3 install scrapy-redis 4. Installing redis See Blog redis Installation and Simple Use Error: You need tcl 8.5 or newer in order to run the Redis test 1,wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz 2,tar -xvf tcl8.6.1-src.tar.gz 3,cd tcl8.6.1/unix ; make; make install cp /root/redis-3.2.11/redis.conf /etc/ Start: / root/redis-3.2.11/src/redis-server/etc/redis.conf& 5,pip3 install redis 6. Installation of mongodb Start: mongod -- bind_ip 192.168.184.129& 7,pip3 install pymongo
The deployment steps of scrapy on windows:
'''
Nobody answered the question? Editor created a Python learning and communication QQ group: 857662006
Look for like-minded friends, help each other, there are good video learning tutorials and PDF e-books in the group!
'''
1. Install wheel
pip install wheel
2. Installing lxml
https://pypi.python.org/pypi/lxml/4.1.0
3. Install pyopenssl
https://pypi.python.org/pypi/pyOpenSSL/17.5.0
4. Install Twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/
5. Install pywin32
https://sourceforge.net/projects/pywin32/files/
6. Installing scrapy
pip install scrapy
Deployment code:
I take the movie crawling of American TV Paradise as a simple example, and talk about the distributed implementation. The code linux and windows have one copy each. The configuration is the same. Both can run crawling at the same time.
List only the areas that need to be modified:
settings
Set up the mongodb, redis for fingerprint and queue
'''
//Nobody answered the question? Editor created a Python learning and communication QQ group: 857662006
//Look for like-minded friends, help each other, there are good video learning tutorials and PDF e-books in the group!
'''
ROBOTSTXT_OBEY = False # Prohibit robot s
CONCURRENT_REQUESTS = 1 # Maximum concurrency for scrapy debugging queue, default 16
ITEM_PIPELINES = {
'meiju.pipelines.MongoPipeline': 300,
}
MONGO_URI = '192.168.184.129' # mongodb connection information
MONGO_DATABASE = 'mj'
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # Scheduling using scrapy_redis
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # Removing duplication in redis libraries (url)
# REDIS_URL = 'redis://root:kongzhagen@localhost:6379'# If redis has a password, use this configuration
REDIS_HOST = '192.168.184.129' #redisdb connection information
REDIS_PORT = 6379
SCHEDULER_PERSIST = True # Unclear fingerprints
piplines
Code stored in MongoDB
'''
//Nobody answered the question? Editor created a Python learning and communication QQ group: 857662006
//Look for like-minded friends, help each other, there are good video learning tutorials and PDF e-books in the group!
'''
import pymongo
class MeijuPipeline(object):
def process_item(self, item, spider):
return item
class MongoPipeline(object):
collection_name = 'movies'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(dict(item))
return item
items
data structure
import scrapy
class MeijuItem(scrapy.Item):
movieName = scrapy.Field()
status = scrapy.Field()
english = scrapy.Field()
alias = scrapy.Field()
tv = scrapy.Field()
year = scrapy.Field()
type = scrapy.Field()
'''
//Nobody answered the question? Editor created a Python learning and communication QQ group: 857662006
//Look for like-minded friends, help each other, there are good video learning tutorials and PDF e-books in the group!
'''
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
class MjSpider(scrapy.Spider):
name = 'mj'
allowed_domains = ['meijutt.com']
# start_urls = ['http://www.meijutt.com/file/list1.html']
def start_requests(self):
yield Request(url='http://www.meijutt.com/file/list1.html', callback=self.parse)
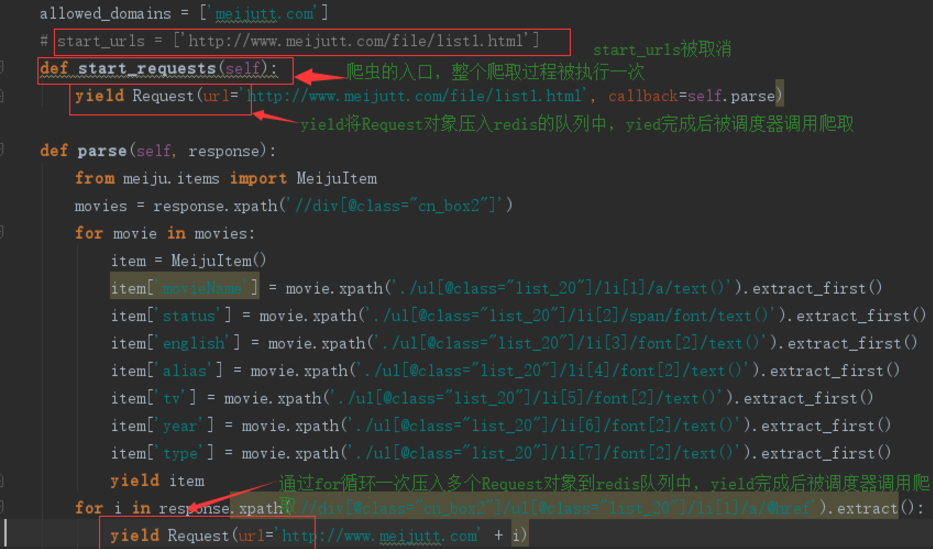
def parse(self, response):
from meiju.items import MeijuItem
movies = response.xpath('//div[@class="cn_box2"]')
for movie in movies:
item = MeijuItem()
item['movieName'] = movie.xpath('./ul[@class="list_20"]/li[1]/a/text()').extract_first()
item['status'] = movie.xpath('./ul[@class="list_20"]/li[2]/span/font/text()').extract_first()
item['english'] = movie.xpath('./ul[@class="list_20"]/li[3]/font[2]/text()').extract_first()
item['alias'] = movie.xpath('./ul[@class="list_20"]/li[4]/font[2]/text()').extract_first()
item['tv'] = movie.xpath('./ul[@class="list_20"]/li[5]/font[2]/text()').extract_first()
item['year'] = movie.xpath('./ul[@class="list_20"]/li[6]/font[2]/text()').extract_first()
item['type'] = movie.xpath('./ul[@class="list_20"]/li[7]/font[2]/text()').extract_first()
yield item
for i in response.xpath('//div[@class="cn_box2"]/ul[@class="list_20"]/li[1]/a/@href').extract():
yield Request(url='http://www.meijutt.com' + i)
# Next = http://www.meijutt.com'+ response.xpath ("//a [contains (,'next page')/@href")[1].extract()
# print(next)
# yield Request(url=next, callback=self.parse)
Take a look at redis:

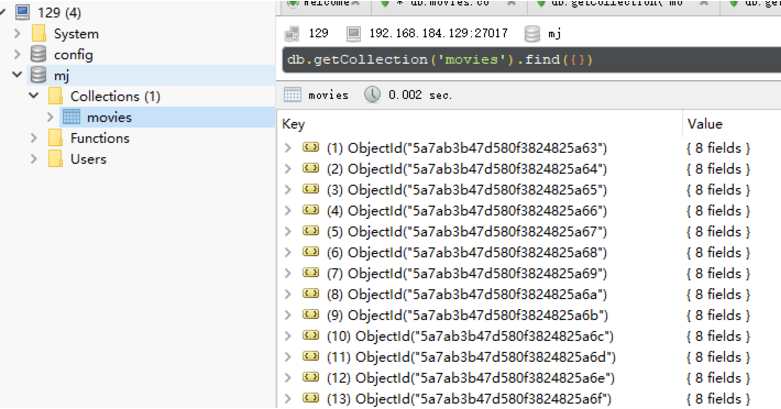
Look at the data in mongodb: