describe
Crawling http://fundact.eastmoney.com/banner/pg.html#ln Data from the website,
Requirements: crawl the fund code, fund name, unit net worth, date, daily growth rate, recent week, recent January, recent March, recent June, recent year, recent two years, recent three years, this year, since its establishment and handling fee of all funds (27 pages). Put the crawled data into the mariaDB database.
Environment description
python 3.6.3
scrapy 1.4.0
Step record
Create a scene project
Enter the place where you intend to put the code (F: \ mypychar_ws), create the project funds, and execute the command:
scrapy startproject funds
After the project is created, you will find that some files are generated. Here is a description of the relevant files
- Scrapy. The configuration information of CFG project mainly provides a basic configuration information for the scripy command line tool. (the configuration information related to the real crawler is in the settings.py file)
- items.py set the data storage template for structured data, such as Django's Model
- Pipeline data processing behavior, such as general structured data persistence
- settings.py configuration files, such as the number of recursive layers, concurrency, delayed download, etc
- spiders crawler directory, such as creating files and writing crawler rules
Next, you can use pycharm to open the project for development
Set up the script project to run under pycharm
step 1: create a py file in the funds project (anywhere in the project)
from scrapy import cmdline
cmdline.execute("scrapy crawl fundsList".split())
step 2: configure run -- > Edit configurations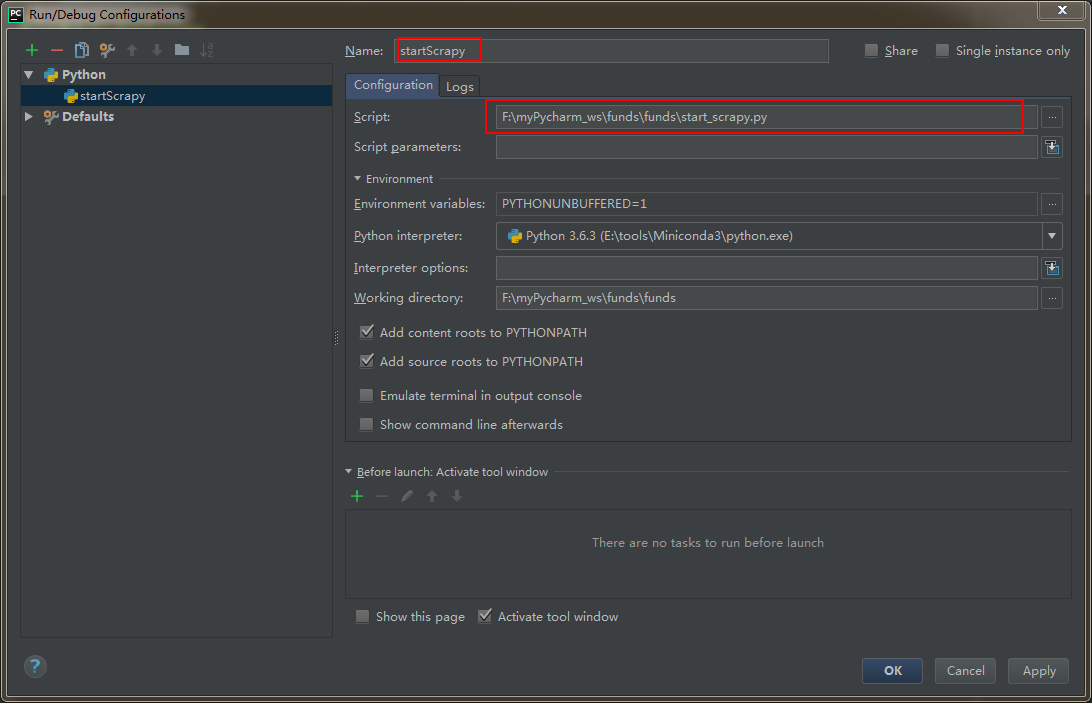
Operation mode: directly run the py file.
Analyze how to obtain data
Since all structured data of the list can be obtained through ajax request, I decided to obtain the url of the requested data through Google browser analysis: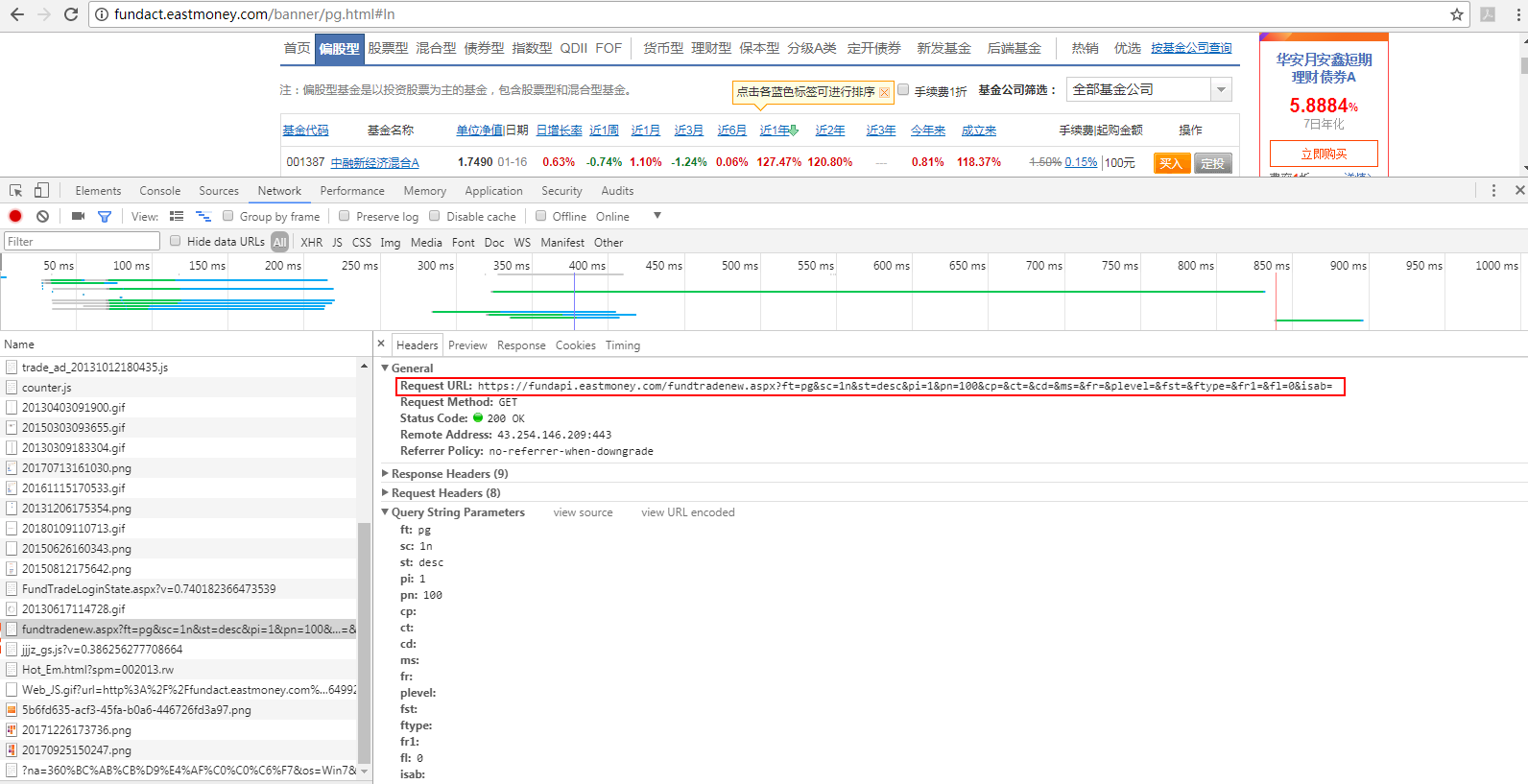
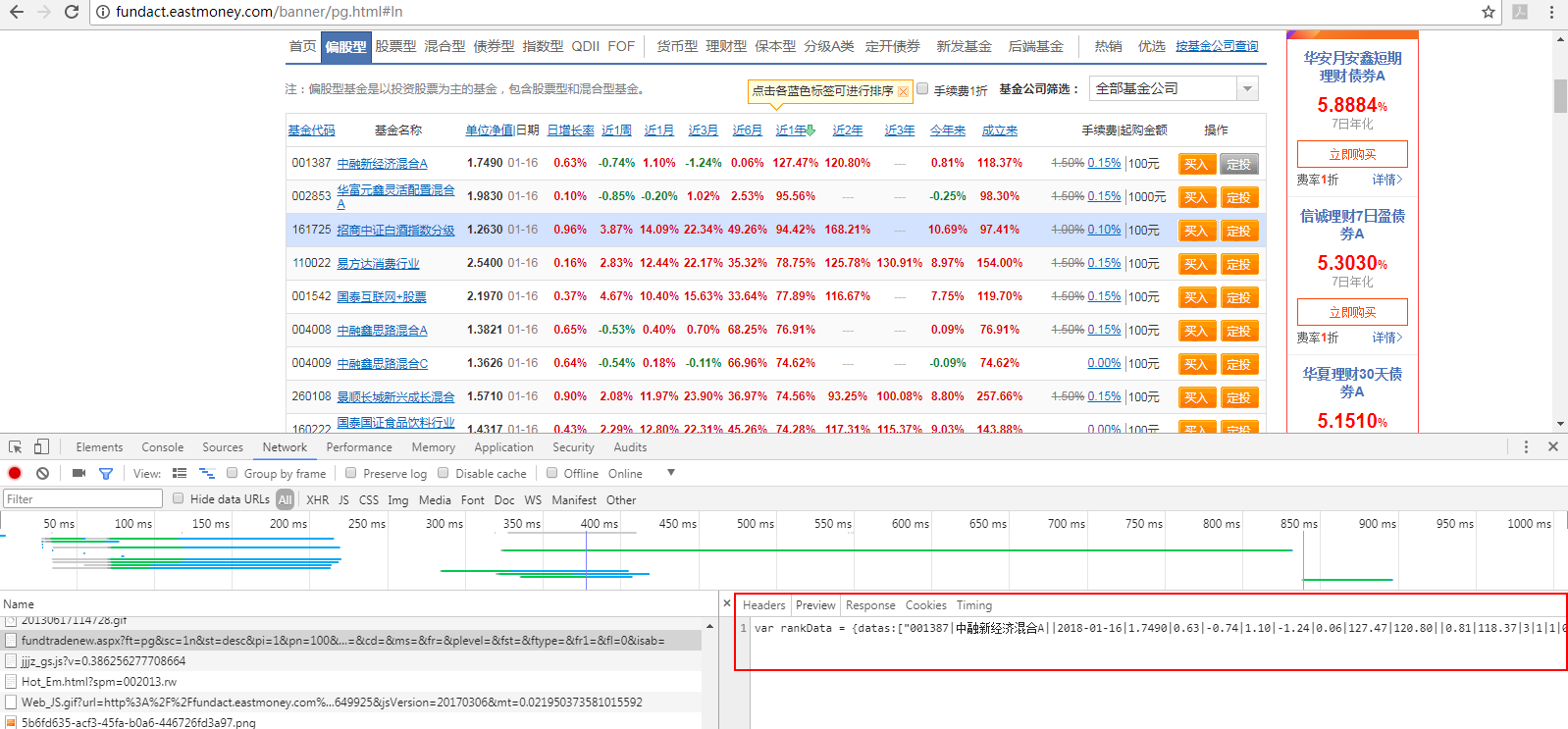
Looking at the data returned by the interface, we find that it is not a json directly, but looks like this: we just need to take out the data item
OK, then I can directly request the data of this interface.
Write code
step 1: set item
class FundsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field() # Fund code
name = scrapy.Field() # Fund name
unitNetWorth = scrapy.Field() # Average NAV
day = scrapy.Field() # date
dayOfGrowth = scrapy.Field() # Daily growth rate
recent1Week = scrapy.Field() # Last week
recent1Month = scrapy.Field() # Last month
recent3Month = scrapy.Field() # Last March
recent6Month = scrapy.Field() # Last June
recent1Year = scrapy.Field() # Last year
recent2Year = scrapy.Field() # Last two years
recent3Year = scrapy.Field() # Last three years
fromThisYear = scrapy.Field() # since this year on
fromBuild = scrapy.Field() # Since its establishment
serviceCharge = scrapy.Field() # Service Charge
upEnoughAmount = scrapy.Field() # Minimum amount
pass
step 2: write spider
import scrapy
import json
from scrapy.http import Request
from funds.items import FundsItem
class FundsSpider(scrapy.Spider):
name = 'fundsList' # Unique, used to distinguish Spider. This name is used when running the crawler
allowed_domains = ['fund.eastmoney.com'] # Allowed domains
# Initial url. Crawling from start_ After URLs starts automatically, the response returned by the server will be automatically passed to the parse(self, response) method.
# Note: this url can directly obtain the relevant data of all funds
# start_url = ['http://fundact.eastmoney.com/banner/pg.html#ln']
# custome_setting can be used to customize the settings of each spider, while setting All in py are global attributes. When there are multiple spiders in your sweep project, this is custom_setting is very useful
# custome_setting = {
#
# }
# The initial Request in the spider is by calling start_requests(). start_requests() read start_urls in URLs and generate a Request with parse as the callback function.
# Override start_requests will not start_urls generate Requests
def start_requests(self):
url = 'https://fundapi.eastmoney.com/fundtradenew.aspx?ft=pg&sc=1n&st=desc&pi=1&pn=3000&cp=&ct=&cd=&ms=&fr=&plevel=&fst=&ftype=&fr1=&fl=0&isab='
requests = []
request = scrapy.Request(url,callback=self.parse_funds_list)
requests.append(request)
return requests
def parse_funds_list(self,response):
datas = response.body.decode('UTF-8')
# Remove json Department
datas = datas[datas.find('{'):datas.find('}')+1] # Start with the first {and get}
# Add double quotation marks to each field name of json
datas = datas.replace('datas', '\"datas\"')
datas = datas.replace('allRecords', '\"allRecords\"')
datas = datas.replace('pageIndex', '\"pageIndex\"')
datas = datas.replace('pageNum', '\"pageNum\"')
datas = datas.replace('allPages', '\"allPages\"')
jsonBody = json.loads(datas)
jsonDatas = jsonBody['datas']
fundsItems = []
for data in jsonDatas:
fundsItem = FundsItem()
fundsArray = data.split('|')
fundsItem['code'] = fundsArray[0]
fundsItem['name'] = fundsArray[1]
fundsItem['day'] = fundsArray[3]
fundsItem['unitNetWorth'] = fundsArray[4]
fundsItem['dayOfGrowth'] = fundsArray[5]
fundsItem['recent1Week'] = fundsArray[6]
fundsItem['recent1Month'] = fundsArray[7]
fundsItem['recent3Month'] = fundsArray[8]
fundsItem['recent6Month'] = fundsArray[9]
fundsItem['recent1Year'] = fundsArray[10]
fundsItem['recent2Year'] = fundsArray[11]
fundsItem['recent3Year'] = fundsArray[12]
fundsItem['fromThisYear'] = fundsArray[13]
fundsItem['fromBuild'] = fundsArray[14]
fundsItem['serviceCharge'] = fundsArray[18]
fundsItem['upEnoughAmount'] = fundsArray[24]
fundsItems.append(fundsItem)
return fundsItems
step 3: configure settings py
custome_setting can be used to customize the settings of each spider, while setting All in py are global attributes. When there are multiple spiders in your sweep project, this is custom_setting is very useful.
However, there is only one crawler in my current project, so I use setting for the time being Py set the spider.
Default is set_ REQUEST_ Headers (since this crawler is a request interface, this item can also be configured without configuration)
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Cookie':'st_pvi=72856792768813; UM_distinctid=1604442b00777b-07f0a512f81594-5e183017-100200-1604442b008b52; qgqp_b_id=f10107e9d27d5fe2099a361a52fcb296; st_si=08923516920112; ASP.NET_SessionId=s3mypeza3w34uq2zsnxl5azj',
'Host':'fundapi.eastmoney.com',
'Referer':'http://fundact.eastmoney.com/banner/pg.html',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}
Set ITEM_PIPELINES
ITEM_PIPELINES = {
'funds.pipelines.FundsPipeline': 300,
}
pipelines.py, write the data into my local database
import pymysql.cursors
class FundsPipeline(object):
def process_item(self, item, spider):
# Connect database
connection = pymysql.connect(host='localhost',
user='root',
password='123',
db='test',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
sql = "INSERT INTO funds(code,name,unitNetWorth,day,dayOfGrowth,recent1Week,recent1Month,recent3Month,recent6Month,recent1Year,recent2Year,recent3Year,fromThisYear,fromBuild,serviceCharge,upEnoughAmount)\
VALUES('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % (
item['code'], item['name'], item['unitNetWorth'], item['day'], item['dayOfGrowth'], item['recent1Week'], \
item['recent1Month'], item['recent3Month'], item['recent6Month'], item['recent1Year'], item['recent2Year'],
item['recent3Year'], item['fromThisYear'], item['fromBuild'], item['serviceCharge'], item['upEnoughAmount'])
with connection.cursor() as cursor:
cursor.execute(sql) # Execute sql
connection.commit() # Submit to database for execution
connection.close()
return item
error handling
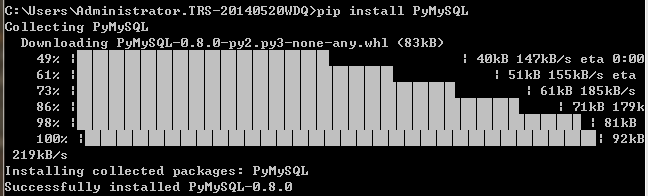
ModuleNotFoundError: No module named 'pymysql'
pip install PyMySQL
1366, "Incorrect string value: '\xE6\x99\xAF\xE9\xA1\xBA...' for column 'name' at row 1"
Chinese is garbled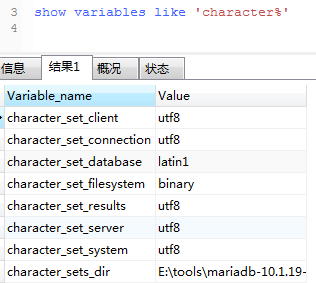
Check the database code, which is latin1.
terms of settlement:
alter table funds convert to character set utf8