This is a relatively comprehensive case. If you clarify the case, you will feel that the knowledge you have learned recently has become very regular and clear. The demand is to climb the news headlines corresponding to the five plates and the news content of each title.
(1) Analyze Netease page
For the home page, through positioning, it is found that each plate is nested in < UL > and exists as a separate < li >.
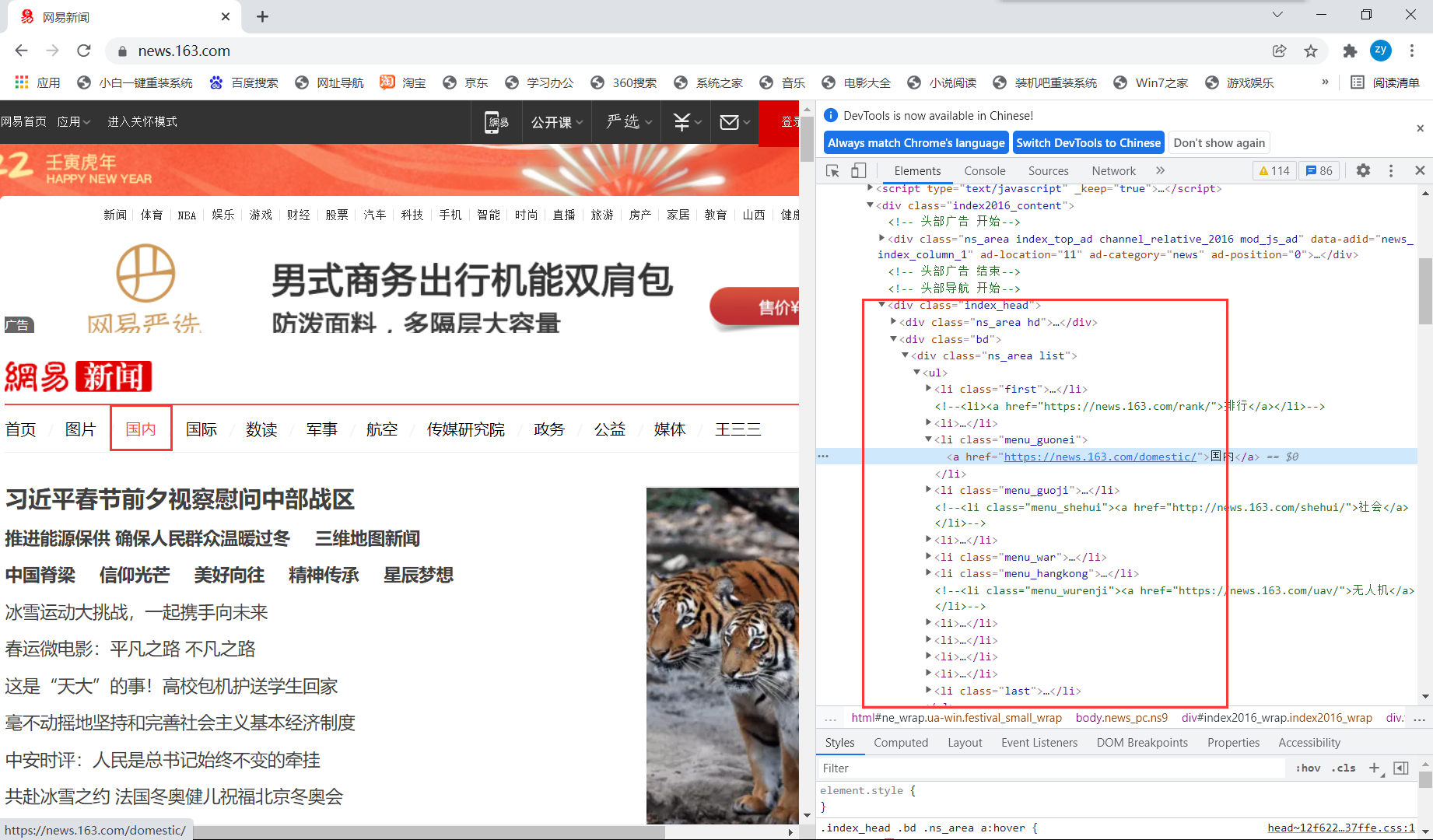
Click each section and find that the page is loaded as follows:
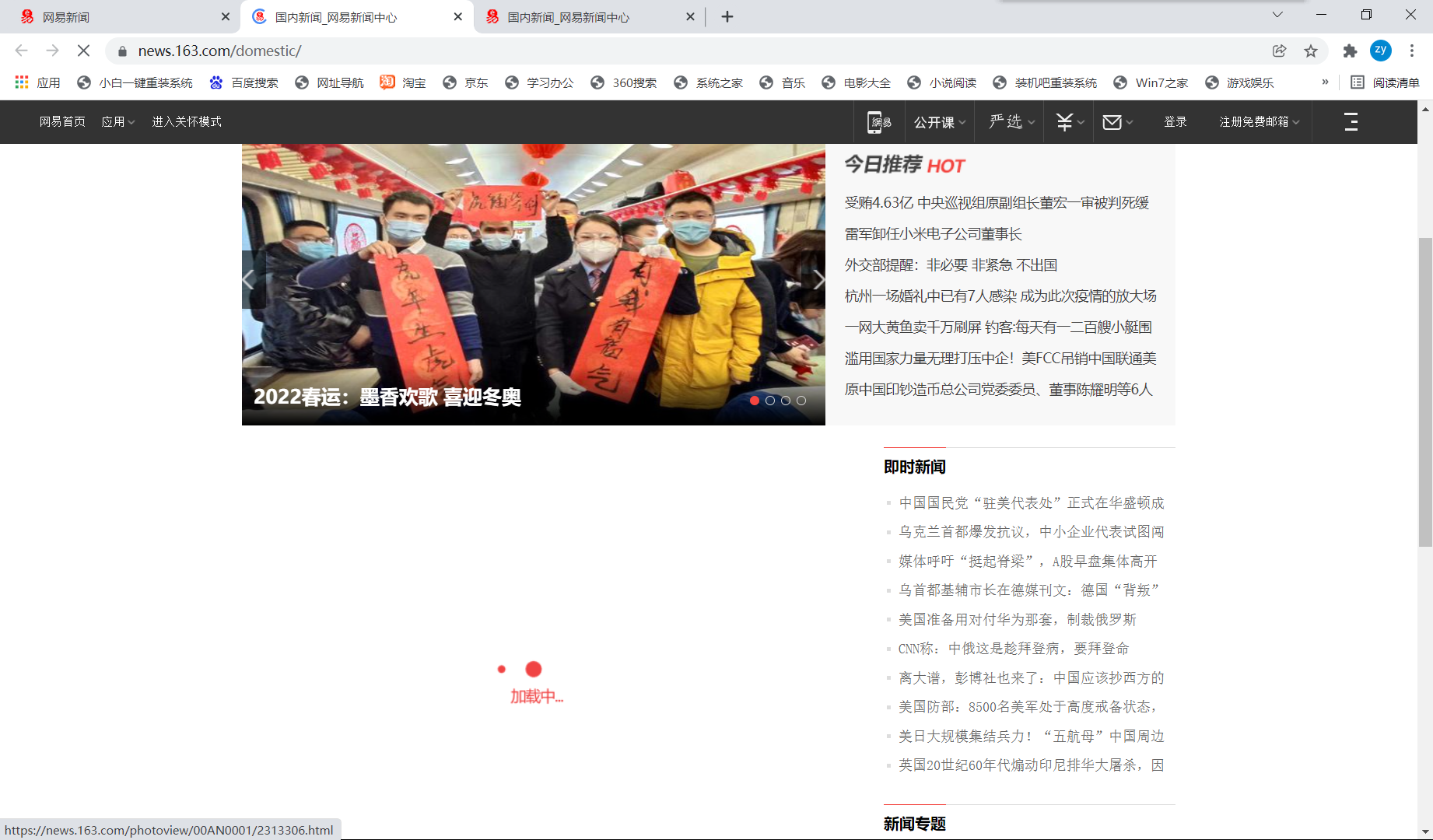
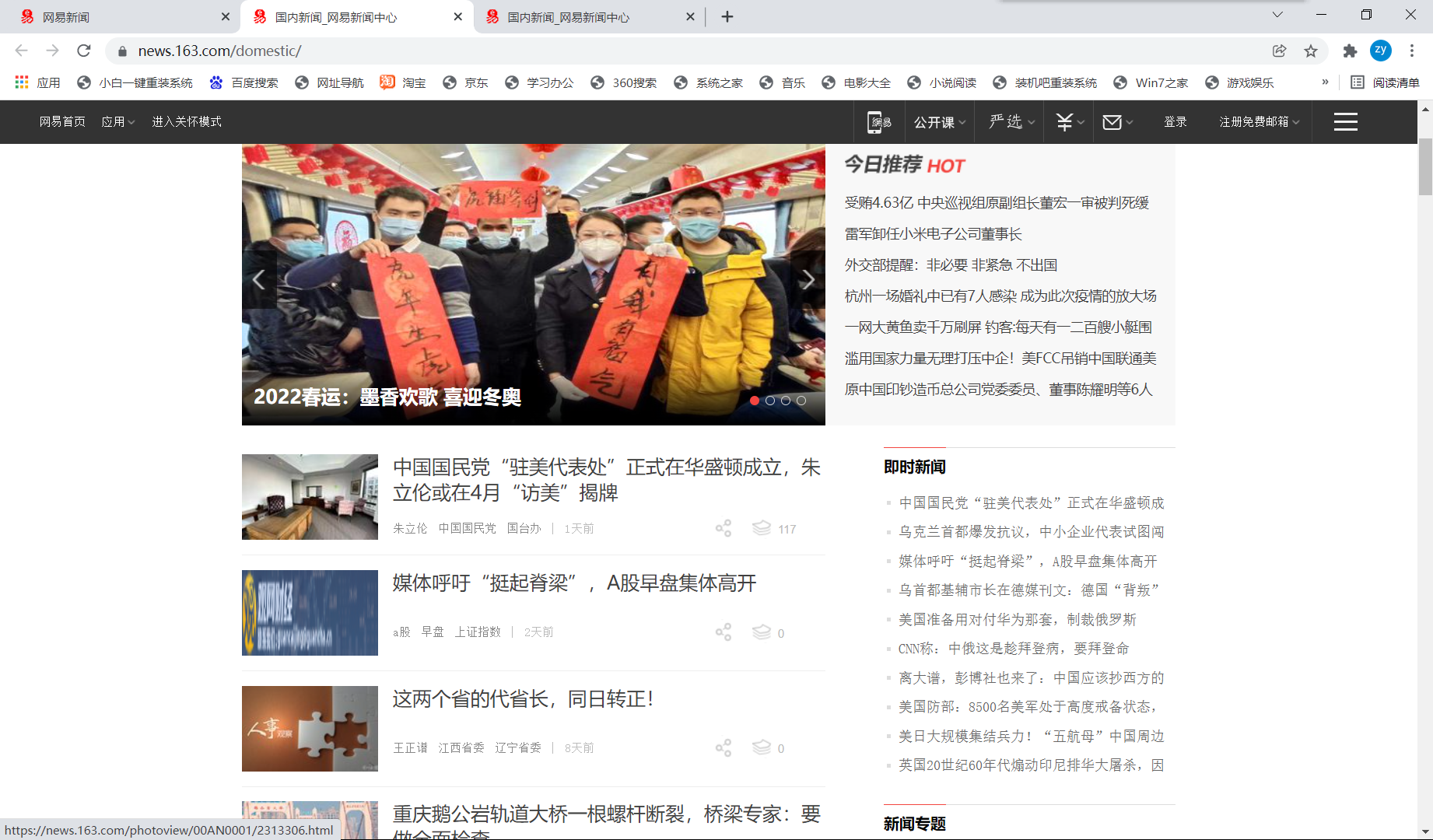
It shows that the news headlines of each section are dynamically loaded data (yes, it's expected that the real-time updated content of news is dynamically loaded). We can't parse the dynamically loaded data directly through the current url. What should we do?
Reviewing the five middleware, after the scheduler gives the engine url, the engine sends it to the downloader, and then the downloader goes to the Internet to obtain the response. At present, the response does not contain dynamic loading data, so we need to modify the returned response to include dynamic loading data.
The problem is, the most convenient way to obtain dynamic loading data is selenium, which you have learned before. You can obtain dynamic loading data through selenium, so where to tamper with it and where to use selenium------ Since you want to tamper with the returned response, it is natural to tamper with it at the place where you download the middleware.
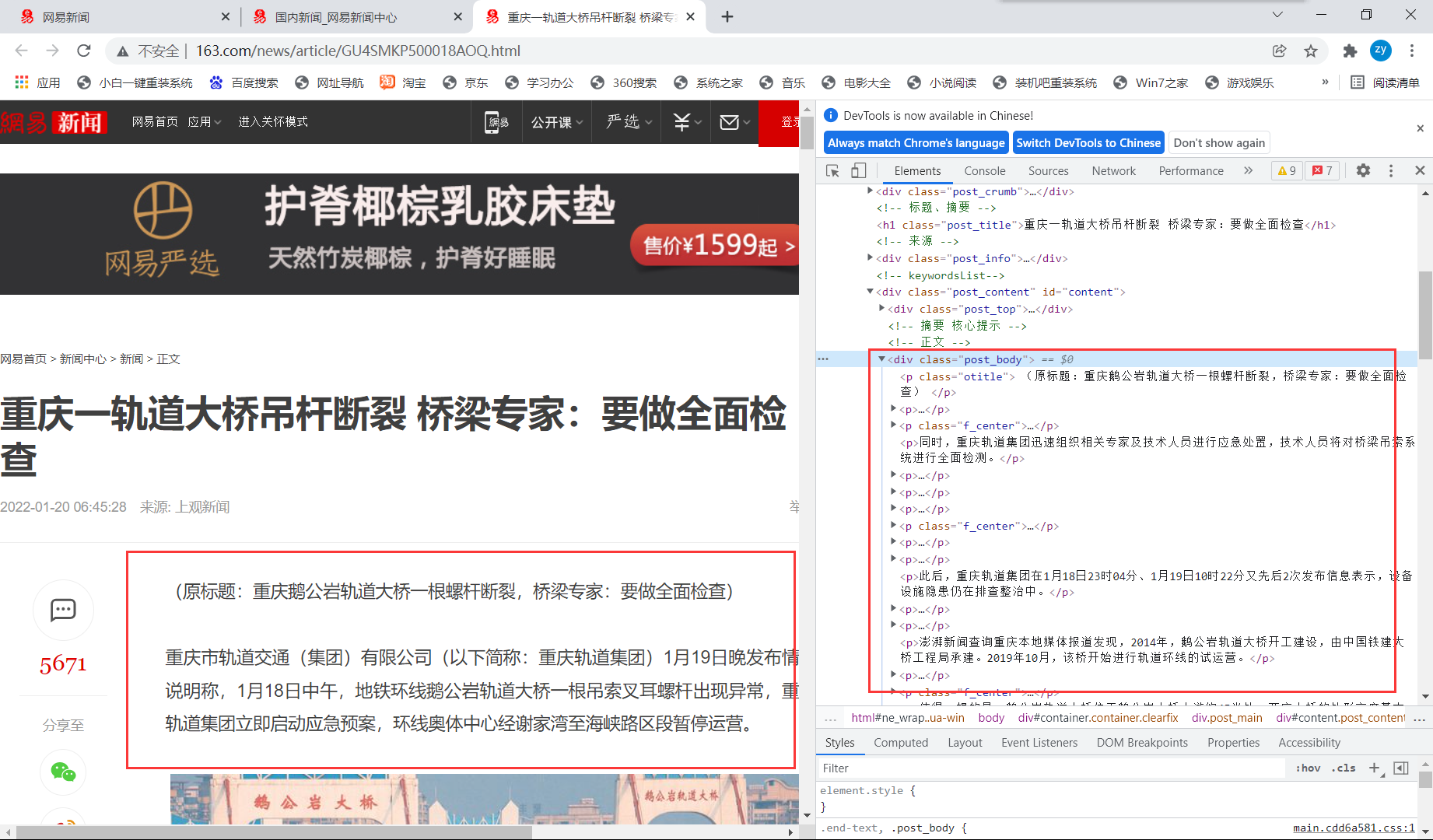
As for the news content corresponding to each news title, it's easy to say. You can see that it is written directly in the source code, which can be parsed directly and then obtained.
(2) Code writing
First, get the URLs of the five sections and store them in a list, and initiate requests for each url in the list in turn:
# Analyze the five sections of the home page url def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[3]/div[2]/div[2]/div[2]/div/ul/li') alist = [2,3,5,6] for index in alist: model_url = li_list[index].xpath('./a/@href').extract_first() self.model_urls.append(model_url) # For each plate in turn url Initiate request for url in self.model_urls: yield scrapy.Request(url,callback=self.parse_model)
Next, we will write the callback function parse() in parse()_ Model () involves response, so you have to write and download middleware to tamper with it.
First analyze a wave: the so-called tampering is nothing more than using new that contains dynamically loaded data_ If response replaces the original response, then new_ How to get the response?
A: Send a request to the URLs of the five sections again through selenium. At this time, the response contains the dynamic loading data, and then obtain it with a class HtmlResponse encapsulated in scratch.
First, you need to instantiate a browser object to simulate selenium:
from selenium import webdriver from selenium.webdriver.chrome.service import Service def __init__(self): self.s = Service(r'D:\Python\spider\selenium\chromedriver.exe') self.driver = webdriver.Chrome(service=self.s)
Then write it in middlewares, because process_ The response inherits from the spider, which means that the URLs involved in the spider need to be verified. The URLs of the five sections are re requesting selenium. Otherwise, the original response will be used directly.
[Note: there are two classes in middleware, corresponding to two middleware, one is crawler middleware and the other is download middleware. Don't write it wrong. We need to write it in class downloadermidware]
# Intercept the response objects corresponding to the five plates and tamper with them def process_response(self, request, response, spider): # Gets the browser object defined in the crawler class driver = spider.driver # Pick out the ones that need to be tampered with response Corresponding request Corresponding url if request.url in spider.model_urls: # Corresponding to the five plates response Tampering # On the five plates url Initiate request driver.get(request.url) sleep(2) # Gets the page containing dynamically loaded data page_text = driver.page_source # Instantiate a new response object (including dynamically loaded data) to replace the old response object new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request) return new_response else: # Other requests response return response
After the above operations, our response has achieved full function coverage. You can directly write the callback function in the script file:
# Analyze the news headlines corresponding to each section (news headlines are dynamically loaded and used to obtain dynamically loaded data) Selenium) # After writing and downloading the middleware process_response After, at this time response Already new_response def parse_model(self,response): div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div') for div in div_list: news_title = div.xpath('./div/div[1]/h3/a/text() | ./div/h3/a/text()').extract_first() news_detail_url = div.xpath('./div/div[1]/h3/a/@href | ./div/h3/a/@href').extract_first() item = WangyiproItem() item['news_title'] = news_title # On the news details page url Initiate request yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item})
Note that the request parameter is used. We need to define the content of item in Item:
class WangyiproItem(scrapy.Item): # define the fields for your item here like: news_title = scrapy.Field() news_content = scrapy.Field() # pass
In addition, pay attention to the use of request parameters:
def parse_detail(self,response): news_content = response.xpath('//*[@id="content"]/div[2]//text() | //*[@id="content"]/div[2]/div[1]//text()').extract() news_content = ''.join(news_content) item = response.meta['item'] item['news_content'] = news_content yield item
Pay attention to a small detail. After instantiating the browser driver at the beginning, remember to close it at the end to reduce unnecessary resource consumption:
# Close browser driver def closed(self,spider): self.driver.quit()
Finally, we store the obtained news content in a txt text, which is convenient to observe the operation results, and adopt the pipeline storage method:
class WangyiproPipeline: fp = None # Override the parent method and open the storage file def open_spider(self,spider): print('Start crawling......') self.fp = open('./NetEase News .txt','w',encoding='utf-8') # This method is specifically used to deal with item Type of object that receives crawler files submitted item object # Every time the method receives a item Will be called once def process_item(self, item, spider): news_title = item['news_title'] news_content = item['news_content'] self.fp.write(news_title + ':' + '\n' + news_content + ':' + '\n') return item # Close file def close_spider(self,spider): print('Crawl complete!!!') self.fp.close()
So far, the content of the code has been written. It needs to be set. It does not comply with the robots protocol, UA camouflage, set the type of output log, and open and download the configuration information of middleware and pipeline classes at the same time:
# Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False LOG_LEVEL = 'ERROR' # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543, } # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'wangyiPro.pipelines.WangyiproPipeline': 300, }
(3) Error reporting processing
After operation, there may be two problems. One is:

Second:
ERROR:device_event_log_impl.cc(211)] USB: usb_device_handle_win.cc:1020 Failed to read descriptor from node connection: The device attached to the system is not functioning. (0x1F) 3ERROR:device_event_log_impl.cc(211)] Bluetooth: bluetooth_adapter_winrt.cc:1204 Gettin g Radio failed. Chrome will be unable to change the power state by itself. ERROR:device_event_log_impl.cc(211)] Bluetooth: bluetooth_adapter_winrt.cc:1297 OnPowe redRadiosEnumerated(), Number of Powered Radios: 0"
The first problem is that there may be two situations: one is that the xpath path is located incorrectly during data analysis, and the other is that the index item is forgotten when obtaining list elements; As for question 2, it will actually work normally, but for obsessive-compulsive disorder, I still want to remove this prompt and add a few lines of code:
# Instantiate browser objects def __init__(self): options = webdriver.ChromeOptions() options.add_experimental_option('excludeSwitches', ['enable-logging']) self.s = Service(r'D:\Python\spider\selenium\chromedriver.exe') self.driver = webdriver.Chrome(service=self.s,options=options)
(4) Operation effect:
(the Chinese New Year is coming soon. I wish all bloggers a happy Spring Festival and success in their studies!!!)
