1.Solr installation and configuration
1.1 introduction to Solr
Most search engine applications must have some kind of search function. The problem is that the search function is often a huge resource consumption and they drag down the performance of your application due to heavy database loading.
That's why it's a good idea to transfer the load to an external search server. Apache Solr is a popular open source search server. It uses a REST like HTTP API, which ensures that you can use solr from almost any programming language.
Solr is an open source search platform for building search applications. It is based on Lucene (full-text search engine). Solr is enterprise class, fast and highly scalable. Applications built with Solr are complex and provide high performance.
To add search capabilities to CNET's corporate website, Yonik Seely created Solr in 2004. And in January 2006, it became an open source project under the Apache Software Foundation. The latest version of Solr 6.0 was released in 2016 to support the execution of parallel SQL queries.
Solr can be used with Hadoop. Because Hadoop processes a lot of data, Solr helps us find the information we need from such a large source. Not only for search, Solr can also be used for storage purposes. Like other NoSQL databases, it is a non relational data storage and processing technology.
All in all, Solr is an extensible, deployable, search / storage engine that optimizes search for large amounts of text centric data.
1.2 Solr installation
1: Download Tomcat and unzip the Tomcat package.
2: Unzip solr.
3: Deploy the dist directory solr-4.10.3.war under Solr to Tomcat\webapps (remove the version number).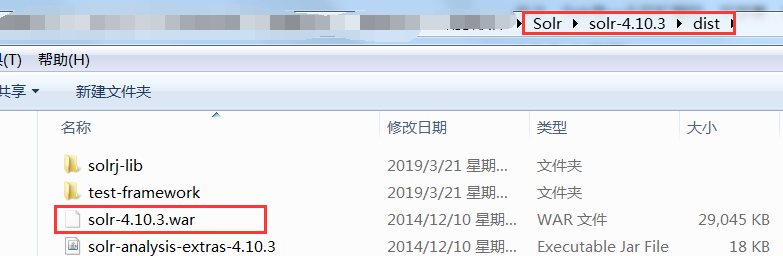
4: Start Tomcat to decompress the war package. To start tomcat, just go to the bin directory of Tomcat 'and double-click startup to start it
5: Add all jar packages under the example/lib/ext directory of solr to solr's project (under the \ WEB-INF\lib directory).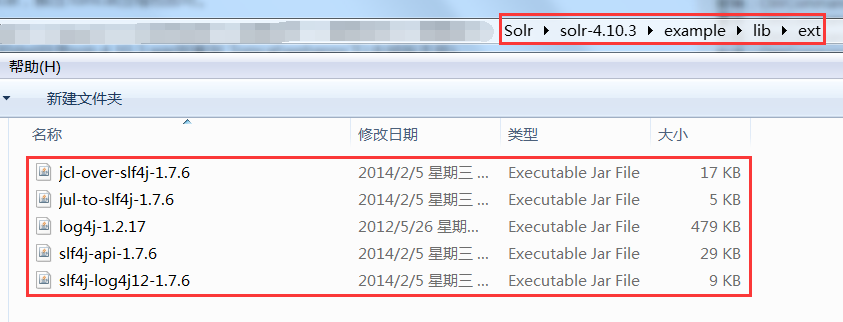
6: Create a solrhome. The / example/solr directory under solr is a solrhome. Copy this directory to disk D and rename it solrhome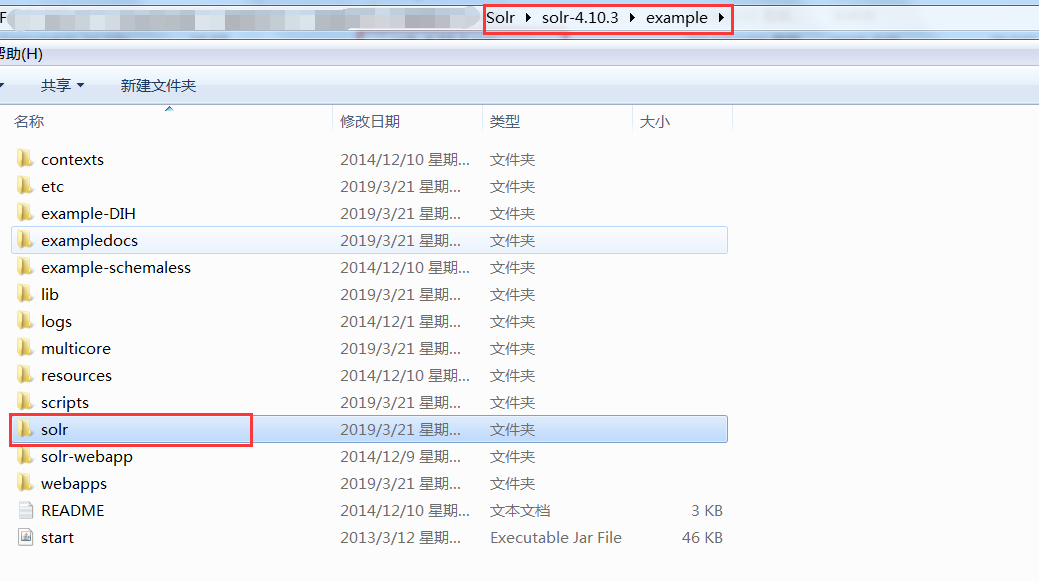
7: Correlates solr with solrhome. The web.xml file of solr project needs to be modified.
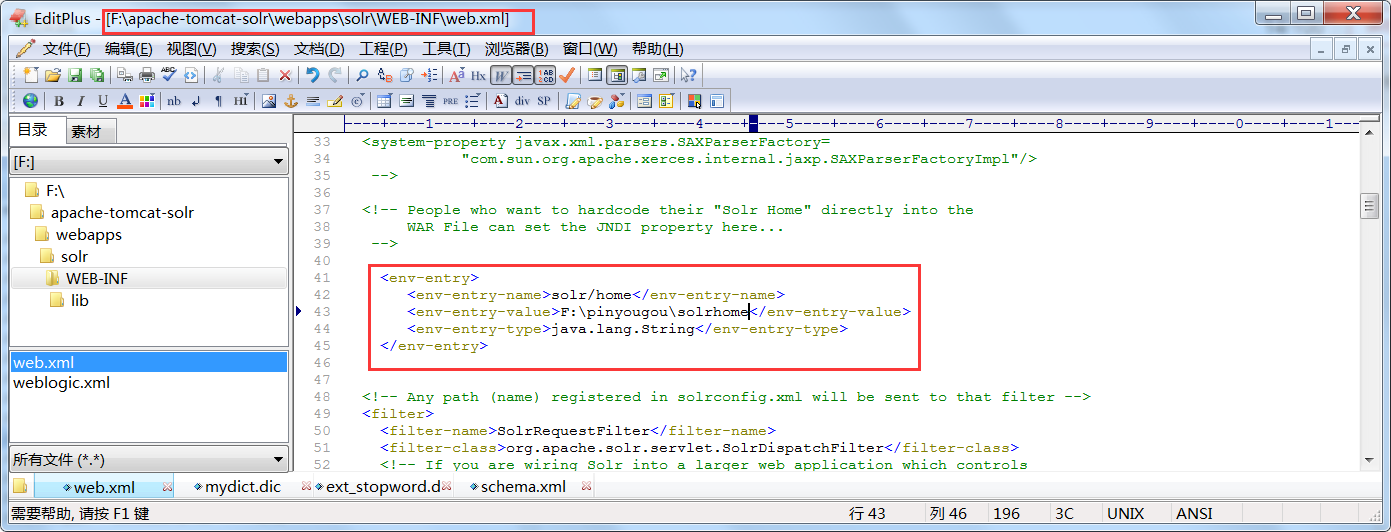
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>d:\solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
8: Start Tomcat
http://IP:8080/solr/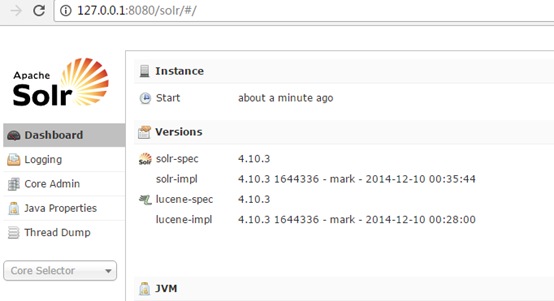
solr is installed successfully. Next, configure the word breaker.
1.3 Chinese analyzer IK Analyzer
1.3.1 introduction to IK analyzer
IK Analyzer is an open source, Java based lightweight Chinese word segmentation toolkit. Since the release of version 1.0 in December 2006, IKAnalyzer has launched four major versions. Initially, it is a Chinese word segmentation component based on the open source project Luence, which combines dictionary word segmentation and grammar analysis algorithm. Since version 3.0, IK has developed into a Java oriented common word segmentation component, independent of Lucene project, and provided the default optimization implementation of Lucene. In the 2012 version, IK implemented a simple word segmentation ambiguity elimination algorithm, marking the evolution of IK word segmentation from a simple dictionary to a simulated semantic word segmentation.
1.3.2 IK Analyzer configuration
Steps:
1. Add ikanalyzer2012ff_1.jar to the lib directory of solr project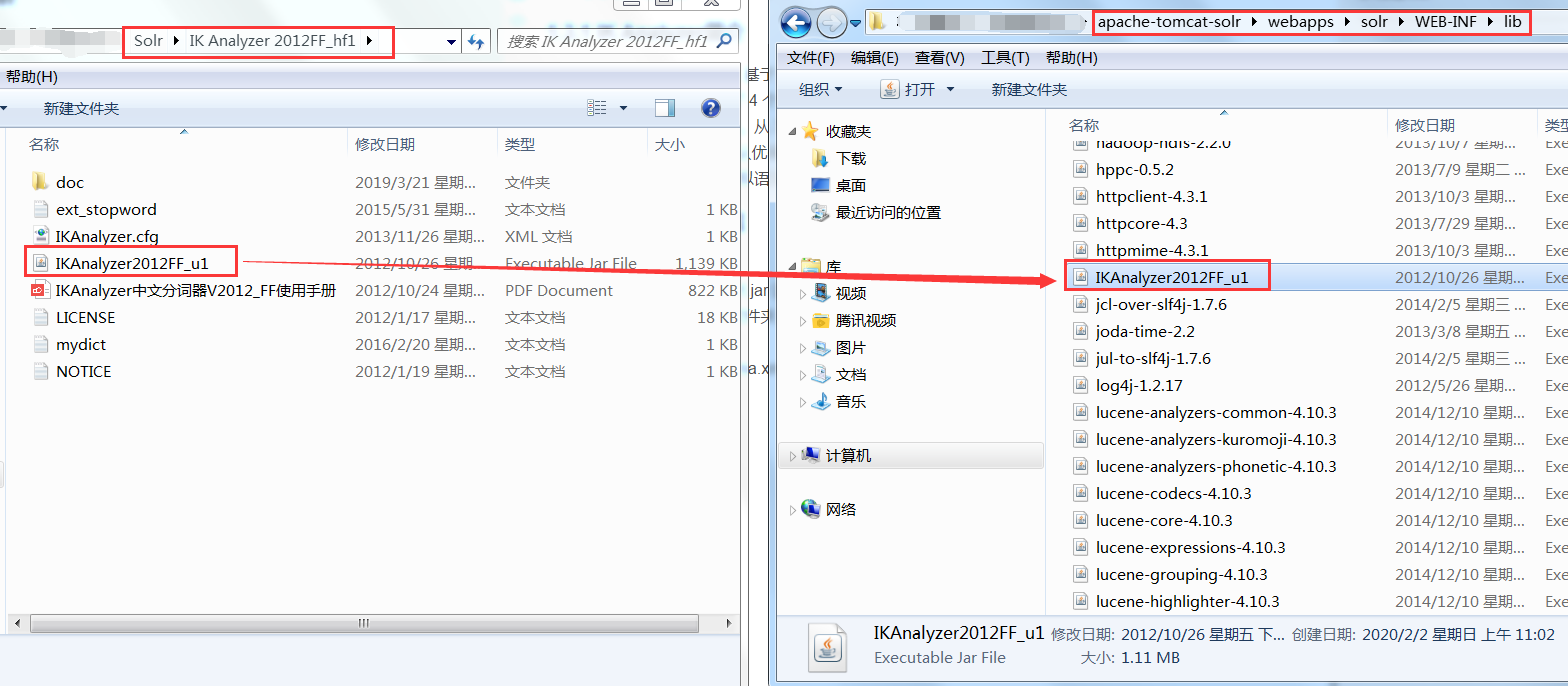
2. Create the WEB-INF/classes folder, and put the extended dictionary, the disabled word dictionary, and the configuration file into the WEB-INF/classes directory of solr project.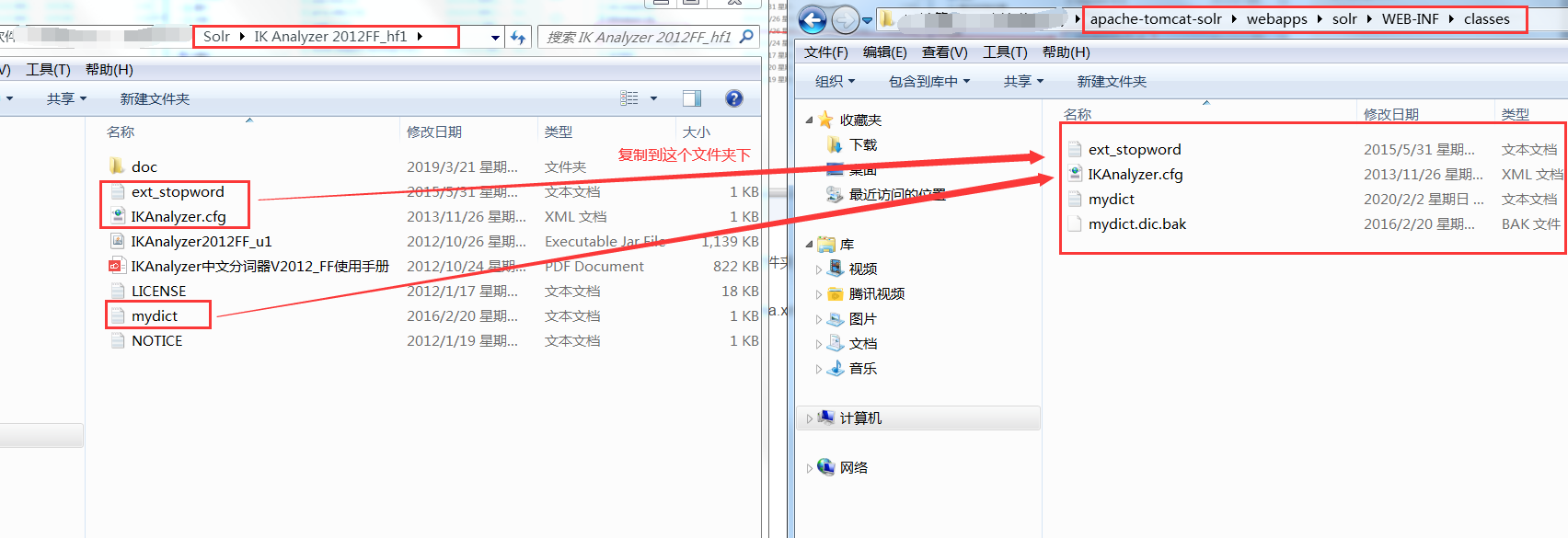
3. Modify the schema.xml file of Solrhome, configure a FieldType, and use IKAnalyzer
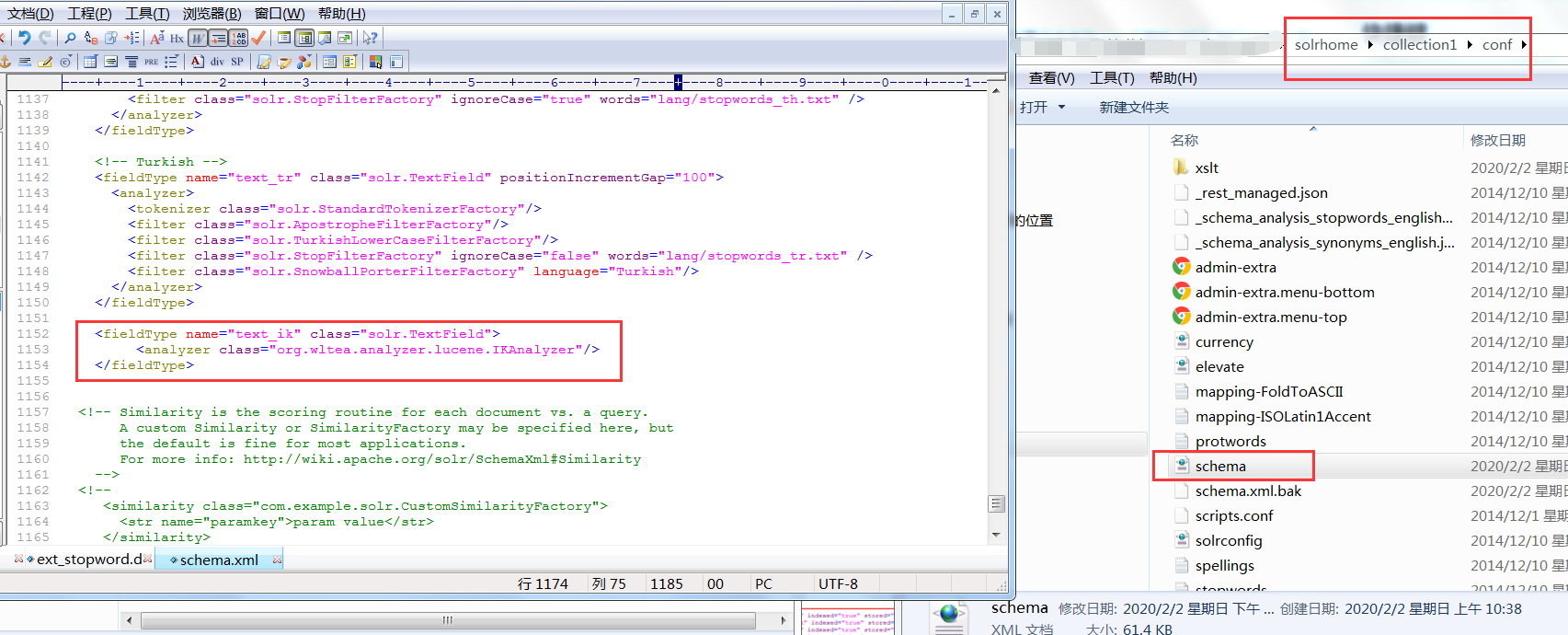
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
1.4 configuration domain
Domain is equivalent to the table Field of database, and users store data. Therefore, users define related fields according to business needs. Generally speaking, each type corresponds to a kind of data, and users perform the same operation on the same kind of data.
Common properties of domain:
• Name: Specifies the name of the domain
• type: Specifies the type of domain
• indexed: index or not
• stored: whether to store
• required: required or not
• multiValued: multi value or not
1.4.1 domain
Modify solrhome's schema.xml file to set the business system Field
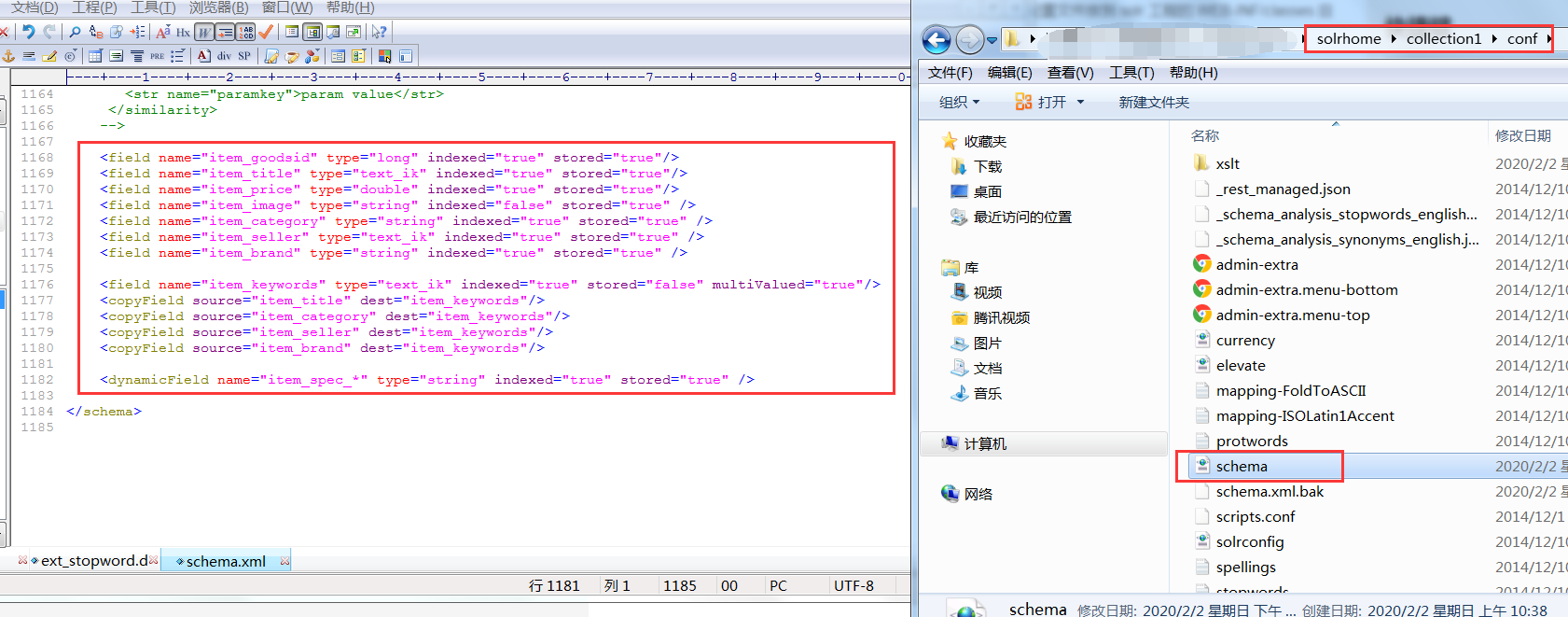
<field name="item_goodsid" type="long" indexed="true" stored="true"/> <field name="item_title" type="text_ik" indexed="true" stored="true"/> <field name="item_price" type="double" indexed="true" stored="true"/> <field name="item_image" type="string" indexed="false" stored="true" /> <field name="item_category" type="string" indexed="true" stored="true" /> <field name="item_seller" type="text_ik" indexed="true" stored="true" /> <field name="item_brand" type="string" indexed="true" stored="true" />
1.4.2 replication domain
The purpose of a replication domain is to copy data from one Field to another
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_keywords"/> <copyField source="item_category" dest="item_keywords"/> <copyField source="item_seller" dest="item_keywords"/> <copyField source="item_brand" dest="item_keywords"/>
1.4.3 dynamic domain
When we need to expand fields dynamically, we need to use dynamic fields. For product optimization, the specification value is uncertain, so we need to use dynamic domain to achieve. The effects to be achieved are as follows: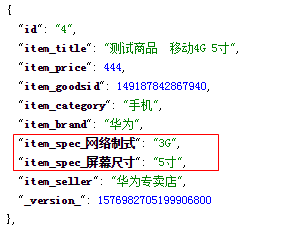
To configure:
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />
2.Spring Data Solr practice
2.1 introduction to spring data Solr
While the ability to support any programming language has great market value, the question you might be interested in is: how do I integrate Solr's applications into Spring? Yes, Spring Data Solr is a framework developed to facilitate the development of Solr. The bottom layer is the encapsulation of SolrJ (official API).
2.2 getting started with spring data Solr
2.2.1 construction works
(1) Create maven project and introduce dependency in pom.xml
<dependencies> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-solr</artifactId> <version>1.5.5.RELEASE</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>4.2.4.RELEASE</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.9</version> </dependency> </dependencies>
(2) Create applicationContext-solr.xml under src/main/resources
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:solr="http://www.springframework.org/schema/data/solr" xsi:schemaLocation="http://www.springframework.org/schema/data/solr http://www.springframework.org/schema/data/solr/spring-solr-1.0.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <!-- solr server address --> <solr:solr-server id="solrServer" url="http://127.0.0.1:8080/solr" /> <!-- solr Templates, using solr Templates can be used to CRUD Operation --> <bean id="solrTemplate" class="org.springframework.data.solr.core.SolrTemplate"> <constructor-arg ref="solrServer" /> </bean> </beans>
2.2.2 @Field annotation
Create cn.itcast.pojo package, copy the entity class of TbItem purchased by pinyougou into the project, and use @ Field annotation for attribute identification. If the property does not match the domain name defined in the configuration file, you need to specify the domain name in the annotation.
public class TbItem implements Serializable{
@Field
private Long id;
@Field("item_title")
private String title;
@Field("item_price")
private BigDecimal price;
@Field("item_image")
private String image;
@Field("item_goodsid")
private Long goodsId;
@Field("item_category")
private String category;
@Field("item_brand")
private String brand;
@Field("item_seller")
private String seller;
.......
}
2.2.3 add (modify)
Create test class TestTemplate.java
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations="classpath:applicationContext-solr.xml")
public class TestTemplate {
@Autowired
private SolrTemplate solrTemplate;
@Test
public void testAdd(){
TbItem item=new TbItem();
item.setId(1L);
item.setBrand("HUAWEI");
item.setCategory("Mobile phone");
item.setGoodsId(1L);
item.setSeller("Huawei No.2 store");
item.setTitle("HUAWEI Mate9");
item.setPrice(new BigDecimal(2000));
solrTemplate.saveBean(item);
solrTemplate.commit();
}
}
2.2.4 query by primary key
@Test
public void testFindOne(){
TbItem item = solrTemplate.getById(1, TbItem.class);
System.out.println(item.getTitle());
}
2.2.5 delete by primary key
@Test
public void testDelete(){
solrTemplate.deleteById("1");
solrTemplate.commit();
}
2.2.6 paging query
First loop 100 test data
@Test
public void testAddList(){
List<TbItem> list=new ArrayList();
for(int i=0;i<100;i++){
TbItem item=new TbItem();
item.setId(i+1L);
item.setBrand("HUAWEI");
item.setCategory("Mobile phone");
item.setGoodsId(1L);
item.setSeller("Huawei No.2 store");
item.setTitle("HUAWEI Mate"+i);
item.setPrice(new BigDecimal(2000+i));
list.add(item);
}
solrTemplate.saveBeans(list);
solrTemplate.commit();
}
Write paging query test code:
@Test
public void testPageQuery(){
Query query=new SimpleQuery("*:*");
query.setOffset(20);//Start index (default 0)
query.setRows(20);//Records per page (default 10)
ScoredPage<TbItem> page = solrTemplate.queryForPage(query, TbItem.class);
System.out.println("Total records:"+page.getTotalElements());
List<TbItem> list = page.getContent();
showList(list);
}
//Display record data
private void showList(List<TbItem> list){
for(TbItem item:list){
System.out.println(item.getTitle() +item.getPrice());
}
}
2.2.7 condition query
Criteria is used to encapsulate conditions:
@Test
public void testPageQueryMutil(){
Query query=new SimpleQuery("*:*");
Criteria criteria=new Criteria("item_title").contains("2");
criteria=criteria.and("item_title").contains("5");
query.addCriteria(criteria);
//query.setOffset(20); / / start index (default 0)
//query.setRows(20); / / records per page (default 10)
ScoredPage<TbItem> page = solrTemplate.queryForPage(query, TbItem.class);
System.out.println("Total records:"+page.getTotalElements());
List<TbItem> list = page.getContent();
showList(list);
}
2.2.8 delete all data
@Test
public void testDeleteAll(){
Query query=new SimpleQuery("*:*");
solrTemplate.delete(query);
solrTemplate.commit();
}
For more courses, please pay attention to: non class class class

