Recently, due to work reasons, I have been busy with various projects of the company (most of them are microservices based on Spring cloud), so I haven't shared and summarized the latest technical research results with you for a while. In fact, I have been studying and studying various framework principles of Spring, Spring Boot and Spring cloud, and I also pay close attention to. NET CORE at any time. The development and the latest technology points also subscribe to the relevant column on geek time. As long as I get off duty, I will read and watch carefully, and the paper bookcase also bought some. In short, nearly a year passed: WeChat technology public number (.NET, JAVA, algorithm, front-end technology direction), Geek time, technical bookcase constantly absorb and learn from the essence of others. To enrich and improve one's own technical level, the so-called: learning is like sailing against the current, never advancing or retreating, learning in the work, and using in the work after learning. Of course, writing and sharing is a kind of summary, and also the best application of "learning from the past and learning from the new".
After a little more nonsense, I will go straight to the topic of this article and write a general search engine query tool class based on Lucene.Net: SearchEngineUtil, what is Lucene, see Baidu Encyclopedia The key point is: Lucene is a full-text search engine architecture, providing a complete query engine and index engine. Lucene.NET is the implementation of another language under the running time of C #, and. NET. The official website address: http://lucenenet.apache.org/ Not to mention the specific usage. There are many on the official website and on the Internet. However, because the API in Lucene.Net's native SDK is complex and inconvenient to use, I have properly encapsulated the commonly used add, delete, modify and query (page search) under the condition of ensuring flexibility, which makes the operation of Lucene.Net relatively simple and the code itself no longer exists. Miscellaneous, paste the complete SearchEngineUtil code as follows:
using Lucene.Net.Analysis.PanGu;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.QueryParsers;
using Lucene.Net.Search;
using Lucene.Net.Store;
using NLog;
using PanGu;
using PanGu.HighLight;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Reflection;
using System.Text;
namespace CN.Zuowenjun.Blog.Common
{
/// <summary>
///Lucene search engine utility class
/// Author:zuowenjun
/// </summary>
public class SearchEngineUtil
{
/// <summary>
///Create and add index records
/// </summary>
/// <typeparam name="TIndex"></typeparam>
/// <param name="indexDir"></param>
/// <param name="indexData"></param>
/// <param name="setDocFiledsAction"></param>
public static void AddIndex<TIndex>(string indexDir, TIndex indexData, Action<Document, TIndex> setDocFiledsAction)
{
//Create index directory
if (!System.IO.Directory.Exists(indexDir))
{
System.IO.Directory.CreateDirectory(indexDir);
}
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
bool isUpdate = IndexReader.IndexExists(directory);
if (isUpdate)
{
//If the index directory is locked (for example, the program exits abnormally during indexing), unlock it first
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);
}
}
using (IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, IndexWriter.MaxFieldLength.UNLIMITED))
{
Document document = new Document();
setDocFiledsAction(document, indexData);
writer.AddDocument(document);
writer.Optimize();//Optimized index
}
}
/// <summary>
///Delete index record
/// </summary>
/// <param name="indexDir"></param>
/// <param name="keyFiledName"></param>
/// <param name="keyFileValue"></param>
public static void DeleteIndex(string indexDir, string keyFiledName, object keyFileValue)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
if (!IndexReader.IndexExists(directory))
{
return;
}
using (IndexWriter iw = new IndexWriter(directory, new PanGuAnalyzer(), IndexWriter.MaxFieldLength.UNLIMITED))
{
iw.DeleteDocuments(new Term(keyFiledName, keyFileValue.ToString()));
iw.Optimize();//Deleting a file does not remove it from the disk, but generates a. del file. You need to call the Optimize method to clear it. You can use UndeleteAll method to recover before clearing files
}
}
/// <summary>
///Update index record
/// </summary>
/// <param name="indexDir"></param>
/// <param name="keyFiledName"></param>
/// <param name="keyFileValue"></param>
/// <param name="doc"></param>
public static void UpdateIndex(string indexDir, string keyFiledName, object keyFileValue, Document doc)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
if (!IndexReader.IndexExists(directory))
{
return;
}
using (IndexWriter iw = new IndexWriter(directory, new PanGuAnalyzer(), IndexWriter.MaxFieldLength.UNLIMITED))
{
iw.UpdateDocument(new Term(keyFiledName, keyFileValue.ToString()), doc);
iw.Optimize();
}
}
/// <summary>
///Whether the specified index document exists
/// </summary>
/// <param name="indexDir"></param>
/// <param name="keyFiledName"></param>
/// <param name="keyFileValue"></param>
/// <returns></returns>
public static bool ExistsDocument(string indexDir, string keyFiledName, object keyFileValue)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
if (!IndexReader.IndexExists(directory))
{
return false;
}
var reader = IndexReader.Open(directory, true);
return reader.DocFreq(new Term(keyFiledName, keyFileValue.ToString())) > 0;
}
/// <summary>
///Query index matched records
/// </summary>
/// <typeparam name="TResult"></typeparam>
/// <param name="indexDir"></param>
/// <param name="buildQueryAction"></param>
/// <param name="getSortFieldsFunc"></param>
/// <param name="buildResultFunc"></param>
/// <param name="topCount"></param>
/// <param name="needHighlight"></param>
/// <returns></returns>
public static List<TResult> SearchIndex<TResult>(string indexDir, Func<BooleanQuery, IDictionary<string, string>> buildQueryAction,
Func<IEnumerable<SortField>> getSortFieldsFunc, Func<Document, TResult> buildResultFunc, bool needHighlight = true, int topCount = 0)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NoLockFactory());
if (!IndexReader.IndexExists(directory))
{
return new List<TResult>();
}
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
BooleanQuery bQuery = new BooleanQuery();
var keyWords = buildQueryAction(bQuery);
Sort sort = null;
var sortFields = getSortFieldsFunc();
if (sortFields != null)
{
sort = new Sort();
sort.SetSort(sortFields.ToArray());
}
topCount = topCount > 0 ? topCount : int.MaxValue;//When no TOP value is specified, set the maximum value to indicate that all
TopDocs resultDocs = null;
if (sort != null)
{
resultDocs = searcher.Search(bQuery, null, topCount, sort);
}
else
{
resultDocs = searcher.Search(bQuery, null, topCount);
}
if (topCount > resultDocs.TotalHits)
{
topCount = resultDocs.TotalHits;
}
Dictionary<string, PropertyInfo> highlightProps = null;
List<TResult> results = new List<TResult>();
if (resultDocs != null)
{
for (int i = 0; i < topCount; i++)
{
Document doc = searcher.Doc(resultDocs.ScoreDocs[i].Doc);
var model = buildResultFunc(doc);
if (needHighlight)
{
model = SetHighlighter(keyWords, model, ref highlightProps);
}
results.Add(model);
}
}
return results;
}
/// <summary>
///Records matched by paging query index
/// </summary>
/// <typeparam name="TResult"></typeparam>
/// <param name="indexDir"></param>
/// <param name="buildQueryAction"></param>
/// <param name="getSortFieldsFunc"></param>
/// <param name="buildResultFunc"></param>
/// <param name="pageSize"></param>
/// <param name="page"></param>
/// <param name="totalCount"></param>
/// <param name="needHighlight"></param>
/// <returns></returns>
public static List<TResult> SearchIndexByPage<TResult>(string indexDir, Func<BooleanQuery, IDictionary<string, string>> buildQueryAction,
Func<IEnumerable<SortField>> getSortFieldsFunc, Func<Document, TResult> buildResultFunc, int pageSize, int page, out int totalCount, bool needHighlight = true)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NoLockFactory());
if (!IndexReader.IndexExists(directory))
{
totalCount = 0;
return new List<TResult>();
}
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
BooleanQuery bQuery = new BooleanQuery();
var keyWords = buildQueryAction(bQuery);
Sort sort = null;
var sortFields = getSortFieldsFunc();
if (sortFields != null)
{
sort = new Sort();
sort.SetSort(sortFields.ToArray());
}
TopScoreDocCollector docCollector = TopScoreDocCollector.Create(1, true);
searcher.Search(bQuery, docCollector);
totalCount = docCollector.TotalHits;
if (totalCount <= 0) return null;
TopDocs resultDocs = searcher.Search(bQuery, null, pageSize * page, sort);
Dictionary<string, PropertyInfo> highlightProps = null;
List<TResult> results = new List<TResult>();
int indexStart = (page - 1) * pageSize;
int indexEnd = indexStart + pageSize;
if (totalCount < indexEnd) indexEnd = totalCount;
if (resultDocs != null)
{
for (int i = indexStart; i < indexEnd; i++)
{
Document doc = searcher.Doc(resultDocs.ScoreDocs[i].Doc);
var model = buildResultFunc(doc);
if (needHighlight)
{
model = SetHighlighter(keyWords, model, ref highlightProps);
}
results.Add(model);
}
}
return results;
}
/// <summary>
///Set result highlight
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="dicKeywords"></param>
/// <param name="model"></param>
/// <param name="props"></param>
/// <returns></returns>
private static T SetHighlighter<T>(IDictionary<string, string> dicKeywords, T model, ref Dictionary<string, PropertyInfo> props)
{
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<font color=\"red\">", "</font>");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new Segment());
highlighter.FragmentSize = 250;
Type modelType = typeof(T);
foreach (var item in dicKeywords)
{
if (!string.IsNullOrWhiteSpace(item.Value))
{
if (props == null)
{
props = new Dictionary<string, PropertyInfo>();
}
if (!props.ContainsKey(item.Key))
{
props[item.Key] = modelType.GetProperty(item.Key, BindingFlags.IgnoreCase | BindingFlags.Public | BindingFlags.Instance);
}
var modelProp = props[item.Key];
if (modelProp.PropertyType == typeof(string))
{
string newValue = highlighter.GetBestFragment(item.Value, modelProp.GetValue(model).ToString());
if (!string.IsNullOrEmpty(newValue))
{
modelProp.SetValue(model, newValue);
}
}
}
}
return model;
}
/// <summary>
///Split keywords
/// </summary>
/// <param name="keywords"></param>
/// <returns></returns>
public static string GetKeyWordsSplitBySpace(string keyword)
{
PanGuTokenizer ktTokenizer = new PanGuTokenizer();
StringBuilder result = new StringBuilder();
ICollection<WordInfo> words = ktTokenizer.SegmentToWordInfos(keyword);
foreach (WordInfo word in words)
{
if (word == null)
{
continue;
}
result.AppendFormat("{0}^{1}.0 ", word.Word, (int)Math.Pow(3, word.Rank));
}
return result.ToString().Trim();
}
/// <summary>
///Auxiliary method create Pangu query object
/// </summary>
/// <param name="field"></param>
/// <param name="keyword"></param>
/// <returns></returns>
public static Query CreatePanGuQuery(string field, string keyword, bool needSplit = true)
{
if (needSplit)
{
keyword = GetKeyWordsSplitBySpace(keyword);
}
QueryParser parse = new QueryParser(Lucene.Net.Util.Version.LUCENE_30, field, new PanGuAnalyzer());
parse.DefaultOperator = QueryParser.Operator.OR;
Query query = parse.Parse(keyword);
return query;
}
/// <summary>
///Auxiliary method: create Pangu multi field query object
/// </summary>
/// <param name="keyword"></param>
/// <param name="fields"></param>
/// <returns></returns>
public static Query CreatePanGuMultiFieldQuery(string keyword, bool needSplit, params string[] fields)
{
if (needSplit)
{
keyword = GetKeyWordsSplitBySpace(keyword);
}
QueryParser parse = new MultiFieldQueryParser(Lucene.Net.Util.Version.LUCENE_30, fields, new PanGuAnalyzer());
parse.DefaultOperator = QueryParser.Operator.OR;
Query query = parse.Parse(keyword);
return query;
}
}
}
In addition to Lucene.Net nuget package, PanGu word breaker and its related components are referenced separately, because most of our content will contain Chinese. The above code is no longer detailed, and the comments are clear. Here are some practical uses:
Create index:
SearchEngineUtil.AddIndex(GetSearchIndexDir(), post, (doc, data) => BuildPostSearchDocument(data, doc));
private Document BuildPostSearchDocument(Post post, Document doc = null)
{
if (doc == null)
{
doc = new Document();//Create Document
}
doc.Add(new Field("Id", post.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.Add(new Field("Title", post.Title, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("Summary", post.Summary, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("CreateTime", post.CreateTime.ToString("yyyy/MM/dd HH:mm"), Field.Store.YES, Field.Index.NO));
doc.Add(new Field("Author", post.IsOriginal ? (post.Creator ?? userQueryService.FindByName(post.CreateBy)).NickName : post.SourceBy, Field.Store.YES, Field.Index.NO));
return doc;
}
Delete index:
SearchEngineUtil.DeleteIndex(GetSearchIndexDir(), "Id", post.Id);
Update index:
SearchEngineUtil.UpdateIndex(GetSearchIndexDir(), "Id", post.Id, BuildPostSearchDocument(post));
Paging query:
var keyword = SearchEngineUtil.GetKeyWordsSplitBySpace("Dream on the journey Chinese dream");
var searchResult = SearchEngineUtil.SearchIndexByPage(indexDir, (bQuery) =>
{
var query = SearchEngineUtil.CreatePanGuMultiFieldQuery(keyword, false, "Title", "Summary");
bQuery.Add(query, Occur.SHOULD);
return new Dictionary<string, string> {
{ "Title",keyword},{"Summary",keyword}
};
}, () =>
{
return new[] { new SortField("Id", SortField.INT, true) };
}, doc =>
{
return new PostSearchInfoDto
{
Id = doc.Get("Id"),
Title = doc.Get("Title"),
Summary = doc.Get("Summary"),
Author = doc.Get("Author"),
CreateTime = doc.Get("CreateTime")
};
}, pageSize, pageNo, out totalCount);
Others: judge whether the specified document record in the index exists, query the qualified index document, etc. are not listed here. If you are interested, you can COPY it to your own project for testing.
Here you can see the effect of applying the search scenario in my own project (a new version of my blog, still under development):
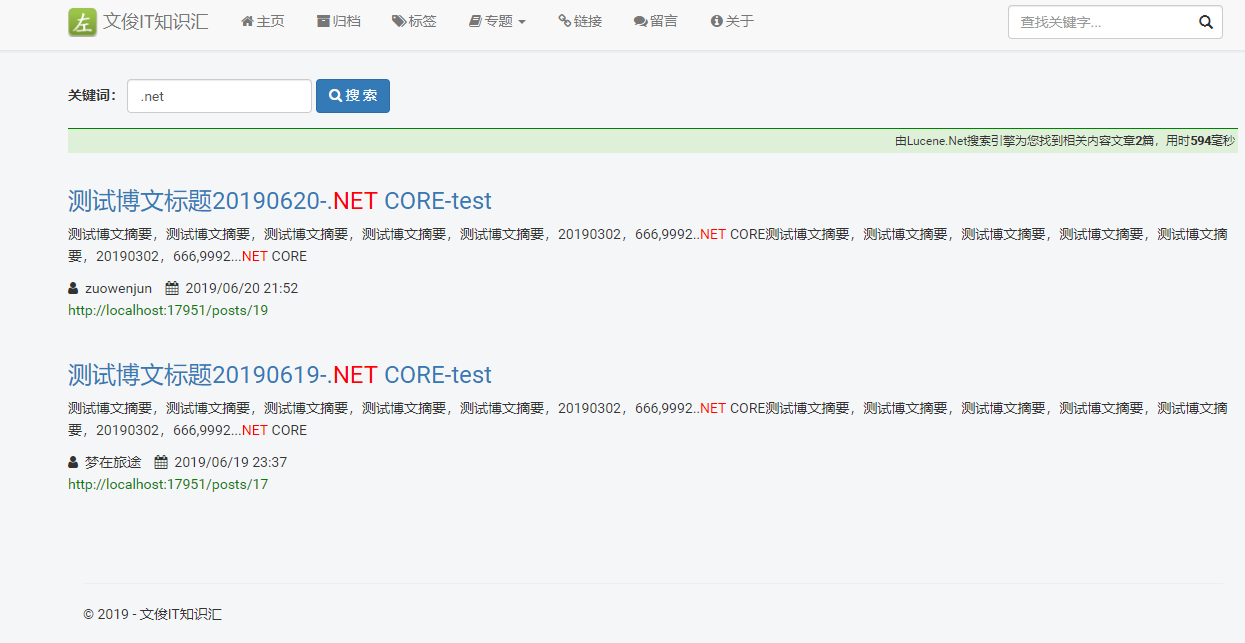
At last, it is explained that Lucene is not a complete full-text search engine, but understanding it is helpful for learning elasticsearch and solr. At present, Lucene is generally used in actual production projects, mostly using higher-level elasticsearch and solr.
(I wrote the code in this article a long time ago this year, and only shared it today.)
I like to encapsulate some common components, such as:
Encapsulate MongoDbCsharpHelper class (CRUD class) based on MongoDb official C ා driver