Spring Content
spring's AOP order
Common Notes for AOP:
- @Before Pre-Notification: Execute before Target Method
- @After Post Notification: After Target Method Executes (Always Executes)
- @AfterReturning Return Notification: Execute before method end (exception not execute)
- @AfterThrowing exception notification: execute when an exception occurs
- @Around Wrap Notification: Wrap Target Method Execution
Face class:
Interpretation of the execution expression The first public int represents the return value type (you can use * to denote all returns), followed by the package name.Class name (you can also use.. * to denote all classes under the package here), and the first * in the. *(..) denotes all methods, the next () denotes parameters, and the... Denotes all parameters
@Aspect
@Component
public class MyASpect {
@Before("execution(public int spring.test.demo.MyAOPImpl.*(..))")
public void beforeNotify(){
System.out.println("@Before Method Called....");
}
@After("execution(public int spring.test.demo.MyAOPImpl.*(..))")
public void afterNotify(){
System.out.println("@After Method Called....");
}
@AfterReturning("execution(public int spring.test.demo.MyAOPImpl.*(..))")
public void afterReturningNotify(){
System.out.println("@AfterReturning Method Called....");
}
@AfterThrowing("execution(public int spring.test.demo.MyAOPImpl.*(..))")
public void afterThrowingNotify(){
System.out.println("@AfterThrowing Method Called....");
}
@Around("execution(public int spring.test.demo.MyAOPImpl.*(..))")
public Object around(ProceedingJoinPoint proceedingJoinPoint)throws Throwable{
Object retValue=null;
System.out.println("@Around Before wrapping notifications....");
retValue=proceedingJoinPoint.proceed();
System.out.println("@Around After wrapping notification....");
return retValue;
}
}
Interface Implementation Class
@Service
public class MyAOPImpl implements MyAOPService {
@Override
public int div(int x, int y) {
int result=x/y;
System.out.println("AOP Implementation method called....The result is:"+result);
return 0;
}
}
test method
@Test
void contextLoads() {
myAOPService.div(3,3);
}The following tests are for SpringBoot 2.3.7, no abnormal print results
@Around before notification...
The @Before method was called...
The AOP implementation method was called.... The result is:1
The @AfterReturning method was called...
The @After method was called...
@Around after notification...
Exceptional Print Results
@Around before notification...
The @Before method was called...
The @AfterThrowing method was called...
The @After method was called...
The following is a printout of springBoot 1.5.9
normal
@Around before notification...
The @Before method was called...
The AOP implementation method was called.... The result is:1
The @After method was called...
The @AfterReturning method was called...
@Around after notification...
Exceptions
@Around before notification...
The @Before method was called...
The @After method was called...
The @AfterThrowing method was called...
To summarize, the After method of Spring4 is always executed before AfterThrowing and AfterReturning, and Spring5 is executed after that. It is understood that After method is executed last and must be executed. It should be placed in final.
Spring's circular dependency
What is circular dependency?
Multiple beans depend on each other to form a closed loop.a depends on b,b depends on c,c depends on a. Usually, if you ask how to solve the circular dependency problem in the spring container, you must refer to the scenario where attributes refer to each other in the default single bean.Rather than injecting through a constructor. Constructor cyclic dependencies are not solvable (this is understandable, similar to deadlock problems)
If there are multiple object types for prototype


BeanCurrentlyInCreationException circular dependency error is also reported, so it is not applicable for prototype scenarios
How does spring solve circular dependency?
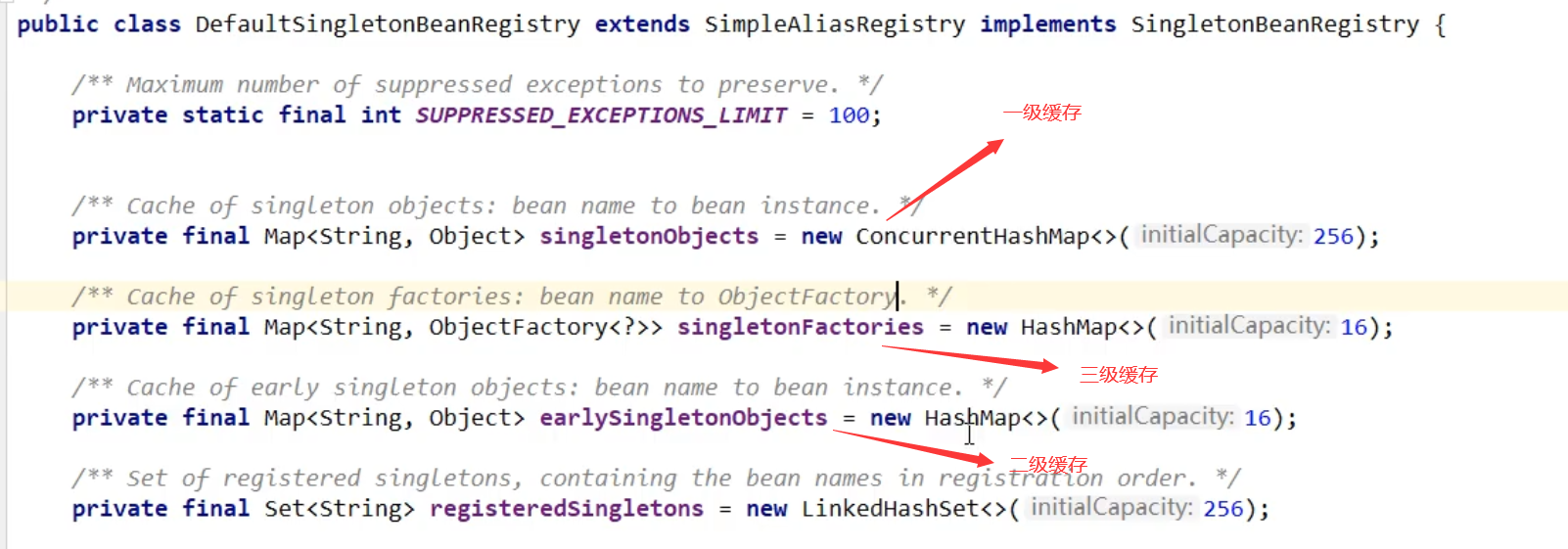
Level 3 Cache - DefaultSingletonBeanRegistry
Instantiation--Request an in-memory space initialization--Complete various assignment fills for attributes
- Level 1 Cache: Stores Bean objects that have gone through their full life cycle (initialized)
- Secondary Cache: Stores Bean objects exposed in the morning, and the Bean's life cycle is not over (properties are not filled out, instantiated but not initialized)
- Level 3 Cache: Stores factory FactoryBeans that can generate beans. If Class A implements FactoryBeans, then the beans produced by Class A are not injected on injection
Process description:
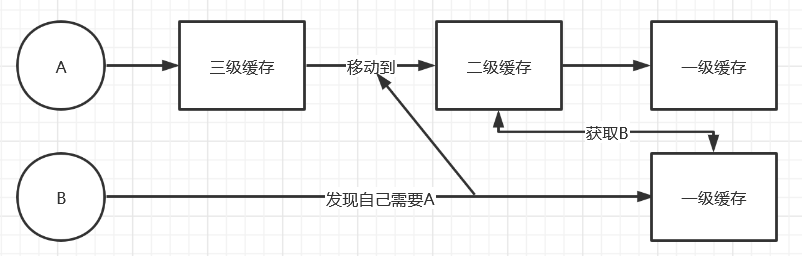
- A needs B in the creation process, so A puts itself in the third level cache to instantiate B
- When B instantiates, it finds that A is needed, so B first looks up the first level cache and the second level cache and finds no, then goes to the third level cache, finds A, then moves A from the third level cache into the second level cache and deletes A from the third level cache.
- B is initialized and placed in the first level cache. Attribute A in B is still in the process of creation. Then it comes back and creates A. At this time, B has been created and finished, B is taken directly from the first level cache, the creation is completed, and A itself is placed in the first level cache.
Source analysis summary:
- Spring creates beans in two main steps, creating the original bean object, then populating the object and initializing it
- Every time a bean is created, we check from the cache to see if it exists because it is a singleton and there can only be one
- When we create the original object of A, we put it in the third-level cache, and then it's time to populate the object properties. We find that we depend on B, and then we create the B object. The same process creates the B-fill properties and finds that A is the same process again. However, the difference is that we can find the A just put in the third-level cache at this time, so we don't need to continue creating it.Completed B creation with A in Level 3 cache
- Once B is created, A can complete the steps to fill in the attributes and the closed loop is completed
Redis Content
The five traditional data types and floor applications of redis (redis commands are case-insensitive, but key values are):
string:(Commodity number is generated by incr command, dots and steps)
- Set/Get multiple build values at the same time: mset key value key value.../mget key key key...
- Incremental/Decreasing Number incr/decr key
- Increase/decrease specified number incrby/decrby key increment
- Get the string length bar strlen key
- Distributed lock set NX key value/set key value[EX seconds][px milliseconds][NX|XX] ex stands for seconds, px stands for milliseconds, NX stands for keys when they do not exist, creating keys is equivalent to set nx, XX means overwriting keys when keys exist

list:(Paging Query)
- Add elements to the left/right side of the list: lpush/rpush key value
- View the list lrange key start stop (all traversed when stop is -1)
- Gets the number of elements in the list llen key
Hash: <string, Map<Object, Object> (early shopping cart)
- Set/Get one field value at a time: hset key field value/hget key field
- Set/Get more than one at a time: hmset key field value.../hmget key field...
- Get all field values: hegetall key
- Get the total number of HLEN keys within a key
- Delete a key hdel key
set:(union: mutual friends, random lottery. user compliment)
- Add/remove element sadd/srem key member
- Gets all elements smembers key in the collection
- Determines whether an element is a sismember key member in a set
- Gets the number of elements in the collection scard key
- Randomly pop up a number of elements from the set without deleting them. By default, no number is an srandmember key [number]
- Randomly pop up a number of elements from the set, delete the element spop key [number]
- Difference set operation of sets A-B sdiff key
- Intersection operation of sets A_B sinter key
- Set union A_B sunion key
Zset: (sorted display, hot search, etc. based on sales of goods)
- Add an element and its score: zadd key score member
- Returns elements in a range from smallest to largest: zrange key start stop
- Gets the element of the specified score range: zrangebyscore key min max
- Increase the fraction of an element zincrby key increment member
- Gets the number of elements in the collection zcard key
- Gets the number of elements within the specified score range: zcount key min max
- Remove element zremrangebyrank key start stop by rank range
Get the rank of elements from smallest to largest/from largest to smallest: zrank key member/zrevrank key member
- Additional data types are bitmap, hyperloglog, GEO, stream.
Do you know distributed locks? What are the implementations? What are the problems when deleting key s?
Scenario for using distributed locks: multiple services + at one time + one request from the same user
The initial case of purchasing goods is an example where there is no error in a single machine version, but not in a multithreaded case with high concurrency

Improvement 1: Using synchronized or reentrantLock: In distributed scenarios, each lock can only lock a local block of service code, so each service can enter a single request, as many micro-services can enter as many requests
Improvement 2: Use distributed lock--setIfAbsent placeholder lock
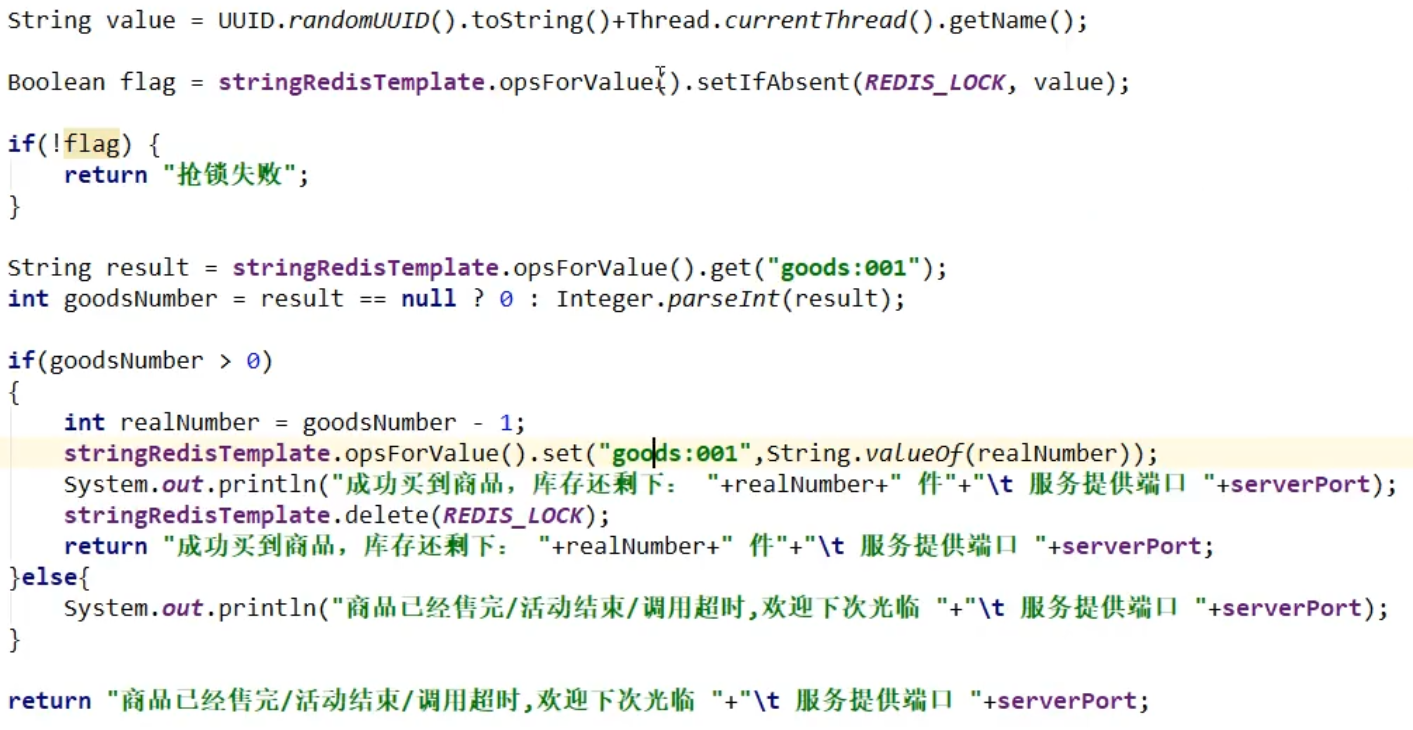
Improvement 3: The unlocking process must be wrapped in a finally block of code

Improvement 4, what to do if the program is down, need to add expiration time

Improvement 5, this is not an atomic operation. What if you just shut down when you set it up? Atomic operation into one line statement

Improvement 6. What if the business is long, Carton, and the set expiration time is exceeded? Locks are automatically deleted, causing other threads to rush in and get locks. When Carton's threads recover, they will delete other people's locks - each lock is set differently. When unlocking, it is decided that it is their own lock to delete.

Improvement 7, the operation to delete a lock now and to judge your own lock is not an atomic operation. It is possible that the lock will expire just after you have judged it, and someone else's lock will be deleted by mistake--change to a LUA script to solve/if you can't use the LUA script to do so (use redis own transaction, and the queue will be empty if the transaction fails)
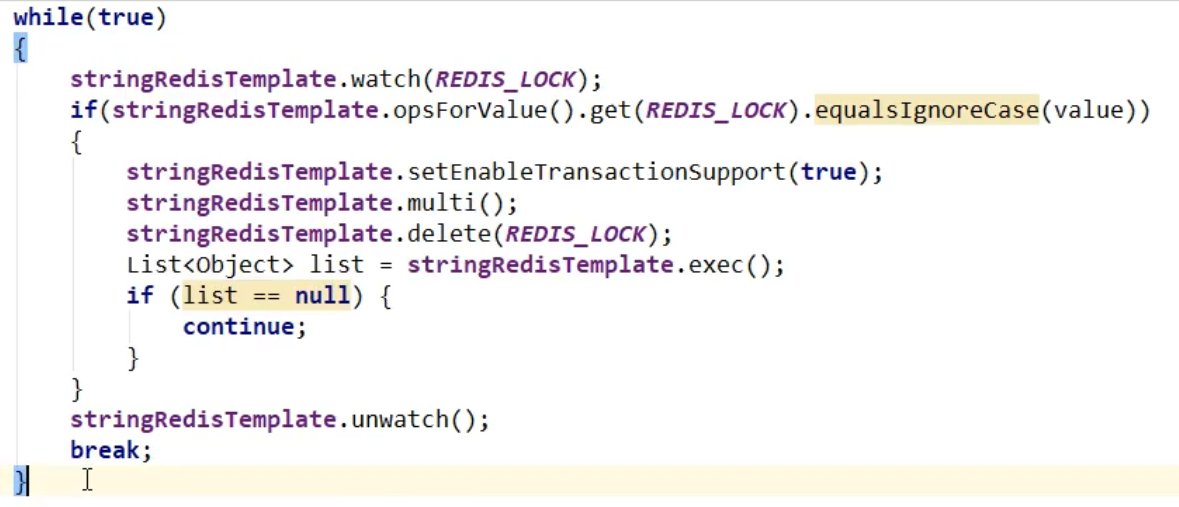
LUA scripting
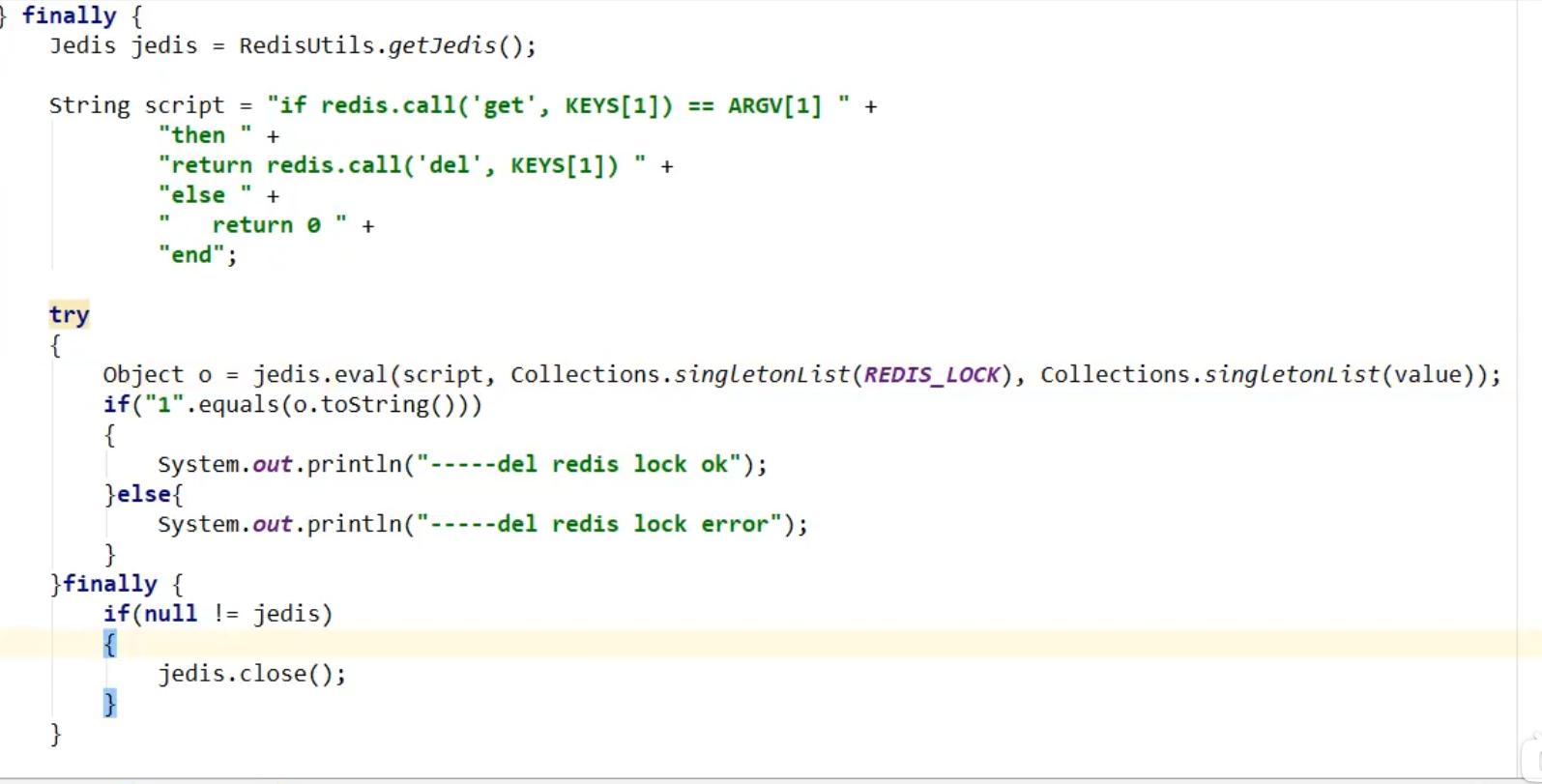
Amendment 8: If the business is lengthy, locks will still be deleted first and other threads will flow in. Redis distributed locks implement cache renewals - watchdog. However, in case of cluster problems, we can't actually write code to solve the problem of data loss during cluster master-slave replication (Redis guarantees high available AP relative to zookeeper's CP guaranteed reliability).--Redisson distributed locks are the only way to ensure these two points



Amendment 9: An error attempt to unlock lock,notlocked by current thread by node id will be reported in the case of excessive concurrency. Add the following actions when unlocking

redis memory adjustment default view
View memory info memory
Modify line 859 of the redis configuration file to set the maxmemory parameter in byte bytes. It is generally recommended that redis memory be set to three-quarters of the maximum physical memory. You can also modify the config set maxmemory value by command
redis Memory Elimination Policy
- Lazy Delete - Data will not be processed until it reaches its expiration date. Delete it the next time it is accessed, CPU-friendly, memory-unfriendly
- Delete on time--Traverse the data once at a specified interval, delete directly when expired, not CPU-friendly, memory-friendly
Both of these options go to extremes, which requires a memory phase-out strategy
Set by config set maxmemory-policy policy
The default is noevication: no key s will be deleted waiting for memory to explode

What is the LRU algorithm?Choose the most recently unused data to phase out

Speculation:
class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;
//The third parameter indicates whether insertion is turned on and reordered
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}Handwriting a lua
addHead method
public class LuaDemo {
private int cacheSize;
Map<Integer,Node<Integer,Integer>> map;
DoubleLinkedList<Integer,Integer> doubleLinkedList;
public LuaDemo(int cacheSize) {
this.cacheSize = cacheSize;
this.map = new HashMap<>();
this.doubleLinkedList = new DoubleLinkedList<Integer,Integer>();
}
public void print(){
map.forEach((k,v)->{
System.out.println("key:"+k+" value:"+v.value);
});
}
public int get(int num){
if(!map.containsKey(num))return -1;
Node<Integer,Integer> node = map.get(num);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
return node.value;
}
public void put(int num,int value){
if(map.containsKey(num)){
Node<Integer,Integer> node = map.get(num);
node.value=value;
map.put(num,node);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
}else{
if(map.size()==cacheSize){
Node<Integer,Integer> last = doubleLinkedList.getLast();
map.remove(last.key);
doubleLinkedList.removeNode(last);
}
Node<Integer,Integer> newNode=new Node<>(num,value);
map.put(num,newNode);
doubleLinkedList.addHead(newNode);
}
}
//Construct a node as a data carrier
class Node<K,V>{
K key;
V value;
Node<K,V> prev;
Node<K,V> next;
public Node(){
this.prev=this.next=null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev=this.next=null;
}
}
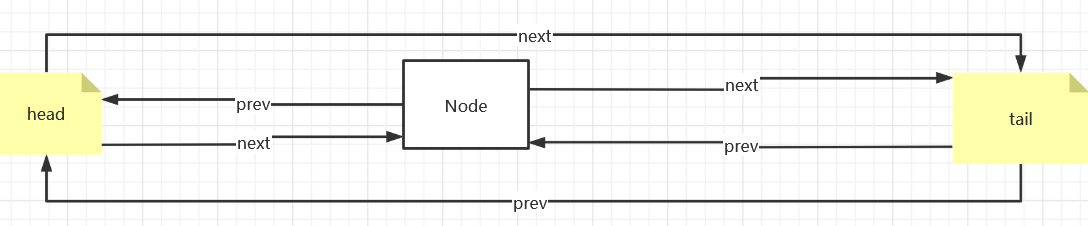
//Building a virtual two-way chain table
class DoubleLinkedList<K,V>{
Node<K,V> head;
Node<K,V> tail;
//Head and tail nodes connected
public DoubleLinkedList() {
this.head = new Node<>();
this.tail = new Node<>();
head.next=tail;
tail.prev=head;
}
//Add a Node
public void addHead( Node<K,V> node){
//Subsequent Connection Tail Node
node.next=head.next;
//Front-end connector node
node.prev=head;
//The precursor node of the tail node connects to the node
head.next.prev=node;
//The succeeding node of the head node points to the node
head.next=node;
}
//Delete a Node
public void removeNode(Node<K,V> node){
//The precursor of a node's successor node is equal to the precursor of the current node
node.next.prev=node.prev;
//The succession of a node's precursor node is equal to that of the current node
node.prev.next=node.next;
//Disconnect Front End
node.prev=null;
node.next=null;
}
//Get the last node
public Node getLast(){
return tail.prev;
}
}
public static void main(String[] args) {
LuaDemo luaDemo = new LuaDemo(3);
luaDemo.put(1,1);
luaDemo.put(2,2);
luaDemo.put(3,3);
luaDemo.print();
System.out.println("-------");
luaDemo.put(2,6);
luaDemo.print();
System.out.println("-------");
luaDemo.put(4,5);
luaDemo.print();
}
}Print results:
key:1 value:1
key:2 value:2
key:3 value:3
-------
key:1 value:1
key:2 value:6
key:3 value:3
-------
key:2 value:6
key:3 value:3
key:4 value:5