Synchronized principle
Chapter one: three problems of concurrent programming
visibility
concept
Visibility: when one thread modifies a shared variable, other threads get the latest information immediately after the modification
demonstration
//1. Static member variable
private static boolean var = true;
public static void main(String[] args) throws InterruptedException {
//2. Create a thread. Keep reading the value of shared variables
new Thread(() -> {
while (var) {
System.out.println("Continue execution");
}
}).start();
Thread.sleep(2000);
//3. Create a new variable and modify the value of the shared variable
new Thread(() -> var = false ).start();
}
The modified value of 3 is not immediately obtained in 2 after modification of 3.
Atomicity
Concept: in one or more operations, or all operations will not be interrupted by other factors. Or all operations are not performed.
Case demonstration:
/***
* Atomicity
* Demonstrate that five threads execute 1000 times i++
*/
public class Atom {
//Define shared variable num
private static Integer num = 0;
public static void main(String[] args) throws InterruptedException {
// 2 perform 1000 + + operations on num
Runnable increment = () -> {
for (int i = 0;i< 1000; i++) {
num ++;
}
};
//Define list combination
Thread t = null;
//3 generate 5 threads
List<Thread> list = new ArrayList<>();
for (int i= 0 ;i < 5; i++) {
t = new Thread(increment);
t.start();
list.add(t);
}
//4 wait until all threads are completed before executing the main thread
for (Thread tt: list) {
tt.join();
}
System.out.println(num);
}
Order
Concept:
ordering: refers to the code execution order in the program. java recompilation and runtime will optimize the code, which will lead to the final execution of the program not necessarily in the order of the code we write.
demonstration:
pom dependency needs to be added
org.openjdk.jcstress jcstress-core 0.15 test/***
* Order
*/
@JCStressTest
@Outcome(id={"1","4"} ,expect = Expect.ACCEPTABLE,desc = "ok")
@Outcome(id={"0"} ,expect = Expect.ACCEPTABLE_INTERESTING,desc = "danger")
@State
public class Order {
int num = 0;
boolean ready = false;
@Action
public void actor1(I_Result r) {
if (ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}@Action
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
java Memory Model (JMM)
Computer structure
Von Neumann proposed that the computer consists of five parts: input equipment, output equipment, memory, controller and arithmetic unit
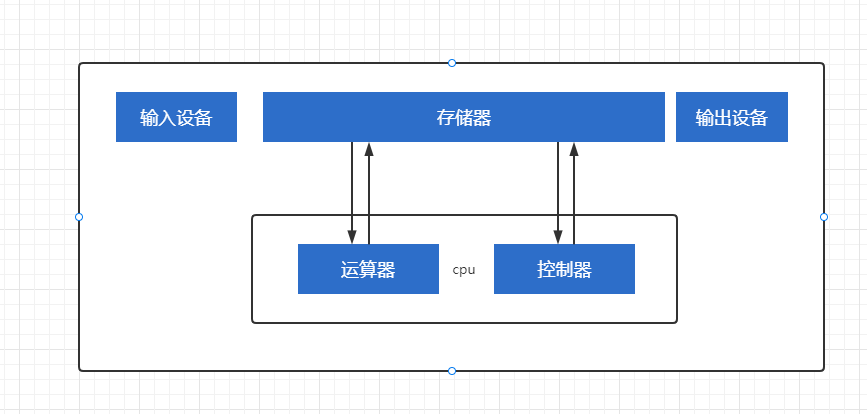
cpu
cpu is the core of computer control and operation. Our programs will program instructions for cpu to execute and process the data in the program.
Memory
Our programs run in memory, which will save the data when the program runs. For cpu processing
cache
There is a big difference between the operation speed of cpu and the access speed of memory. This causes the cpu to spend a long time waiting for each operation. The reading and writing speed of memory has become the bottleneck of computer operation. So there is the design of adding cache between cpu and main memory. L1 and L3 become the closest main memory in turn, and then L2 becomes the closest main memory.
cpu cache is divided into three levels: L1, L2 and L3. The smaller the level, the closer it is to the cpu, and the faster it is. It also means that the smaller the capacity.
1. L1 is closest to the cpu, with the smallest capacity, such as 32k, and the fastest speed. There is an L1 cache on each core
2. L2 is larger. For example, 256K is slower. Generally, there is an independent L2 cache on each core.
3. L3 is the largest level. For example, 12MB is also the slowest level in the cache. Cores in the same cpu slot share an L3 cache
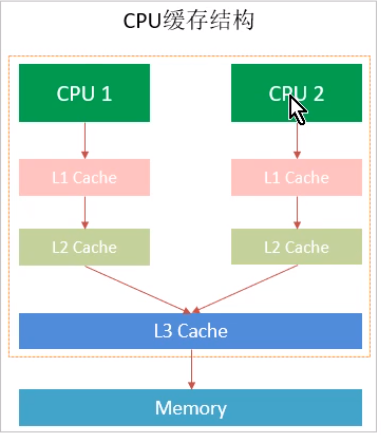
The cpu reads the L1 cache before reading the data. If you get the data and synchronize it to memory after processing. If L1 has no corresponding data. Find L2 cache, L3 cache and memory data in turn. After the cpu obtains the data for operation, it will save it back to L1 cache.
java Memory Model
java memory model (java memory model / JMM) should not be confused with jiava memory results.
java memory model is a memory model defined in the java virtual machine specification. java memory model is standardized and shields the differences between different underlying computers.
java memory model is a set of specifications, which describes the access rules of various variables (thread shared variables) in java programs, as well as the underlying details of storing variables into memory and reading variables from memory in the jvm, as follows.
- Main memory
Main memory is shared by all threads. Can be accessed. All thread variables are stored in main memory.
- Working memory
Each thread has its own working memory, which only stores a copy of the shared variables of the line change city. All operations (reading and writing) of threads on variables must be completed in working memory, rather than directly reading and writing variables in main memory. Different threads cannot directly access each other's working memory variables.
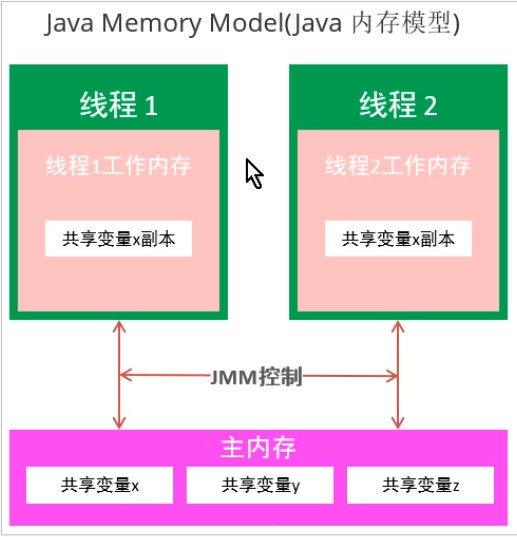
Threads read variables in shared memory. First, copy the shared variable in main memory to the contribution shared variable in thread memory. Operate on the shared variable copy, and then synchronize the copy back to the shared variable in main memory.
The role of java Memory Model
java memory model is a set of rules and guarantees for the visibility, order and atomicity of shared data when multithreading reads and writes shared data.
synchronized,volatile
Relationship between CPU cache and memory and java Memory Model
Through the above understanding of cpu memory, java Memory Model and the implementation principle of java multithreading. We have realized that the execution of multithreading will eventually be mapped to the hardware processor for execution.
However, the java memory model is completely inconsistent with the hardware memory structure. For hardware memory, there are only the concepts of register, cache memory and main memory, and there is no distinction between working memory and main memory. It is not said that the division of java memory model has no impact on hardware, because JMM is only an abstract concept and a set of rules, whether it is the data of working memory or the data of main memory, For a computer, it will be stored in the main memory of the computer. Of course, it may also be stored in the cup cache or register. In turn, generally speaking, the java Memory Model and the memory architecture of computer hardware are a cross relationship, which is a cross between the division of abstract concepts and real physical hardware.
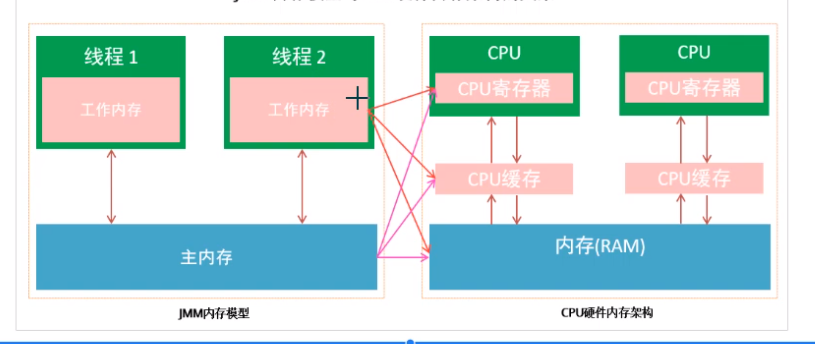
Interaction between main memory and working memory
Eight operations are defined in java memory to complete. The specific interaction protocol between main memory and working memory, that is, the implementation details of how to copy a variable from main memory to working memory and how to synchronize main memory from working memory. During the implementation of virtual machine, each operation mentioned below must be atomic and inseparable.
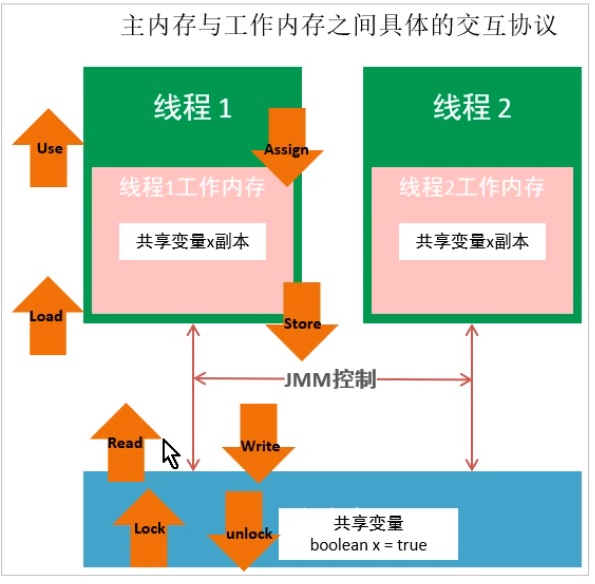
be careful:
1. If you perform a lock operation on a variable, the working memory will be emptied of the value of this variable.
2. Before unlock ing a variable, you must synchronize the variable into main memory.
8 atomic operations
lack -> read ->load -> use -> assign -> store -> write -> unlock
Chapter 3: three features of synchronized assurance
synchronized can ensure that at most one thread executes the code at the same time, so as to ensure concurrency safety.
synchronized (Lock object) {
//Protected resources;
}
synchronized ensures atomicity
demonstration:
/***
* Atomicity
* Demonstrate that five threads execute 1000 times i++
*/
public class Atom {
//Define shared variable num
private static Integer num = 0;
private static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 2 perform 1000 + + operations on num
Runnable increment = () -> {
for (int i = 0;i< 1000; i++) {
synchronized (obj) {
num++;
}
}
};
//Define list combination
Thread t = null;
//3 generate 5 threads
List<Thread> list = new ArrayList<>();
for (int i= 0 ;i < 5; i++) {
t = new Thread(increment);
t.start();
list.add(t);
}
//4 wait until all threads are completed before executing the main thread
for (Thread tt: list) {
tt.join();
}
System.out.println(num);
}
}
synchronized principle:
Ensure that there is only one thread operation at the same time, and there will be no safety problems. Ensure that a thread gets the lock before entering the synchronous code block.
synchronized ensures visibility
1. Using volatile
private static volatile boolean var = true;
Principle: the thread modifies the variables in the main thread. The memory of other threads will reset the copy of this variable. Causes another thread to reread the variable.
2. Using synchronized
/***
* Visibility issues
*/
public class Visibility {
//1. Static member variable
//The first scheme
// private static volatile boolean var = true;
private static boolean var = true;
private static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
//2. Create a thread. Keep reading the value of shared variables
new Thread(() -> {
while (var) {
synchronized (obj) {
System.out.println("Continue execution");
}
}
}).start();
Thread.sleep(2000);
//3. Create a new variable and modify the value of the shared variable
new Thread(() -> var = false ).start();
}
Synchronized ensures visibility. When synchronized is executed, it will perform atomic operations on lock and refresh the values of shared variables in working memory.
synchronized ensures order
The meaning of as if serial semantics: no matter how the compiler and cpu reorder, we must ensure that the results of the program are correct in the case of single thread.
The following data has dependencies and cannot be reordered.
Write follow-up:
int a = 1; int b = a;
Write after write:
int a = 1; int a = 2;
Write after reading:
int a = 1; int b = a; int a = 2;
Compilers and processors will not rush sort operations with existing data dependencies, because this reordering will change the execution results. However, if there is no data dependency between operations, they may be sorted by the compiler.
int a = 1; int b = 2; int c = a + b;
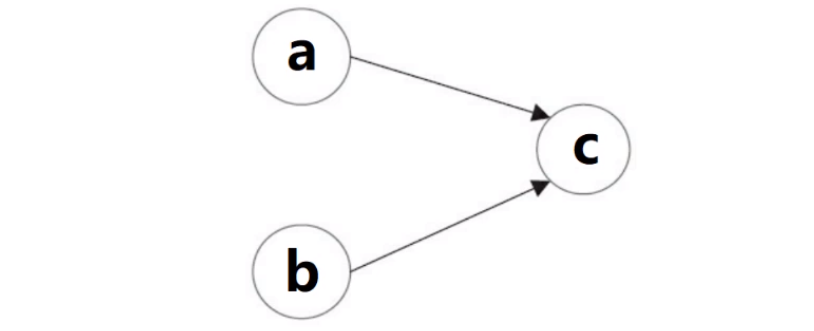
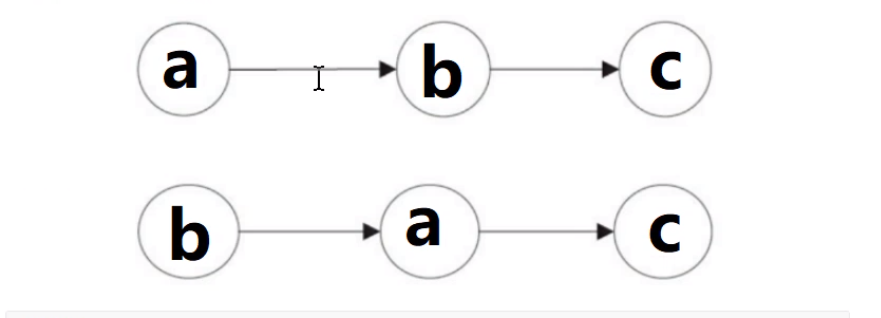
As shown in the figure above, there is a dependency between a and c, and there is a dependency between b and c. Therefore, in the final executed instruction, c cannot be sorted before a and b. However, there is no dependency between a and b. the compiler and processor can reorder the execution order between a and b. The following two execution sequences of the modification.
synchronized sorting method
/***
* Order
*/
//@JCStressTest
//@Outcome(id={"1","4"} ,expect = Expect.ACCEPTABLE,desc = "ok")
//@Outcome(id={"0"} ,expect = Expect.ACCEPTABLE_INTERESTING,desc = "danger")
//@State
public class Order {
int num = 0;
boolean ready = false;
private static Object obj = new Object();
// @Action
public void actor1(I_Result r) {
synchronized (obj) {
if (ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
}
// @Action
public void actor2(I_Result r) {
synchronized (obj) {
num = 2;
ready = true;
}
}
synchronized guaranteed reordering principle
Equivalent to a single thread executing a code block.
Chapter 4: synchronized features
1. Reentrant
A thread can perform synchronized operations multiple times and repeatedly acquire the same lock.
Principle: there is a counter (recursions variable) in the synchronized lock object, which will record the number of times the thread obtains the lock When the code block is executed, the counter will be - 1. When the number of counters is 0, the lock will be released.
Advantages: avoid deadlock.
2. Non interruptible
After a thread obtains a lock, another thread must be in a blocking or waiting state if it wants to obtain the lock. If the first thread does not release the lock, the second thread will always block or wait and cannot be interrupted.
synchronized is non interruptible.
The lock method of lock cannot be interrupted.
Lock's trylock method can be interrupted.
Chapter 5: synchronized principle
Synchronous code block
Source code:
package com.cn.java;
public class Main {
private static Object object = new Object();
public static void main(String[] args) {
synchronized (object) {
System.out.println(1);
}
}
public synchronized void test() {
synchronized (object) {
System.out.println("a");
}
}
}
Find the corresponding file, output cmd in the address bar and enter the dos command
javap -p -v Main.class
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: getstatic #2 // Field object:Ljava/lang/Object;
3: dup
4: astore_1
5: monitorenter
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: iconst_1
10: invokevirtual #4 // Method java/io/PrintStream.println:(I)V
13: aload_1
14: monitorexit
15: goto 23
18: astore_2
19: aload_1
20: monitorexit
21: aload_2
22: athrow
23: return
5: monitorenter //Acquire lock
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #5 // String a
11: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: aload_1
15: monitorexit //Release lock
Description of monitorenter in jvm
Each object is associated with a monitor. When the monitor is occupied, it will be locked, and other threads will get the monitor. When the jvm executes the monitorenter of a method of a thread, it will try to obtain the corresponding monitor ownership of the current object. The process is as follows:
1. If the entry number of monitor is 0, the thread can enter monitor and set the entry of monitor to 1 When the money thread is the owner of monitor.
2. If the thread already owns the monitor, it is allowed to re-enter the monitor, which is the number of entries in the monitor plus 1
3. If other threads already possess the ownership of monitor, the thread currently trying to acquire the ownership of monitor will be blocked. Only after knowing that the number of entries of the owner of monitor is 0, can we try to acquire the ownership of monitor again.
An exception in the synchronization code block releases the lock.
Synchronization method
public synchronized void test();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=3, args_size=1
0: getstatic #2 // Field object:Ljava/lang/Object;
3: dup
4: astore_1
5: monitorenter
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #5 // String a
11: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: aload_1
15: monitorexit
16: goto 24
19: astore_2
20: aload_1
21: monitorexit
22: aload_2
23: athrow
24: return
Will increase ACC_PUBLIC, ACC_SYNCHRONIZED modification. Monitorenter and monitorexit are implicitly called. When the synchronization method is executed, monitorenter is called. Monitorexit is called after execution.
Each lock object will be associated with a monitor, which has two important member variables. owner will save the thread that obtains the lock, and recursions will save the number of times it obtains the lock.
When monitorenter is executed, recursions will + 1. When monitorexit is executed, recursions will - 1. When recursions = 0, the thread releases the lock.
Common interview questions: the difference between synchronized and lock.
1. synchronized is a common keyword. Lock is the interface.
2. synchronized automatically releases the lock. Lock must be released manually.
3. synchronized is non interruptible. Lock can be interrupted or not.
4. Through Lock, you can know whether the thread has got the Lock. synchronized cannot.
5. synchronized locks objects and blocks of code. lock intelligently locks code blocks.
6. Lock can use read-write lock to improve thread reading efficiency.
7. synchronized is a non fair lock. ReetrantLock can null whether it is a fair lock.
In depth JVM source code
Download jvm source code
http://openjdk.java.net/ --> mercurial --> jdk8 --> hotspot --> zip
IDE(Clion) Download
https://www.jetbrains.com/
monitor lock
Whether synchronized code blocks or synchronized methods, their thread safe semantic implementation ultimately depends on something called monitor. So what is this monitor? Let's introduce it in detail.
In the hotspot virtual machine, monitor is implemented by ObjectMonitor, and its source code is implemented in c + +, which is located in ObjectMonitor HPP file (src/share/vm/runtime/objectMonitor.hpp). The main data structure of ObjectMonitor is as follows:
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; //Number of thread reentries
_object = NULL;//The thread that stores the monitor object
_owner = NULL;//Identifies the thread that owns the monitor
_WaitSet = NULL;//Threads in wait state will be added to_ waitset
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;//A multithreaded contention lock is a single item list
FreeNext = NULL ;
_EntryList = NULL ;//Threads in the state of waiting for lock block will be added to the list
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
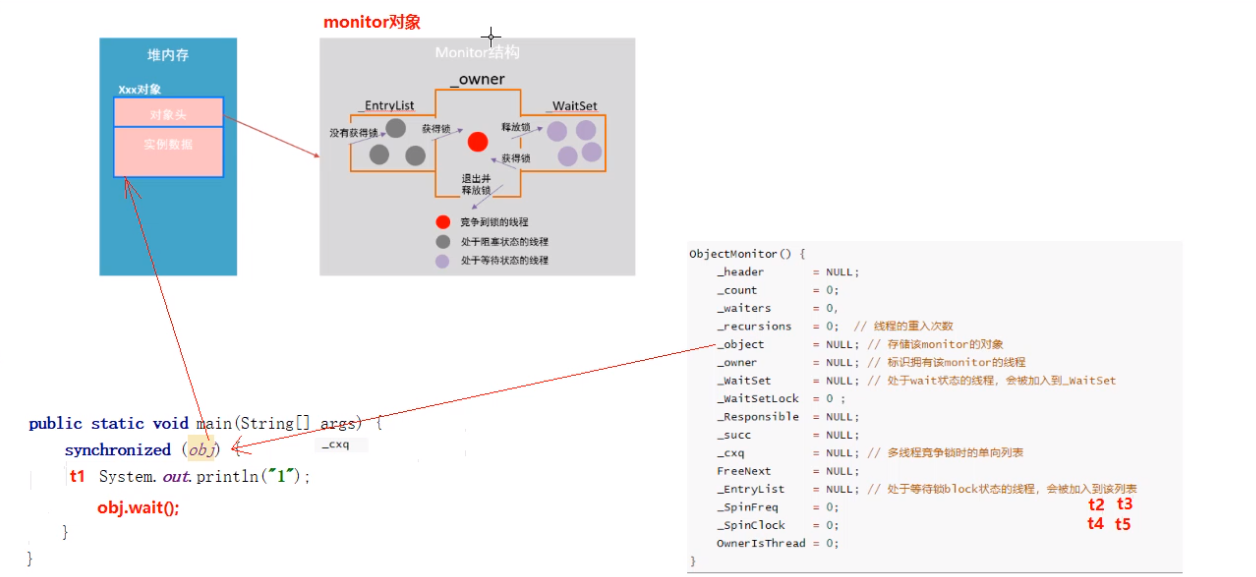
Two threads t1, t2 and t3 enter after t1 is locked_ cxq wait. If t1 grabs the lock after t1 execution, t2 and t3 enter_ EntryList waiting.
There are two threads t4, t5 and t1. After the execution is completed, t1 grabs the lock again. t4 and t5 enter_ Wait in EntryList.
monitor competition
1. When the monitorenter is executed, the interpreterruntime is called cpp
The interpreterRuntime::monitorenter function located in (src/share/vminterpreter/interpreterRuntime.cpp). Please refer to the HotSpot source code for the specific code.
//%note monitor_1
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) { //Whether to set deflection lock
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else { //Call heavyweight lock
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),
"must be NULL or an object");
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
IRT_END
2. For heavyweight locks, objectsynchronizer:: slow will be called in the monitorenter function_ enter
3. Finally, call objectmonitor:: enter (located in src/share/vm/runtime/objectMonitor.cpp)
void ATTR ObjectMonitor::enter(TRAPS) {
// The following code is ordered to check the most common cases first
// and to reduce RTS->RTO cache line upgrades on SPARC and IA32 processors.
Thread * const Self = THREAD ;
void * cur ;
//Try to monitor through cas operation_ The owner field is set to the current thread.
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
// Either ASSERT _recursions == 0 or explicitly set _recursions = 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
// CONSIDER: set or assert OwnerIsThread == 1
return ;
}
//If you grab the lock
if (cur == Self) {
_recursions ++ ; //All right_ recursions attribute plus 1
return ;
}
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ;
_owner = Self ; //If you get the lock, set the thread owner to self
OwnerIsThread = 1 ;
return ;
}
assert (Self->_Stalled == 0, "invariant") ;
Self->_Stalled = intptr_t(this) ;
if (Knob_SpinEarly && TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_recursions == 0 , "invariant") ;
assert (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;
Self->_Stalled = 0 ;
return ;
}
assert (_owner != Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (Self->is_Java_thread() , "invariant") ;
JavaThread * jt = (JavaThread *) Self ;
assert (!SafepointSynchronize::is_at_safepoint(), "invariant") ;
assert (jt->thread_state() != _thread_blocked , "invariant") ;
assert (this->object() != NULL , "invariant") ;
assert (_count >= 0, "invariant") ;
Atomic::inc_ptr(&_count);
EventJavaMonitorEnter event;
{
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
DTRACE_MONITOR_PROBE(contended__enter, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_enter()) {
JvmtiExport::post_monitor_contended_enter(jt, this);
}
OSThreadContendState osts(Self->osthread());
ThreadBlockInVM tbivm(jt);
Self->set_current_pending_monitor(this);
//If you don't grab the lock. The following code is executed.
for (;;) {
jt->set_suspend_equivalent();
//Failed to acquire lock.
EnterI (THREAD) ;
if (!ExitSuspendEquivalent(jt)) break ;
_recursions = 0 ;
_succ = NULL ;
exit (false, Self) ;
jt->java_suspend_self();
}
Self->set_current_pending_monitor(NULL);
}
Atomic::dec_ptr(&_count);
assert (_count >= 0, "invariant") ;
Self->_Stalled = 0 ;
// Must either set _recursions = 0 or ASSERT _recursions == 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;
DTRACE_MONITOR_PROBE(contended__entered, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_entered()) {
JvmtiExport::post_monitor_contended_entered(jt, this);
}
if (event.should_commit()) {
event.set_klass(((oop)this->object())->klass());
event.set_previousOwner((TYPE_JAVALANGTHREAD)_previous_owner_tid);
event.set_address((TYPE_ADDRESS)(uintptr_t)(this->object_addr()));
event.commit();
}
if (ObjectMonitor::_sync_ContendedLockAttempts != NULL) {
ObjectMonitor::_sync_ContendedLockAttempts->inc() ;
}
}
monitor wait
void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
assert (Self->is_Java_thread(), "invariant") ;
assert (((JavaThread *) Self)->thread_state() == _thread_blocked , "invariant") ;
// Try the lock - TATAS
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
DeferredInitialize () ;
if (TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
assert (_succ != Self , "invariant") ;
assert (_owner != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
ObjectWaiter * nxt ;
for (;;) {
node._next = nxt = _cxq ;
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
}
if ((SyncFlags & 16) == 0 && nxt == NULL && _EntryList == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
TEVENT (Inflated enter - Contention) ;
int nWakeups = 0 ;
int RecheckInterval = 1 ;
for (;;) {
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
if (TryLock(Self) > 0) break ;
TEVENT (Inflated enter - Futile wakeup) ;
if (ObjectMonitor::_sync_FutileWakeups != NULL) {
ObjectMonitor::_sync_FutileWakeups->inc() ;
}
++ nWakeups ;
if ((Knob_SpinAfterFutile & 1) && TrySpin (Self) > 0) break
if ((Knob_ResetEvent & 1) && Self->_ParkEvent->fired()) {
Self->_ParkEvent->reset() ;
OrderAccess::fence() ;
}
if (_succ == Self) _succ = NULL ;
OrderAccess::fence() ;
}
assert (_owner == Self , "invariant") ;
assert (object() != NULL , "invariant") ;
UnlinkAfterAcquire (Self, &node) ;
if (_succ == Self) _succ = NULL ;
assert (_succ != Self, "invariant") ;
if (_Responsible == Self) {
_Responsible = NULL ;
OrderAccess::fence(); // Dekker pivot-point
}
if (SyncFlags & 8) {
OrderAccess::fence() ;
}
return ;
}
The specific code flow is summarized as follows:
1. The current thread is encapsulated in the node of the ObjectWaiter object, and the status is set to ObjectWaiter:TS_CXQ.
2. In the for loop, the node is pushed to the through cas_ In the cxq list, there may be multiple threads pushing their own node nodes at the same time_ cxq list.
3. push node to_ After the cxq list, try to obtain the lock by spinning. If the lock is still not obtained, suspend the current thread through park and wait to be awakened.
4. When the thread is awakened, it will continue to execute from the suspended point and try to obtain the lock through ObjectMonitor::TryLock.
monitor release
When the execution of an execution code block or method holding a lock is completed, the lock will be released, giving other threads the opportunity to execute synchronous code blocks or synchronous methods. In hotspot, the lock will be released by exiting the monitor, and the blocked thread will be notified. The specific implementation is located in the exit method of ObjectMonitor. Located at: (/ src/share/vm/runtime/objectMonitor.cpp). The source code is as follows.
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
Thread * Self = THREAD ;
if (THREAD != _owner) {
if (THREAD->is_lock_owned((address) _owner)) {
// Transmute _owner from a BasicLock pointer to a Thread address.
// We don't need to hold _mutex for this transition.
// Non-null to Non-null is safe as long as all readers can
// tolerate either flavor.
assert (_recursions == 0, "invariant") ;
_owner = THREAD ;
_recursions = 0 ;
OwnerIsThread = 1 ;
} else {
// NOTE: we need to handle unbalanced monitor enter/exit
// in native code by throwing an exception.
// TODO: Throw an IllegalMonitorStateException ?
TEVENT (Exit - Throw IMSX) ;
assert(false, "Non-balanced monitor enter/exit!");
if (false) {
THROW(vmSymbols::java_lang_IllegalMonitorStateException());
}
return;
}
}
ObjectWaiter * w = NULL ;
int QMode = Knob_QMode ;
//qmode = 2; Directly bypass the entrylist queue and obtain threads from the cxq queue to compete for locks.
if (QMode == 2 && _cxq != NULL) {
w = _cxq ;
assert (w != NULL, "invariant") ;
assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
ExitEpilog (Self, w) ;
return ;
}
//qmode = 3; Insert from cxq queue to the end of entrylist queue
if (QMode == 3 && _cxq != NULL) {
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
ObjectWaiter * Tail ;
for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next) ;
if (Tail == NULL) {
_EntryList = w ;
} else {
Tail->_next = w ;
w->_prev = Tail ;
}
}
//qmode = 3; Insert entrylist queue header from cxq queue
if (QMode == 4 && _cxq != NULL) {
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
if (_EntryList != NULL) {
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
}
//Wake up the thread.
w = _EntryList ;
if (w != NULL) {
assert (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
}
1. When you exit synchronization_ Recursions minus 1. When the value of recursions is reduced to 0, the program releases the lock.
2. According to different strategies (specified by QMode), obtain the header node from cxq or Entrylist, and wake up the encapsulated thread of the node through OjbectMonitor::ExitEpilog method. The wake-up operation is finally completed by unpark. The implementation is as follows:
void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {
assert (_owner == Self, "invariant") ;
_succ = Knob_SuccEnabled ? Wakee->_thread : NULL ;
ParkEvent * Trigger = Wakee->_event ;
Wakee = NULL ;
OrderAccess::release_store_ptr (&_owner, NULL) ;
OrderAccess::fence() ; // ST _owner vs LD in unpark()
if (SafepointSynchronize::do_call_back()) {
TEVENT (unpark before SAFEPOINT) ;
}
DTRACE_MONITOR_PROBE(contended__exit, this, object(), Self);
Trigger->unpark() ; //Wake up the thread suspended by pack before.
if (ObjectMonitor::_sync_Parks != NULL) {
ObjectMonitor::_sync_Parks->inc() ;
}
}
monitor is a heavyweight lock
Atomic: will be designed in the function call of ObjectMonitor; cmpxchg_ ptr,Atomic::inc_ PTR and other kernel functions execute synchronous code blocks. Objects that do not compete for locks will be suspended by park(), and threads that compete for locks will be awakened by unpark(). At this time, there will be operating system user and kernel state switching, which consumes a lot of system resources. All syncronized java is a heavyweight lock
What are user state and kernel state? To understand user mode and kernel mode, you also need to understand the architecture of linux system:
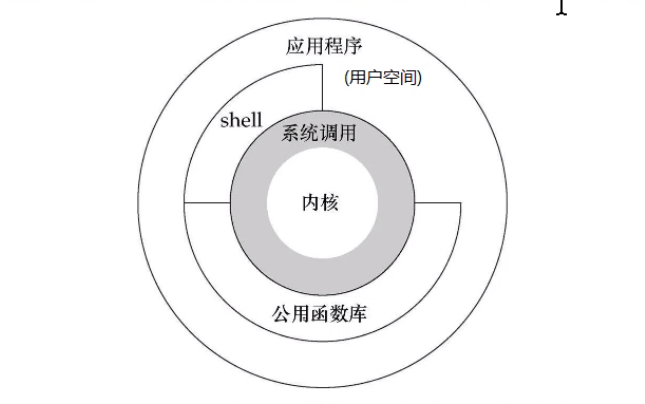
It can be seen from the architecture of linux kernel that it can be divided into user space and operating system space.
Kernel: the humble position can be understood as a kind of software, the hardware resources of the null value computer, and provides the upper application running environment.
User space: the space in which the upper application is active. The execution of application programs must rely on the resources provided by the kernel, including cpu resources, storage resources, I/O resources, etc.
System call: in order for the upper application to locate these resources, the kernel must provide the interface for the upper application: system call.
The comfort of all processes runs in the user space, which is the user running state (user state for short); However, when it calls to perform some operations, such as I/O calls, it needs to run in the kernel, and we become that the process is in the kernel running state (or kernel state for short). The process of system call can be understood as:
1 . The user order places some data values in registers or creates a stack with parameters to indicate the service provided by the operating system.
2 . User mode programs perform system calls.
3 . The CPU switches to the kernel state and jumps to the instruction located in the specified location of memory.
4 . The system call handler will read the data parameters put into the memory by the program and execute the service cleared by the program.
5 . After the system call is completed, the operating system will reset the CPU to user state and return the result of the system call.
It can be seen that many variables need to be passed when switching from user state to kernel state. At the same time, the kernel also needs to protect some register values and variables when switching from user state
Wait for the kernel state to switch back to the user state. This switching brings a lot of system resource consumption, which is the reason why the efficiency is low before synchronized is optimized.
Chapter 6: JDK6 synchronized optimization
CAS overview and role:
CAS is all about: Compare And Swap. It is a kind of special instruction for shared data in memory, which is widely used in modern CPU.
Role of CAS: CAS can convert comparison and exchange into atomic operation, which is directly guaranteed by CPU. CAS can guarantee the atomic operation when assigning shared variables. CAS operation depends on three values: the value V in memory, the old value X and the value B to be modified. If the estimated value X of the old value is equal to the value V in memory, the new value B is saved in memory.
**
* cas
* use AtomicInteger
*/
public class Cas01 {
//Define shared variable num
private static AtomicInteger num = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
// 2 perform 1000 + + operations on num
Runnable increment = () -> {
for (int i = 0;i< 1000; i++) {
num.incrementAndGet();
}
};
//Define list combination
Thread t = null;
//3 generate 5 threads
List<Thread> list = new ArrayList<>();
for (int i= 0 ;i < 5; i++) {
t = new Thread(increment);
t.start();
list.add(t);
}
//4 wait until all threads are completed before executing the main thread
for (Thread tt: list) {
tt.join();
}
System.out.println(num.get());
}
}
CAS principle
The Unsafe class provides atomic operations through AtomicInteger.
Introduction to Unsafe class
Unsafe class makes java have the ability to operate memory space like c language pointer. At the same time, it also brings the problem of pointer. Excessive use of unsafe class will increase the probability of error. Therefore, java official does not recommend it. There are few official documents. Unsafe objects cannot be called directly. Intelligence is obtained through reflection.

1. t1 thread executes the memory value 0, the old value 0 is equal -- > VAR4 + var 5, and the result is updated to memory
2. At the same time, t2 thread gets the value 1 in memory, gets the value 0 is not equal, returns false, and continues to execute the loop. 1 in memory is equal to the estimated value 1, and the result of var4 + var 5 is updated to memory.
Pessimistic lock and optimistic lock
Pessimistic lock from a pessimistic perspective:
Always assume the worst case. Every time you get the data, you think others will modify it, so you will lock it every time you get the data, so others will block it if they want to get the data. So synchronized me
They also call it pessimistic lock. ReentrantLock in JDK is also a pessimistic lock. Poor performance!
Optimistic lock from an optimistic perspective:
Always assume the best situation. Every time you go to get the data, you think others will not modify it. Even if you do, it doesn't matter. Just try again. Therefore, it will not be locked, but it will be judged during the update
Whether others have modified this data and how to update it if no one has modified it. If someone has modified it, try again.
CAS mechanism can also be called optimistic lock. Good comprehensive performance!
When CAS obtains a shared variable, volatile modification needs to be used to ensure the visibility of the variable. The combination of CAS and volatile can realize lock free concurrency, which is suitable for the scenario of less fierce competition and multi-core CPU“
1. Because synchronized is not used, the thread will not be blocked, which is one of the factors to improve efficiency.
2. However, if the competition is fierce, it can be expected that retry will occur frequently, but the efficiency will be affected.
Summary I
The role of CAS? Compare And Swap, CAS can convert comparison and exchange into atomic operation, which is directly guaranteed by the processor.
How does CAS work? CAS needs three values: memory address V, old expected value A and new value B to be modified. If the memory address / port is equal to the old expected value A, modify the memory address value to B
Lock upgrade process
Efficient concurrency is an important improvement from JDK 1.5 to JDK 1.6. The HotSpot virtual machine development team has spent a lot of energy on this version to implement various lock optimization technologies, including packet Biased Locking
It includes Lightweight Locking and adaptive spinning Lock elimination and Lock Coarsening are all used to make the threads more transparent
Efficiently share data and solve competitive problems, so as to improve the execution efficiency of the program.
No lock – "bias lock" - "lightweight lock" - "heavyweight lock (java15 discards bias lock)
Bias lock
principle
In most cases, the lock is not tight, there is no multi-threaded competition, and it is always obtained by the same thread many times. In order to make the cost of obtaining the lock lower, the biased lock is introduced.
Biased lock is biased, eccentric and partial. What he means is that the lock is biased to the first thread to obtain it, and the thread id biased by the lock will be stored for the object. Later, when changing the thread to enter and leave the synchronous code block, you only need to check whether it is biased, and the lock flag is located in and ThreadId.
Once there are other threads competing, the bias lock is revoked immediately.
Deflection lock cancellation
Once there are other threads competing for thread locks. Automatic cancellation of deflection lock
1. The revocation of the bias lock must wait for the global security point.
2. Pause the thread with biased lock and judge whether the lock object is in the locked state.
3. Undo the chip clue and return to the state of no lock or lightweight lock.
Bias lock in java1 After 6, it will start by default, but it will not be activated until a few seconds after the application starts. You can use the XX:biasedLockingStartupDelay=0 parameter to turn off the delay. If it is determined that all locks in the application are in a competitive state under normal circumstances, you can turn off the bias lock through the XX:-UseBiasedLocking=false parameter.
Benefits of bias lock
1 . The revocation of the bias lock must wait for the global security point
2 . Pause the thread with biased lock and judge whether the lock object is locked
3 . Cancel the bias lock and return to the state of no lock (flag bit 01) or lightweight lock (flag bit 00)
Bias lock is enabled by default after Java 1.6, but it is activated only a few seconds after the application starts. It can be used-
20: Bi asedlocki ngstartupdelay = 0 parameter off delay. If it is determined that all locks in the application are in a competitive state under normal circumstances, you can use XX: -UseBi
asedLocki ng=false parameter turns off the bias lock.
Lightweight Locking
What is a lightweight lock
The lightweight lock is jdk1 The new lock mechanism added in 6. The "light ink level" in its name is relative to the traditional lock using monitor. Therefore, the traditional lock mechanism is called "heavyweight" lock. First of all, it should be emphasized that lightweight locks are not used to replace ordinary heavyweight locks.
The purpose of introducing lightweight lock: when multiple threads execute ^ synchronization blocks alternately, try to avoid the performance consumption caused by heavyweight lock, but if multiple threads enter the temporary lock at the same time
Battery limit will lead to the expansion of lightweight locks and the upgrading of heavyweight locks, so the emergence of lightweight locks is not to replace the heavyweight collar.
Lightweight lock principle
When the skew lock function is turned off or multiple threads compete for the skew lock, which leads to the upgrade of the skew lock to a lightweight lock, an attempt will be made to obtain the lightweight lock. The steps are as follows: obtain the lock
1 . Judge whether the current object is in the unlocked state (hashcode, 0, 01). If so, the JVM will first create a record called Lock in the stack frame of the current thread
The space of Record) is used to store the current copy of Mark Word of the lock object (the official prefix is added to this copy, that is, Displaced Mark Word)
Copy the Mark Word of the object to the Lock Record in the stack frame, and point the owner in Lock Reocrd to the current object.
2 . The JVM uses CAS operation to try to update the Mark Word of the object to the pointer to Lock Record. If it succeeds, it indicates that the lock is contested, the lock flag bit will be changed to 00 and the synchronization operation will be performed.
Lightweight lock release
The release of hydroxyl lock is also carried out through CA moose. The main steps are as follows:
1 . Take out the data saved in the Displaced Mark Word after obtaining the light star lock.
2 . Use CAS operation to replace the extracted data in the Mark Word of the current object. If it is successful, it means that Mingcheng has successfully released the lock.
3 . If CAS operation replacement fails, it indicates that other threads are trying to obtain the lock, and the lightweight lock needs to be upgraded to a heavyweight lock.
For lightweight locks, the performance improvement is based on "for most locks, there will be no competition in the whole life cycle". If this basis is broken, there will be additional CAS operations in addition to the cost of mutual exclusion. Therefore, in the case of multi-threaded competition, lightweight locks are slower than heavyweight locks.
Lightweight lock benefits
When multiple threads execute synchronous blocks alternately, the performance consumption caused by heavyweight locks can be avoided.
Summary
What is the principle of lightweight lock?
Copy the Mark Word of the object to Lock Recod in the stack. Mark Word is updated to a pointer to Lock Record.
What are the benefits of lightweight locks?
When multithreads execute synchronization blocks alternately, the performance consumption caused by heavyweight locks can be avoided
Spin lock
When we discussed the lock implementation of monitor earlier, we know that monitor will block and wake up threads. Thread blocking and wake-up require the CPU to change from user state to core state. Frequent blocking and wake-up are a heavy burden for the CPU. These operations put a lot of pressure on the concurrency performance of the system. At the same time, the virtual machine development team also noticed that in many applications, the locking state of shared data will only last for a short period of time. It is not worth blocking and waking up threads for this period of time. If the physical machine has more than one processor, it can make two or more threads execute in parallel at the same time, We can let the thread requesting the lock "wait a minute", but do not give up the execution time of the processor to see if the thread holding the lock will release the lock soon. In order to make the thread wait, we only need to let the thread execute a busy loop (spin). This technology is called spin lock.
Spin lock at jdk1 Wine is introduced in 4.2, but it is turned off by default. You can use the - XX:+UsRSpinning parameter to turn it on. It has been turned on by default in JDK 6. Spin waiting cannot replace blocking, let alone the requirements for the number of processors. Although spin waiting itself avoids the overhead of thread switching, it takes up processor time. Therefore, if the lock is occupied for a short time, the effect of spin waiting will be usually good. On the contrary, if the lock is occupied for a long time. Then spinning threads will only consume processor resources in vain, and will not do any useful work. On the contrary, it will bring a waste of performance. Therefore, the spin waiting time must have a certain limit. If the spin exceeds the limited number of times and still fails to obtain the lock, the traditional method should be used to suspend the thread. The default value of spin times is 10 times, which can be changed by the user using the parameter - XX: PruBlockSpin
Lock elimination
Lock elimination means that the virtual machine just in time compiler (JIT) eliminates locks that require synchronization in some code, but it is detected that there is no competition for shared data. The main judgment basis of lock elimination comes from the data support of escape analysis. If it is judged that in a piece of code, all data on the heap will not escape and be accessed by other threads, they can be treated as data on the stack. It is considered that they are thread private, and synchronous locking is naturally unnecessary. Whether variables escape or not needs to be determined by data flow analysis for virtual machines, but programmers themselves should be very clear. How can they require synchronization when they know that there is no data contention? In fact, many synchronization measures are not added by programmers themselves, and the popularity of synchronized code in Java programs may exceed the imagination of most readers. The following very simple code just outputs the result of the addition of three strings. There is no synchronization either in the literal source code or in the semantics of the program.
Coarsening lock
The JVM detects that a series of small operations use the same object lock. Enlarge the scope of the synchronization code block. Put it outside this series of operations, so you only need to add a lock once.
How to optimize synchronized when writing code
1. Reduce the synchronized range.
2. Reduce the force of the synchronized lock.
hashtable locks all operations. ConcurrentHashMap locks parts. Using ConcurrentHashMap
3. Separate reading and writing.
Do not lock when reading, and lock when writing and deleting.
Concurrent HashMap copyonwritearraylist and ConyOnWriteSet are both read without lock and written without lock.