selenium python easy to get started
Hello everyone, I believe you want to automatically obtain the things you can only see by clicking the web content manually, including saving the knowledge content, collecting data, calculating the price, etc., but it is a little difficult due to the past methods. You know that the emergence of browsers such as chrome, Firefox and edge using the core of webkit, coupled with built-in automatic testing tools, Make these things easier, introduce them grandly (pretend that only I know), selenium!!! This is an automated testing tool. It can not only obtain page elements and download, but also simulate keyboard, mouse, click, drag and drop, etc
1. Installation
Suppose everyone uses chrome
First, we need to determine the version of chrome
emmm opens the browser. I think it's too low-end. The code is:
import subprocess cmd="(Get-Item (Get-ItemProperty 'HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\App Paths\chrome.exe').'(Default)').VersionInfo|select FileVersion" completed = subprocess.run(["powershell", "-Command", cmd], capture_output=True) print(completed.stdout.decode().strip().splitlines()[2])
This is to run a powershell statement on python to get a chrome statement
stdout is of type bytes, so I need decode()
strip() pulls out some spaces, but it doesn't
splitlines() breaks it up into multiple lines of text
[2] Third line
Well, I thought everyone didn't understand, so I watered
Then, to install chrome driver, selenium needs to specify the driver corresponding to different browsers before it can be used
Go here to download the chrome driver corresponding to the chrome version. If you use the development version (Canary), you need to download the chrome driver of the Canary version. As for Firefox, edge and phantom JS, the usage is the same, so I won't say more
https://chromedriver.chromium.org/
If you learn selenium, you can even go to this website and climb down directly according to the version. Well, that's what I do
Before python runs selenium and opens chromedriver, it is necessary to add parameters. First, start the first instance of selenium
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
import re
class hello:
def __init__(self,url,selepath='c:\\1\\selenium\\chromedriver\\98\\chromedriver.exe'):
self.url=url
self.seleniumpath=selepath
ser = Service(self.seleniumpath)
"""
This is a new version selenium Specified syntax,It used to be Options
You can add it yourself here header Equal statement,Examples will be found later to explain
"""
self.driver=webdriver.Chrome(service = ser)
"""
Headless mode --headless,Is running in the background,You won't see anything chrome open,The test won't open
Contains multiple parameters
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
#chrome_options.add_argument("--disable-extensions")
#chrome_options.add_argument("--disable-gpu")
#chrome_options.add_argument("--no-sandbox") # linux only
chrome_options.add_argument("--headless")
# chrome_options.headless = True # also works
driver = webdriver.Chrome(service = ser,options=chrome_options)
"""
self.driver.maximize_window()
#self.driver.
#window maximizing
self.driver.get(self.url)
#Open web page
def closedriver(self):
self.driver.close()
x=hello('https://www.baidu.com')
x.closedriver()
Pay attention to your saved chromedriver path
Note that the open website must start with https: / / or http: / /
Finally, close the driver, or you will have a chance to leave the driver in the process. Don't be afraid. It's very quiet. It doesn't move and won't come out to bite your ass
You can open the old version as many times as you don't turn it off. Now there are only one or two big chances
How to get web page elements
If you have learned dom or other crawlers, you know how to capture web page elements, including class name, id name, include name, xpath path, ccs selector, tag, etc. the most commonly used ones are listed. In fact, there are others that will not be discussed in detail here
How do you find the names of these elements
After you open the browser, you will see the key code of the browser by pressing f12 + tools or Ctrl + shift
Just practice with Baidu Encyclopedia
Open devtools and click
 This button
This button
Then point to the page element you want to get
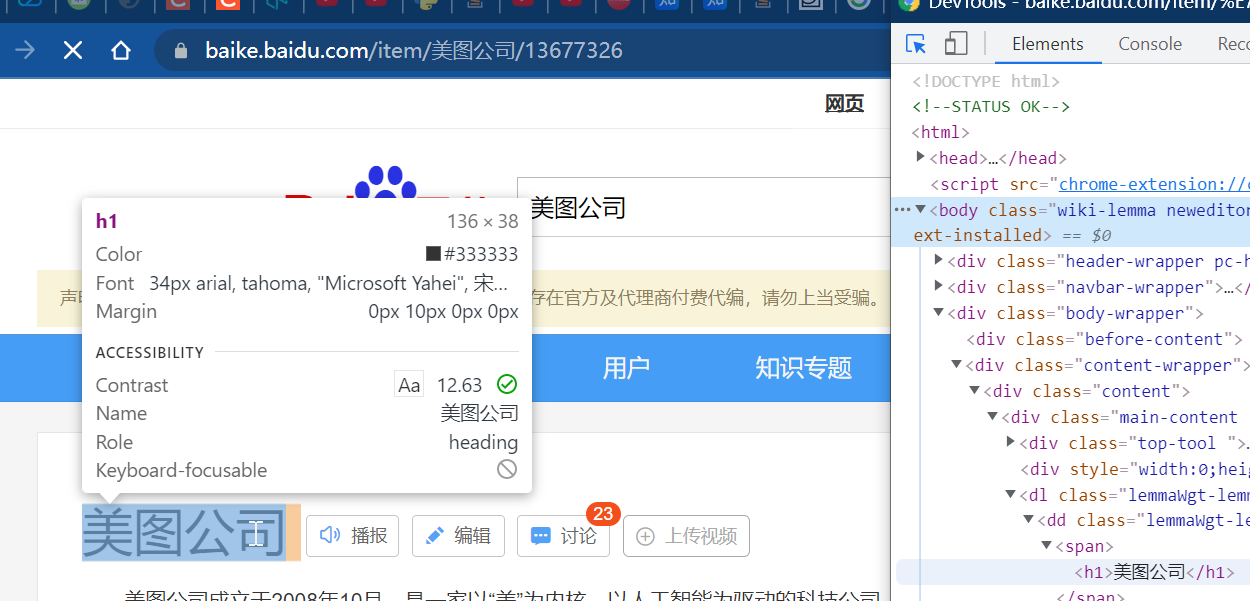
It's easy to know the location of this element
Right click > copy
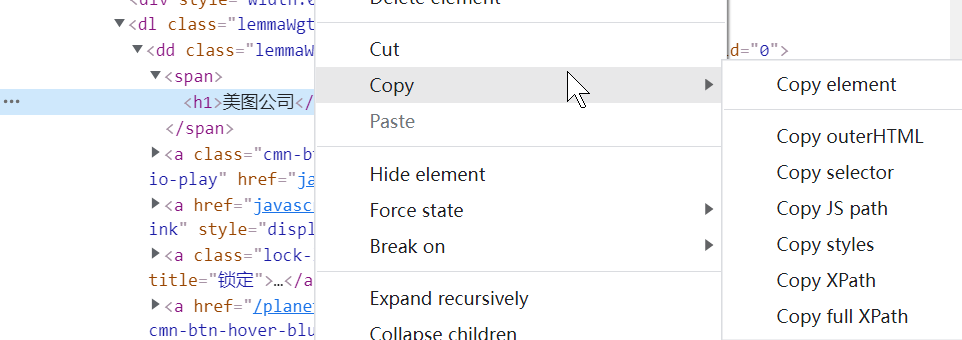
It is necessary to explain:
copy element: the current web page code segment, including nested ones, will be copied at one time
copy outerHtml: almost the same as above. I don't know the difference
Copy jspath
copy styles: css style
copy xpath: xpath path. It will try to use @ classname @id as the path. It is also findbyelement (by.xpath) (demonstration later)
copy full xpath: absolute xpath path
xpath is the fastest and most accurate, but the path is also the longest. If it's troublesome, you can get the classname id separately. The method is to select the element and then see the following properties
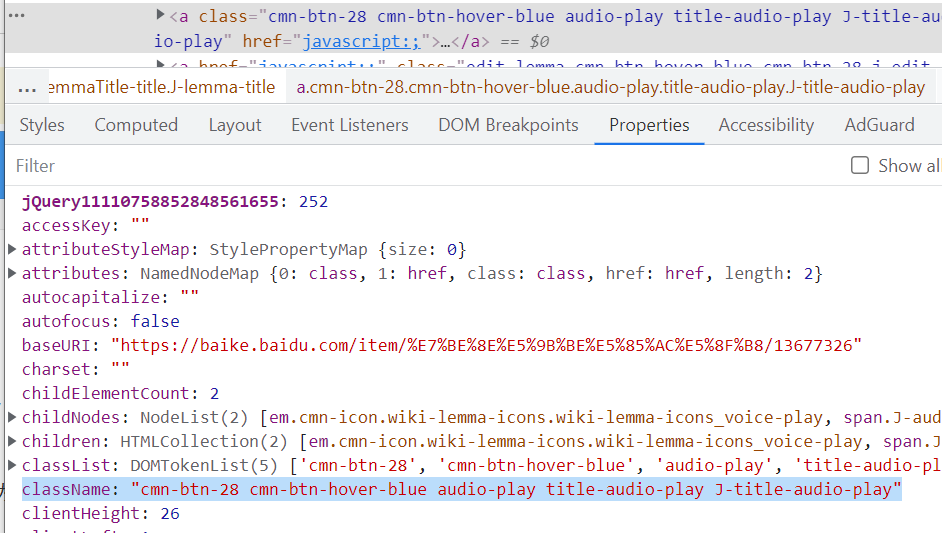
Well, after copying the path, you can get the element content. Please see the following code:
x=self.driver.find_element(By.CSS_SELECTOR,"body") y=self.driver.find_element(By.XPATH,"/html/body/div[3]/div[2]/div/div[1]/dl[1]/dd/a[1]") #xpath absolute path z=self.driver.find_element(By.class_namee,"cmn-btn-28.cmn-btn-hover-blue.audio-play.title-audio-play.J-title-audio-play")#classname does not allow spaces. Spaces are used replace
The above is a simple version. It's not very safe. I'll add it later
Then capture the elements and get the contents
z.get_attribute('textContent')
#Get text content
z.get_attribute('innerHTML')
#Get the whole piece of code under the element
z.get_attribute('href')
#Get web address
z.get_attribute('src')
#Loaded file contents, such as pictures, js, files, etc
Then there is the simulated mouse and keyboard action
First of all, for a single operation
z.click()
z.send_key("abcd")
z.send_key(Keys.PAGE_DOWN)
Especially PAGE_DOWN is used to turn the page. Because it simulates the rendering effect, it is necessary to turn the page
Multiple action chains:
source_element = self.driver.find_element(By.link_text,"Courses") target_element = self.driver.find_element(By.link_text,"Hard") action = ActionChains(self.driver) #action.move_to_element(By.class_name,"xxx") #action.sendkeys #action.click() action.drag_and_drop(source_element, target_element) action.perform()
It is to put multiple actions into action and then perform() releases them
Due to the problem of amplitude variation and delayed execution, switch the tab. Iframe will talk about it next time