preface
In the front, I made a small program of automatic clock in, which can basically realize the tasks of checking in and checking out after work, and white whored CSDN server as the basis of data sending and receiving. While continuing to optimize functions, small pits in the use of selenium are solved.
- Locate and switch frame (iframe)
- webdriver crawler #document problem
1, Python+Selenium
Refer to the previous article for specific environment configuration.
2, The #document problem in webdriver
As shown in the figure, we want to get #document below the body.
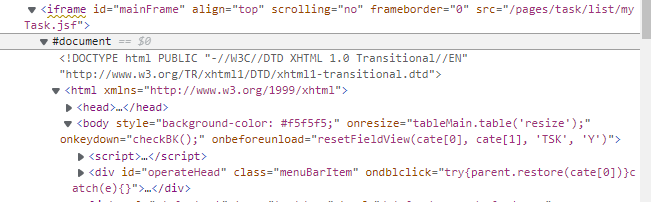
If you locate directly through the obtained xpath
driver = webdriver.Firefox() driver.get(url) driver.find_element_by_xpath() print(driver .page_source)
You will find that the content under #document is empty. In other words, the corresponding element is not located at all, and the content under #document is not crawled. It is observed that the upper level of #docoment is the iframe tag, which is equivalent to embedding a piece of HTML into the original code. According to the experience of newly opening the tag page before: when the driver reopens a tag page, it needs to switch to the sub tag page through the following code.
current_windows = browser.window_handles # browser.switch_to_window(current_windows[1]) self.__driver.switch_to.window(current_windows[0]) self.__driver.maximize_window()
Therefore, it is the same for iframe. You need to switch to iframe to locate the corresponding element and complete crawling. When many people use selenium to locate page elements, the Xpath elements obtained through the browser cannot be located. This situation is likely to be caused by the frame.
2.1 method of switching frame
-
selenium provides switch_ to. The frame () method to switch the frame
switch_to.frame(reference) switch_to_frame(reference)
Referring to switch_ to_ The method of frame () has been out, and may not be supported later. The recommended writing method is switch_to.frame(), try it a few more times at that time, and one is always OK. reference is the passed in parameter, which is used to locate the frame. You can pass in the WebElement object of id, name, index and selenium. For example:
from selenium import webdriver driver = webdriver.Firefox() driver.switch_to.frame(0) # 1. Use the index of the frame to locate. The first one is 0 driver.switch_to.frame("frame1") # 2. Use id to locate driver.switch_to.frame("myframe") # 3. Use name to locate driver.switch_to.frame(driver.find_element_by_tag_name("iframe")) # 4. Use WebElement object to locate -
Cut back the main document from the frame (switch_to.default_content())
After switching to the frame, we cannot continue to operate the elements of the main document. At this time, if we want to operate the contents of the main document, we need to switch back to the main document.driver.switch_to.default_content()
-
For the operation of nested frames (switch_to.parent_frame()), sometimes we encounter nested frames, as follows:
<html> <iframe id="frame1"> <iframe id="frame2" / > </iframe> </html>Cut from the main document to frame2 and cut in layer by layer:
driver.switch_to.frame("frame1") driver.switch_to.frame("frame2") -
So as long as you make good use of the following three methods, you can solve it in minutes when you encounter the frame:
driver.switch_to.frame(reference) driver.switch_to.parent_frame() driver.switch_to.default_content()
2.2 switching #document method
With the foundation of just switching iframe, you can get the content in iframe. At this time, if you use xpath to locate the content in document, the result is still failure. The following methods have been found on the Internet, which are actually useful: use after get(url)
driver.switch_to_default_content()
frame = driver.find_elements_by_tag_name('iframe')[0]
driver.switch_to_frame(frame)
Jump to iframe first, then driver find_ element_ by_ XPath is OK. I don't know why this jump method is OK.
2.3 switching #document sub #document methods of #document
This time #document is nested in #document. No matter how many levels, the switching method is similar to the nesting of iframe, switching layer by layer
# Switch to child#document
frame1 = browser3.find_elements_by_tag_name('iframe')[0]
browser3.switch_to_frame(frame1)
# Switch to grandson#document
frame2 = browser3.find_elements_by_tag_name('iframe')[0]
browser3.switch_to_frame(frame2)
#print(browser1.page_source)
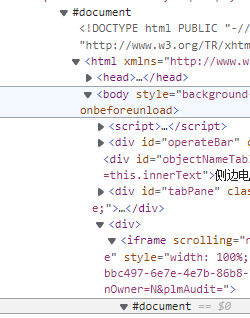
The overall process is as follows: because #document is embedded in iframe, the multi-layer nested code is as follows:
# Switch to mainFrame this iframe Medium#document==0
browser3.switch_to_default_content()
frame = browser3.find_elements_by_tag_name('iframe')[0]
browser3.switch_to_frame(frame)
# Switch to child#document
frame1 = browser3.find_elements_by_tag_name('iframe')[0]
browser3.switch_to_frame(frame1)
# Switch to grandson#document
frame2 = browser3.find_elements_by_tag_name('iframe')[0]
browser3.switch_to_frame(frame2)
# Click OK, and the OK button is in the upper iframe
browser3.switch_to.parent_frame()
# Click OK to return to the first level
browser3.switch_to.default_content()