SequoiaDB, as a storage engine, supports high concurrency HTAP scenarios. The standard summarizes the high availability deployment practice of using SequoiaDB as data storage in the operation and maintenance analysis project, and accesses Kafka for high concurrency update business and Spark for high concurrency batch query business.
SequoiaDB high availability cluster deployment of database Series (I)
SequoiaDB high availability cluster deployment of database Series (2)
2.5 MySQL engine deployment
2.5.1 installing MySQL instance
- The extracted sequoiasql-mysql-3.4-linux_ x86_ 64-installer. The run installation package grants executable permissions
chmod u+x sequoiasql-mysql-3.4-linux_x86_64-installer.run
- Run sequoiasql-mysql-3.4-linux with root_ x86_ 64-enterprise-installer. Run package
./sequoiasql-mysql-3.4-linux_x86_64-installer.run --mode text
- The program prompts you to select the wizard language, enter 2, and select Chinese
Language Selection Please select the installation language [1] English - English [2] Simplified Chinese - Simplified Chinese Please choose an option [1] : 2
- Display the installation agreement. Enter 1 to ignore reading and agree to the agreement, and enter 2 to read the complete agreement
from BitRock InstallBuilder Evaluate the establishment of the Institute Welcome to SequoiaSQL MySQL Server erection sequence ---------------------------------------------------------------------------- GNU General public authorization Second Edition, 1991 June Copyright ownership (C) 1989,1991 Free Software Foundation, Inc. 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA. Everyone is allowed to copy and distribute a complete copy of this authorization document, but no modification is allowed. [1] Agree to the above agreement: To learn more about the protocol, you can view the protocol file after installation [2] View detailed agreement content Please select an option [1] : 1
- Enter the installation path and press enter. Use / usr/local/sequoiasql/mysql
Please specify SequoiaSQL MySQL Server The directory to which it will be installed Installation directory [/usr/local/sequoiadb]: /usr/local/sequoiasql/mysql
- Prompt for user name, user group and user password (sdbadmin user and sdbadmin_group user group are created by default, and the default password is sdbadmin)
Database management user configuration Configure for startup SequoiaSQL-MySql User name, user group, and password for user name [sdbadmin]: User group [sdbadmin_group]: password [********] : Confirm password [********] :
- The system prompts you to start the installation, and you need to confirm
The settings are now ready to SequoiaSQL MySQL Server Install to your computer. Are you sure you want to continue? [Y/n]: y
- installation is complete
Installing SequoiaSQL MySQL Server In your computer, please wait. Installation in progress 0% ______________ 50% ______________ 100% ######################################### ---------------------------------------------------------------------------- Setup has completed the installation SequoiaSQL MySQL Server In your computer.
2.5.2 deploying MySQL instance components
- Switch users and directories
[root@tango-centos03 sequoiadb-3.4]# su - sdbadmin [sdbadmin@tango-centos01 ~]$ cd /usr/local/sequoiasql/mysql
- Add instance
bin/sdb_sql_ctl addinst myinst -D database/3306/
If the 3306 port is occupied, you can use the - p parameter to specify the instance port
bin/sdb_sql_ctl addinst myinst -D database/3316/ -p 3316
As shown in the following operation results
[sdbadmin@tango-centos03 mysql]$ bin/sdb_sql_ctl addinst myinst -D database/3306/ (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) Adding instance myinst ... Start instance myinst ... (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) ok
- View instance
[sdbadmin@tango-centos03 mysql]$ bin/sdb_sql_ctl listinst NAME SQLDATA SQLLOG myinst /usr/local/sequoiasql/mysql/database/3306/ /usr/local/sequoiasql/mysql/myinst.log Total: 1
- Start instance
[sdbadmin@tango-centos01 mysql]$ bin/sdb_sql_ctl start myinst Check port is available ... (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) Starting instance myinst ... ok (PID: 7785) [sdbadmin@tango-centos03 mysql]$ bin/sdb_sql_ctl status INSTANCE PID SVCNAME SQLDATA SQLLOG myinst 7785 3306 /usr/local/sequoiasql/mysql/database/3306/ /usr/local/sequoiasql/mysql/myinst.log Total: 1; Run: 1
- Stop instance
[sdbadmin@tango-centos03 mysql]$ bin/sdb_sql_ctl stop myinst Stoping instance myinst (PID: 7785) ...
2.5.3 using MySQL
- Configure SequoiaDB connection address. The default SequoiaDB connection address is "localhost:11810". If you need to modify it, you can refer to the following two methods:
- Via bin/sdb_sql_ctl specify instance name modification
#sdb_sql_ctl chconf myinst --sdb-conn-addr=192.168.112.102:11810,xxxx:11810 [sdbadmin@tango-centos01 ~]$ sdb_sql_ctl chconf myinst --sdb-conn-addr=192.168.112.102:11810 Changing configure of instance myinst ... Enter password: ok
- Modify through the configuration file: modify auto. In the database directory CNF, add the parameter sequoiadb_conn_addr
[sdbadmin@tango-centos03 3306]$ cd /usr/local/sequoiasql/mysql/database/3306 [sdbadmin@tango-centos03 3306]$ vi auto.cnf # SequoiaDB addresses. sequoiadb_conn_addr="192.168.112.102:11810"
It takes effect after restarting MySQL service
- Log in to MySQL
[sdbadmin@tango-centos01 ~]$ mysql -h 127.0.0.1 -P 3306 -u root Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.25 Source distribution Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
- Creating database s and tables
mysql> create database cs; mysql> create table cl(a int,b int,c text,primary key(a,b));
2.6 SDB cluster operation
2.6.1 start and stop of SDB cluster
1) Start the entire cluster
#Switch to sdbadmin user sdbstart –t all
2) Shut down the entire cluster
#Switch to sdbadmin user sdbstop –t all
3) View SDB cluster information
[sdbadmin@tango-centos01 ~]$ sdblist sequoiadb(11800) (4953) C sequoiadb(11820) (5889) D Total: 2 #sdblist -t all –l –m local
4) Manually start SDB specific nodes
#Switch to sdbadmin user: su – sdbadmin #Connect to coordination node $ /opt/sequoiadb/bin/sdb > var db = new Sdb( "localhost", 11810 ) #Get partition group > dataRG = db.getRG( "<datagroup1>" ) #Get data node > dataNode = dataRG.getNode( "<hostname1>", "<servicename1>" ) #Start node > dataNode.start()
5) Manually stop the SDB cluster
#Connect to coordination node $ /opt/sequoiadb/bin/sdb > var db = new Sdb( "localhost", 11810 ) #Get partition group > dataRG = db.getRG( "<datagroup1>" ) #Get data node > dataNode = dataRG.getNode( "<hostname1>", "<servicename1>" ) #Stop node > dataNode.stop()
2.6.2 SDB collection operation
1) Enter the SDB cluster and create the logical domain CS_ DOMAIN_ one
[sdbadmin@tango-centos02 bin]$ sdb
> var db = new Sdb("localhost",11810);
> db.createDomain("CS_DOMAIN_1",["datagroup1",],{AutoSplit:true});
CS_DOMAIN_1
Takes 0.006933s.
2) Create assembly space CS01
> db.createCS("CS01",{Domain:"CS_DOMAIN_1"});
localhost:11810. CS01
3) Create data field
>db.createDomain("CS_DOMAIN_1",["datagroup1"],{AutoSplit:true});
4) Create master table
db.getCS(mainCSName).createCL("CL01",{"ShardingKey":{"DATE":1,"TIME":1},"ShardingType":"range","IsMainCL":true});
5) Create daily sub table
db.createCS("CS_D1", {"Domain":domainName}).createCL("CL01",{"ShardingKey":{"DATE":1,"TIME":1,"ID":1},"ShardingType":"hash","Compressed":true,"CompressionType":"lzw","EnsureShardingIndex": false, "AutoSplit": true, ReplSize:2});
6) Mount the sub table on the main table
db.getCS(mainCSName).getCL("CL01").attachCL("CS_D1.CL01",{"LowBound":{"DATE":"2021-12-26","TIME":"00:00:00"},"UpBound":{"DATE":"2021-12-26","TIME":"09:59:59"}});
7) Unload child tables from the main table
db.getCS(mainCSName).getCL("CL01").detachCL("CS_D1.CL01")
8) Create primary key index
db. CS01.CL01.createIndex("CL01_PriIdx",{"DATE":1,"TIME":1},true);
9) Collection space and collection query
#View collection space
db.listCollectionSpacespaces();
#View which collections are in the collection space
db.snapshot( SDB_SNAP_COLLECTIONSPACES,{"Name":"CS_D1"},{"Collection":{}})
#View sub table information
db.snapshot(SDB_SNAP_CATALOG,{"CataInfo.SubCLName":"CS_D1.CL01"})
#View which sub tables exist in a collection space
db.snapshot(SDB_SNAP_CATALOG,{"CataInfo.SubCLName":{"$regex":"^CS_D1 [.].*"}})
#Get space usage information of collection space
db.snapshot(5,{Name:"CS_D1"},{Name:"",PageSize:"",TotalSize:"",FreeSize:"",TotalDataSize:"",FreeDataSize:"",TotalIndexSize:"",FreeIndexSize:""})
3. Kafka data warehousing SDB
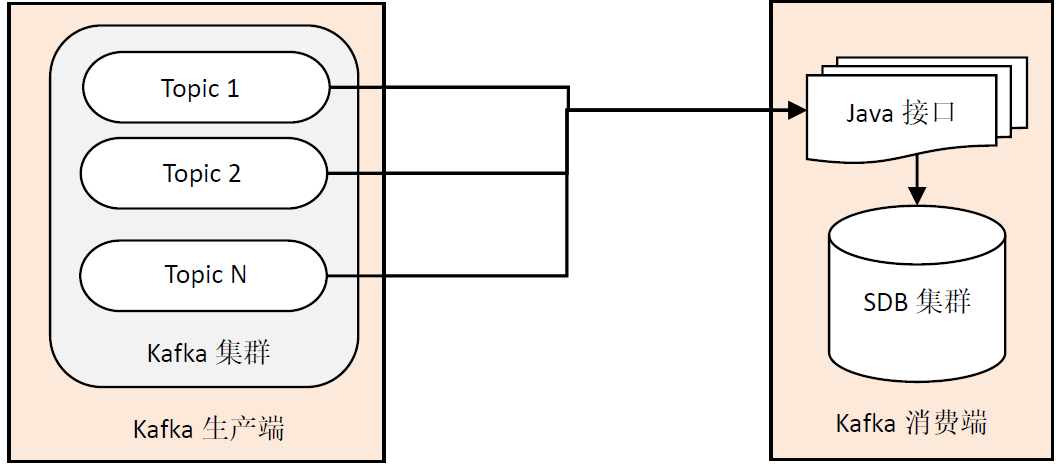
3.1 connection architecture between Kafka and SDB
On the consumer side of Kafka, the SDB database cluster stores the data subscribed by Kafka into the database through the java interface, and each Topic will be associated with a collection.
3.2 SDB configuration
Kafka theme, SequoiaDB set and message partition configuration files are as follows:
config.json
[{
topicName:'SYSLOG',
sdbCLName:'SYSLOG ',
partitionNum:4,
topicGroupName:'SYSLOG-consumer-group',
pollTimeout:5000
}]
The business logic of consumers is to consume messages in the way of one thread and one topic. Multiple topic and collection sets can be specified in Kafka configuration. In the actual joint commissioning test, there will be scenarios where multiple Topics run in parallel.
3.3 realization of Kafka and SDB docking function
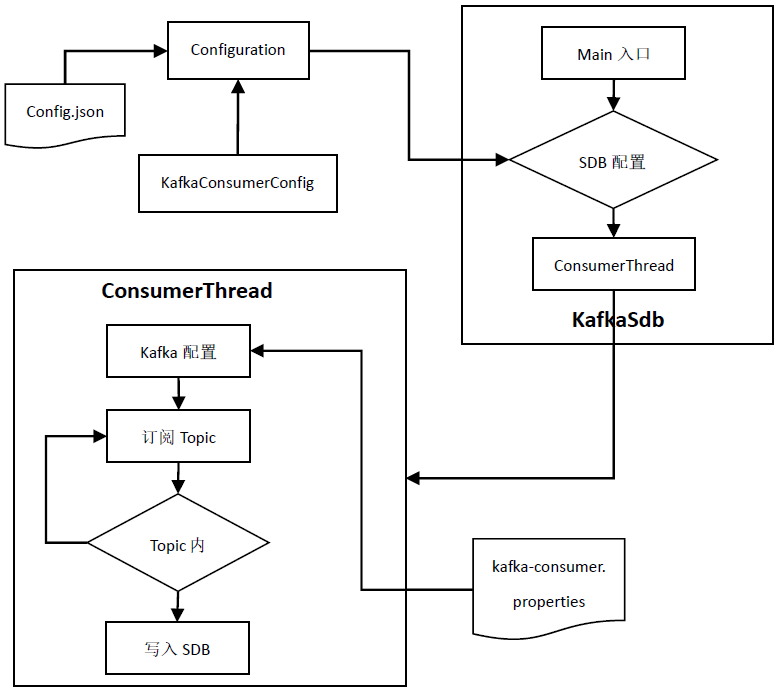
The Kafka data is written to the SDB functional component, as shown in the following figure:
- Configuration information java entity class KafkaConsumerConfig
- Configuration information acquisition tool class configuration
- KafkaSdb, the main program entry of consumer business logic, consumes messages in the way of one thread and one topic
- The ConsumerThread thread class is responsible for the consumption of specific messages and writes the message data to SequoiaDB
4. Spark SDB docking configuration
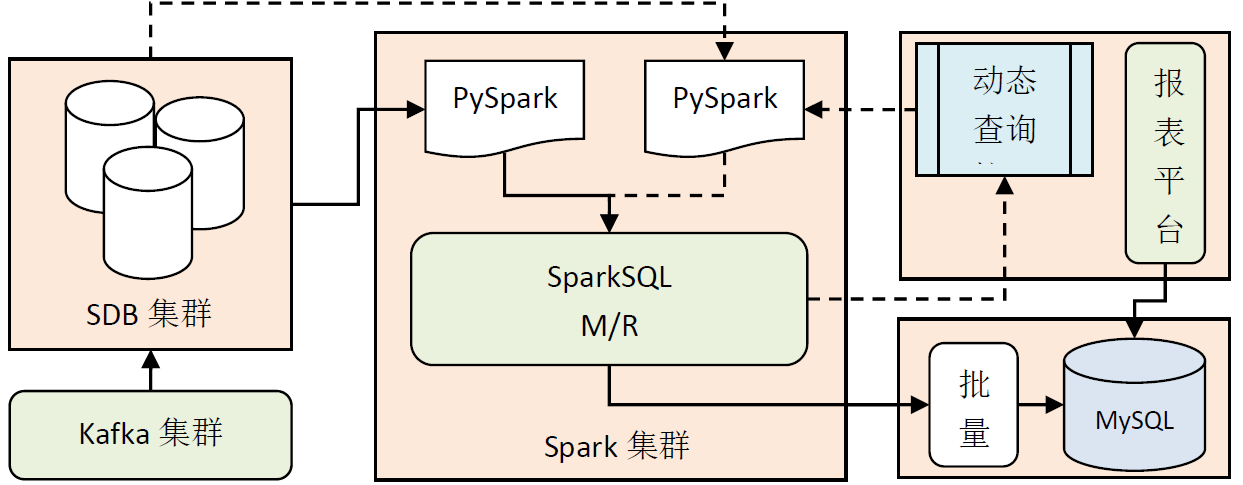
4.1 connection architecture between spark and SDB
After the performance data is saved to the SDB cluster through the Kafka cluster, the Spark computing cluster will access the data according to the following scenarios:
- The performance data is processed and calculated by scheduled batch tasks, and the results are saved in MySQL structured database, which is connected with the report platform
- For the dynamic SQL query task on the UI side, parse the SQL and access the SDB cluster data through PySpark, and return the result set to the query interface after processing and calculation
4.2 Spark and SDB docking test
- Spark interfaces with SDB and uses the driver spark sequoiadb_ 2.11-3.4. jar
- Create mapping table
mappingSql = \
"CREATE temporary view SYSLOG" +\
"USING com.sequoiadb.spark " +\
"OPTIONS( " +\
"host '192.168.112.102:11810', " +\
"collectionspace 'CS01', " +\
"collection ' SYSLOG', " +\
"preferredinstance 'S', " +\
"partitionblocknum 16, " +\
"partitionmode 'auto', " +\
"partitionmaxnum 100000, " +\
"user 'sdbadmin'," +\
"passwordtype 'file'," +\
"password '/usr/local/spark/sdbpasswd/passwd'" +\
")";
- Query using SparkSQL
#Query SDB
queryTable = "SELECT * FROM SYSLOG limit 20";
query_sdb = ctx.sql(queryTable)
- Run Spark Program
spark-submit --master yarn --deploy-mode client --jars jars/spark-sequoiadb_2.11-3.4.jar spark2sdb-01.py
The above is the high availability deployment practice of SequoiaDB database, and SequoiaDB is used as data storage to realize Kafka data consumption and Spark access query and analysis functions. In the actual project operation, the concurrent write operation of more than 100 million data per hour and the query business of 2000w single batch job are realized through multi-dimensional partition sub tables.
reference material:
Please indicate the original address for Reprint: https://blog.csdn.net/solihawk/article/details/122594023
The article will be synchronized in the official account of "shepherd's direction". Interested parties can official account. Thank you!
