Introduction: server springboot + netty socket IO, client socket io. JS + java socket io-client
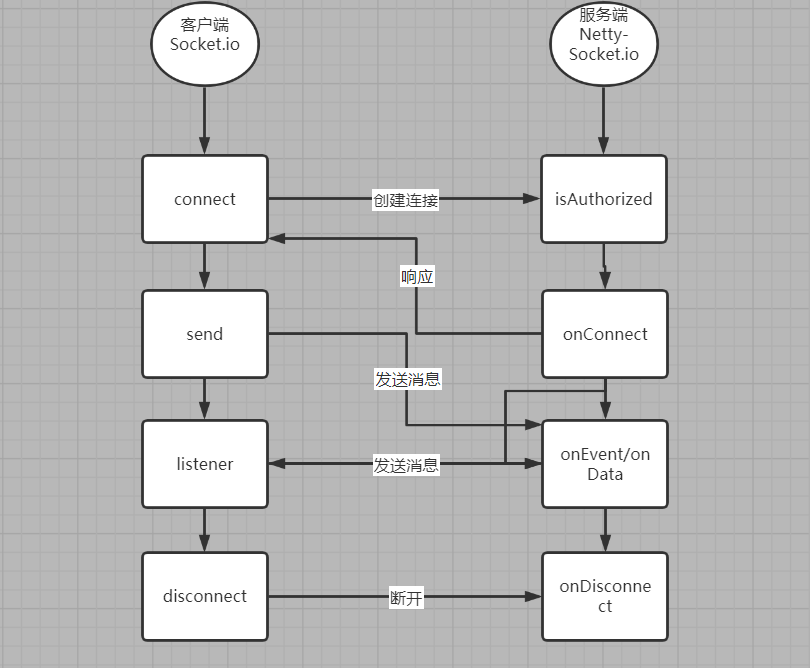
Based on socket io:
- Server use netty-socketio
- Client use socket.io-client-java
Scenario Description: by integrating the XXL job distributed scheduling platform, set the cron time expression, turn on the job task polling mode, and regularly schedule the RestFul # API to complete the relevant business logic. Here is only one example, such as message push.
Of course, if it's a stand-alone machine, it doesn't need to be distributed. It depends on the specific scenario. The timing task can be implemented in combination with springboot to meet the timing and fixed-point push:
/**
* @Author: X.D.Yang
* @Date: 2017/7/15 14:35
* @Description:
*/
@SpringBootApplication
@EnableScheduling
public class Application {
public static void main(String[] args) {
//System.setProperty("es.set.netty.runtime.available.processors", "false");
SpringApplication.run(Application.class, args);
}
}/**
* @Author: X.D.Yang
* @Date: 2017/7/15 15:10
* @Description:
*/
@Component
public class QuartzService {
private static final Logger logger = LoggerFactory.getLogger(QuartzService.class);
//Every night at twelve o'clock
@Scheduled(cron = "0 0 0 * * ?")
public void reportFailure() {
//Related business logic - todo
logger.info("now time: {}", DateUtils.dateToStr(new Date()));
}Thought provoking: although it can realize regular and fixed-point push, it obviously needs to be improved in some scenes with high real-time requirements. Here also mark some scenes of processing the message center before the small series >
Synchronization: RestFul API > call message center interface push > high real-time, simple business logic and easy maintenance.
Asynchronous: xxljob + MQ > notification message center push > program writing performance is high, which can reduce the strong coupling of services to a certain extent, but there may be a delay problem - the frequency of polling and consumption cannot be guaranteed to be exactly the same - MQ consumption may be caused by the network or other reasons, and the data written by users may not be visible immediately. Of course, asynchrony can also be handled through multiple threads, depending on the specific scenario. Excessive thread scheduling and context switching consume a lot of CPU resources.
For example, there is A scenario where system A receives A request and needs to operate the database in its own system. It also needs to operate the database in BC # two systems. It takes 100ms for A to write the database and 350ms and 450ms for BC to write the database respectively. The total delay of the final request is 100 + 350 + 450 = 900ms, which is close to 1s. Especially in the products of To C, users are most concerned about the experience, and there are some network delays. Users will only think that your system is too lj and slow. Generally speaking, each request is completed within 200ms, which is almost imperceptible to users, In fact, it feels like we click A button and return directly after A few Ms. WOW! The first feeling is that this website is doing well. Thief, come on!
Peak shaving and valley filling: we all know that MySQL can carry almost 2k requests per second. When the number of concurrent requests per second suddenly increases to 4k +. However, if the system is directly based on MySQL and there is no redis cache, A large number of requests will flow into MySQL (Note: of course, even with redis cache, there will be cache penetration avalanche, there is no unified solution to all scenarios, but it is more inappropriate for business scenarios - like an "upgrade and blame" process), MySQL may be directly killed, This leads to service unavailability, which is unacceptable in the DT-AI era of high concurrency, high availability and high performance. However, once the peak period is over, it becomes A low peak period. The number of requests per second may be dozens of requests, which has little pressure on the whole system. Therefore, MQ is used. 4k requests per second are written to MQ. System A can process up to 2k requests per second, while system A pulls 2k requests per second from MQ, which should not exceed the maximum number of requests it can process per second, In this way, even in peak hours, system A will never hang up and become unavailable.
It should be considered that every second 4k requests come in and 2k requests go out. As A result, hundreds of thousands or even millions of requests may be overstocked in MQ during the peak period. Of course, this short peak backlog is ok. After the peak period, dozens of requests enter MQ every second, However, system A will still process 2k requests per second. As soon as the peak period is over, system A will quickly solve the backlog of messages. In general, the upstream speed limit is issued and the downstream speed limit is implemented. Here is also A description for mq-kafka producers and consumers:
kafka:
consumer:
auto:
commit:
interval: 100
offset:
#This attribute specifies what the consumer should do when reading a partition without an offset or if the offset is invalid:
#Latest (default) if the offset is invalid, the consumer will read the data from the latest record (the record generated after the consumer starts)
#Earlist: in case of invalid offset, the consumer will read the record of the partition from the starting position
reset: latest
#Concurrent number
concurrency: 3
#Message signing mechanism: manual signing
enable:
auto:
commit: false
#Maximum pull number
max:
poll:
records: 100
#Consumer group
group:
id: consumer-group
servers: ip:9092
session:
timeout: 6000
zookeeper:
connect: ip:2181
producer:
batch:
size: 65536
buffer:
memory: 52428800
max:
request:
size: 31457280
servers: ip:9092i. Producer > acks = 0: the producer will not wait for any response from the server before successfully writing the message; acks=1: as long as the leader node of the cluster receives the message, the producer receives a successful response from the server; When acks=-1, the partition leader must wait for the message to be successfully written to all ISR copies (synchronous copies) before considering that the producer request is successful, providing the highest message persistence guarantee. Theoretically, the throughput is the worst. The producer can also set batch size 65536;
ii. Consumer > batch consumption @ KafkaListener support, set batchListener to true:
@Bean
public KafkaListenerContainerFactory<?> batchFactory(ConsumerFactory consumerFactory){
ConcurrentKafkaListenerContainerFactory<Integer,String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.setConcurrency(10);
factory.getContainerProperties().setPollTimeout(1400);
//Set as batch consumption, and the quantity of each batch is set in Kafka configuration parameters
factory.setBatchListener(true);
//Set manual submission
ackModefactory.getContainerProperties().setAckMode(
ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}Where containerFactory = "batchFactory" is specified as batch consumption,
//Batch consumption
@KafkaListener(topics = {"yxd179"},containerFactory="batchFactory")
public void consumerBatch(List<ConsumerRecord<?, ?>> records, Acknowledgment ack){
log.info("Number of messages received:{}",record.size());
//Manual submission - submit the offset > message for repeated consumption after successful processing by the business logic
ack.acknowledge();
}Of course, mass consumption can also be combined with springboot shielding kafka automatic configuration to introduce our customized configuration:
@SpringBootApplication(scanBasePackages ={"com.yxd"},exclude = {KafkaAutoConfiguration.class})Among them, the new Kafka configuration items are not described in detail. Of course, there are multi-threaded concurrent consumption scenarios - the order of original partition messages cannot be guaranteed, and the simulated large amount of data batch processing Test is accessed:
@Test
public void testSendKafka() throws InterruptedException {
int clientTotal = 10000;
int threadTotal = 200;
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
String log = "TEST TEST TEST TEST TEST TEST TEST TEST";
kafkaTemplate.send("dhclick", log);
semaphore.release();
} catch (Exception e) {
log.error("e >>> ", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
}
Ok,Now:
Let's go back to instant messaging - chat: use long connection to realize instant messaging - online real-time chat >