Automatic text abstraction and keyword extraction belong to the category of natural language processing.One advantage of extracting a summary is that the reader can tell with minimal information whether the article is meaningful or valuable to him or her and whether he or she needs to read it in more detail. The advantage of extracting a keyword is that it can associate the article with the article and allow the reader to quickly locate the content of the article related to the keyword.
Text summary and keyword extraction can be combined with traditional CMS, through the transformation of publishing functions such as articles/news, synchronously extract keywords and summaries, and put into HTML pages as Description s and Keyworks.To some extent, this is conducive to search engine inclusion and belongs to the scope of SEO optimization.
Keyword Extraction
There are many ways to extract keywords, but tf-idf should be the most common one.
jieba-based tf-idf keyword extraction method:
jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=('n', 'vn', 'v'))
Text Summary
There are also many ways to summarize text, if divided broadly, including extractive and generative.The extractive method is to find the key sentences and assemble them to form a summary through TextRank and other algorithms in the article. This method is relatively simple, but it is difficult to extract the true semantics and so on. The other method is to extract and regenerate the text semantics through the methods of deep learning.
If understood simply, the extractive method produces a summary in which all sentences come from the original text, while the generative method produces them independently.
To simplify the difficulty, this paper will use extractive to achieve text summary function, through SnowNLP third-party library, to achieve text summary function based on TextRank.We abstract the contents of 20,000 miles under the sea as the original text:
Original:
When these events happened, I had just returned from a science exam in a barren area of Nebraska.I was an associate professor at the Museum of Natural History in Paris and was sent by the French Government to participate in this expedition.I spent half a year in Nebraska, collected a lot of valuable data, returned home, and arrived in New York at the end of March.I decided to leave for France in early May.So I grabbed hold of the ship's stay and sorted out the mineral and animal and plant specimens that I had collected, when the Scores crashed.
I knew the street conversations at that time very well. Besides, how can I ignore them and be indifferent?I read and reread various newspapers and magazines in the United States and Europe, but I couldn't get to the bottom of the truth.Mystery is beyond solution.I thought left and right, swinging between the two extremes, and never forming an idea.There must be a hall in it, which is beyond doubt. If anyone doubts, ask them to feel the Scosch wound.
When I arrived in New York, the problem was stirring up.Some inexperienced people have come up with ideas, floating islands and unpredictable reefs, but they have all been overturned.Obviously, how can the reef move so quickly unless it has a machine in its belly?
Similarly, the assumption that it is a floating hull or a pile of debris does not hold, because it still moves too fast.
So, there are only two explanations for the problem. People have their own views and naturally fall into two distinct groups: one says it's a monster of enormous power, the other says it's a very powerful "submarine".
Well, that last assumption is acceptable, but it's hard to justify it when you go to Europe and the United States.Which ordinary person would have such a powerful machine?It's impossible.Where and when did he ask anyone to make such a huge object, and how could he keep the wind from leaking during construction?
It seems that only a government can possibly possess such a destructive machine, and in this catastrophic age, when people are trying to increase the power of weapons of war, it is possible that one country is concealing the possibility that other countries are trying to produce such appalling weapons.After the Charsberg rifle there was a torpedo, after which there was an underwater hammer, and then the magic path climbed in response, the situation became more and more intense.At least, that's what I think.
Algorithms provided by SnowNLP:
from snownlp import SnowNLP text = " The text above, omitted here " s = SnowNLP(text) print(". ".join(s.summary(5)))
Output results:
Naturally there are two distinct schools of thought: one that says it's a monster of enormous power.This assumption is also not valid.When I arrived in New York.Say it's a floating hull or a pile of debris.Others say it's a very powerful "diving boat"
Initially, the result is not very good. Next, we calculate the sentence weights ourselves to achieve a simple summary function, which requires jieba:
import re import jieba.analyse import jieba.posseg class TextSummary: def __init__(self, text): self.text = text def splitSentence(self): sectionNum = 0 self.sentences = [] for eveSection in self.text.split("\n"): if eveSection: sentenceNum = 0 for eveSentence in re.split("!|. |?", eveSection): if eveSentence: mark = [] if sectionNum == 0: mark.append("FIRSTSECTION") if sentenceNum == 0: mark.append("FIRSTSENTENCE") self.sentences.append({ "text": eveSentence, "pos": { "x": sectionNum, "y": sentenceNum, "mark": mark } }) sentenceNum = sentenceNum + 1 sectionNum = sectionNum + 1 self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE") for i in range(0, len(self.sentences)): if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]: self.sentences[i]["pos"]["mark"].append("LASTSECTION") def getKeywords(self): self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v')) def sentenceWeight(self): # Calculating Position Weights of Sentences for sentence in self.sentences: mark = sentence["pos"]["mark"] weightPos = 0 if "FIRSTSECTION" in mark: weightPos = weightPos + 2 if "FIRSTSENTENCE" in mark: weightPos = weightPos + 2 if "LASTSENTENCE" in mark: weightPos = weightPos + 1 if "LASTSECTION" in mark: weightPos = weightPos + 1 sentence["weightPos"] = weightPos # Calculating the Thread Word Weights of Sentences index = [" in short ", " To make a long story short "] for sentence in self.sentences: sentence["weightCueWords"] = 0 sentence["weightKeywords"] = 0 for i in index: for sentence in self.sentences: if sentence["text"].find(i) >= 0: sentence["weightCueWords"] = 1 for keyword in self.keywords: for sentence in self.sentences: if sentence["text"].find(keyword) >= 0: sentence["weightKeywords"] = sentence["weightKeywords"] + 1 for sentence in self.sentences: sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"] def getSummary(self, ratio=0.1): self.keywords = list() self.sentences = list() self.summary = list() # Call method to calculate keywords, clauses and weights respectively self.getKeywords() self.splitSentence() self.sentenceWeight() # Sort the weight values of sentences self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True) # Based on the sorting results, the top ratio sentences are used as summaries for i in range(len(self.sentences)): if i < ratio * len(self.sentences): sentence = self.sentences[i] self.summary.append(sentence["text"]) return self.summary
This code mainly uses tf-idf to extract keywords, then uses keyword extraction to give sentences full weight, and finally obtains the overall result and runs:
testSummary = TextSummary(text) print(". ".join(testSummary.getSummary()))
You can get the results:
Building prefix dict from the default dictionary ... Loading model from cache /var/folders/yb/wvy_7wm91mzd7cjg4444gvdjsglgs8/T/jieba.cache Loading model cost 0.721 seconds. Prefix dict has been built successfully. It seems that only a government can possibly possess such a destructive machine, and in this catastrophic age, when people are trying to increase the power of weapons of war, it is possible that one country is concealing the possibility that other countries are trying to produce such appalling weapons.So I grabbed hold of the ship's stay and sorted out the mineral and animal and plant specimens that I had collected, when the Scores crashed.Similarly, the assumption that it is a floating hull or a pile of debris does not hold, because it still moves too fast
We can see that the overall effect is better than just now.
Publish API
With the Serverless architecture, the above code is collated and published.
Code collation results:
import re, json import jieba.analyse import jieba.posseg class NLPAttr: def __init__(self, text): self.text = text def splitSentence(self): sectionNum = 0 self.sentences = [] for eveSection in self.text.split("\n"): if eveSection: sentenceNum = 0 for eveSentence in re.split("!|. |?", eveSection): if eveSentence: mark = [] if sectionNum == 0: mark.append("FIRSTSECTION") if sentenceNum == 0: mark.append("FIRSTSENTENCE") self.sentences.append({ "text": eveSentence, "pos": { "x": sectionNum, "y": sentenceNum, "mark": mark } }) sentenceNum = sentenceNum + 1 sectionNum = sectionNum + 1 self.sentences[-1]["pos"]["mark"].append("LASTSENTENCE") for i in range(0, len(self.sentences)): if self.sentences[i]["pos"]["x"] == self.sentences[-1]["pos"]["x"]: self.sentences[i]["pos"]["mark"].append("LASTSECTION") def getKeywords(self): self.keywords = jieba.analyse.extract_tags(self.text, topK=20, withWeight=False, allowPOS=('n', 'vn', 'v')) return self.keywords def sentenceWeight(self): # Calculating Position Weights of Sentences for sentence in self.sentences: mark = sentence["pos"]["mark"] weightPos = 0 if "FIRSTSECTION" in mark: weightPos = weightPos + 2 if "FIRSTSENTENCE" in mark: weightPos = weightPos + 2 if "LASTSENTENCE" in mark: weightPos = weightPos + 1 if "LASTSECTION" in mark: weightPos = weightPos + 1 sentence["weightPos"] = weightPos # Calculating the Thread Word Weights of Sentences index = [" in short ", " To make a long story short "] for sentence in self.sentences: sentence["weightCueWords"] = 0 sentence["weightKeywords"] = 0 for i in index: for sentence in self.sentences: if sentence["text"].find(i) >= 0: sentence["weightCueWords"] = 1 for keyword in self.keywords: for sentence in self.sentences: if sentence["text"].find(keyword) >= 0: sentence["weightKeywords"] = sentence["weightKeywords"] + 1 for sentence in self.sentences: sentence["weight"] = sentence["weightPos"] + 2 * sentence["weightCueWords"] + sentence["weightKeywords"] def getSummary(self, ratio=0.1): self.keywords = list() self.sentences = list() self.summary = list() # Call method to calculate keywords, clauses and weights respectively self.getKeywords() self.splitSentence() self.sentenceWeight() # Sort the weight values of sentences self.sentences = sorted(self.sentences, key=lambda k: k['weight'], reverse=True) # Based on the sorting results, the top ratio sentences are used as summaries for i in range(len(self.sentences)): if i < ratio * len(self.sentences): sentence = self.sentences[i] self.summary.append(sentence["text"]) return self.summary def main_handler(event, context): nlp = NLPAttr(json.loads(event['body'])['text']) return { "keywords": nlp.getKeywords(), "summary": ". ".join(nlp.getSummary()) }
Write the project serverless.yaml file:
nlpDemo: component: "@serverless/tencent-scf" inputs: name: nlpDemo codeUri: ./ handler: index.main_handler runtime: Python3.6 region: ap-guangzhou description: Text Summary / Keyword function memorySize: 256 timeout: 10 events: - apigw: name: nlpDemo_apigw_service parameters: protocols: - http serviceName: serverless description: Text Summary / Keyword function environment: release endpoints: - path: /nlp method: ANY
Since jieba is used in the project, it is recommended that you install it under the CentOS system with the corresponding Python version, or use a dependency tool I previously made for convenience:
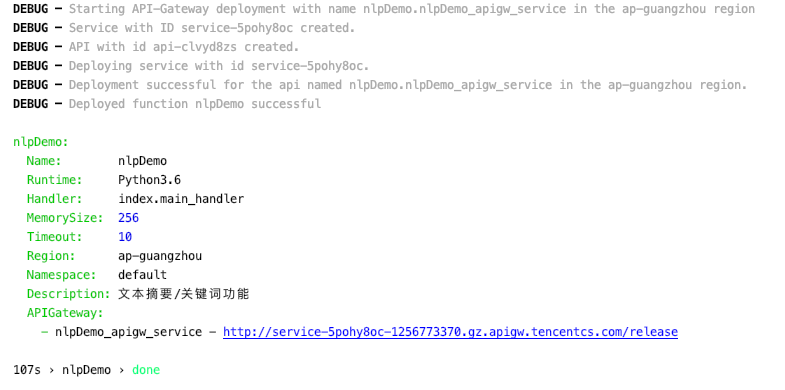
Deploy through sls --debug:
Deployment is complete and simple testing can be done with PostMan:
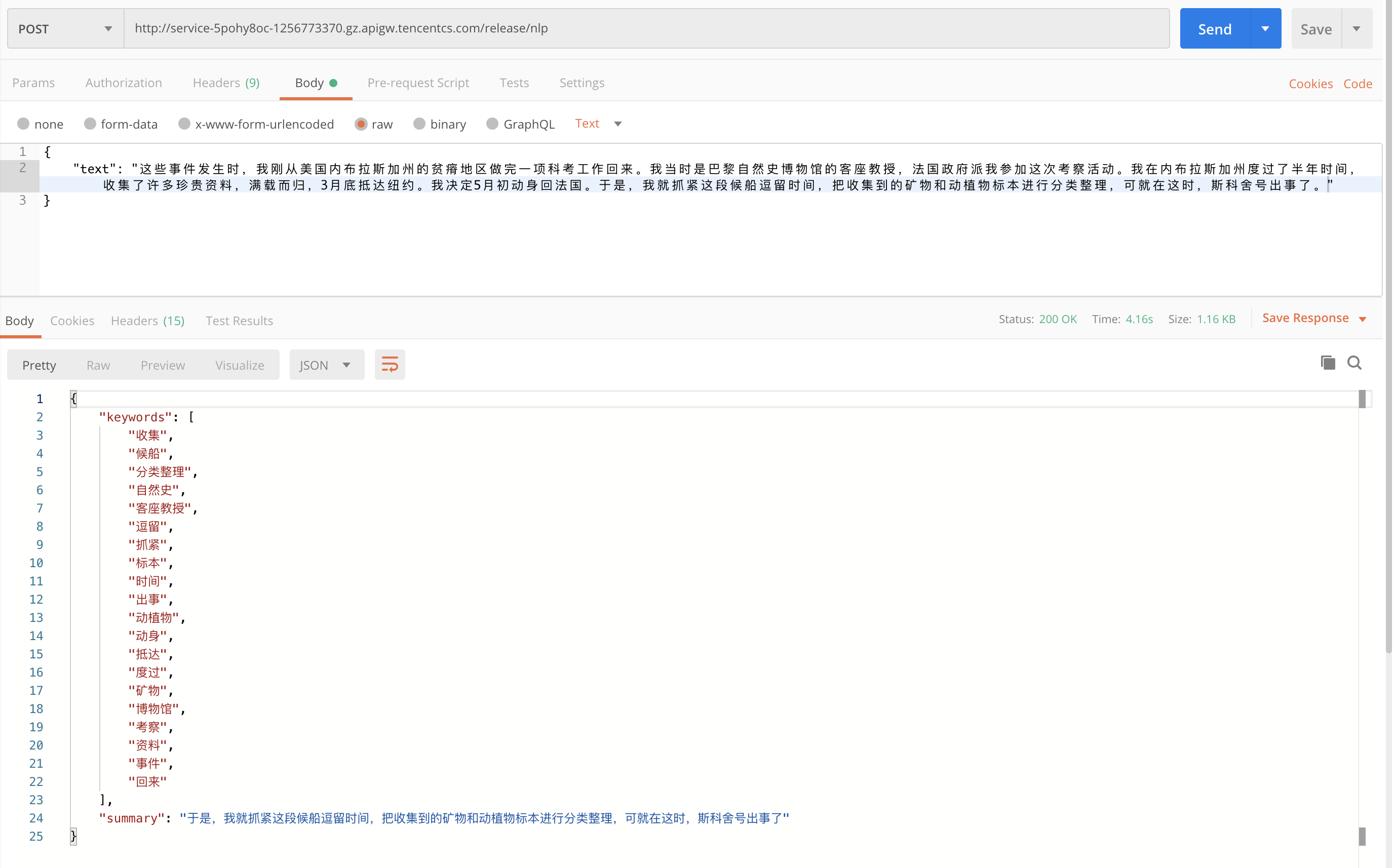
As you can see from the diagram above, we have already output the target results as expected.At this point, the API for text summary/keyword extraction has been deployed.
summary
Relatively, it is very easy and convenient to make an API through Serveless architecture, which can plug and unplug the API and make it component. I hope this article can give readers more ideas and inspiration.
We invite you to experience the most convenient way to develop and deploy Serverless.During the trial period, the associated products and services provide free resources and professional technical support to help your business achieve Serverless quickly and easily!
One More Thing
What can you do in 3 seconds?Have a drink of water, see an email, or - deploy a complete Serverless Apply?
Copy Link to PC Browser Access: https://serverless.cloud.tencent.com/deploy/express
Fast deployment in 3 seconds for the fastest ever experience Serverless HTTP Actual development!
Port:
- GitHub: github.com/serverless
- Official website: serverless.com
Welcome to: Serverless Chinese Network , you can Best Practices Experience more development of Serverless apps here!
Recommended reading: Serverless Architecture: From Principles, Design to Project Practice