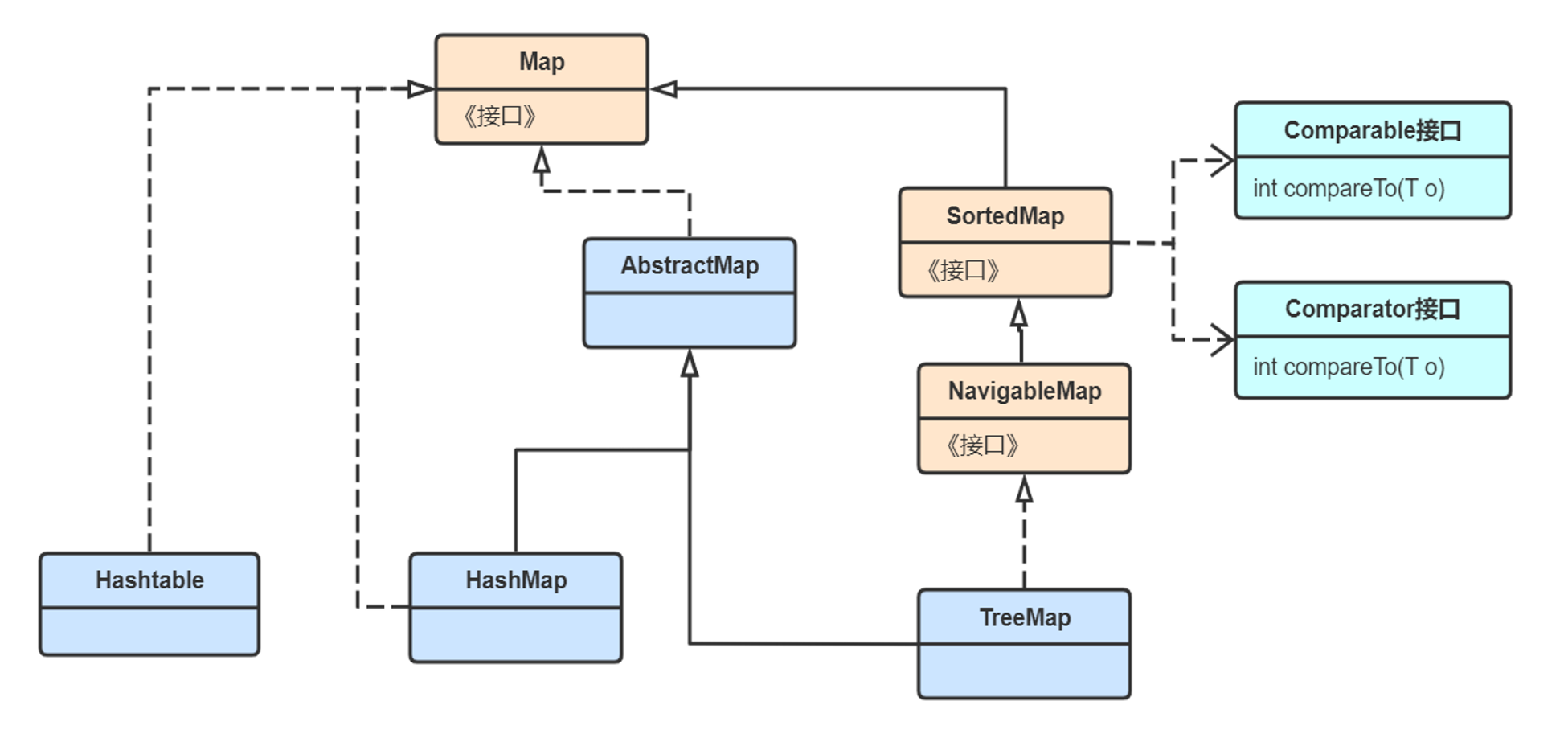
1, Map interface
Key and Value form a mapping relationship by storing data through key and Value
import java.util.HashMap;
import java.util.Map;
public class TestHashMap {
public static void main(String[] args) {
//The time complexity of map searching is O(1)
Map map = new HashMap();
//Store "a" string
map.put(1, "a");
//Overlay operation
map.put(1, "b");
map.put(2, "c");
System.out.println(map.size());//Length: 2
//Get the value of 1key
System.out.println(map.get(1));//value: b
//remove
map.remove(1);
System.out.println(map.size());//Length after removal: 1
}
}2, How HashMap works
HashMap is the most commonly used implementation class of Map interface
It encapsulates the hash table (hash table) data structure. The hash table is composed of array + linked list / red black tree. The stored key and value are encapsulated into the node object. When storing the node, first calculate the hash code value of the key and calculate the position in the array. If there is a node in the array, if it is different, it will be stored in the following linked list.
How HashMap works:
When creating a HashMap object, allocate a load factor value (a percentage value. When the element stored in the hash table reaches the load factor value compared with the array length, the capacity will be expanded). The default load factor value is 0.75; You can specify the initial capacity of the array (hash table). The default initial capacity is 16. When the constructor of HashMap is called, the array (hash table) is not created.
When storing a key value, first obtain the hashcode value of the key, shift the value to the right by 16, and do XOR operation with the result and the value to obtain the processed int value. The purpose of XOR operation is to make the positions calculated by the hashcode evenly distributed in the hash table. If the hash table is empty or exceeds the load factor value, expand the capacity, Initially create a Node array (hash table) with a length of 16. Use the processed hash code and array length remainder operation to obtain the location stored in the hash table. If there is no Node in the location, create a new Node and store it in the location; If there is a Node in this location, judge whether the hashcode of this Node's key and the stored key are the same, and whether the equals comparison is true. If both are met, replace the value of the original Node; If not, add nodes to the linked list of nodes. If the length of the linked list is greater than or equal to 7, turn the linked list into a red black tree. When the hash table is expanded, it should be expanded to twice the original length, because try to ensure that the location of the original Node and the location of the Node after expansion do not change greatly.
3, Apply
import java.util.Collection;
import java.util.HashMap;
public class TestHashMap {
public static void main(String[] args) {
HashMap<String,Integer> map = new HashMap<String,Integer>();
map.put("103", 30);
map.put("102", 20);
map.put("101", 10);
System.out.println(map);//{101=10, 102=20, 103=30}
System.out.println(map.containsKey("1022"));//false
System.out.println(map.containsValue(10));//true
//System.out.println(map.getOrDefault("1011", 100));
map.put("104", null);
//map.putIfAbsent("104", 40);
System.out.println(map);//{101=10, 102=20, 103=30, 104=null}
Collection<Integer> list = map.values();
System.out.println(list);//[10, 20, 30, null]
/* Map<String,Person> map = new HashMap<String,Person>();
map.put("230101199901011234", new Person("tom",23));
map.put("230101199901011235", new Person("tom2",23));
System.out.println(map.get("230101199901011234").getName());
*/
}
}4, The difference between Hashtable and HashMap
Hashtable is thread safe and inefficient. Neither key nor value can store null values
HashMap is thread unsafe and efficient. key and value can store null values
5, The difference between LinkedHashMap and HashMap
LinkedHashMap is an ordered Map set, which encapsulates a two-way linked list. When storing the key value node, it is stored in two data structures and stored in the linked list and hash table respectively. The hash table is used when searching and the linked list is used when traversing
LinkedHashMap has the advantage of order, but the disadvantage is that it is less efficient than HashMap when inserting key value
Extension: red black tree
6, HashSet
Unordered and unrepeatable collections encapsulate the collection of HashMap
The difference between ArrayList and HashSet:
import java.util.HashMap;
import java.util.HashSet;
public class TestHashSet {
public static void main(String[] args) {
//Unordered and unrepeatable (hashcode and equals of two key s are the same)
HashSet<String> set = new HashSet<String>();
set.add("tom"); //Overlay? Not added?
set.add("jack");
set.add("tom");
System.out.println(set.size());//Length: 2
//Get element?
set.remove("tom"); //Delete elements can only be deleted by object
System.out.println(set);//[jack]
HashMap<String,Object> map = new HashMap<String,Object>();
Object obj = new Object();
map.put("tom", obj);
map.put("jack", obj);
map.put("tom", obj);
System.out.println(map.size());//2
System.out.println(map.keySet());//[tom, jack]
}7, TreeMap/TreeSet
TreeMap is a sortable Map collection, which is sorted by default according to the description of the Comparable interface method of key
import java.util.Comparator;
import java.util.TreeMap;
public class TestTreeMap {
public static void main(String[] args) {
class StringLengthComparator implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}
}
TreeMap<String, Integer> treeMap = new TreeMap<String,Integer>(new
StringLengthComparator());
treeMap.put("ccc", 30);
treeMap.put("aa", 10);
treeMap.put("bbbb", 20);
//The result is sorted
System.out.println(treeMap);//{aa=10, ccc=30, bbbb=20}
}
}TreeSet encapsulates TreeMap and is a sortable and non repeatable collection
import java.util.Comparator;
import java.util.TreeSet;
public class TestTreeSet {
public static void main(String[] args) {
class StringLengthComparator implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}
}
TreeSet<String> treeSet = new TreeSet<String>(new StringLengthComparator());
treeSet.add("ccc");
treeSet.add("aa");
treeSet.add("bbbb");
treeSet.add("aa");
treeSet.add("ddddd");
System.out.println(treeSet.size());//Length: 4
//The result is sorted
System.out.println(treeSet);//[aa, ccc, bbbb, ddddd]
}
}8, PriorityQueue
The priority of Comparable queue can be determined according to the priority of Comparable queue, or only one priority can be determined by default
import java.util.PriorityQueue;
public class TestPriorityQueue {
public static void main(String[] args) {
PriorityQueue<Integer> queue = new PriorityQueue<Integer>();
//Queue and sort
queue.add(5);
queue.add(1);
queue.add(2);
queue.add(2);
//poll: retrieve and delete the header of this queue. If this queue is empty, null will be returned.
//Result: the head of the queue, or null, if the queue is empty
System.out.println(queue.poll());//1
System.out.println(queue.poll());//2
System.out.println(queue.poll());//2
System.out.println(queue.poll());//5
}
}9, Deque interface
Implementation classes include LinkedList and ArrayDeque
10, Iterator (iterator)
Iterator, which can be used to iterate over the Collection under the Collection
Iterator is one-way, and cannot modify the collection (add or delete elements) during iteration
Two methods of Iterator interface:
1. hasNext(): whether the next element exists. The iterator has a pointer
2. next(): the pointer moves backward one bit to return the element of the current position
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
Collections.addAll(list, "a","b");
Iterator<String> it = list.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}The judgment of existing hasNext must be made before calling next
1. Iteration of set:
public static void main(String[] args) {
//The Set under the Set interface inherits the iteratable interface and has the iterator method
HashSet<String> set = new HashSet<String>();
Collections.addAll(set, "a","b");
Iterator<String> it = set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
2. Iteration of map set:
Obtain the Set set containing all key s or the Set set containing all node objects through the API method of Map Set
keySet of Map
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<String,String>();
map.put("001", "a");
map.put("002", "b");
map.put("003", "c");
//Traverse all key values in the map
Set<String> set = map.keySet();
Iterator<String> it = set.iterator();
while(it.hasNext()) {
String key = it.next();
System.out.println(key+"-"+map.get(key));
}
}
Unidirectionality:
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
Collections.addAll(list, "a","b","c","d");
Iterator<String> it = list.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
//Re iteration has no way to manipulate the pointer of the iterator
it = list.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
Concurrency:
Concurrent modifications cannot be made during the iteration process, otherwise it will be thrown
ArrayList<String> list = new ArrayList<String>();
Collections.addAll(list, "a","b","c","d");
/* Iterator<String> it = list.iterator();
while(it.hasNext()) {
String s = it.next();
if("b".equals(s)) {
list.remove("b");
}
}*/
for(int i = 0;i<list.size();i++) {
if("b".equals(list.get(i))) {
list.remove("b");
}
}
System.out.println(list);Map to delete the qualified data during iteration:
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<String,String>();
map.put("001", "a");
map.put("002", "b");
map.put("003", "c");
map.put("004", "a");
map.put("005", "a");
map.put("006", "d");
//Traverse all key values in the map
Set<String> set = map.keySet();
Set<String> delKeySet = new HashSet<String>();
Iterator<String> it = set.iterator();
while(it.hasNext()) {
String key = it.next();
if("a".equals(map.get(key)))
delKeySet.add(key);
}
it = delKeySet.iterator();
while(it.hasNext()) {
map.remove(it.next());
}
System.out.println(map);
//The iterative deletion value in the Map is the key value of "a"
//Store the key with the value "a" in a collection
//Then traverse the collection and call map remove(key)
}11, Enhanced for loop
Syntax:
For (variable declaration: set or array){
Use variables
}
Iterator based
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
Collections.addAll(list, "a","b","c");
for(String str:list) {
System.out.println(str);
}
}public static void main(String[] args) {
//The Set under the Set interface inherits the iteratable interface and has the iterator method
HashSet<String> set = new HashSet<String>();
Collections.addAll(set, "a","b");
for(String str:set) {
System.out.println(str);
}
}HashMap<String,String> map = new HashMap<String,String>();
map.put("001", "a");
map.put("002", "b");
map.put("003", "c");
//Traverse all key values in the map
Set<Entry<String,String>> set = map.entrySet();
for(Entry<String,String> entry:set) {
System.out.println(entry.getKey()+"-"+entry.getValue());
}
int[] arr = new int[] {1,2,3};
for(int i :arr) {
System.out.println(i);
}
int[][] arrs = new int[][] {{4,5},{6,7,8}};
for(int[] is:arrs){
for(int i:is){
System.out.println(i);
}
}