1. Basic introduction to set interface
- Unordered (the order of addition and extraction is inconsistent), and there is no index
- Duplicate elements are not allowed, so it can contain at most one null
public static void main(String[] args) {
HashSet<Object> set = new HashSet<>();
set.add(1);
set.add(1);
set.add("zjh");
set.add("zjh");
set.add("jxj");
set.add("jxj");
set.add(null);
set.add(null);
System.out.println(set);
}

Note: the disorder mentioned here means that the order of output is different from that of addition, but if the output is repeated all the time, the order of output is the same. The reason will be analyzed when explaining the source code
1.1 traversal mode of set interface
- You can use iterators
- Enhanced for loop
2. HashSet
- HashSet implements the Set interface
- HashSet is actually a HashMap

- null values can be stored, but there can only be 1
- HashSet does not guarantee that the elements are ordered. It depends on the result of determining the index after hash
- Cannot have duplicate elements / objects
2.1 underlying mechanism of HashSet
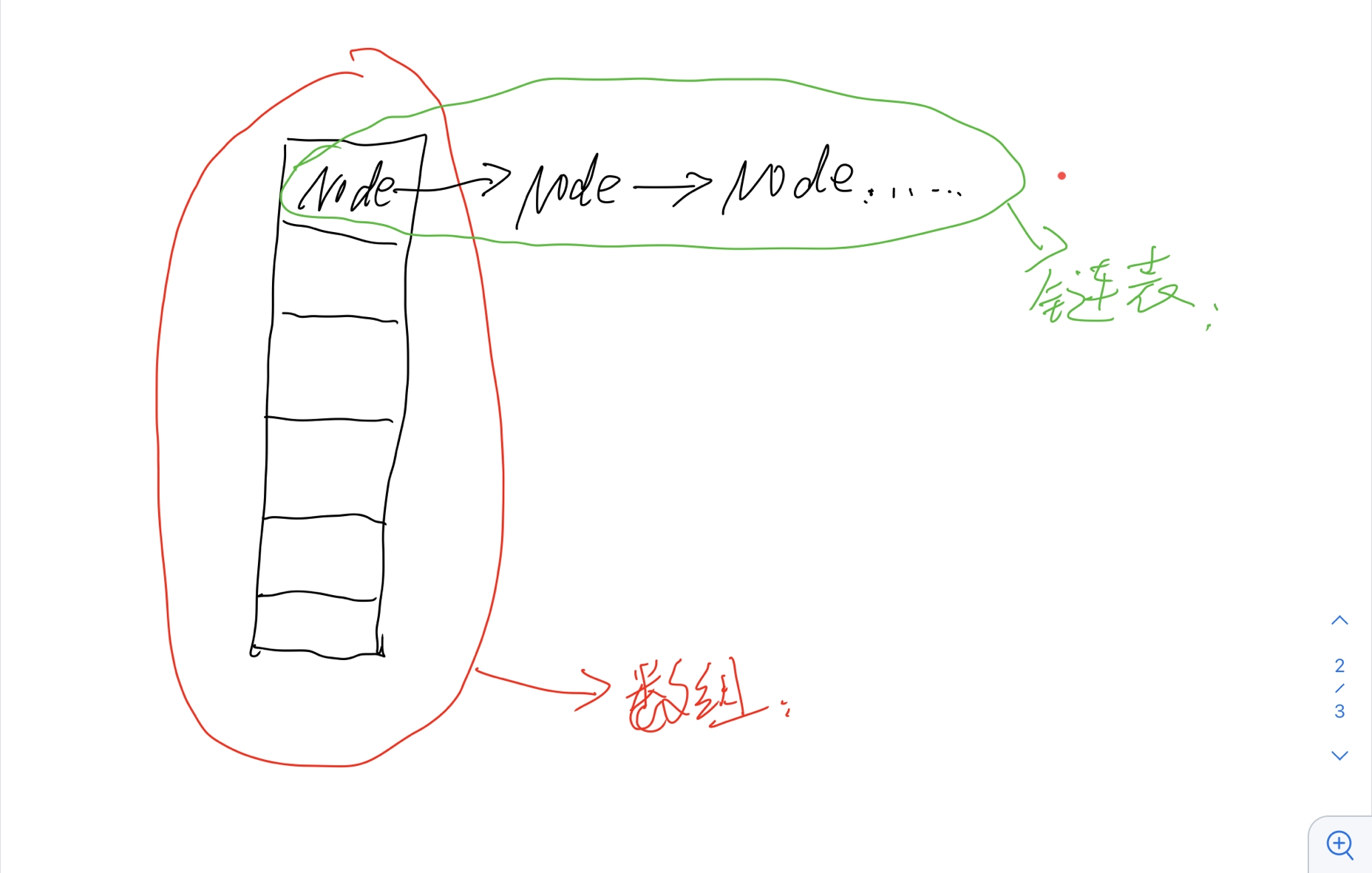
The bottom layer of HashSet is HashMap, and the bottom layer of HashMap is (array + linked list + red black tree)
As shown in the figure above, each position of the array can form a linked list (the linked list is composed of nodes, which are used to store data and point to the next node to form a linked list. If the length of a linked list and the total array reaches a certain condition, the linked list at a certain position of the array will be converted into a red black tree)
2.2 source code analysis of HashSet
2.2.1 conclusion
- The bottom layer of HashSet is HashMap
- When adding an element, first get the hash value, and then convert it to the index value (the index value is to determine where to put it in the array)
- Find the storage data table table and see whether the index position has stored data
- If not, join directly
- If yes, call equals for comparison. If it is the same, give up adding. If it is different, add it to the end (in the form of linked list)
- In Java 8, if the number of elements in a linked list exceeds TREEIFY_THRESHOLD (8 by default) and the size of table (that is, array) > = min_ TREEIFY_ Capability (64 by default), the linked list with a length of more than 8 will be trealized (i.e. converted into a red black tree)
2.2.2 source code analysis
Test code
public class SetMethod {
public static void main(String[] args) {
HashSet<Object> set = new HashSet<>();
set.add("java");
set.add("php");
set.add("java");
System.out.println(set);
}
}
result
Source code analysis (put a breakpoint on the new HashSet())
First, enter the parameterless constructor (you can see that the bottom layer is HashMap)

Then you enter the add() method
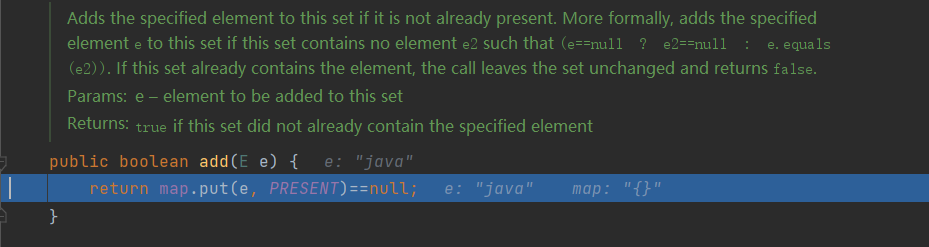

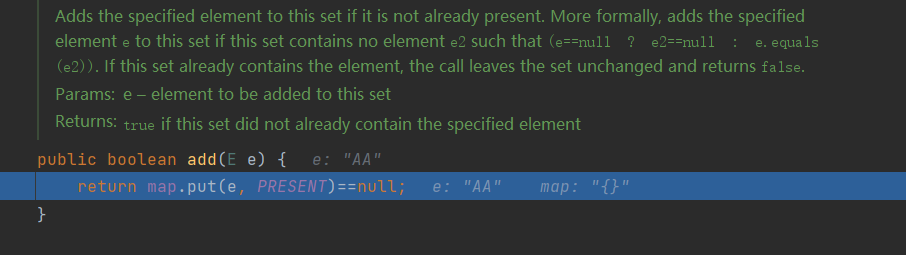
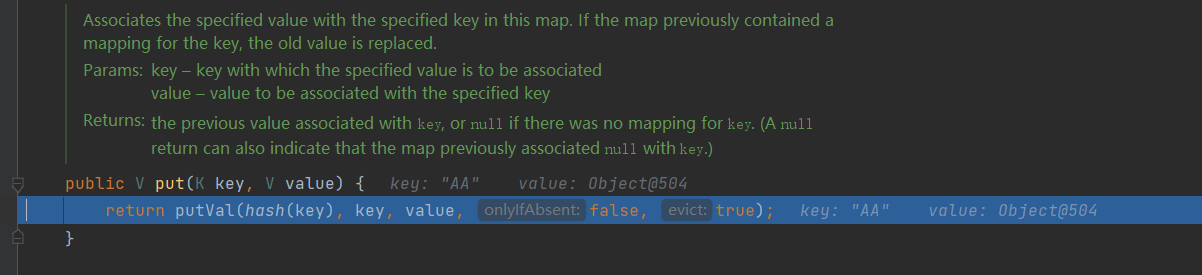
PRESENT is an Object class. Next, enter the put() method
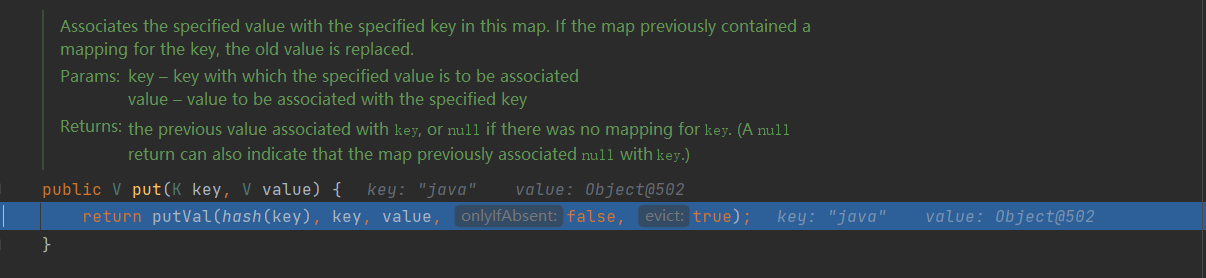
In the above figure, we can find that in the put() method, there are key and value. Key is the value of the "java" string we store, and value is the just PRESENT, that is, the Object class. In fact, this Object class has no function, just to occupy space, so that the HashSet can be stored in the form of key value of Map. No matter how many times you execute the put() method, the Object remains unchanged.
Next, first look at the hash() method

Here is to judge whether the key is empty. The current key is "java". If the key is empty, it will return 0. Otherwise, it will return the corresponding hash value. Note that this hash value is not hashcode
Next, enter the putVal() method
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; // These are auxiliary variables
if ((tab = table) == null || (n = tab.length) == 0) // First of all, we must understand that HashSet is essentially a HashMap, so in this line of code, table is the table in HashMap. This table is the array of Node nodes. When I first came in, this table was empty
n = (tab = resize()).length; // If the tab is empty or the length is 0, this statement will be executed. The most important thing is the resize() method, which is described below
if ((p = tab[i = (n - 1) & hash]) == null) // This step is to determine whether the position of the array where the hash value corresponding to your key should be stored is empty
tab[i] = newNode(hash, key, value, null); // If it is empty, it will be assigned directly. Note that this key is the value we store, and value is the Object object. The purpose of storing hash is to prepare for the subsequent linked list link. This null position is the next pointer, which is the next pointer of the linked list
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // Judge whether the current size has exceeded the critical value. If it exceeds the critical value, resize() is the capacity expansion
resize();
afterNodeInsertion(evict); //This method is a method left by HashMap to its subclass, which is empty. For example, it is left to LinkedHashMap to implement
return null;
}
The above code is the most important code, and the explanation has been written in the above code.
resize() method
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length; // Here, table is null, that is, oldTab is null
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY; // That's it. Give newCap a constant. The value of this constant is 16. This is the capacity of the default initialization array
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // DEFAULT_LOAD_FACTOR this is the default loading factor, which is 0.75 default by default_ INITIAL_ Capability is the default initial capacity, and newThr is the multiplication of the two. This newThr is the critical value. What does this mean? That is, if your array reaches the critical value, which is 12, the critical value will change continuously, because your critical value will change continuously with the change of your capacity. If your capacity reaches the critical value, it will be expanded. It will not be expanded until it is full. If it reaches the critical value, it will be expanded
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // Here, the threshold is used to record the critical value. At the beginning, it is 12
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // Here we begin to create a Node array with a length of 16
table = newTab; // Assign the created Node array with length of 16 to table
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab; // Finally, the newTab is returned. Now it is an array with a length of 16, because this is the HashSet just created and the add operation just started
}
Next, enter the add method for the second time
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // Directly enter here. Now, because it is the second time to add, the table is no longer empty and the length has changed to 16
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // Here is to judge the position in the table according to the hash of the key. At this time, the result corresponding to "php" should be stored in the position where the array index position is 9
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount; // Just walk right here
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Next, start the add() method for the third time
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // If you enter here, you won't go in if the conditions are not established
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // It doesn't hold because "java" has been stored before
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k; // Enter here to create some auxiliary variable development skills. Where auxiliary variables are needed, they will be created in which code block
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) // This p is the object of the current index position, if 1 The hash value of the first element in the current index position is the same as the hash value of the value to be stored, and the key in the index position is the same object or 2 The hash value of the first element in the current index position is the same as the hash value of the value to be stored at present, and (the key currently stored is not empty and key. Equals (key stored in the index position) is true). As long as the above conditions are met, the node in the index position is assigned to e. in fact, it is considered that it cannot be added, and it is considered to be duplicate
e = p;
else if (p instanceof TreeNode)// Now the else if and the following else will not be triggered in this add method. Now we will explain the else if and the else code, and explain that the else if is to judge whether the p is a red black tree, because the p is a node at the index position of the array, and judge whether the node is a red black tree through this node
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // If it is a red black tree, call putTreeVal to add it
else {
for (int binCount = 0; ; ++binCount) { // This for loop has no termination condition. If you want to jump out of the for loop, only the following break will take effect
if ((e = p.next) == null) { // Here is the next node of the node that obtains the index position. Assign the value to E. if e is empty, add the node to the back of the linked list
p.next = newNode(hash, key, value, null); // Here is to add
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st / / if the cycle continues, if the length of the linked list at the current index position reaches the critical value, the linked list will be treated as a red black tree_ The value of threshold is 8, because when our binCount starts from 0 to 7, there are actually 8 nodes, so we need to start treeing. Note that after treeing, in the treeing method, we will also judge whether the array length is less than 64. If it is less than 64, we will not treeing, but only expand the array capacity
treeifyBin(tab, hash); // Red black tree
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // If you find that the added value is the same as the value in the linked list, break immediately and leave without adding
break;
p = e;
}
}
if (e != null) { // existing mapping for key / / that's it,
V oldValue = e.value; // The value of e is the Object object
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue; // Return the Object object and return it to the upper layer for judgment. Finally, the result of the add method is false, so the addition fails
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
2.3 capacity expansion mechanism of HashSet
- The bottom layer of HashSet is HashMap. When it is added for the first time, the table is expanded to 16, and the critical value is array capacity * loading factor. The loading factor is 0.75
- If the table array contains a linked list whose length reaches the critical value, the capacity will be expanded (for example, there is a linked list with length of 8 at the place with index 1 and a linked list with length of 8 at the place with index 2, and the combined length of these two places reaches 16, the capacity will also be expanded). The new capacity is the array capacity * 2, and the new critical value will also be changed, but the loading factor will not be changed
- In jdk8, if the length of the array reaches 64 and the length of the linked list reaches 8, the red black tree will be implemented. If not, the form of array expansion will be adopted
3. LinkedHashSet
- LinkedHashSet is a subclass of HashSet
- The bottom layer of LinkedHashSet is a LinkedHashMap, and the bottom layer maintains an array + two-way linked list
- LinkedHashSet determines the storage location of elements according to the hashcode value of elements, and uses linked list to maintain the order of elements, which makes elements appear to be saved in insertion order
- LinkedHashSet does not allow adding duplicate elements
Code case
public class LinkedHashSetResource {
public static void main(String[] args) {
LinkedHashSet<Object> set = new LinkedHashSet<>();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("Liu",100));
set.add(123);
set.add("HSP");
}
}
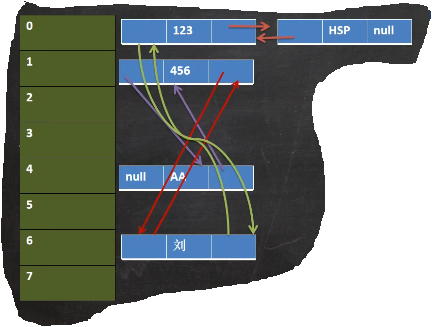
Simulated ground floor diagram
3.1 LinkedHashSet underlying source code analysis
Case code
public class LinkedHashSetResource {
public static void main(String[] args) {
LinkedHashSet<Object> set = new LinkedHashSet<>();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("Liu",100));
set.add(123);
set.add("HSP");
}
}
explain:
- A hash table and a two-way linked list are maintained in the LinkedHashSet (the LinkedHashSet has a head and a tail)
- Each node has before and after attributes, which can form a two-way linked list
- When adding an element, first calculate the hash value, then the index, determine the position of the element in the table, and then add the element to the two-way linked list (the principle of adding is the same as that of HashSet)
- Traverse the LinkedHashSet, and the insertion order is consistent with the traversal order
Source code analysis (breakpoints in new LinkedHashSet())

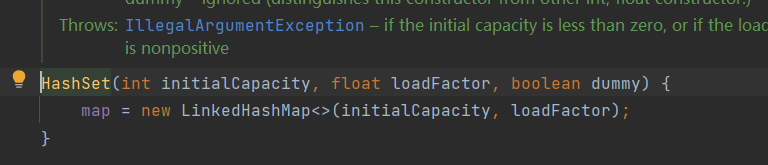
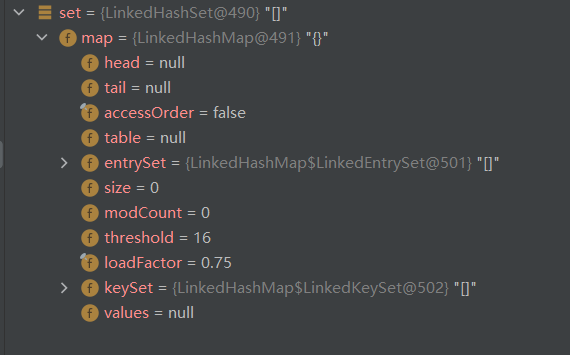
You can see that the underlying layer calls LinkedHashMap. The initialization capacity is 16 and the loading factor is 0.75
The underlying structure of LinkedHashSet is shown in the figure above
Next, enter the add method
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}

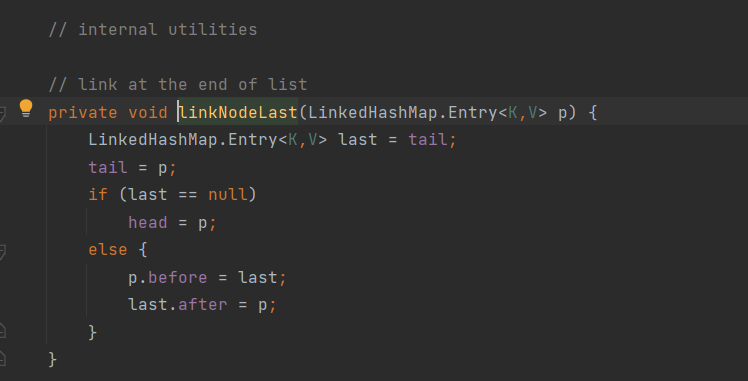
In fact, it can be seen that it is almost the same as the bottom layer of HashSet, that is, the stored node is Entry

Entry is an internal class that inherits Node.
Summary:
- The difference between LinkedHashSet and HashSet is the difference between linked list and node (roughly)
- The bottom layer of Set is Map
- The value stored in Set is actually stored in key (key value structure), and value is occupied by an Object
- Why is the stored value of Set stored in key? Because in its key value structure, key is non repeatable