Set type of redis value basic data type
1. Why
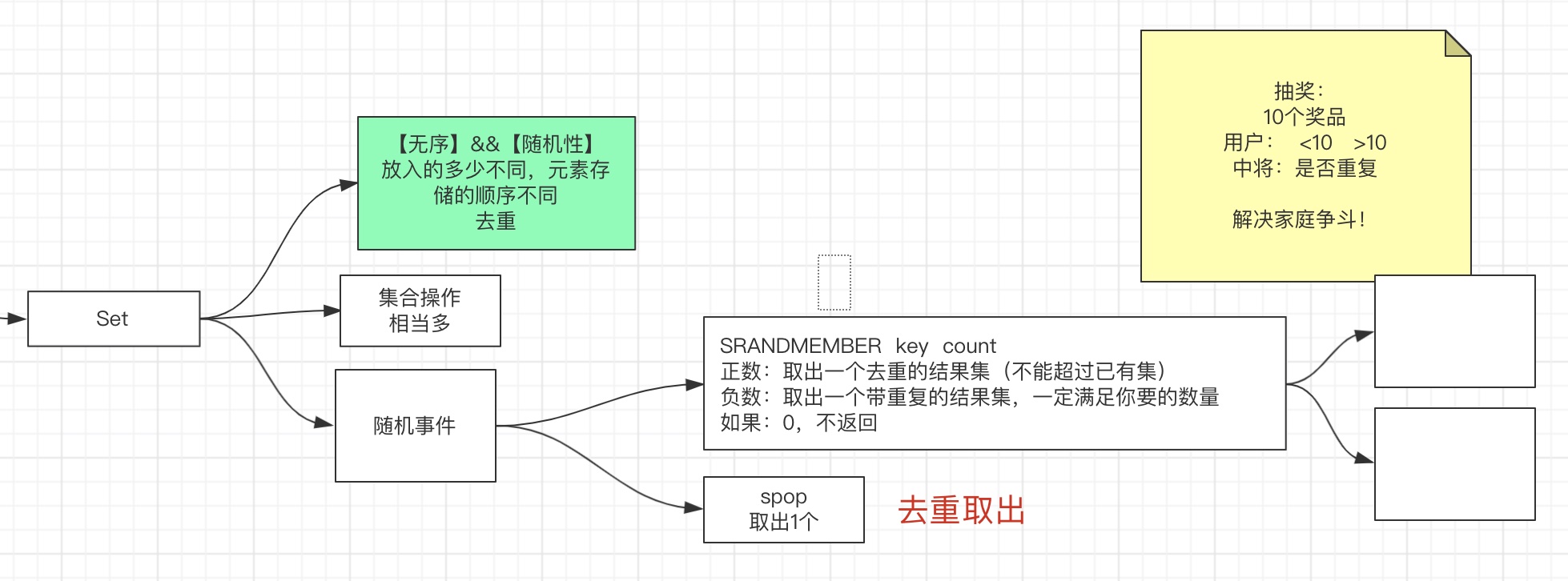
characteristic
- disorder
- duplicate removal
Application scenario
-
Collection operation. Finding intersection, union and difference sets
-
Random events.
-
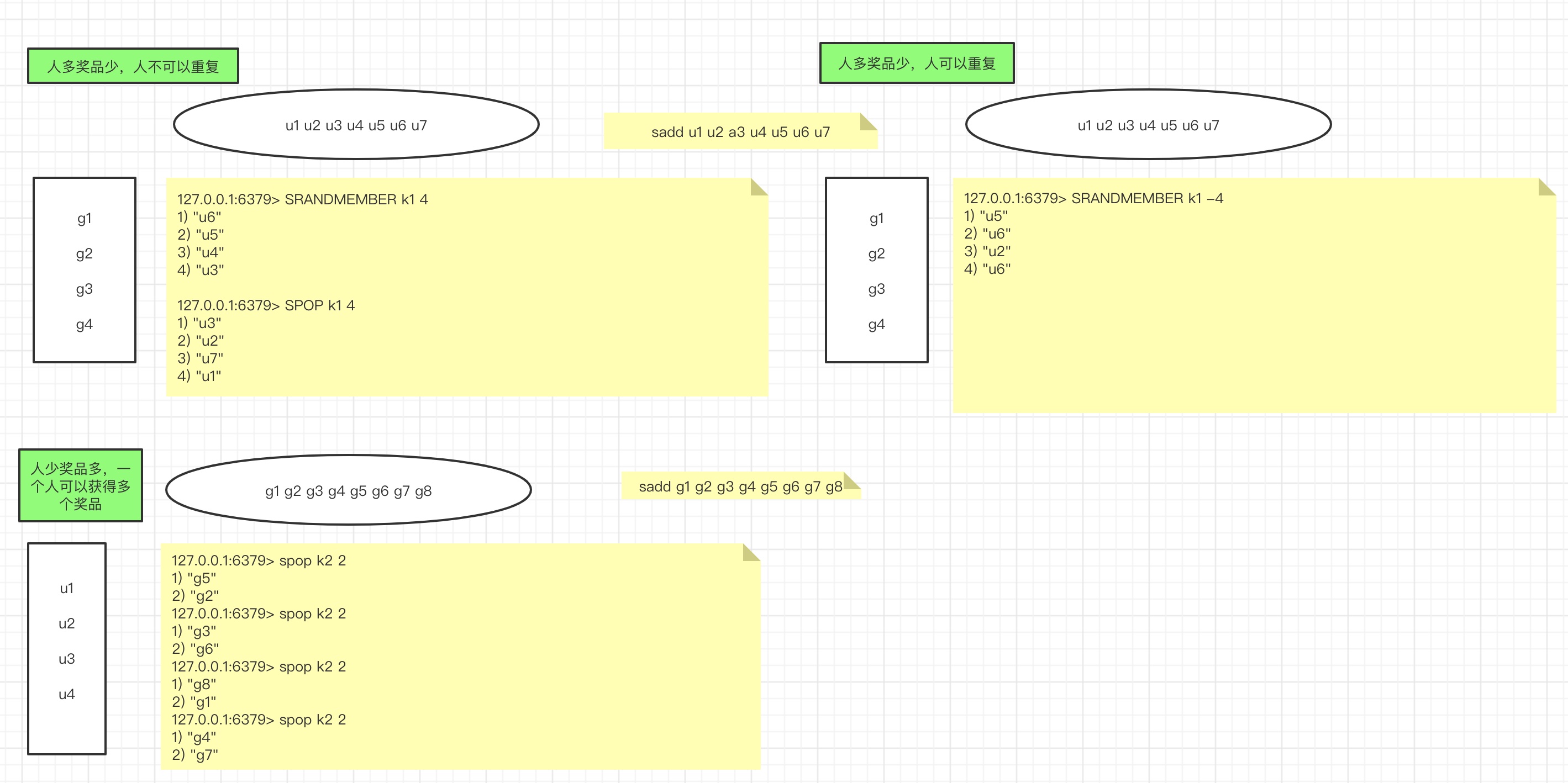
Solve the lottery problem: 10 prize users < 10, and the winning points of users are whether to repeat or not
-
Positive number de duplication: in line with the semantics that a person can only win one gift
-
Negative numbers can be repeated:
-
Several dimensions:
-
-
-
Redis's Set data type can be used to track some unique data, such as the unique IP address information of accessing a blog. For this scenario, we only need to store the visitor's IP in redis every time we visit the blog, and the Set data type will automatically ensure the uniqueness of the IP address.
-
Make full use of the convenient and efficient characteristics of Set type server aggregation operation, which can be used to maintain the association relationship between data objects. For example, all customer IDs for purchasing an electronic device are stored in a specified Set, while the customer ID for purchasing another electronic product is stored in another Set. If we want to obtain which customers have purchased these two goods at the same time, the intersection command of Set can give full play to its advantages of convenience and efficiency.
2. What
1. help @set
SADD key member [member ...] summary: Add one or more members to a set since: 1.0.0 SCARD key summary: Get the number of members in a set since: 1.0.0 SDIFF key [key ...] summary: Subtract multiple sets since: 1.0.0 SDIFFSTORE destination key [key ...] summary: Subtract multiple sets and store the resulting set in a key since: 1.0.0 SINTER key [key ...] summary: Intersect multiple sets since: 1.0.0 SINTERSTORE destination key [key ...] summary: Intersect multiple sets and store the resulting set in a key since: 1.0.0 SISMEMBER key member summary: Determine if a given value is a member of a set since: 1.0.0 SMEMBERS key summary: Get all the members in a set since: 1.0.0 SMOVE source destination member summary: Move a member from one set to another since: 1.0.0 SPOP key [count] summary: Remove and return one or multiple random members from a set since: 1.0.0 SRANDMEMBER key [count] summary: Get one or multiple random members from a set since: 1.0.0 SREM key member [member ...] summary: Remove one or more members from a set since: 1.0.0 SSCAN key cursor [MATCH pattern] [COUNT count] summary: Incrementally iterate Set elements since: 2.8.0 SUNION key [key ...] summary: Add multiple sets since: 1.0.0 SUNIONSTORE destination key [key ...] summary: Add multiple sets and store the resulting set in a key since: 1.0.0
2. Document extension
-
SDIFF The left difference set is taken in the order of the passed parameters
-
SDIFFSTORE The STORE method is the delicacy of the author's design to avoid multiple IO
-
SMEMBERS More resource consuming operations
-
SPOP Take out one
-
-
Redis SRANDMEMBER If the command only uses the key parameter, a random element in the set key is returned randomly.
From Redis 2.6, the count parameter can be accepted. If count is an integer and less than the number of elements, an array containing count different elements will be returned. If count is an integer and greater than the number of elements in the set, all elements of the whole set will be returned. If count is a negative number, an array containing the number of elements with the absolute value of count will be returned, Then one element will appear multiple times in the returned result set.
When only the key parameter is provided, the command is similar to the SPOP command. The difference is that the SPOP command will remove the selected random element from the set, while SRANDMEMBER only returns the tag element without any operation on the original set.
1. Code of conduct when passing count parameter
When a count parameter with a positive value is passed, the returned element is like removing each selected element from the collection (just like extracting a number in a bingo game). However, elements are not removed from the collection. So basically:
- Duplicate elements are not returned.
- If the value of the count parameter is greater than the number of elements in the collection, this command will only return the entire collection without additional elements.
On the contrary, when the value of the count parameter is negative, the behavior of this command will change, and the extraction operation is like putting the extracted elements back into the package after each extraction. Therefore, duplicate elements may be returned, and the number of elements we request will always be returned, because we can repeat the same elements again and again, Except when the collection is empty (or there is no key), an empty array will always be returned.
2. Return the distribution of elements
When the number of elements in the set is small, the distribution of returned elements is far from perfect. This is because we use an approximate random element function, which can not guarantee a good distribution.
The algorithm used (implemented in dict.c) samples the hash table bucket to find a non empty bucket. Once the non empty bucket is found, because we use the linking method in the implementation of the hash table, we will check the number of elements in the bucket and select a random element.
This means that if you have two non empty buckets in the whole hash table, one of which has three elements and the other has only one element, the elements that exist alone in its bucket will be returned with a higher probability.
-
3. Classification
-
Add, delete, modify and check
-
Set operation, intersection, union, difference
-
Random events