1 data set introduction
ShpaeNet is a common data set in the point cloud. It can complete the task of component segmentation, that is, the component knows the segmentation of large data in the point cloud, and also needs to segment its widgets. It includes a total of 16 categories, each of which can be divided into several sub categories (for example, aircraft can be divided into wing, body and other sub categories), and a total of 50 sub categories. Let's visualize what it looks like after sampling and coloring:


It can be found that it not only divides the table and chair, but also divides its table legs and other small parts into different colors.
2. Data set structure
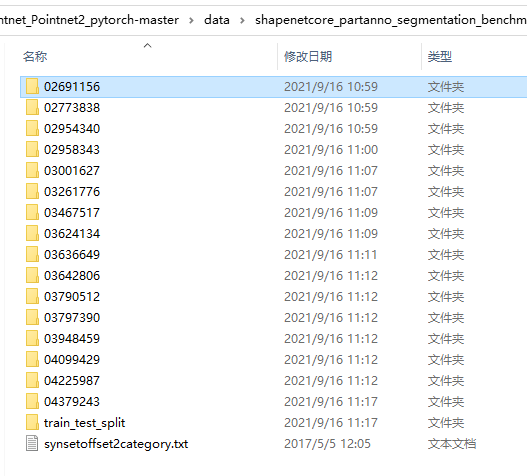
After downloading the dataset, the dataset is like this. The digital folder contains point cloud data of each category. For example, the first is the aircraft category.
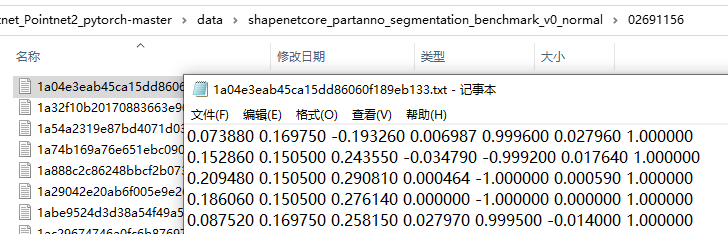
Open the folder, you can find that there are many txt files. Each TXT file is a point cloud data, which is equivalent to an image in 2d. Each point cloud data consists of many points. The first three points are xyz, the position coordinates of the point cloud, and the last three points are the rgb color coordinates of the point cloud. For shapenet, the best point is the subcategory to which the point belongs, that is, 1 represents the first of the 50 subcategories.
The form of other folders is the same as this one, but there is no more detail here.

For train_ test_ The split folder is a jason file that divides data. It divides the data set into training set, test set and verification set. Each element is a point cloud data, divided by slash. The second is the category of the point cloud data, and the third is the name of the point cloud data. For example, the name in the test jason file is the name of the point cloud data used for the test.
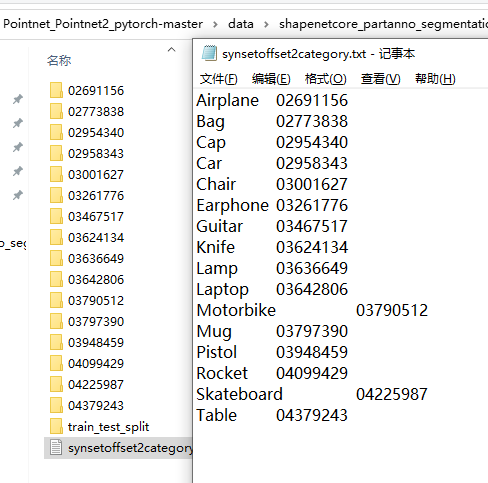
synsetoffset2category.txt stores the relationship between the 16 categories of shapnet and the folder name.
3. Data sets read in code analysis
For the data set read in by shapenet data, I refer to the data set part of potinet.
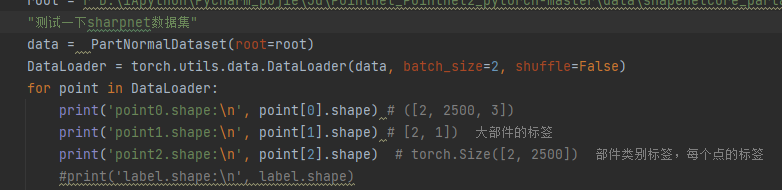
Fill in the path and test some output parts first. It can be found that the shapenet data set returns us three outputs. The first is the xyz coordinates after sampling in each point cloud set, the label of each large category, and the category of each point in each point cloud set (22500).
The following is a brief analysis of the code of the data set. I have commented on the key code
# *_*coding:utf-8 *_*
import os
import json
import warnings
import numpy as np
from torch.utils.data import Dataset
warnings.filterwarnings('ignore')
def pc_normalize(pc):
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))
pc = pc / m
return pc
class PartNormalDataset(Dataset):
def __init__(self,root = './data/shapenetcore_partanno_segmentation_benchmark_v0_normal', npoints=2500, split='train', class_choice=None, normal_channel=False):
self.npoints = npoints # Sampling points
self.root = root # File root path
self.catfile = os.path.join(self.root, 'synsetoffset2category.txt') # Path corresponding to category and folder name
self.cat = {}
self.normal_channel = normal_channel # Whether to use rgb information
with open(self.catfile, 'r') as f:
for line in f:
ls = line.strip().split()
self.cat[ls[0]] = ls[1]
self.cat = {k: v for k, v in self.cat.items()} #{'Airplane': '02691156', 'Bag': '02773838', 'Cap': '02954340', 'Car': '02958343', 'Chair': '03001627', 'Earphone': '03261776', 'Guitar': '03467517', 'Knife': '03624134', 'Lamp': '03636649', 'Laptop': '03642806', 'Motorbike': '03790512', 'Mug': '03797390', 'Pistol': '03948459', 'Rocket': '04099429', 'Skateboard': '04225987', 'Table': '04379243'}
self.classes_original = dict(zip(self.cat, range(len(self.cat)))) #{'Airplane': 0, 'Bag': 1, 'Cap': 2, 'Car': 3, 'Chair': 4, 'Earphone': 5, 'Guitar': 6, 'Knife': 7, 'Lamp': 8, 'Laptop': 9, 'Motorbike': 10, 'Mug': 11, 'Pistol': 12, 'Rocket': 13, 'Skateboard': 14, 'Table': 15}
if not class_choice is None: # Select some categories for training. It seems that this function is not used
self.cat = {k:v for k,v in self.cat.items() if k in class_choice}
# print(self.cat)
self.meta = {} # Read the classified folder jason file and put their names in the list
with open(os.path.join(self.root, 'train_test_split', 'shuffled_train_file_list.json'), 'r') as f:
train_ids = set([str(d.split('/')[2]) for d in json.load(f)]) # '928c86eabc0be624c2bf2dc31ba1713' this is the first value
with open(os.path.join(self.root, 'train_test_split', 'shuffled_val_file_list.json'), 'r') as f:
val_ids = set([str(d.split('/')[2]) for d in json.load(f)])
with open(os.path.join(self.root, 'train_test_split', 'shuffled_test_file_list.json'), 'r') as f:
test_ids = set([str(d.split('/')[2]) for d in json.load(f)])
for item in self.cat:
self.meta[item] = []
dir_point = os.path.join(self.root, self.cat[item]) # # Get the path corresponding to a folder, such as the first folder 02691156
fns = sorted(os.listdir(dir_point)) # Get each txt file under the folder according to the path and put it in the list
# print(fns[0][0:-4])
if split == 'trainval':
fns = [fn for fn in fns if ((fn[0:-4] in train_ids) or (fn[0:-4] in val_ids))]
elif split == 'train':
fns = [fn for fn in fns if fn[0:-4] in train_ids] # Judge whether the txt file in the folder is in the training TXT. If so, the txt file obtained in fns is the file to be trained in all txt files in this category, and put it into fns
elif split == 'val':
fns = [fn for fn in fns if fn[0:-4] in val_ids]
elif split == 'test':
fns = [fn for fn in fns if fn[0:-4] in test_ids]
else:
print('Unknown split: %s. Exiting..' % (split))
exit(-1)
# print(os.path.basename(fns))
for fn in fns:
"The first i Secondary cycle fns What you get is the third i Training eligible in folders txt Folder name"
token = (os.path.splitext(os.path.basename(fn))[0])
self.meta[item].append(os.path.join(dir_point, token + '.txt')) # Generate a dictionary and combine the category name and the training path as the training data in a large class
#After the above code is executed, you can put all the data to be trained or verified into a dictionary. The key of the dictionary is the category to which the data belongs, such as aircraft. Value is the full path of its corresponding data
#{aircraft: [path 1, path 2.....]}
#####################################################################################################################################################
self.datapath = []
for item in self.cat: # self.cat is the dictionary corresponding to the category name and folder
for fn in self.meta[item]:
self.datapath.append((item, fn)) # Generate tuples of labels and point cloud paths, and convert the dictionary in self.met into a tuple
self.classes = {}
for i in self.cat.keys():
self.classes[i] = self.classes_original[i]
## self.classes corresponds the name and index of the category, such as aircraft < --- > 0
# Mapping from category ('Chair') to a list of int [10,11,12,13] as segmentation labels
"""
shapenet There are 16 categories, and then each category has some components, such as aircraft 'Airplane': [0, 1, 2, 3] Among them, the four sub categories labeled 0 1 2 3 belong to the category of aircraft
self.seg_classes Is to correspond the major class to the minor class
"""
self.seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],
'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46],
'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27],
'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40],
'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
# for cat in sorted(self.seg_classes.keys()):
# print(cat, self.seg_classes[cat])
self.cache = {} # from index to (point_set, cls, seg) tuple
self.cache_size = 20000
def __getitem__(self, index):
if index in self.cache: # The initial slef.cache is an empty dictionary, which is used to store the retrieved data and place it according to (point_set, cls, seg) while avoiding repeated sampling
point_set, cls, seg = self.cache[index]
else:
fn = self.datapath[index] # The path to get the training data according to the index self.datepath is a tuple (class name, path)
cat = self.datapath[index][0] # Get the class name
cls = self.classes[cat] # Convert class name to index
cls = np.array([cls]).astype(np.int32)
data = np.loadtxt(fn[1]).astype(np.float32) # size 20488,7 read in this txt file, a total of 20488 points, each point xyz rgb + sub category label
if not self.normal_channel: # Determine whether to use rgb information
point_set = data[:, 0:3]
else:
point_set = data[:, 0:6]
seg = data[:, -1].astype(np.int32) # Get the label of the sub category
if len(self.cache) < self.cache_size:
self.cache[index] = (point_set, cls, seg)
point_set[:, 0:3] = pc_normalize(point_set[:, 0:3]) # Make a normalization
choice = np.random.choice(len(seg), self.npoints, replace=True) # Random sampling of data in a category returns the index, allowing repeated sampling
# resample
point_set = point_set[choice, :] # Sample by index
seg = seg[choice]
return point_set, cls, seg # pointset is point cloud data, cls has 16 categories, and seg is a small category corresponding to different points in the data
def __len__(self):
return len(self.datapath)
if __name__ == '__main__':
import torch
root = r'D:\1Apython\Pycharm_pojie\3d\Pointnet_Pointnet2_pytorch-master\data\shapenetcore_partanno_segmentation_benchmark_v0_normal'
"Test it sharpnet data set"
data = PartNormalDataset(root=root)
DataLoader = torch.utils.data.DataLoader(data, batch_size=2, shuffle=False)
for point in DataLoader:
print('point0.shape:\n', point[0].shape) # ([2, 2500, 3])
print('point1.shape:\n', point[1].shape) # [2, 1]) labels of large parts
print('point2.shape:\n', point[2].shape) # torch.Size([2, 2500]) part category label, label of each point
#print('label.shape:\n', label.shape)
