preface
Requirement description
Use sharding JDBC to complete the horizontal division of the order table, and quickly experience the use method of sharding JDBC through the development of quick start program.
Create two tables manually, t_order_1 and t_order_2. These two tables are the tables after splitting the order table. Insert data into the order table through sharding JDBC. According to certain fragmentation rules, those with even primary key enter t_order_1. Another part of data enters t_order_2. Query the data through sharding JDBC, and start from t according to the content of SQL statement_ order_ 1 or t_order_2 query data.
1, Environment construction?
1 environmental description
- Operating system: Win10
- Database: MySQL-5.7.25
- JDK: 64 bit jdk1.8.0_ two hundred and one
- Application framework: spring-boot-2.1.3.RELEASE, mybatis 3.5.0
- Sharding-JDBC: sharding-jdbc-spring-boot-starter-4.0.0-RC1
Version is not mandatory
2 create database
Create order library order_db
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
In order_ Create t in DB_ order_ 1,t_ order_ Table 2
DROP TABLE IF EXISTS `t_order_1`; CREATE TABLE `t_order_1` ( `order_id` bigint(20) NOT NULL COMMENT 'order id', `price` decimal(10, 2) NOT NULL COMMENT 'Order price', `user_id` bigint(20) NOT NULL COMMENT 'Order user id', `status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'Order status', PRIMARY KEY USING BTREE (`order_id`) ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `t_order_2`; CREATE TABLE `t_order_2` ( `order_id` bigint(20) NOT NULL COMMENT 'order id', `price` decimal(10, 2) NOT NULL COMMENT 'Order price', `user_id` bigint(20) NOT NULL COMMENT 'Order user id', `status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'Order status', PRIMARY KEY USING BTREE (`order_id`) ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE utf8_general_ci ROW_FORMAT = Dynamic;
3. Introduce maven dependency
Jar package integrating sharding JDBC and SpringBoot is introduced:

<dependencies>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.0</version>
</dependency>
<dependency>
<groupId>javax.interceptor</groupId>
<artifactId>javax.interceptor-api</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-typehandlers-jsr310</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.mybatis.spring.boot</groupId>-->
<!-- <artifactId>mybatis-spring-boot-starter</artifactId>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>com.alibaba</groupId>-->
<!-- <artifactId>druid-spring-boot-starter</artifactId>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>mysql</groupId>-->
<!-- <artifactId>mysql-connector-java</artifactId>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>org.apache.shardingsphere</groupId>-->
<!-- <artifactId>sharding-jdbc-spring-boot-starter</artifactId>-->
<!-- </dependency>-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
</dependencies>
<distributionManagement>
<repository>
<id>maven-releases</id>
<name>maven-releases</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
<snapshotRepository>
<id>maven-snapshots</id>
<name>maven-snapshots</name>
<url>https://maven.aliyun.com/repository/snapshots</url>
</snapshotRepository>
</distributionManagement>
<build>
<finalName>${project.name}</finalName>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
<includes>
<include>**/*</include>
</includes>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<encoding>utf-8</encoding>
<useDefaultDelimiters>true</useDefaultDelimiters>
</configuration>
</plugin>
</plugins>
</build>
Refer to the dbsharding / sharding JDBC simple project in resources for specific spring boot dependencies and configurations. This guide only describes the contents related to sharding JDBC.
2, Programming
1. Partition rule configuration
Sharding rule configuration is an important basis for sharding JDBC to perform database and table operations. The configuration contents include data source, primary key generation strategy, sharding strategy, etc.
Configure in application.properties
server.port=56081
spring.application.name = sharding‐jdbc‐simple‐demo
server.servlet.context‐path = /sharding‐jdbc‐simple‐demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = UTF‐8
spring.http.encoding.force = true
spring.main.allow‐bean‐definition‐overriding = true
mybatis.configuration.map‐underscore‐to‐camel‐case = true
# The following is the partition rule configuration
# Define data source
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_dbuseUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = root
# Specify t_ Configure the data node according to the data distribution of the order table
spring.shardingsphere.sharding.tables.t_order.actual‐data‐nodes = m1.t_order_$‐>{1..2}
# Specify t_ The primary key generation strategy of the order table is SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key‐generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key‐generator.type=SNOWFLAKE
# Specify t_ The fragmentation strategy of order table includes fragmentation key and fragmentation algorithm
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.sharding‐column = order_id
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.algorithm‐expression = t_order_$‐>{order_id % 2 + 1}
# Open sql output log
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
logging.level.druid.sql = debug
1. First define the data source m1 and configure the actual parameters of m1.
2. Specify t_ Data distribution of order table, which is distributed in m1.t_order_1,m1.t_order_ two
3. Specify t_ The primary key generation strategy of order table is SNOWFLAKE. SNOWFLAKE is a distributed self increasing algorithm to ensure the global uniqueness of id
4. Definition t_order fragmentation strategy_ Data with an even ID falls in t_order_1. The odd number falls on t_order_2. The expression of table splitting strategy is
t_order_$->{order_id % 2 + 1}
2. Data operation
@Mapper
@Component
public interface OrderDao {
/*** New order
* @param price Order price
* @param userId User id
* @param status Order status
* @return
*/
@Insert("insert into t_order(price,user_id,status) value(#{price},#{userId},#{status})")
int insertOrder(@Param("price") BigDecimal price, @Param("userId")Long userId, @Param("status") String status);
/*** Query multiple orders by id list
* @param orderIds Order id list
* @return
*/
@Select({"<script>" + "select " + " * " + " from t_order t" +
" where t.order_id in " +
"<foreach collection='orderIds' item='id' open='(' separator=',' close=')'>" +
" #{id} " + "</foreach>" + "</script>"})
List<Map> selectOrderbyIds(@Param("orderIds")List<Long> orderIds);
}
3. Test
Write unit tests:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleDemoBootstrap.class})
public class OrderDaoTest {
@Autowired
private OrderDao orderDao;
@Test
public void testInsertOrder() {
for (int i = 0; i < 10; i++) {
orderDao.insertOrder(new BigDecimal((i + 1) * 5), 1L, "WAIT_PAY");
}
}
@Test
public void testSelectOrderbyIds() {
List<Long> ids = new ArrayList<>();
ids.add(373771636085620736L);
ids.add(373771635804602369L);
List<Map> maps = orderDao.selectOrderbyIds(ids);
System.out.println(maps);
}
}
Execute testInsertOrder:
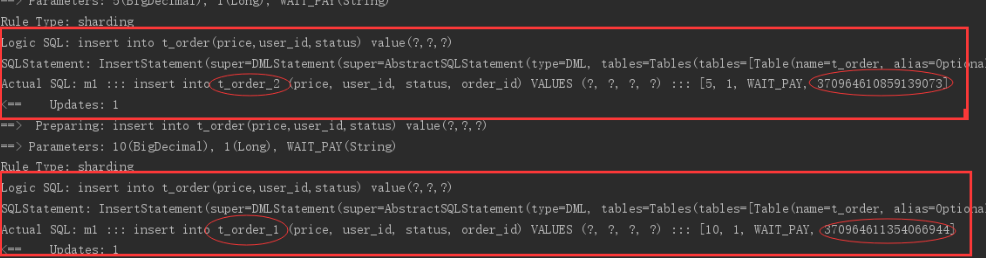
Order can be found through the log_ Odd ID is inserted into t_ order_ Table 2, even numbers are inserted into t_order_1 table to achieve the expected objectives.
Execute testSelectOrderbyIds:

Through the log, it can be found that according to the incoming order_ With different parity of IDS, sharding JDBC retrieves data from different tables to achieve the desired goal.
4. Process analysis
Through log analysis, what did sharding JDBC do after getting the sql to be executed by the user:
(1) Parse the sql to obtain the slice key value, in this case, order_id
(2) Sharding JDBC configures T through rules_ order_$-> {order_id% 2 + 1}, OK, when order_ When ID is an even number, it should go to t_order_1. Insert the data in the table. When it is an odd number, go to t_order_2 insert data.
(3) So sharding JDBC according to order_ The value of ID rewrites the SQL statement. The rewritten SQL statement is the real SQL statement to be executed.
(4) Execute the rewritten real sql statement
(5) Summarize and merge all the actual sql execution results and return.
5. Other integration methods
Sharding JDBC can not only integrate well with spring boot, but also support other configuration methods.
5.1 Spring Boot Yaml configuration
Define application.yml as follows:
server:
port: 56081
servlet:
context-path: /sharding-jdbc-simple-demo
spring:
application:
name: sharding-jdbc-simple-demo
http:
encoding:
enabled: true
charset: utf-8
force: true
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/order_db?useUnicode=true
username: root
password: mysql
sharding:
tables:
t_order:
actualDataNodes: m1.t_order_$->{1..2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_$->{order_id % 2 + 1}
keyGenerator:
type: SNOWFLAKE
column: order_id
props:
sql:
show: true
mybatis:
configuration:
map-underscore-to-camel-case: true
swagger:
enable: true
logging:
level:
root: info
org.springframework.web: info
com.itheima.dbsharding: debug
druid.sql: debug
3, Sharding JDBC execution principle
1. Basic concepts
Before understanding the execution principle of sharding JDBC, you need to understand the following concepts:
Logic table
The general name of a horizontally split data table. Example: the order data table is divided into 10 tables according to the mantissa of the primary key, which are t_order_0,t_order_1 to t_order_9. Their logical table is named t_order.
Real table
The smallest physical unit of data fragmentation. It consists of data source name and data table, for example: ds_0.t_order_0
Binding table
It refers to the main table and sub table with consistent fragmentation rules. For example: t_order table and t_order_item table, all according to order_id fragmentation, binding partitions between tables
If the keys are identical, the two tables are bound to each other. The Cartesian product association will not appear in the multi table Association query between bound tables, and the efficiency of association query will be high
Big promotion. For example, if the SQL is:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
When the binding table relationship is not configured, the sharding key order is assumed_ ID routes the value 10 to slice 0 and the value 11 to slice 1, then the SQL after routing
It should be 4 bars, which are presented as Cartesian Products:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
After configuring the binding table relationship, the route SQL should be 2:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
Broadcast table
It refers to the tables that exist in all partitioned data sources. The table structure and the data in the table are completely consistent in each database. It is applicable to scenarios with small amount of data and need to be associated with massive data tables, such as dictionary tables.
Slice key
The database field used for sharding is the key field to split the database (table) horizontally. Example: if the mantissa of the order primary key in the order table is taken as a module fragment, the order primary key is a fragment field. If there is no fragment field in SQL, full routing will be executed, and the performance is poor. In addition to the support for single sharding fields, Sharding- Jdbc also supports sharding according to multiple fields.
Partition algorithm
The data is segmented through the segmentation algorithm, and segmentation through =, between and IN is supported. The slicing algorithm needs to be implemented by the application developer, and the flexibility is very high. Including: accurate segmentation algorithm, range segmentation algorithm, composite segmentation algorithm, etc. For example: where order_id = ? The precise slicing algorithm will be used, where order_id in (?,?,?) will adopt the accurate segmentation algorithm, where order_id BETWEEN ? and ? Range slicing algorithm and composite slicing algorithm will be used IN multiple complex cases of slicing keys.
Partition strategy
It includes partition key and partition algorithm. Due to the independence of partition algorithm, it is separated independently. What can really be used for sharding operation is sharding key + sharding algorithm, that is, sharding strategy. The built-in fragmentation strategy can be roughly divided into mantissa modulus, hash, range, label, time, etc. The slicing strategy configured by the user side is more flexible. The commonly used line expression is used to configure the slicing strategy, which is expressed by Groovy expression, such as: t_user_$-> {u_id% 8} indicates t_user table according to u_ ID module 8 is divided into 8 tables, and the table name is t_user_0 to t_user_7 .
Auto increment primary key generation strategy
By generating self incrementing primary keys on the client to replace the original self incrementing primary keys of the database, there is no duplication of distributed primary keys.
2.SQL parsing
When sharding JDBC receives an SQL statement, it will successively execute SQL parsing = > query optimization = > sql routing = > sql rewriting = > sql execution = > result merging, and finally return the execution result.
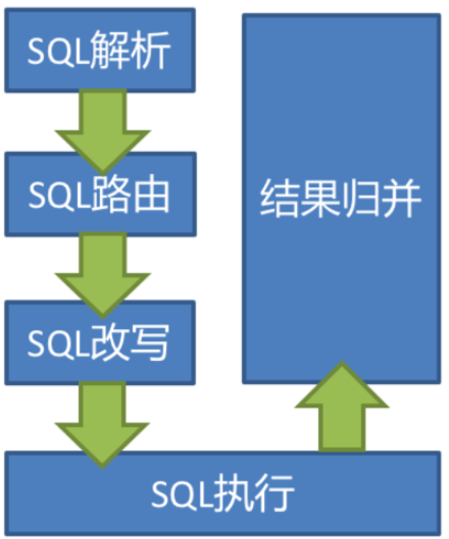
SQL parsing process is divided into lexical parsing and syntax parsing. The lexical parser is used to disassemble SQL into non separable atomic symbols, called tokens. And according to
Dictionaries provided by different database dialects are classified into keywords, expressions, literals and operators. Then use the syntax parser to convert the SQL into an abstract syntax tree.
3.SQL routing
SQL routing is the process of mapping data operations on logical tables to operations on data nodes.
Match the partition strategy of database and table according to the parsing context, and generate the routing path. According to different fragment key operators, SQL with fragment key can be divided into monolithic routing (the operator of fragment key is equal sign), multi fragment routing (the operator of fragment key is IN) and range routing (the operator of fragment key is BETWEEN). SQL without fragment key adopts broadcast routing. The scenarios of routing based on fragment keys can be divided into direct routing, standard routing, Cartesian routing, etc.
Standard routing
Standard routing is the sharding JDBC's most recommended fragmentation method. Its scope of application is SQL that does not contain associated queries or only contains associated queries BETWEEN bound tables. When the sharding operator is equal, the routing result will fall into a single database (table). When the sharding operator is BETWEEN or IN, the routing result may not fall into a unique database (table). Therefore, a logical SQL may eventually be split into multiple real SQL for execution. For example, if you follow order_ The odd and even numbers of ID are used for data fragmentation. The SQL of a single table query is as follows:
SELECT * FROM t_order WHERE order_id IN (1, 2);
Then the result of routing should be:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2); SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
The complexity and performance of associated queries with bound tables are equivalent to those of single table queries. For example, if the SQL of an associated query containing a bound table is as follows:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
Then the result of routing should be:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
You can see that the number of SQL splits is consistent with that of a single table.
Cartesian routing
Cartesian routing is the most complex case. It cannot locate fragmentation rules according to the relationship between bound tables. Therefore, the association query between unbound tables needs to be disassembled into Cartesian product combination for execution. If the SQL in the previous example does not configure the binding table relationship, the result of the route should be:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2); SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
Cartesian routing query has low performance and should be used with caution.
Full database table routing
For SQL without fragment key, broadcast routing is adopted. According to the SQL type, it can be divided into five types: full database table routing, full database routing, full instance routing, unicast routing and blocking routing. The full database table routing is used to handle the operations on all real tables related to their logical tables in the database, mainly including DQL (data query) and DML (data manipulation) without fragmentation key, DDL (data definition), etc. For example:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
It will traverse all tables in all databases, match the logical table and the real table name one by one, and execute if it can match. Become after routing
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10); SELECT * FROM t_order_1 WHERE good_prority IN (1, 10); SELECT * FROM t_order_2 WHERE good_prority IN (1, 10); SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
4.SQL rewriting
The SQL written by engineers for logical tables cannot be directly executed in the real database. SQL rewriting is used to rewrite logical SQL into SQL that can be correctly executed in the real database.
As a simple example, if the logical SQL is:
SELECT order_id FROM t_order WHERE order_id=1;
Suppose that the SQL is configured with the sharding key order_id and order_ If id = 1, it will be routed to fragment Table 1. The rewritten SQL should be:
SELECT order_id FROM t_order_1 WHERE order_id=1;
For another example, sharding JDBC needs to obtain the corresponding data when merging the results, but the data cannot be returned through the SQL query. This is mainly for group by and order by. When merging results, you need to group and sort according to the field items of group by and order by. However, if the selection items of the original SQL do not contain grouping items or sorting items, you need to overwrite the original SQL. Let's take a look at the scenario in the original SQL with the information required for result merging:
SELECT order_id, user_id FROM t_order ORDER BY user_id;
Due to the use of user_id to sort. In the result merging, you need to be able to get the user_id, and the above SQL can get user_id data, so there is no need to supplement columns.
If the selected item does not contain the columns required for result merging, supplementary columns are required, such as the following SQL:
SELECT order_id FROM t_order ORDER BY user_id;
Because the original SQL does not contain the user that needs to be obtained in the result merging_ ID, so the SQL needs to be supplemented and rewritten. The SQL after column supplement is:
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
5.SQL execution
Sharding JDBC adopts a set of automatic execution engine, which is responsible for sending the real SQL after routing and rewriting safely and efficiently to the underlying data source for execution. It does not simply send SQL directly to the data source through JDBC for execution; Nor does it directly put the execution request into the thread pool for concurrent execution. It pays more attention to balancing the consumption caused by data source connection creation and memory occupation, as well as maximizing the rational use of concurrency. The goal of the execution engine is to automatically balance resource control and execution efficiency. It can adaptively switch between the following two modes:
Memory limit mode
The premise of using this mode is that sharding JDBC does not limit the number of database connections consumed by one operation. If the actual SQL needs to operate on 200 tables in a database instance, create a new database connection for each table and process it concurrently through multithreading to maximize the execution efficiency.
Connection restriction mode
The premise of using this mode is that sharding JDBC strictly controls the number of database connections consumed for one operation. If the actually executed SQL needs to operate on 200 tables in a database instance, only a unique database connection will be created and its 200 tables will be processed serially. If the fragments in an operation are scattered in different databases, multithreading is still used to handle the operations on different databases, but each operation of each library still creates only one unique database connection.
The memory restriction mode is applicable to OLAP operation, and can improve the system throughput by relaxing the restrictions on database connection; The connection restriction mode is applicable to OLTP operation. OLTP usually has a partition key and will be routed to a single partition. Therefore, it is a wise choice to strictly control the database connection to ensure that the online system database resources can be used by more applications.
6 result merging
Combining multiple data result sets obtained from various data nodes into one result set and returning them to the requesting client correctly is called result merging.
The result merging supported by sharding JDBC can be divided into five types: traversal, sorting, grouping, paging and aggregation. They are combined rather than mutually exclusive
Relationship.
The overall structure of the merge engine is divided as follows.
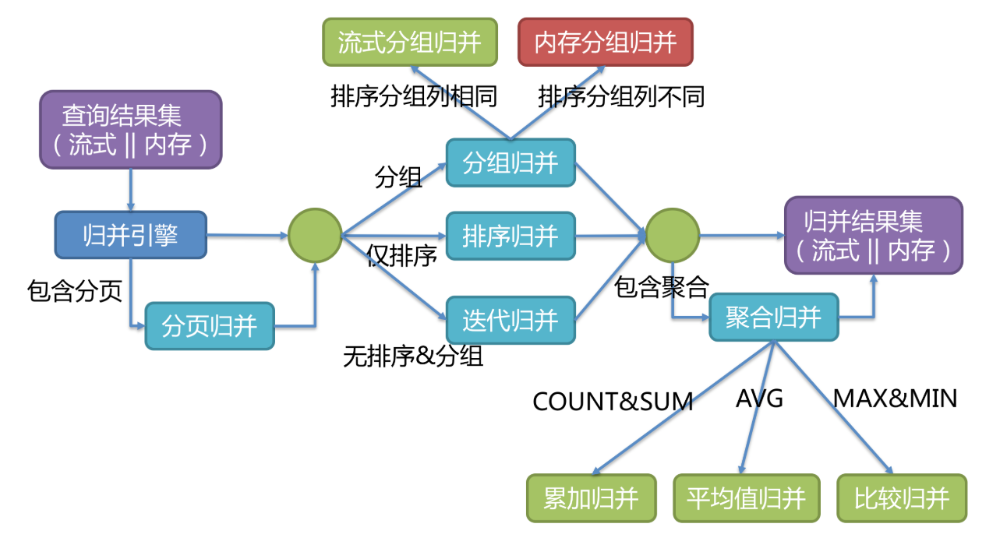
Results merging can be divided into stream merging, memory merging and decorator merging. Stream merge and memory merge are mutually exclusive. Decorator merge can be
Do further processing on stream merging and memory merging.
Memory merging is easy to understand. It traverses and stores the data of all fragment result sets in memory, and then through unified grouping, sorting and aggregation
After calculation, it is encapsulated into a data result set accessed one by one and returned.
Stream merging refers to that every time the data obtained from the database result set can return the correct single piece of data one by one through the cursor. It is most consistent with the original way of returning the result set of the database.
7 Summary
Through the above introduction, I believe you have understood the basic concept, core functions and implementation principle of sharding JDBC.
Basic concepts: logical table, real table, data node, binding table, broadcast table, sharding key, sharding algorithm, sharding strategy, and primary key generation strategy
Core functions: data fragmentation, read-write separation
Execution process: SQL parsing = > query optimization = > sql routing = > sql rewriting = > sql execution = > result merging
In the next chapter, we will demonstrate the practical use of sharding JDBC through demos.