There are many text processors or text editors in Linux/UNIX system, among which grep, sed and awk are commonly used text processing tools in shell programming. Therefore, they are widely called "Three Swordsmen in shell programming".
grep command tool
The grep command tool, which is often used in daily life, is not to mention here. If you have friends you don't understand, please refer to the blog: Explanation of regular expressions used by Shell scripts Which details the parameters and uses of the grep command.
sed command tool
Sed is a powerful and simple text parsing and conversion tool that reads text, edits its contents according to specified conditions, and outputs only certain lines of processing for all lines of life. sed can perform fairly complex text processing operations without interaction.It is widely used in shell scripts to accomplish a variety of automated processing tasks.
sed's workflow mainly includes: 1. Read: sed reads a line from the input stream and cannot be stored in a temporary buffer; 2. Execute: By default, all sed commands are executed sequentially in the mode space, unless the address of the line is specified, the SED command will execute sequentially on all the lines again. 3. Display: After sending the modified content to the output stream and then sending the data, the mode space will be emptied. Note: The above process repeats until all file contents are processed.
1) The syntax of sed command and related parameters:
sed [option]'action'parameter or sed [Options] -f scriptfile parameter
The main parameters of the common sed command options are:
Common operating parameters include:
2) Sample sed command usage (note that the following does not change the contents of the file itself, and must be modified with the'-i'option if necessary)
1. Output qualified text
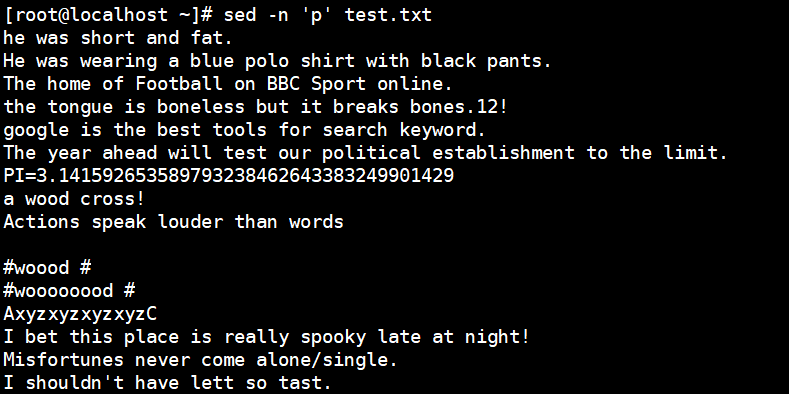
[root@localhost ~]# sed -n 'p' test.txt //Output everything, equivalent to "cat test.txt"
[root@localhost ~]# sed -n '3p' test.txt //Output the third line

[root@localhost ~]# sed -n '3,5p' test.txt //Output 3~5 rows

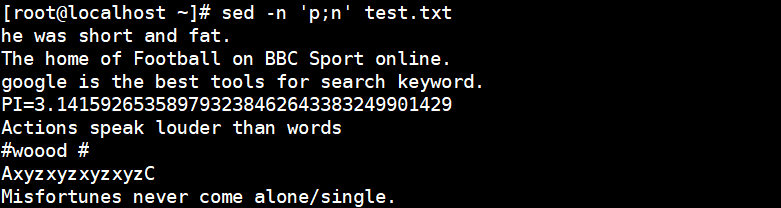
[root@localhost ~]# sed -n 'p;n' test.txt //Output all odd rows, n means read in the next row
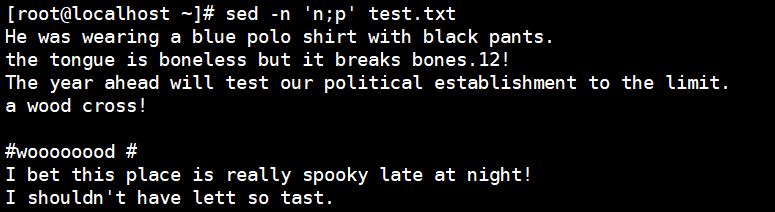
[root@localhost ~]# sed -n 'n;p' test.txt //Output all even rows, n means read in the next row
[root@localhost ~]# sed -n '1,5{p;n}' test.txt
//Output odd lines between lines 1 and 5 (lines 1, 3, 5)

[root@localhost ~]# sed -n '10,${n;p}' test.txt
//Output even lines (including empty lines) between line 10 and the end of the file

Case study of combining sed command with regular expression
The sed command combines regular expressions with slightly different formats, which are surrounded by'/'.
[root@localhost ~]# sed -n '/the/p' test.txt //Output line containing "the"

[root@localhost ~]# sed -n '4,/the/p' test.txt //Output from line 4 to the first line containing "the"

[root@localhost ~]# sed -n '/the/=' test.txt //The output contains the line number where the line containing the''is located (the equal sign (=) is used to output the line number)
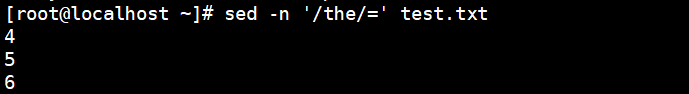
[root@localhost ~]# sed -n '/^PI/p' test.txt //Output lines starting with PI

[root@localhost ~]# sed -n '/\<wood\>/p' test.txt //Output lines containing the word wood, \<, \> representing word boundaries

2. Delete qualified text
The nl command calculates the number of lines in a file
[root@localhost ~]# nl test.txt | sed '3d' //Delete line 3
[root@localhost ~]# nl test.txt | sed '3,5d' //Delete lines 3-5
[root@localhost ~]# nl test.txt | sed '/cross/d' //Delete rows containing cross es, original 8th row deleted
[root@localhost ~]# nl test.txt | sed '/cross/! d' //Delete rows that do not contain cross es

[root@localhost ~]# sed '/\.$/d' test.txt
//Delete rows ending with'. '
[root@localhost ~]# sed '/^$/d' test.txt
//Delete all empty lines
[root@localhost ~]# sed -e '/^$/{n;/^$/d}' test.txt
//Delete empty rows, leaving one empty row in succession
3. Replace qualified text
The options you need to use for substitution with the sed command are s (string substitution), c (whole line/block substitution), y (character conversion), and so on.Since the test file does not meet the requirements, the following screenshots will not be taken.
[root@localhost ~]# sed 's/the/THE/' test.txt //Replace the first of each line with The [root@localhost ~]# sed 's/l/L/2' test.txt //Replace the third "l" in each line with "L" [root@localhost ~]# sed 's/the/THE/g' test.txt //Replace all "the" in the file with "THE" [root@localhost ~]# sed 's/o//g' test.txt //Delete all "o" from the file [root@localhost ~]# sed 's/^/#/' test.txt //Insert'#'at the beginning of each line [root@localhost ~]# sed '/the/s/^/#/' test.txt //Insert'#'at the beginning of each line containing'the' [root@localhost ~]# sed 's/$/EOF/' test.txt //Insert the string "EOF" at the end of each line [root@localhost ~]# sed '3,5s/the/THE/g' test.txt //Replace all "the" in lines 3-5 with "THE" [root@localhost ~]# sed '/the/s/o/O/g' test.txt //Replace o in all rows containing "the" with "O"
4. Migrate eligible text
The options needed to migrate text using the sed command are: g, G to overwrite/append data from the clipboard to the specified line; w to save as a file; r to read the specified file; a to append the specified content.
[root@localhost ~]# sed '/the/{H;d};$G' test.txt
//Migrate rows containing "the" to the end of the file, ";" for multiple operations
[root@localhost ~]# sed '1,5{H;d};17G' test.txt
//Move the contents of lines 1-5 after line 17
[root@localhost ~]# sed '/the/w out.file' test.txt
//Save the line containing "the" as a file out.file
[root@localhost ~]# sed '/the/r /etc/hostname' test.txt
//After adding the contents of the file/etc/hostname to each line containing "the"
[root@localhost ~]# sed '3aNEW' test.txt
//Insert a new line after line 3 with the content "NEW"
[root@localhost ~]# sed '/the/aNEW' test.txt
//Insert a new line after each line containing "the" with the content "NEW"
[root@localhost ~]# sed '3aNEW1\nNEW2' test.txt
//Multiple lines after line 3, with "\n" in the middle indicating a line break
5. Use scripts to edit files
Using the sed script, edit instructions are stored in a file (one tag instruction per line) and invoked with the'-f'option.
[root@localhost ~]# sed '1,5{H;d};17G' test.txt
//Move lines 1-5 after line 17
The above operations are converted to script files:
[root@localhost ~]# vim 1.list 1,5H 1,5d 17G [root@localhost ~]# sed -f 1.list test.txt
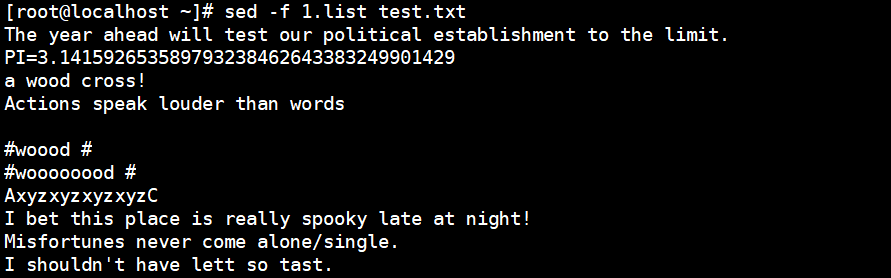
6.sed Direct Action File Example
Write a script to adjust the vsftpd service configuration: disallow anonymous users but allow local users (and write) to log on.
[root@localhost ~]# vim local_only_ftp.sh #!/bin/bash S="/usr/share/doc/vsftpd-3.0.2/EXAMPLE/INSERNET_SITE/vsftpd.conf" C="/etc/vsftpd/vsftpd.conf" #Specify Sample File Path, Profile Path [ ! -e "$C.bak" ] && cp $C $C.bak #Back up the original configuration file, check if (configuration file.bak) exists, or use the cp command to copy if it does not exist sed -e '/^anonymous_enable/s/YES/NO/g' $S > $C sed -i -e '/^local_enable/s/NO/YES/g' -e '/^write_enable/s/NO/YES/g' $C grep "listen" $C || sed -i '$alisten=YES' $A #Adjust based on sample configuration to overwrite existing files systemctl restart vsftpd systemctl enable vsftpd #Restart the ftp service and set it to boot-up and self-start
awk command tool
In Linux/UNIX systems, awk is a powerful editing tool that reads input text line by line, searches according to a specified matching pattern, formats and outputs qualified content or filters it. It can perform quite complex text operations without interaction and is widely used in Shell footers.This completes various automation configuration tasks.
1. Syntax and overview of awk command
awk option'mode or condition {edit instructions}'file 1 file 2...
//Filter and output qualified contents of the file
Awk-f script file file file 1 file 2...
//Invoke editing instructions from scripts, filter and output content*The result of awk execution can be printed and displayed by the print function.Logical operators'&'and'||' can be used during the use of awk commands;
Simple mathematical operations can also be performed, such as +, -, /,%, ^ for addition, subtraction, multiplication, division, redundancy, and multiplication, respectively.**
Awk reads information from an input file or standard input, and like sed, information is read line by line.The difference is that the awk command treats a line in a text file as a record and a part (column) of the line as a field of the record.To manipulate these different fields (columns), awk borrows a location variable-like method from the shell, using $1, $2...The order of $9 represents different columns and $0 represents the entire row.Different fields can be separated from different fields in a specified way, and the awk default separator is a space.The awk command allows you to specify a separator in the form of a'-F separator'.
The awk command processes the /etc/passwd file as shown in the following figure: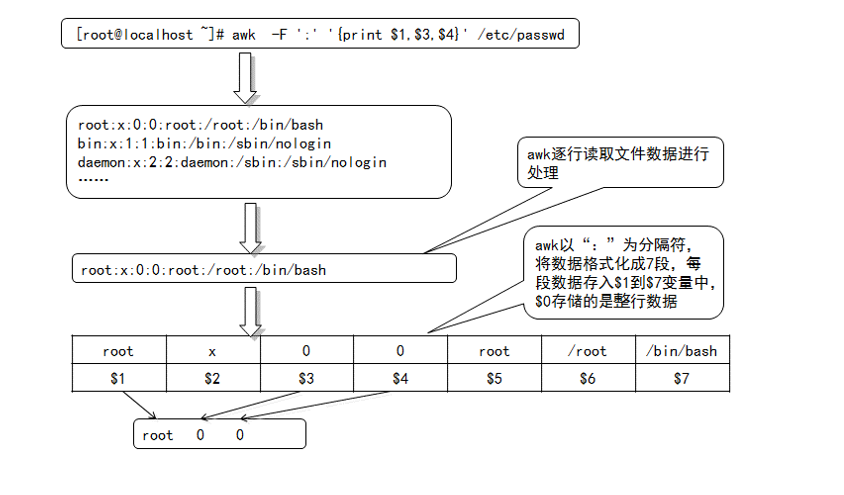
awk contains several special built-in variables, such as:
2.Example awk command usage
1) Output text by line
[root@localhost ~]# awk '{print}' test.txt
//Output everything, equivalent to "cat test.txt"
[root@localhost ~]# awk '{print $0}' test.txt
//Output everything, equivalent to "cat test.txt"
[root@localhost ~]# awk 'NR==1,NR==3{print}' test.txt
//Output lines 1~3
[root@localhost ~]# awk '(NR>=1) && (NR<=3) {print}' test.txt
//Output lines 1~3
[root@localhost ~]# awk 'NR==1 || NR==3{print}' test.txt
//Output lines 1 and 3
[root@localhost ~]# awk '(NR%2)==1 {print}' test.txt
//Output the contents of all odd rows
[root@localhost ~]# awk '(NR%2)==0 {print}' test.txt
//Output the contents of all even rows
[root@localhost ~]# awk '/^root/{print}' /etc/passwd
//Output lines starting with "root"
[root@localhost ~]# awk '/nologin$/{print}' /etc/passwd
//Output lines ending with "nologin"
[root@localhost ~]# awk 'BEGIN {x=0} ;/\/bin\/bash$/{x++};END {print x}' /etc/passwd
//Count rows ending in/bin/bash
[root@localhost ~]# grep -c "/bin/bash$" /etc/passwd
//Count rows ending in/bin/bash
[root@localhost ~]# awk 'BEGIN{RS=""}; END{print NR}' /etc/squid/squid.conf
//Count the number of space-delimited file paragraphs
Note: Use "BEGIN...END"
2) Output text by field
[root@localhost ~]# awk '{print $3}' test.txt
//Output the third field in each row separated by spaces
[root@localhost ~]# awk '{print $1,$3}' test.txt
//Output the first and third fields in each row separated by spaces
[root@localhost ~]# awk -F ":" '$2==""{print}' /etc/shadow
//Second field in output/etc/shadow file (separated by':') (user with empty password)
[root@localhost ~]# awk 'BEGIN {FS=":"}; $2=""{print}' /etc/shadow
//Second field in output/etc/shadow file (separated by':') (user with empty password)
[root@localhost ~]# awk -F ":" '$7~"/bash"{print $1}' /etc/passwd
//Output is separated by':'and the first field of the row containing'/bash' in the 7th field
[root@localhost ~]# awk '($1~"nfs") && (NF==8) {print $1,$2}' /etc/services
//Output contains eight fields and the first field contains the first and second fields of rows with "nfs"
[root@localhost ~]# awk -F ":" '($7!="/bin/bash") && ($7!="/sbin/nologin") {print}' /etc/passwd
//Output field 7 is neither'/bin/bash'nor'/bin/nologin' for all rows
3) Call Shell commands through pipes with double quotes
[root@localhost ~]# awk -F: '/bash$/{print | "wc -l"}' /etc/passwd
//Call the'wc-l'command to count the number of users using'bash'
[root@localhost ~]# grep -c "bash$" /etc/passwd
//Same as previous command
[root@localhost ~]# awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}}'
//Call the "w" command and count the number of online users
[root@localhost ~]# awk 'BEGIN { "hostname" | getline ; print $0}'
//Call the "hostname" command and output the current user name
4) Simple mathematical operations using awk commands
[root@localhost ~]# awk 'BEGIN{ a=6;b=3;print"(a + b)=",(a + b)}'
(a + b)= 9
[root@localhost ~]# awk 'BEGIN{ a=6;b=3;print"(a - b)=",(a - b)}'
(a - b)= 3
[root@localhost ~]# awk 'BEGIN{ a=6;b=3;print"(a / b)=",(a / b)}'
(a / b)= 2
[root@localhost ~]# awk 'BEGIN{ a=6;b=3;print"(a % b)=",(a % b)}'
(a % b)= 0
For more detailed awk commands, you can refer to the blog post: awk learning