
Competition background
In recent years, with the expansion of onshore wind turbine assembly sites, wind turbines installed in areas with more abrupt weather changes are more and more significantly affected by meteorological changes. In case of sudden change of wind conditions, due to the lag of the control system, it is easy to lead to excessive load or even switching of the unit, resulting in significant economic losses. At the same time, the accuracy of the existing ultra short-term wind power prediction is poor, which leads to the low reference value of the wind power prediction system for power grid dispatching, and will lead to a large number of power generation plan assessment by the owner. Due to the high unit price of common wind speed measurement products such as lidar, which are greatly affected by the weather, it is difficult to realize batch application deployment, and it is still difficult to be reliable and forward-looking on a large time and space scale. Therefore, reliable ultra short-term wind condition prediction is imminent.
Ultra short term wind condition prediction is a worldwide problem. If we can predict the wind speed and direction data of each unit in a short time in the future through big data and artificial intelligence technology, we can improve the control foresight of wind turbine and improve the load safety of wind turbine; At the same time, the improvement of the existing ultra short-term wind power prediction ability will bring significant safety value and economic benefits.
This competition is jointly sponsored by the people's Government of Shenzhen Baoan District and China information and Communication Research Institute. It provides real data and scenes from industrial production. It is hoped to combine industrial and AI big data to solve the challenges faced in actual production tasks.
Data analysis
Training set description
Training data of two wind farms for two years:
- 25 wind turbine units in each wind farm, providing the engine room wind speed, wind direction, temperature, power and corresponding hourly meteorological data of each unit; 2. The fan number of wind farm 1 is x26-x50, and the data range of training set is 2018 and 2019; 3. The fan number of wind farm 2 is x25-x49, and the data range of training set is 2017 and 2018; 4. The data files of each unit are based on / training set / [wind farm] / [unit] / [date] csv storage;
- The meteorological data is stored in the / training set / [wind farm] folder.
Test set description
- The test set is divided into two folders: the preliminary and final of the test set. The folder organization form of the preliminary and final is the same;
- The preliminary and final folders each include 80 periods of data, 1 hour data (30S resolution, time expressed in seconds) in each period, 20 periods in spring, summer, autumn and winter, preliminary No. 1-20 and final No. 21-40; That is, the period number of the preliminary is spring_ 01 winter_ 20, 80 in total; The final session number is spring_ 21 winter_ 40, 80 in total;
- The data files of each unit are in accordance with the / test set_**/ [wind farm] / [unit] / [time period] csv storage;
- Meteorological data is stored in the / test set_**/ Under the [wind farm] / folder, the wind speed and direction data of the wind farm location in 80 periods, and each period provides the wind speed and direction data of the past 12 hours and the next 1 hour. The time period code is the same as above, and the time code is - 11 ~ 2, in which the hour 0 ~ 1 exactly corresponds to the one hour data of the engine room.

The above figure shows the division method of test set data. The data accumulated in the time period of - 11 ~ 1 is used as the input of the model to predict the wind speed and direction in the next 10 minutes (between 1 ~ 2).
Missing value
The missing values in the data mainly come from two aspects: one is the lack of data records on the day, and the other is the lack of data in some time periods. A variety of missing conditions lead to missing problems when filling data. Filling missing values in only one way will lead to missing filling of missing values. Therefore, we used forward fill, backward fill and mean fill at the same time in the competition to ensure the filling coverage. Such processing may introduce noise, but the neural network has a certain tolerance for noise, so the final training effect is not affected much. Considering that there may be missing data in training data and future test data, and their recording methods are the same, we did not remove the data with missing values, and used the same filling method for them to avoid the inconsistency of data distribution due to different preprocessing.
Introduction to model ideas
model structure
In the competition, we adopt the model in the form of Encoder Decoder, mine the information in the input sequence through the sequence model, and then predict through the Decoder. There are many options for Encoder and Decoder here, such as the common sequence model LSTM, or Transformer, which has sprung up in recent years. In the competition, we stacked multiple layers of LSTM on the Decoder side, and only one layer of LSTM was used on the Encoder side. Dropout is not added to the model for regularization, considering that there is a large amount of high-frequency noise in the data itself. Adding dropout will lead to slow convergence of the model and affect the training efficiency of the model. We used the propeller frame to build the model structure, and later found the official natural language processing model library paddelnlp( https://github.com/PaddlePaddle/PaddleNLP )It provides convenient data processing API, rich network structure and pre training model, as well as various NLP application examples such as classification and generation. It is very suitable for playing games and will be considered for use in the future.
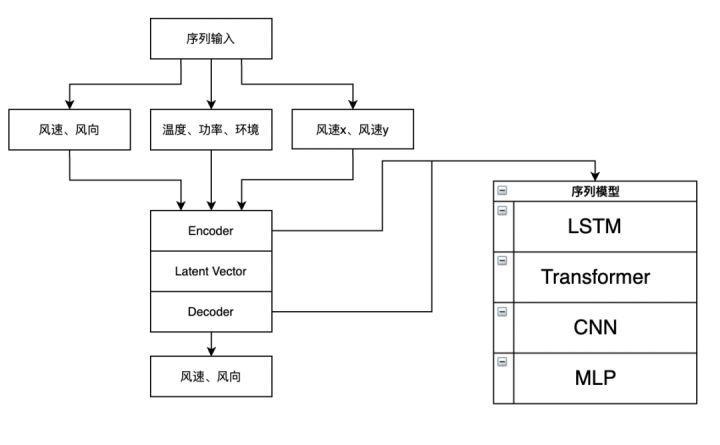
The code of the final model structure constructed using the propeller frame is as follows:
class network(nn.Layer):
def __init__(self, name_scope='baseline'):
super(network, self).__init__(name_scope)
name_scope = self.full_name()
self.lstm1 = paddle.nn.LSTM(128, 128, direction = 'bidirectional', dropout=0.0)
self.lstm2 = paddle.nn.LSTM(25, 128, direction = 'bidirectional', dropout=0.0)
self.embedding_layer1= paddle.nn.Embedding(100, 4)
self.embedding_layer2 = paddle.nn.Embedding(100, 16)
self.mlp1 = paddle.nn.Linear(29, 128)
self.mlp_bn1 = paddle.nn.BatchNorm(120)
self.bn2 = paddle.nn.BatchNorm(14)
self.mlp2 = paddle.nn.Linear(1536, 256)
self.mlp_bn2 = paddle.nn.BatchNorm(256)
self.lstm_out1 = paddle.nn.LSTM(256, 256, direction = 'bidirectional', dropout=0.0)
self.lstm_out2 = paddle.nn.LSTM(512, 128, direction = 'bidirectional', dropout=0.0)
self.lstm_out3 = paddle.nn.LSTM(256, 64, direction = 'bidirectional', dropout=0.0)
self.lstm_out4 = paddle.nn.LSTM(128, 64, direction = 'bidirectional', dropout=0.0)
self.output = paddle.nn.Linear(128, 2, )
self.sigmoid = paddle.nn.Sigmoid()
# Forward calculation function of network
def forward(self, input1, input2):
embedded1 = self.embedding_layer1(paddle.cast(input1[:,:,0], dtype='int64'))
embedded2 = self.embedding_layer2(paddle.cast(input1[:,:,1]+input1[:,:,0] # * 30
, dtype='int64'))
x1 = paddle.concat([
embedded1,
embedded2,
input1[:,:,2:],
input1[:,:,-2:-1] * paddle.sin(np.pi * 2 *input1[:,:,-1:]),
input1[:,:,-2:-1] * paddle.cos(np.pi * 2 *input1[:,:,-1:]),
paddle.sin(np.pi * 2 *input1[:,:,-1:]),
paddle.cos(np.pi * 2 *input1[:,:,-1:]),
], axis=-1) # 4+16+5+2+2 = 29
x1 = self.mlp1(x1)
x1 = self.mlp_bn1(x1)
x1 = paddle.nn.ReLU()(x1)
x2 = paddle.concat([
embedded1[:,:14],
embedded2[:,:14],
input2[:,:,:-1],
input2[:,:,-2:-1] * paddle.sin(np.pi * 2 * input2[:,:,-1:]/360.),
input2[:,:,-2:-1] * paddle.cos(np.pi * 2 * input2[:,:,-1:]/360.),
paddle.sin(np.pi * 2 * input2[:,:,-1:]/360.),
paddle.cos(np.pi * 2 * input2[:,:,-1:]/360.),
], axis=-1) # 4+16+1+2+2 = 25
x2 = self.bn2(x2)
x1_lstm_out, (hidden, _) = self.lstm1(x1)
x1 = paddle.concat([
hidden[-2, :, :], hidden[-1, :, :],
paddle.max(x1_lstm_out, axis=1),
paddle.mean(x1_lstm_out, axis=1)
], axis=-1)
x2_lstm_out, (hidden, _) = self.lstm2(x2)
x2 = paddle.concat([
hidden[-2, :, :], hidden[-1, :, :],
paddle.max(x2_lstm_out, axis=1),
paddle.mean(x2_lstm_out, axis=1)
], axis=-1)
x = paddle.concat([x1, x2], axis=-1)
x = self.mlp2(x)
x = self.mlp_bn2(x)
x = paddle.nn.ReLU()(x)
# decoder
x = paddle.stack([x]*20, axis=1)
x = self.lstm_out1(x)[0]
x = self.lstm_out2(x)[0]
x = self.lstm_out3(x)[0]
x = self.lstm_out4(x)[0]
x = self.output(x)
output = self.sigmoid(x)*2-1
output = paddle.cast(output, dtype='float32')
return outputThere are many ways for the propeller frame to train the model. Like other deep learning frames, it can be trained by gradient return, or by using the highly encapsulated API. When using high-level API training, we need to prepare the data generator and model structure. The generator in the propeller frame is packaged in the following way, with high efficiency:
class TrainDataset(Dataset):
def __init__(self, x_train_array, x_train_array2, y_train_array=None, mode='train'):
# Number of samples
self.training_data = x_train_array.astype('float32')
self.training_data2 = x_train_array2.astype('float32')
self.mode = mode
if self.mode=='train':
self.training_label = y_train_array.astype('float32')
self.num_samples = self.training_data.shape[0]
def __getitem__(self, idx):
data = self.training_data[idx]
data2 = self.training_data2[idx]
if self.mode=='train':
label = self.training_label[idx]
return [data, data2], label
else:
return [data, data2]
def __len__(self):
# Return the total number of samples
return self.num_samplesAfter preparing the generator, you can directly use the fit interface for training:
model = paddle.Model(network(), inputs=inputs)
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.002,
parameters=model.parameters()),
loss=paddle.nn.L1Loss(),
)
model.fit(
train_data=train_loader,
eval_data=valid_loader,
epochs=10,
verbose=1,
)Optimize pipeline
For the data of different fans, we extract features in the same way, so we can use python's Parallel library to further optimize the performance of the code and improve the efficiency of iteration. The core code is as follows:
# Generate training data
def generate_train_data(station, id):
df = read_data(station, id, 'train').values
return extract_train_data(df)
# The training set is generated by parallel operation
train_data = []
for station in [1, 2]:
train_data_tmp = Parallel(n_jobs = -1, verbose = 1)(delayed(lambda x: generate_train_data(station, x))(id) for id in tqdm(range(25)))
train_data = train_data + train_data_tmpThe efficiency improved here is directly proportional to the number of CPU cores. In the competition, we used 8-core CPU, so we can improve the efficiency of data generation by 8 times.
Problem of fitting wind direction
The prediction label of this competition includes wind speed and wind direction. For the wind direction, because the angle is circular, we have
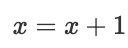
The evaluation function is MAE. In the training stage, there will be problems in directly predicting the wind direction, because 0 and 1 represent the same meaning. When the wind direction is 0 / 1, the model predicts their mean value of 0.5, resulting in error. Here, we convert the wind direction and angle into the component of the wind direction in the vertical direction to avoid directly predicting the wind direction and avoiding the problems caused by fitting the wind direction.
Dealing with noise
After ranking first in the A list, we try to deal with the noise in the data. Due to the high risk of processing the input side, it is easy to erase the effective signal in the input feature, so we choose to smooth the label. We make A weighted average between the predicted value of the model and the original label, and then use the smoothed new label for training to achieve an improvement of 0.1 points in the A list.
experimental result
The score of the competition is calculated as follows:
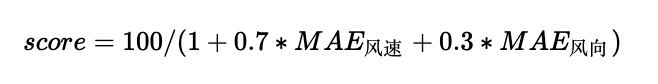
Among them,
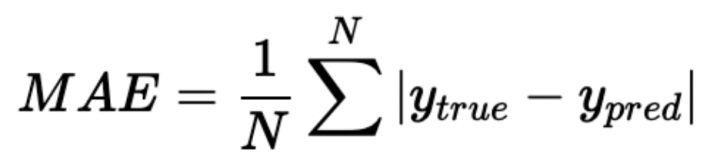
Is the average absolute error. The experimental results are shown in the table below. It is not difficult to find that the improvement of competition results mainly comes from the processing of data and labels, which are also the two elements we should pay most attention to in modeling.
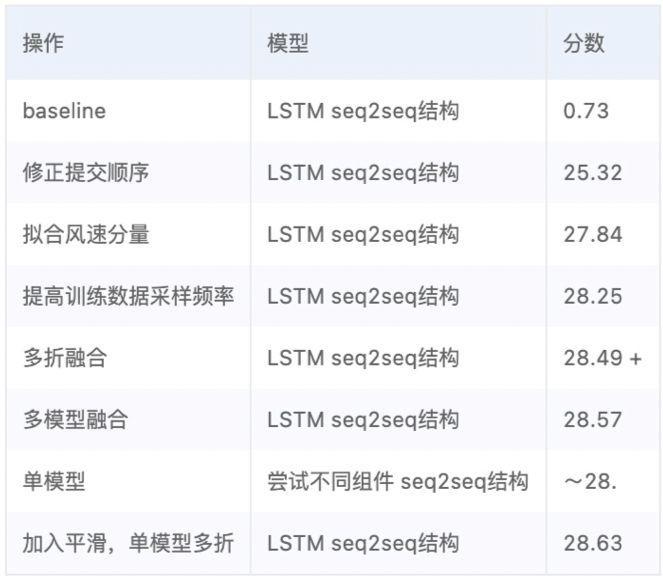
Post game thoughts
In this industrial big data competition, we won the second prize in both the wind condition prediction track and the heavy parts demand prediction track. Through this competition, we found that the data quality in the industrial scene may not be ideal, and the missing value and noise need to be handled carefully. When dealing with the task of time series prediction, the accumulation of historical data may not include the emergencies encountered in the future. Relying only on the model may have large deviation, which is also a problem that we need to pay special attention to in modeling.
studio project link: https://aistudio.baidu.com/aistudio/projectdetail/3260925 Paddle address: https://github.com/PaddlePaddle/Paddle PaddleNLP address: https://github.com/PaddlePaddle/PaddleNLP
reference
[1] Industrial big data industrial innovation platform https://www.industrial-bigdata.com/