Problem classification and introduction
n represents the number of points and m represents the number of edges
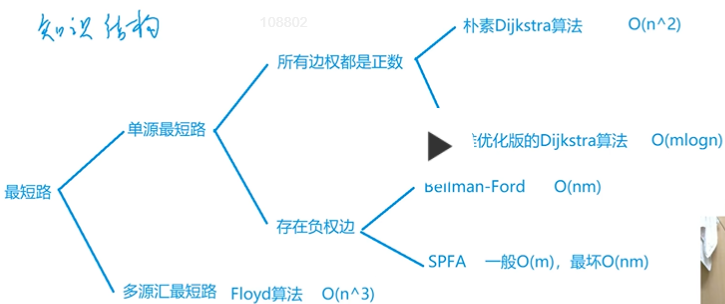
The focus of the investigation of the shortest path problem in the algorithm problem is not to prove the correctness of the algorithm, and the principle requirements of the algorithm are not high. The focus of the investigation is how to build a graph according to the problem background and abstract the problem into the shortest path problem in graph theory.
Naive dijkstra algorithm
Application occasion
Single source shortest circuit
All edge weights are positive
Dense graphs with fewer points but more edges (when m and n2 are at the same level)
Algorithm complexity
O(n2)
Algorithm idea
Because it is a sparse graph, the adjacency matrix is used to store the graph

Template code
//Title Background: AcWing 849
int g[N][N]; //adjacency matrix
int dist[N]; //Distance between recording point and source point
bool st[N]; //Mark whether the point has been applied
int dijkstra()
{
memset(dist,0x3f,sizeof(dist));
st[1]=true; //Mark source point as active
for(int i=2;i<=n;i++) dist[i]=g[1][i]; //Initialize the distance between all points and the source point
for(int i=1;i<=n-1;i++) //In addition to the source point, there are n-1 points not judged
{
int t=-1;
for(int j=1;j<=n;j++) //Find the point with the shortest distance from the source point in the current undecided set
if(!st[j]&&(t==-1||dist[t]>dist[j]))
t=j;
st[t]=true; //Mark as activated
for(int j=1;j<=n;j++)
if(!st[j]) //Update the distance of the point
dist[j]=min(dist[j],dist[t]+g[t][j]);
if(t==n) //If point n has been used, jump out directly. Here is a special case of the problem
break;
} //After the cycle is completely completed, dist[i] represents the shortest distance from the source point to point I
if(dist[n]==0x3f3f3f3f) return -1;
else
return dist[n];
}
dijkstra algorithm for heap optimization
Application occasion
Single source shortest circuit
All edge weights are positive
Sparse graph
Algorithm complexity
O(mlogn)
Algorithm idea
Because it is a sparse graph, it is stored in the adjacency table
In dijkstra algorithm, the complexity of the algorithm is large when finding the point with the smallest dist every time
We maintain dist array with heap to reduce the complexity to O (m), which is linear
Here, we use the priority queue in STL to maintain. Since the priority queue has no modification function, we directly add a new one to it to allow redundancy. We can borrow the st array to judge whether it has been accessed.
Template code
//Title Background: AcWing 850
const int N=1000010;
int n,m;
int h[N],e[N],ne[N],w[N],idx; //e stores the point on the other side of the edge and w stores the weight of this edge
int dist[N]; //dist[i] indicates the distance from point I to the source point
bool st[N]; //Mark whether the point has been selected
typedef pair<int,int> PII;
int dijkstra()
{
memset(dist,0x3f,sizeof(dist)); //All distances are initialized to infinity
dist[1]=0;
priority_queue<PII, vector<PII>, greater<PII>> q; //Priority queue
q.push({0,1}); //Throw the used points into the pile
//In this way, you can directly find the minimum distance in the heap
while(!q.empty())
{
auto t=q.top(); //Take out the top element of the small top heap, which is the minimum value
q.pop();
int ver=t.second,distance=t.first;
if(st[ver]) continue; //Because there is redundancy, it is necessary to judge whether it has worked
st[ver]=true;
for(int i=h[ver];i!=-1;i=ne[i]) //Update the distance between the adjacent points of the point ver and the source point
{
int j=e[i];
if(dist[j]>dist[ver]+w[i])
{
dist[j]=dist[ver]+w[i];
q.push({dist[j],j}); //Add it directly without deleting it, which brings redundancy
}
}
if(ver==n) //If point n has been used, jump out directly. Here is a special case of the problem
break;
}
if(dist[n]==0x3f3f3f3f) return -1;
else return dist[n];
}
Bellman Ford algorithm
Application occasion
Existence of negative edge weight
Limit the number of edges on the path (i.e. the number of iterations of the outermost for loop)
Algorithm complexity
O(nm)
Algorithm idea

The outermost loop (number of iterations) n indicates that the source point passes through at most N edges to the end point
Template code
//Title Background AcWing 853
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 510, M = 10010;
struct Edge
{
int a, b, c;
}edges[M];
int n, m, k;
int dist[N];
int last[N]; //The last array holds the dist result of the last iteration
//Otherwise, only the dist array itself is used, and concatenation is likely to occur during update
void bellman_ford()
{
memset(dist, 0x3f, sizeof dist); //Initialize dist distance array to infinity
dist[1] = 0; //Source distance is 0
for (int i = 0; i < k; i ++ ) //Iterate K times, which means passing through k edges
{
memcpy(last, dist, sizeof dist); //Copy the dist after the last iteration to last and save it
for (int j = 0; j < m; j ++ ) //Traverse each edge
{
auto e = edges[j];
dist[e.b] = min(dist[e.b], last[e.a] + e.c); //To update the dist of the sink of each edge
}
}
}
int main()
{
scanf("%d%d%d", &n, &m, &k);
for (int i = 0; i < m; i ++ )
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
edges[i] = {a, b, c};
}
bellman_ford(); //Call algorithm
if (dist[n] > 0x3f3f3f3f / 2) puts("impossible"); //Why > 0x3f3f3f3f3f / 2 is enough, because the initial value 0x3f3f3f3f3f may be changed by adding or subtracting any value in the calculation process. The accurate judgment with = = is not accurate enough, it is more than half
else printf("%d\n", dist[n]);
return 0;
}
SPFA algorithm
Application occasion
Single source shortest path, with negative weight edge
It is required that the path cannot contain negative rings (99% of the shortest path problems do not have negative rings)
ps: spfa algorithm can also be used when all edge weights are positive, and the speed is also very fast. If it can't be used, replace it with another one
Algorithm complexity
In general: O (m)
Worst case: O (nm)
Algorithm idea

SPFA algorithm is actually the optimization of Bellman Ford algorithm.
Bellman_ford algorithm will traverse all edges, but there are many edges. In fact, it is meaningless. We only traverse the edges connected by the points whose distance to the source point becomes smaller. Only when the precursor node of a point is updated, the node will be updated; Therefore, with this in mind, we will create a queue to join the node whose distance is updated each time.
- The function of st array: judge whether the current point has been added to the queue; Nodes that have joined the queue do not need to repeatedly add the point to the queue. Even if the distance to the source point will be updated this time, only update the value instead of joining the queue.
Even if you don't use the st array, it doesn't matter in the end, but the advantage of using it is that it can improve efficiency.
SPFA algorithm looks a little like Dijstra algorithm, but its meaning is still very different:
- The st array in Dijkstra algorithm saves the point with the minimum distance from the source point, and once the minimum is determined, it is irreversible (it cannot be marked as true and changed to false);
The st array in SPFA algorithm only represents the current updated point, and the st array in SPFA is reversible (it can be marked as true and then false). Incidentally, the st array in BFS records the points that have been traversed - Dijkstra algorithm uses the priority queue to save the points with the current undetermined minimum distance, in order to quickly extract the points with the current minimum distance to the source point; The SPFA algorithm uses queues (you can also use other data structures) to record the current update points.
- Bellman_ The judgment condition of the last return-1 in the Ford algorithm is dist [n] > 0x3f3f3f3f / 2; The SPFA algorithm writes dist[n]==0x3f3f3f3f; The reason is Bellman_ford algorithm will traverse all edges, so it will be updated whether it is the edge connected with the source point or not; But the SPFA algorithm is different. It is equivalent to using BFS, so the traversed nodes are connected with the source point. Therefore, if the n you require is not connected with the source point, it will not be updated, but it will remain 0x3f3f3f.
- Bellman_ford algorithm can have a negative weight loop because the number of cycles is limited, so there will be no life and death cycle in the end; However, the SPFA algorithm cannot be used. Because it is stored in a queue, it will continue to join the queue as long as updates occur. Therefore, if there is a negative weight loop, please do not use SPFA, otherwise it will be dead circulation.
- Since the SPFA algorithm is developed by Bellman_ford algorithm is optimized. In the worst case, the time complexity is the same as it, that is, the time complexity is O(nm). If the problem time allows, you can directly use SPFA algorithm to solve the problem of Dijkstra algorithm. (it seems that SPFA feels a little omnipotent?)
Template code
//Title Background: AcWing 851
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N=100010;
int h[N],e[N],ne[N],w[N],idx;
bool st[N];
int dist[N];
int n,m;
void add(int a,int b,int c)
{
e[idx]=b;
w[idx]=c;
ne[idx]=h[a];
h[a]=idx++;
}
int spfa()
{
memset(dist,0x3f,sizeof(dist));
dist[1]=0;
queue<int> q;
q.push(1);
//st[1]=true;
while(!q.empty())
{
int t=q.front();
q.pop();
st[t]=false;//After the node st is taken out of the queue, it is marked as false, which means that if the node is updated later, it can join the queue again
for(int i=h[t];i!=-1;i=ne[i])
{
int j=e[i];
if(dist[j]>dist[t]+w[i])
{
dist[j]=dist[t]+w[i];
if(!st[j])//Nodes that have joined the queue do not need to join the queue again. Even if they are updated, they can only update the value. Repeated addition reduces efficiency
{
q.push(j);
st[j]=true;
}
}
}
}
return dist[n];
}
int main()
{
memset(h,-1,sizeof(h));
scanf("%d%d",&n,&m);
while(m--)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
}
int t=spfa();
if(t==0x3f3f3f3f) printf("impossible");
else printf("%d",dist[n]);
return 0;
}
Using SPFA algorithm to judge negative loop
The SPFA algorithm is generally used to find the negative ring. The method is to use a cnt array to record the number of edges from each point to the source point. If a point is updated once, it will be + 1. Once the number of edges of a point reaches n, it is proved that there is a negative ring.
It must be correct to do spfa() every time, but the time complexity is high and may timeout. Initially, all points are inserted into the queue, which can be understood as follows:
Create a new virtual source point on the basis of the original graph, and connect a directed edge with weight 0 from this point to all other points. Then the original graph with negative rings is equivalent to the new graph with negative rings. At this time, do spfa on the new graph and add the virtual source point to the queue. Then the first iteration of spfa will be carried out. At this time, the distance of all points will be updated and all points will be inserted into the queue. At this point, it is equivalent to the practice in the video. Then the method in the video can find negative rings, which is equivalent to that spfa can find negative rings this time, which is equivalent to that the new graph has negative rings, and that the original graph has negative rings. Get a certificate.
- 1. dist[x] records the shortest distance from the virtual source point to X
- 2. cnt[x] records the number of the shortest path edges from the current point x to the virtual source point. The initial distance from each point to the virtual source point is 0. As long as it can take another n steps, that is, cnt[x] > = n, it means that there must be a negative ring in the figure. When at least n edges pass from the virtual source point to x, it means that there are at least n + 1 points in the figure, which means that some points must be reused
- 3. If dist [j] > dist [t] + w [i], it means that walking from point t to point j can reduce the weight. Therefore, update the point j, and corresponding cnt[j] = cnt[t] + 1, move forward
Note: this question is to judge whether there is a negative ring, not whether there is a negative ring starting from 1. Therefore, all points need to be added to the queue to update the surrounding points
//Title Background: AcWing 852
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N=2010,M=10010;
int h[N],e[M],idx,w[M],ne[M]; //The point and edge here are different in size
int dist[N];
int cnt[N]; //Record how many edges have passed from the starting point to the end point. If the number of edges ≥ n, it means that at least n+1 points must have passed, and there must be a negative ring at this time
bool st[N];
int n,m;
void add(int a,int b,int c)
{
e[idx]=b;
w[idx]=c;
ne[idx]=h[a];
h[a]=idx++;
}
bool spfa()
{
queue<int> q;
for(int i=1;i<=n;i++) //Join the team
{ //Because asking whether there is a negative ring is not asking whether there is a negative ring arriving from 1. Some negative rings may not arrive from 1. All points are included in the team here
q.push(i);
st[i]=true;
}
while(!q.empty())
{
int t=q.front();
q.pop();
st[t]=false;
for(int i=h[t];i!=-1;i=ne[i])
{
int j=e[i];
if(dist[j]>dist[t]+w[i])
{
dist[j]=dist[t]+w[i];
cnt[j]=cnt[t]+1; //Key operations
if(cnt[j]>=n) return true;
if(!st[j])
{
q.push(j);
st[j]=true;
}
}
}
}
return false;
}
int main()
{
memset(h,-1,sizeof(h));
scanf("%d%d",&n,&m);
while(m--)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
}
if(spfa()) printf("Yes");
else printf("No");
return 0;
}
Floyd algorithm
Application occasion
Multi source sink shortest path
Whether the edge weight is positive or negative, it can be handled
Negative rings cannot be handled
Algorithm complexity
O(n3)
Algorithm idea

Based on the principle of dynamic programming
-
f
[
i
,
j
,
k
]
f[i, j, k]
f[i,j,k] represents the shortest distance of all paths on the path from i to j that only passes through points 1 to K except points i and J. that
f
[
i
,
j
,
k
]
=
m
i
n
(
f
[
i
,
j
,
k
−
1
)
,
f
[
i
,
k
,
k
−
1
]
+
f
[
k
,
j
,
k
−
1
]
f[i, j, k] = min(f[i, j, k - 1), f[i, k, k - 1] + f[k, j, k - 1]
f[i,j,k]=min(f[i,j,k−1),f[i,k,k−1]+f[k,j,k−1]
Therefore, when calculating the k-th layer f [ i , j ] f[i, j] When f[i,j], all States of the k - 1 layer must be calculated first, so k needs to be placed on the outermost layer. - Read in the adjacency matrix and replace the next pass dynamic programming with the shortest distance matrix from i to j
- In the following code, when judging whether the distance from a to b is infinite, you need to judge if (T > inf / 2) instead of if(t == INF). The reason is that inf is a certain value, not really infinite, and will be affected with other values. T is greater than a number of the same order of magnitude as inf
Assume that the node sequence number is from 1 to n.
hypothesis
f
[
0
]
[
i
]
[
j
]
f[0][i][j]
f[0][i][j] is an n*n matrix, and the i-th row and the j-th column represent the weight from I to J. if I to j have edges, then its value is ci,j (the weight of edge ij).
If there are no edges, the value is infinite.
f
[
k
]
[
i
]
[
j
]
f[k][i][j]
f[k][i][j] represents (the value range of K is from 1 to n). When considering the nodes from 1 to K as the intermediate nodes, the length of the shortest path from I to j.
For example,
f
[
1
]
[
i
]
[
j
]
f[1][i][j]
f[1][i][j] represents the length of the shortest path from I to j when considering node 1 as the passing node.
According to the analysis,
f
[
1
]
[
i
]
[
j
]
f[1][i][j]
The value of f[1][i][j] is nothing more than two cases, and the path to be analyzed now is nothing more than two cases, I = > J, I = > 1 = > J:
[1]
f
[
0
]
[
i
]
[
j
]
f[0][i][j]
f[0][i][j]: I = > j the length of this path, less than, I = > 1 = > j the length of this path
[2]
f
[
0
]
[
i
]
[
1
]
+
f
[
0
]
[
1
]
[
j
]
f[0][i][1]+f[0][1][j]
f[0][i][1]+f[0][1][j]: I = > 1 = > j the length of this path is less than, I = > j the length of this path
The formal description is as follows:
f
[
k
]
[
i
]
[
j
]
f[k][i][j]
f[k][i][j] can be transferred from two situations:
[1] From
f
[
k
−
1
]
[
i
]
[
j
]
f[k−1][i][j]
f[k − 1][i][j] is transferred, which means that the shortest path from I to j does not pass through the node k
[2] From
f
[
k
−
1
]
[
i
]
[
k
]
+
f
[
k
−
1
]
[
k
]
[
j
]
f[k−1][i][k]+f[k−1][k][j]
f[k − 1][i][k]+f[k − 1][k][j] means that the shortest path from I to j passes through the node K
The conclusion is:
f
[
k
]
[
i
]
[
j
]
=
m
i
n
(
f
[
k
−
1
]
[
i
]
[
j
]
,
f
[
k
−
1
]
[
i
]
[
k
]
+
f
[
k
−
1
]
[
k
]
[
j
]
)
f[k][i][j]=min(f[k−1][i][j],f[k−1][i][k]+f[k−1][k][j])
f[k][i][j]=min(f[k−1][i][j],f[k−1][i][k]+f[k−1][k][j])
In conclusion, it is found that
f
[
k
]
f[k]
f[k] only possible with
f
[
k
−
1
]
f[k−1]
f[k − 1].
Template code
//Title Background: AcWing 854
#include<iostream>
using namespace std;
const int N=210,INF=0x3f3f3f3f;
int n,m,K;
int d[N][N];
void Floyd() //Classical algorithm
{
for(int k=1;k<=n;k++)
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
d[i][j]=min(d[i][j],d[i][k]+d[k][j]);
}
int main()
{
scanf("%d%d%d",&n,&m,&K);
for(int i=1;i<=n;i++) //At the beginning, initialize the d matrix so that the data can be read in later
for(int j=1;j<=n;j++)
if(i==j) d[i][j]=0; //The point on the diagonal represents the distance between the point and itself, which is initialized to 0
else d[i][j]=INF; //The remaining point distances are initialized to infinity
while(m--)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
d[a][b]=min(d[a][b],c); //Because there are multiple edges, it is to find the shortest path, so the multiple edges only retain the smallest edge
}
Floyd();
while(K--)
{
int x,y;
scanf("%d%d",&x,&y);
if(d[x][y]>INF/2) puts("impossible");
else printf("%d\n",d[x][y]);
}
return 0;
}