Mutator, Allocator, and Collector
The garbage collector consists of three main modules, Mutator, Allocator, and Collector.
Mutator is our user program where we create objects for our own purposes. All other modules should respect Mutator's view on the object view. For example, under no circumstances can a collector recycle an active object.
However, Mutator does not assign objects on its own. Instead, it delegates this generic task to the Allocator module -- that's what we're talking about today.
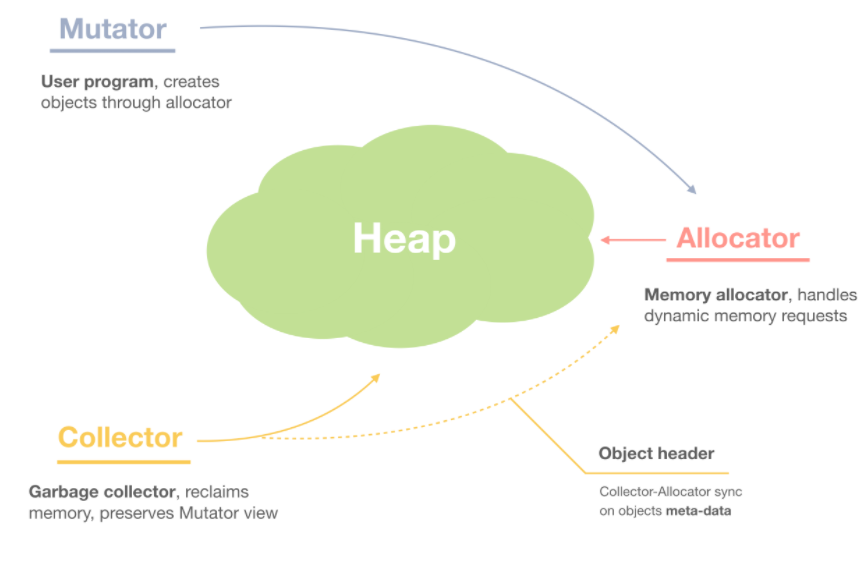
Let's dig into the details of implementing Memory Allocator.
Memory block
Typically, when dealing with class objects in advanced programming languages, we include: structure, fields, methods, etc:
const rect = new Rectangle({width: 10, height: 20});
However, from the memory allocator's point of view, it works at a lower level, with objects represented only as memory blocks. It is well known that this block has a certain size, its content is opaque, and is considered the original byte sequence. The memory block can be cast to a desired type at run time, and its logical layout may be due to the casting.
Memory allocation is always accompanied by memory alignment and object headers. Headers store meta-information about each object, as well as servers for allocator and collector purposes.
Our block of memory combines the object header with the payload pointer, which points to the first word of user data. This pointer is returned to the user when assigning the request:
/**
* Machine word size. Depending on the architecture,
* can be 4 or 8 bytes.
*/
using word_t = intptr_t;
/**
* Allocated block of memory. Contains the object header structure,
* and the actual payload pointer.
*/
struct Block {
// -------------------------------------
// 1. Object header
/**
* Block size.
*/
size_t size;
/**
* Whether this block is currently used.
*/
bool used;
/**
* Next block in the list.
*/
Block *next;
// -------------------------------------
// 2. User data
/**
* Payload pointer.
*/
word_t data[1];
};
As you can see, the header tracks the size object and whether the block - used flag is currently assigned. It is set to true at allocation time and reset back to false during free operation, so it can be reused in future requests. In addition, the next field points to the next block in the chain table of all available blocks.
The data field points to the first word that returns a user value.
This is the look and feel of the block in memory:
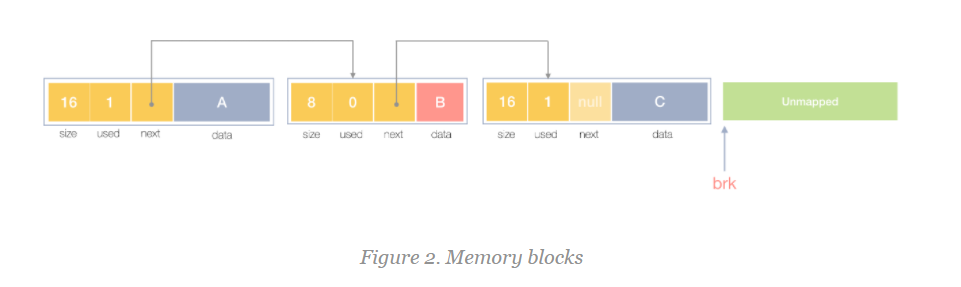
Objects A, C are in use, and block B is not currently in use.
Since this is a chain list, we will track the start and end of the heap:
/** * Heap start. Initialized on first allocation. */ static Block *heapStart = nullptr; /** * Current top. Updated on each allocation. */ static auto top = heapStart;
Allocator interface
When allocating memory, we do not make any changes to the logical layout of the object, but use the block size directly.
To mimic this malloc function, we have the following interfaces (except that we use typedword_t instead of void return types):
/**
* Allocates a block of memory of (at least) `size` bytes.
*/
word_t *alloc(size_t size) {
...
}
Memory alignment
For faster access, memory blocks should be aligned, usually the size of machine words.
This is a picture of the alignment block with the object title:

Let's define the alignment function:
/**
* Aligns the size by the machine word.
*/
inline size_t align(size_t n) {
return (n + sizeof(word_t) - 1) & ~(sizeof(word_t) - 1);
}
This means that if a user requests an allocation, such as 6 bytes, we actually allocate 8 bytes. Allocating four bytes can result in four bytes (on a 32-bit architecture) or eight bytes (on an x64 machine).
Let's do some testing:
// Assuming x64 architecture: align(3); // 8 align(8); // 8 align(12); // 16 align(16); // 16 ... // Assuming 32-bit architecture: align(3); // 4 align(8); // 8 align(12); // 12 align(16); // 16 ...
So that's the first step we'll take to assign requests:
word_t *alloc(size_t size) {
size = align(size);
...
}
Memory map
Memory layout:
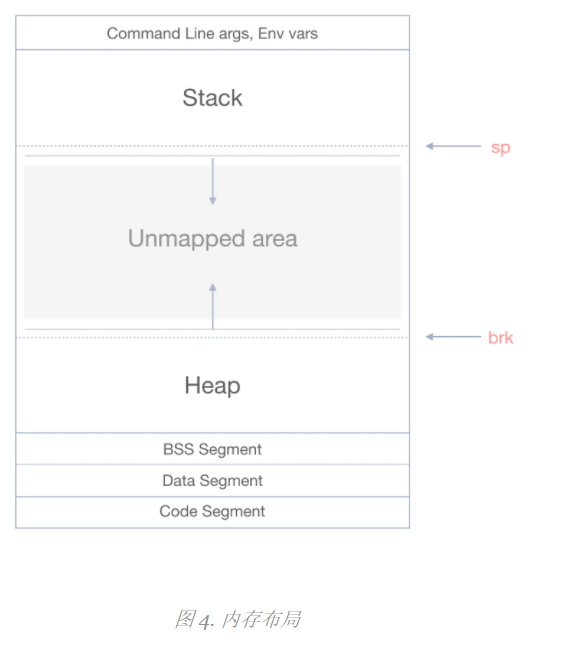
As we can see, the heap grows up toward a higher address. Stacks and stacks between regions are unmapped regions. Maps the program interrupt (BRK) pointer at the control location.
Memory mapping has several system calls: brk, sbrk, and mmap. Production allocators often use their combination, but for simplicity, we will only use the sbrk call.
With the top of the current heap, this sbrk function increases the number of bytes passed by program interrupts.
The following is the process of requesting memory from the operating system:
#include <unistd.h> // for sbrk
...
/**
* Returns total allocation size, reserving in addition the space for
* the Block structure (object header + first data word).
*
* Since the `word_t data[1]` already allocates one word inside the Block
* structure, we decrease it from the size request: if a user allocates
* only one word, it's fully in the Block struct.
*/
inline size_t allocSize(size_t size) {
return size + sizeof(Block) - sizeof(std::declval<Block>().data);
}
/**
* Requests (maps) memory from OS.
*/
Block *requestFromOS(size_t size) {
// Current heap break.
auto block = (Block *)sbrk(0); // (1)
// OOM.
if (sbrk(allocSize(size)) == (void *)-1) { // (2)
return nullptr;
}
return block;
}
By calling sbrk(0)--(1), we get a pointer to the current heap interrupt, which is where the new allocation block begins.
Next in (2) we called sbrk again, but this time we passed in the number of bytes where we should increase the break. If the result of this call is (void *)-1, indicating that memory has been allocated, we signal OOM and return nullptr. Otherwise we return the address of the allocation block obtained in (1).
Reiterate the comment on the allocSize function that in addition to the actual size of the request, we should also add the size of the structure of the Block storage object header. However, since the first word of user data is automatically reserved in the field, we reduce it.
RequFromOS is invoked only if there are no available blocks in our block list. Otherwise, we will reuse an idle block.
Deprecated on MacOSsbrk, mmap is currently emulated by using pre-allocated memory regions.
To use sbrk with clangMac OS without warnings, add:
Okay, now we can request memory from the operating system:
/**
* Allocates a block of memory of (at least) `size` bytes.
*/
word_t *alloc(size_t size) {
size = align(size);
auto block = requestFromOS(size);
block->size = size;
block->used = true;
// Init heap.
if (heapStart == nullptr) {
heapStart = block;
}
// Chain the blocks.
if (top != nullptr) {
top->next = block;
}
top = block;
// User payload:
return block->data;
}
Let's add an auxiliary function to get the header from the user pointer:
/**
* Returns the object header.
*/
Block *getHeader(word_t *data) {
return (Block *)((char *)data + sizeof(std::declval<Block>().data) -
sizeof(Block));
}
And try to assign:
#include <assert.h>
...
int main(int argc, char const *argv[]) {
// --------------------------------------
// Test case 1: Alignment
//
// A request for 3 bytes is aligned to 8.
//
auto p1 = alloc(3); // (1)
auto p1b = getHeader(p1);
assert(p1b->size == sizeof(word_t));
// --------------------------------------
// Test case 2: Exact amount of aligned bytes
//
auto p2 = alloc(8); // (2)
auto p2b = getHeader(p2);
assert(p2b->size == 8);
...
puts("\nAll assertions passed!\n");
}
In (1), the allocation size is aligned with the size of the word, that is, 8 is on x64. In (2) it's already aligned, so we get 8 as well.
You can compile it using any C++ compiler, such as clang:
# Compile: clang++ alloc.cpp -o alloc # Execute: ./alloc
As a result of this execution, you should see:
All assertions passed!
Okay, it looks good. However, we have a "small" problem with this naive allocator - it just keeps bumping into sbrk pointers, requesting more and more memory from the operating system. At some point, we will run out of memory and cannot satisfy the allocation request. What we need here is the ability to reuse previously released blocks. We will first look at object release and then improve the allocator by adding a reuse algorithm.
Freeing the objects
The free process is very simple, just set the user flag to false:
/**
* Frees a previously allocated block.
*/
void free(word_t *data) {
auto block = getHeader(data);
block->used = false;
}
The free function receives an actual user pointer, gets the corresponding Block from it, and updates the user flag.
Corresponding tests:
... // -------------------------------------- // Test case 3: Free the object // free(p2); assert(p2b->used == false);
Simple and clear. Okay, now let's finally achieve reuse so we don't run out of all available operating system memory very quickly.
Blocks reuse
Our free function does not actually return (unmap) memory to the operating system, it just sets the user flag to false. This means we can (read: should!) Reuse free blocks in future allocations.
Our alloc function is updated as follows:
/**
* Allocates a block of memory of (at least) `size` bytes.
*/
word_t *alloc(size_t size) {
size = align(size);
// ---------------------------------------------------------
// 1. Search for an available free block:
if (auto block = findBlock(size)) { // (1)
return block->data;
}
// ---------------------------------------------------------
// 2. If block not found in the free list, request from OS:
auto block = requestFromOS(size);
block->size = size;
block->used = true;
// Init heap.
if (heapStart == nullptr) {
heapStart = block;
}
// Chain the blocks.
if (top != nullptr) {
top->next = block;
}
top = block;
// User payload:
return block->data;
}
The actual reuse functionality is managed by the findBlock function in (1). Let's look at its implementation, starting with the first-fit algorithm.
First-fit search
The findBlock process should try to find a block of the appropriate size. This can be done in a variety of ways. The first thing we think about is the first search that fits.
The first-fit algorithm traverses all blocks starting at the beginning of the heap (heapStart is initialized at the first allocation). If it fits size, it returns the first found block, nullptr otherwise.
/**
* First-fit algorithm.
*
* Returns the first free block which fits the size.
*/
Block *firstFit(size_t size) {
auto block = heapStart;
while (block != nullptr) {
// O(n) search.
if (block->used || block->size < size) {
block = block->next;
continue;
}
// Found the block:
return block;
}
return nullptr;
}
/**
* Tries to find a block of a needed size.
*/
Block *findBlock(size_t size) {
return firstFit(size);
}

test
// -------------------------------------- // Test case 4: The block is reused // // A consequent allocation of the same size reuses // the previously freed block. // auto p3 = alloc(8); auto p3b = getHeader(p3); assert(p3b->size == 8); assert(p3b == p2b); // Reused!
Next-fit search
The Next-fit search is a First-fit search change, but it continues from the previous successful bits of the next search. This allows smaller blocks to be skipped at the beginning of the heap, so you do not have to traverse them frequently to get frequent requests for larger blocks. When it reaches the end of the list, it starts from the beginning and is sometimes referred to as circular preference allocation.
Again, unlike the basic first match: suppose you have 100 blocks of size 8 at the beginning of the heap, followed by blocks of size 16. Each alloc(16) request will cause traversal of all 100 blocks in the first-fit heap at the beginning of the heap, whereas in the next-fit it will start from the previous successful position of the 16-size block.
This is an example of a picture:

When we subsequently request a larger block, we immediately find it and start by skipping all smaller blocks.
Let's define the search mode and how to reset the heap:
/**
* Mode for searching a free block.
*/
enum class SearchMode {
FirstFit,
NextFit,
};
/**
* Previously found block. Updated in `nextFit`.
*/
static Block *searchStart = heapStart;
/**
* Current search mode.
*/
static auto searchMode = SearchMode::FirstFit;
/**
* Reset the heap to the original position.
*/
void resetHeap() {
// Already reset.
if (heapStart == nullptr) {
return;
}
// Roll back to the beginning.
brk(heapStart);
heapStart = nullptr;
top = nullptr;
searchStart = nullptr;
}
/**
* Initializes the heap, and the search mode.
*/
void init(SearchMode mode) {
searchMode = mode;
resetHeap();
}
Continue to implement the next-fit algorithm:
...
/**
* Next-fit algorithm.
*
* Returns the next free block which fits the size.
* Updates the `searchStart` of success.
*/
Block *nextFit(size_t size) {
// Implement here...
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
case SearchMode::FirstFit:
return firstFit(size);
case SearchMode::NextFit:
return nextFit(size);
}
}
This is one of its test cases:
... // Init the heap, and the searching algorithm. init(SearchMode::NextFit); // -------------------------------------- // Test case 5: Next search start position // // [[8, 1], [8, 1], [8, 1]] alloc(8); alloc(8); alloc(8); // [[8, 1], [8, 1], [8, 1], [16, 1], [16, 1]] auto o1 = alloc(16); auto o2 = alloc(16); // [[8, 1], [8, 1], [8, 1], [16, 0], [16, 0]] free(o1); free(o2); // [[8, 1], [8, 1], [8, 1], [16, 1], [16, 0]] auto o3 = alloc(16); // Start position from o3: assert(searchStart == getHeader(o3)); // [[8, 1], [8, 1], [8, 1], [16, 1], [16, 1]] // ^ start here alloc(16);
Okay, the next fit may be better, but it will still return a block that is too large, even if there are other more suitable blocks. Let's look at the best fit algorithm, which solves this problem.
Best-fit search
The main idea of Best Fit Search is to try to find the most appropriate block.
For example, if you have a block of [4, 32, 8] size and request alloc(8), the two previous searches will return block 32 of the second size, which unnecessarily wastes space. Obviously, returning to the third big block, 8, would be the best fit here.

The first free block is skipped here because it is too large, so the search results are in the second block.
/**
* Mode for searching a free block.
*/
enum class SearchMode {
...
BestFit,
};
...
/**
* Best-fit algorithm.
*
* Returns a free block which size fits the best.
*/
Block *bestFit(size_t size) {
// Implement here...
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
...
case SearchMode::BestFit:
return bestFit(size);
}
}
This is a test case:
... init(SearchMode::BestFit); // -------------------------------------- // Test case 6: Best-fit search // // [[8, 1], [64, 1], [8, 1], [16, 1]] alloc(8); auto z1 = alloc(64); alloc(8); auto z2 = alloc(16); // Free the last 16 free(z2); // Free 64: free(z1); // [[8, 1], [64, 0], [8, 1], [16, 0]] // Reuse the last 16 block: auto z3 = alloc(16); assert(getHeader(z3) == getHeader(z2)); // [[8, 1], [64, 0], [8, 1], [16, 1]] // Reuse 64, splitting it to 16, and 48 z3 = alloc(16); assert(getHeader(z3) == getHeader(z1)); // [[8, 1], [16, 1], [48, 0], [8, 1], [16, 1]]
Okay, it looks better! However, even if it is most appropriate, we may eventually return a block larger than the requested block. We should now look at another optimization, called block splitting.
Block spliting
Currently, if we find a block of the right size, we use it. This can be inefficient if the block found is much larger than the requested block.
We will now implement a process of splitting a larger free block out of which only a smaller block is requested. The other part remains idle and can be used for further allocation requests.
Here is an example: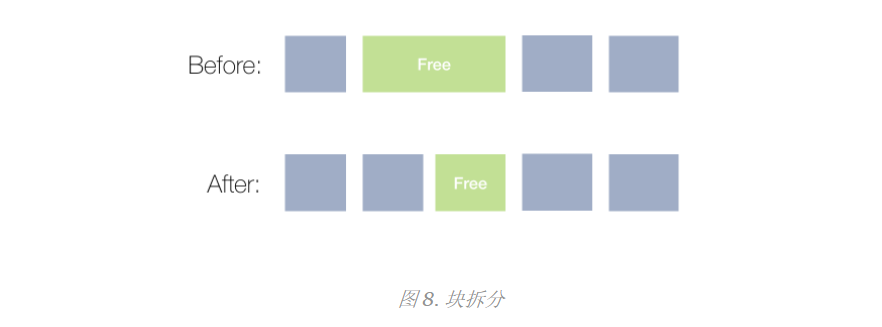
Our first suitable algorithm used to take up only the whole block, and we will not have any free blocks in the list. Although the blocks are split, we still have a free block to reuse.
listAllocate calls this function whenever it finds a block in the search algorithm. It is responsible for splitting larger blocks on smaller blocks:
/**
* Splits the block on two, returns the pointer to the smaller sub-block.
*/
Block *split(Block *block, size_t size) {
// Implement here...
}
/**
* Whether this block can be split.
*/
inline bool canSplit(Block *block, size_t size) {
// Implement here...
}
/**
* Allocates a block from the list, splitting if needed.
*/
Block *listAllocate(Block *block, size_t size) {
// Split the larger block, reusing the free part.
if (canSplit(block, size)) {
block = split(block, size);
}
block->used = true;
block->size = size;
return block;
}
By splitting it up, we can now reuse the available space very well. However, if we have two adjacent cost blocks on a heap of size 8 and the user request size is 16, we will not be able to satisfy the allocation request. Let's look at another optimization for this - the blocks coalescing.
Blocks coalescing
When an object is released, we can do the opposite of a split operation by merging two (or more) adjacent blocks into one larger block.
Here is an example:
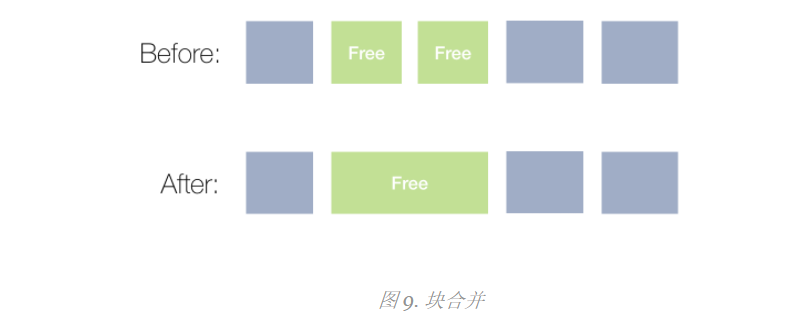
Continue with the merger:
...
/**
* Whether we should merge this block.
*/
bool canCoalesce(Block *block) {
return block->next && !block->next->used;
}
/**
* Coalesces two adjacent blocks.
*/
Block *coalesce(Block *block) {
// Implement here...
}
/**
* Frees the previously allocated block.
*/
void free(word_t *data) {
auto block = getHeader(data);
if (canCoalesce(block)) {
block = coalesce(block);
}
block->used = false;
}
Note that we only merge with the next block because we can only access the next pointer. Try adding a prev pointer to the object header and consider merging with the previous block.
Block merging allows us to meet the allocation requirements for larger blocks, but we still need to traverse the list using the O(n) method to find free blocks. Let's see how to solve this problem using an explicit free list algorithm.
Explicit Free-list
Currently, we perform a linear search on each block, analyzing it one by one. A more efficient algorithm is to use an explicit free-list, which links only free blocks.
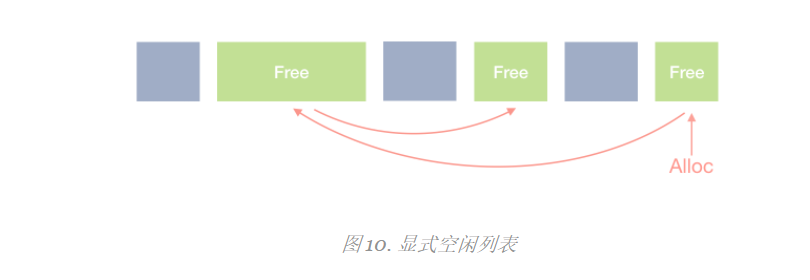
This may be a significant performance improvement, as the heap grows larger and larger, many objects need to be traversed in the basic algorithm.
Explicit free lists can be implemented directly in the object header. For this next, the and prev pointers point to the free block. The splitting and merging process should be updated accordingly, because next, and prev no longer points to adjacent blocks.
Or a person can have a separate additional free_list data structure (works): std::list
#include <list> /** * Free list structure. Blocks are added to the free list * on the `free` operation. Consequent allocations of the * appropriate size reuse the free blocks. */ static std::list<Block *> free_list;
This alloc procedure will only iterate through free_list: If nothing is found, a request from the operating system:
/**
* Mode for searching a free block.
*/
enum class SearchMode {
...
FreeList,
};
/**
* Explicit free-list algorithm.
*/
Block *freeList(size_t size) {
for (const auto &block : free_list) {
if (block->size < size) {
continue;
}
free_list.remove(block);
return listAllocate(block, size);
}
return nullptr;
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
...
case SearchMode::FreeList:
return freeList(size);
}
}
This free operation only places blocks in free_list:
/**
* Frees the previously allocated block.
*/
void free(word_t *data) {
...
if (searchMode == SearchMode::FreeList) {
free_list.push_back(block);
}
}
The two-way chain table method is experimented and implemented. For the purpose of free list, next and prev are used in headers.
Finally, let's consider another speed optimization that searches for predefined blocks faster. This method is called an isolated list.
Segregated-list search
Consider that the above search algorithms perform linear searches for blocks of different sizes. This slows down the search for blocks of the appropriate size. The idea of isolating fit is to group blocks by size.
That is, we have many block lists, not one, but each list contains only a specific size of blocks.
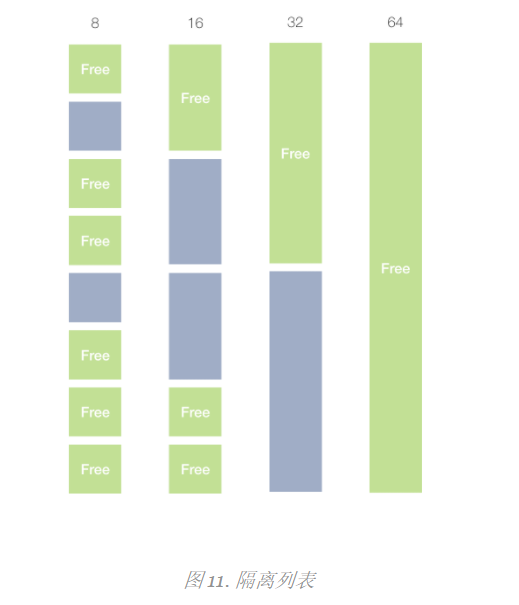
In this example, the first group contains only blocks of size 8, the second group - sizes 16, the third group - 32, and so on. Then, if we receive a request to allocate 16 bytes, we jump directly to the desired bucket (group) and allocate from there.
Heap isolation can be implemented in a variety of ways. A large arena can be pre-allocated and split into barrels, with continuous barrel arrays, and can quickly jump to desired groups and blocks within groups.
Another way is to have only one list array. The following example initializes these isolation lists. When the first block of the appropriate size is allocated, it replaces the value in the nullptr bucket. The next allocation link of the same size goes further.
That is, we have a lot of "heapStarts" and "tops" instead of a heapStart, andtop
/**
* Segregated lists. Reserve the space
* with nullptr. Each list is initialized
* on first allocation.
*/
Block *segregatedLists[] = {
nullptr, // 8
nullptr, // 16
nullptr, // 32
nullptr, // 64
nullptr, // 128
nullptr, // any > 128
};
Actual searches in a bucket can reuse any of these algorithms. In the following example, we reuse firstFit search.
enum class SearchMode {
...
SegregatedList,
};
...
/**
* Gets the bucket number from segregatedLists
* based on the size.
*/
inline int getBucket(size_t size) {
return size / sizeof(word_t) - 1;
}
/**
* Segregated fit algorithm.
*/
Block *segregatedFit(size_t size) {
// Bucket number based on size.
auto bucket = getBucket(size);
auto originalHeapStart = heapStart;
// Init the search.
heapStart = segregatedLists[bucket];
// Use first-fit here, but can be any:
auto block = firstFit(size);
heapStart = originalHeapStart;
return block;
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
...
case SearchMode::SegregatedList:
return segregatedFit(size);
}
}
OK, we've optimized the search speed. Now let's see how to optimize the storage size.
Optimizing the storage
Currently, the object header is fairly heavy: it contains size, user, and next fields. People can process some information more effectively.
For example, nextWe can access the next block through a simple block size calculation instead of an explicit pointer.
In addition, since our blocks are aligned by word length, we can reuse the LSB (least significant bit) of the size field for our purposes. For example: 1000 means size 8, not used. And 001 represent size 8, and are used.
The header structure is as follows:
struct Block {
// -------------------------------------
// 1. Object header
/**
* Object header. Encodes size and used flag.
*/
size_t header;
// -------------------------------------
// 2. User data
/**
* Payload pointer.
*/
word_t data[1];
};
And several encoding/decoding functions:
/**
* Returns actual size.
*/
inline size_t getSize(Block *block) {
return block->header & ~1L;
}
/**
* Whether the block is used.
*/
inline bool isUsed(Block *block) {
return block->header & 1;
}
/**
* Sets the used flag.
*/
inline void setUsed(Block *block, bool used) {
if (used) {
block->header |= 1;
} else {
block->header &= ~1;
}
}
This is basically a transaction store for speed. If your storage space is small, you can consider such encoding/decoding. Conversely, when you have a large amount of storage space and speed is important, using explicit fields in your structure may be faster than constant encoding and decoding of object header data.
It is currently deprecated on MacOS sbrk and implemented via mmap.
Specific features and operating systems are not recommended. However, in itself, sbrk is not only a "function", it is also a mechanism, an abstraction. As mentioned earlier, it also corresponds directly to bump-allocator.
When requesting a larger memory block, the production malloc implementation also uses mmap instead of brk. Usually mmap can be used to map external files to memory or to create anonymous mappings (not supported by any file). The latter happens to be used for memory allocation.
#include <sys/mman.h>
...
/**
* Allocation arena for custom sbrk example.
*/
static void *arena = nullptr;
/**
* Program break;
*/
static char *_brk = nullptr;
/**
* Arena size.
*/
static size_t arenaSize = 4194304; // 4 MB
...
// Map a large chunk of anonymous memory, which is a
// virtual heap for custom sbrk manipulation.
arena = mmap(0, arenaSize, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
Instead of using standard sbrk, implement your own:
void *_sbrk(intptr_t increment) {
// Implement here...
// 0. Pre-allocate a large arena using `mmap`. Init program break
// to the beginning of this arena.
// 1. If `increment` is 0, return current break position.
// 2. If `current + increment` exceeds the top of
// the arena, return -1.
// 3. Otherwise, increase the program break on
// `increment` bytes.
}