The crawler function is realized bit by bit. If we want to crawl qq music, we must first crawl one of the songs.
We open the official website of qq music, randomly find a song, enter the playback page, and then press F12 to enter the detection interface.
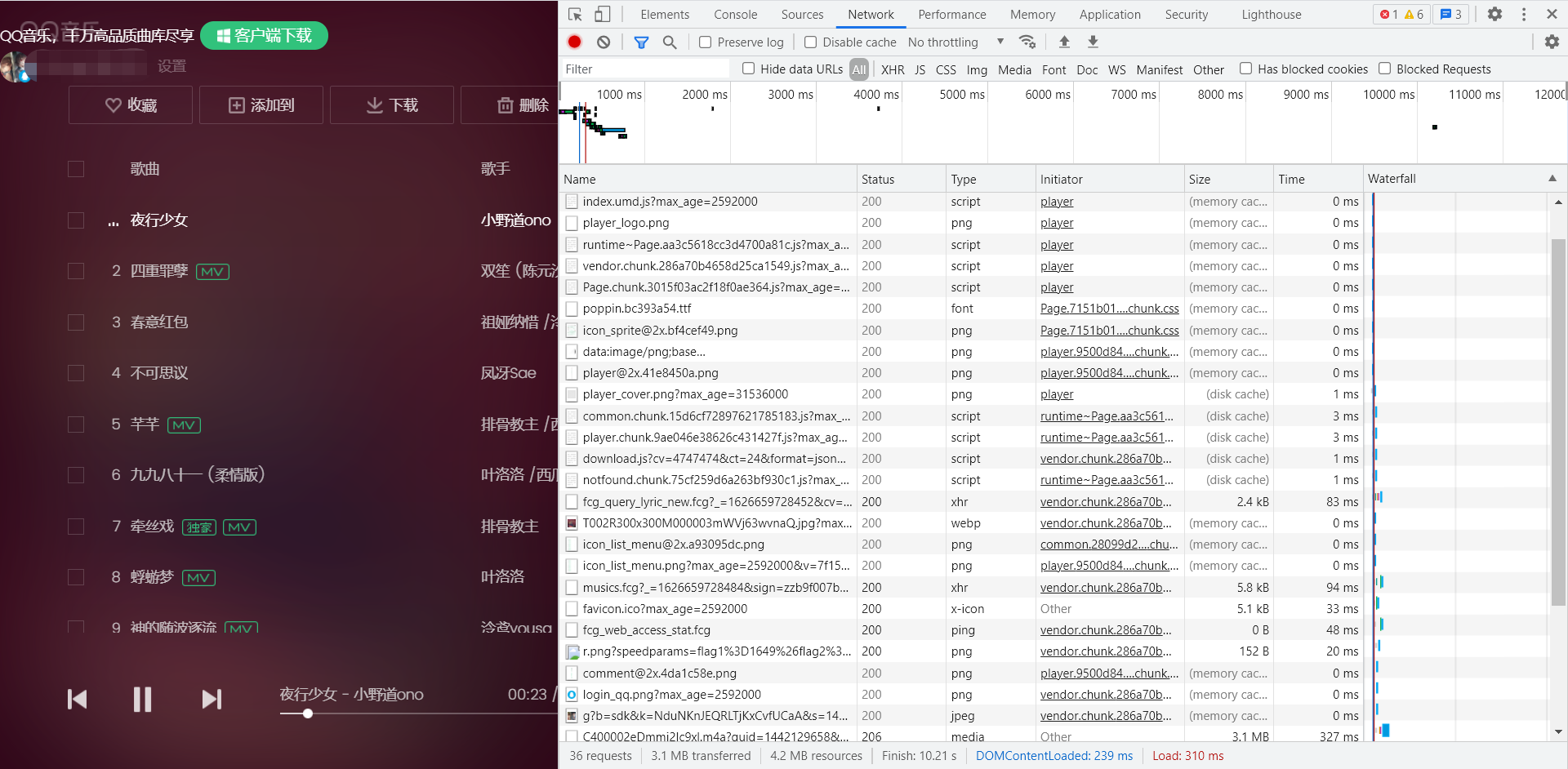
If no data appears, refresh the page. Then we find the file with the size of a song here. Here is the 3.1MB file. Click to view its URL. Obviously, this is the address of the song being played.
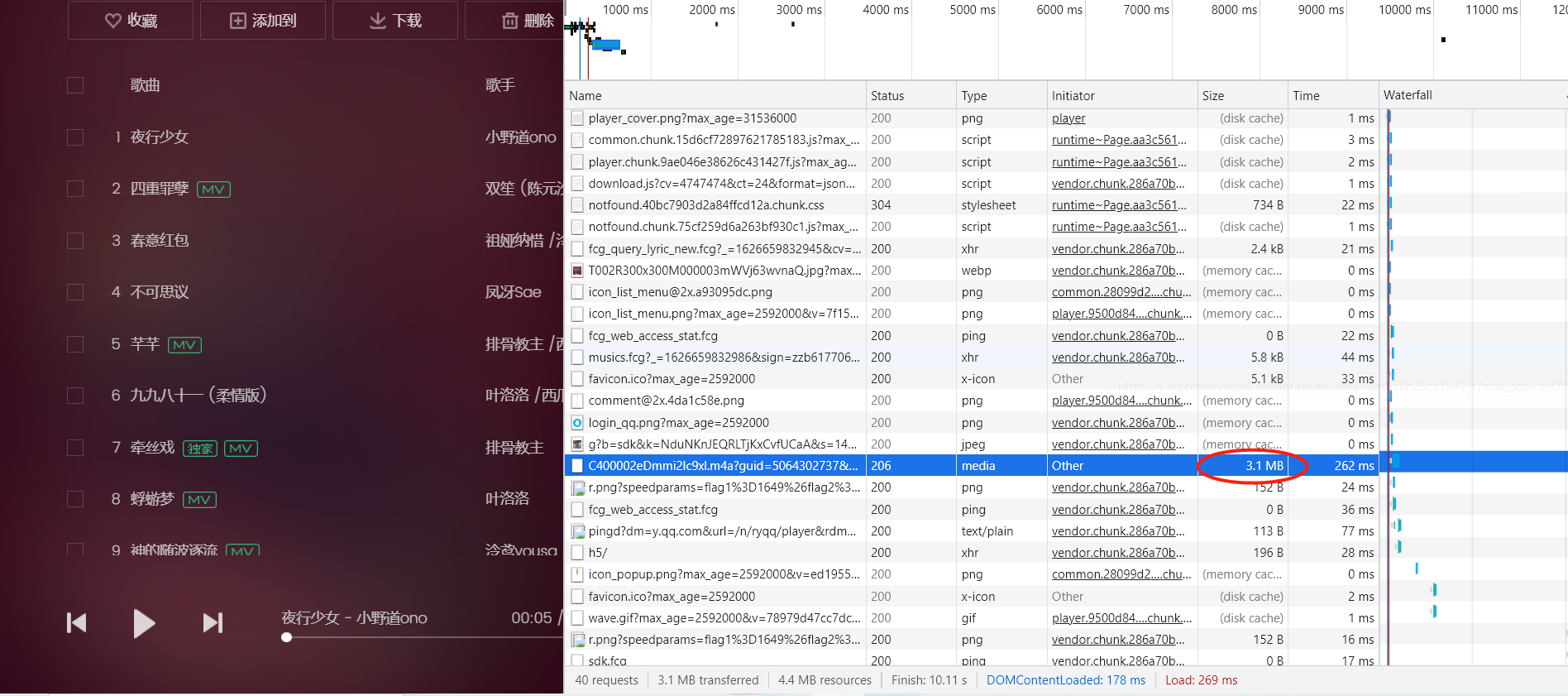
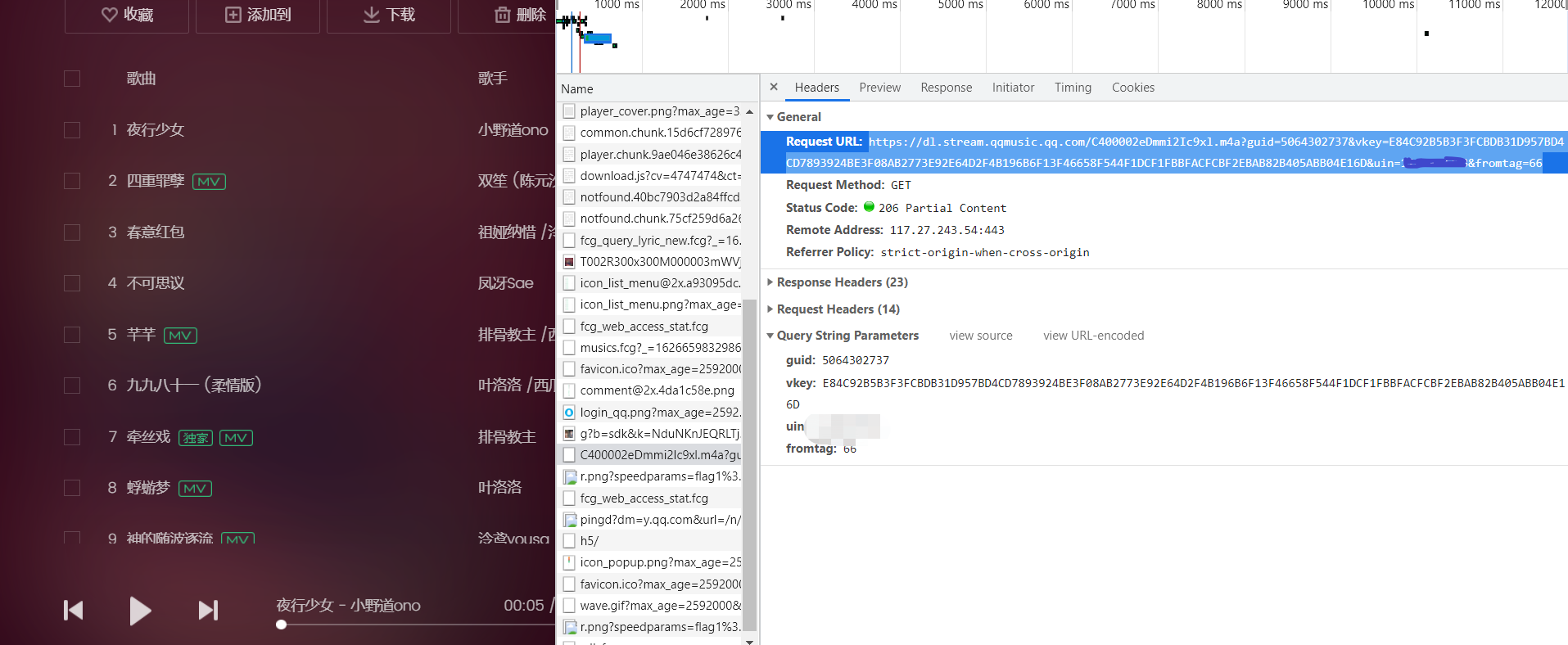
We can open this website to check whether it is the address of the song we need.
Obviously, this is the address we need. So, how do we use crawlers to get this address?
By comparing the addresses of several different songs, we can see that the section from C400 to guid and the section from vkey to uin are what we need to obtain, and other parts remain unchanged.

Then we continue to find out how the website is generated. I have no choice but to turn it one by one. After we find the file, we can see that its purl is what we need.
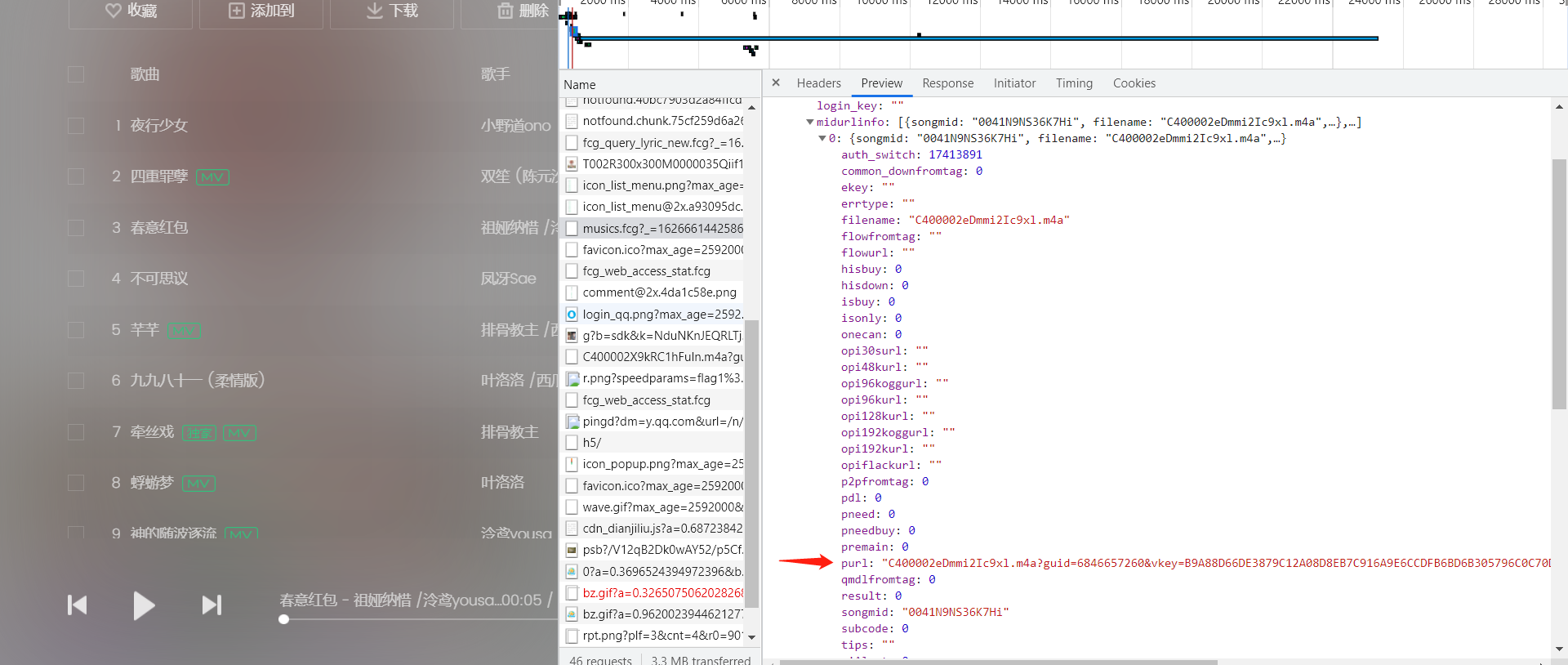
Let's see what parameters are required for this request.
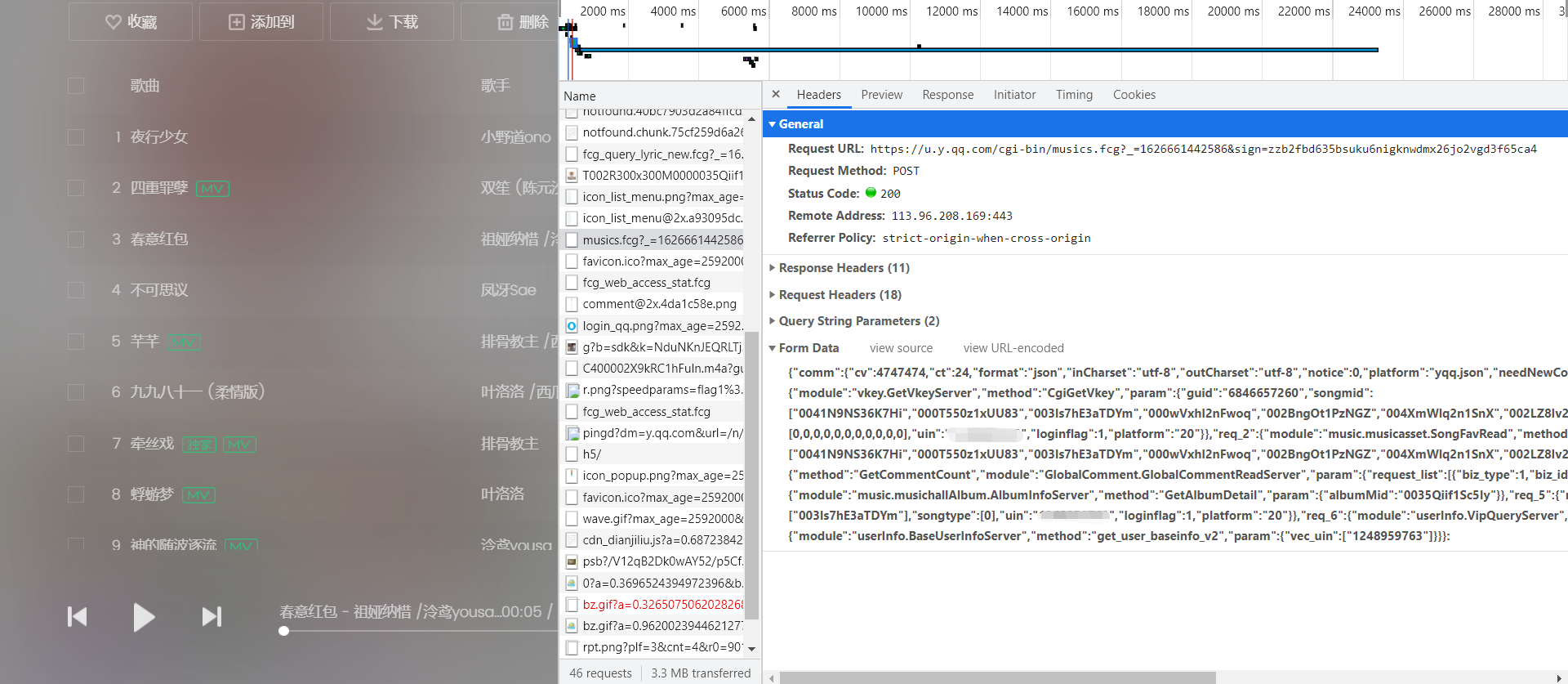
Is there a long list of parameters in Form Data that look headache? No hurry. Let's analyze which parameters need to be passed in.

Is the parameter in songmid familiar? We can check it and find that this is the logo of those songs, that is, we can send the songmid of the song we need to listen to to to this website, and we can get the url we need.
So we can try, we will req_2. The previous parameters are passed in.
data={"comm":{"cv":4747474,"ct":24,"format":"json","inCharset":"utf-8","outCharset":"utf-8","notice":0,"platform":"yqq.json","needNewCode":1,"uin":1248959521,"g_tk_new_20200303":1832066374,"g_tk":1832066374},"req_1":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"6846657260","songmid":["0041N9NS36K7Hi","000T550z1xUU83","003Is7hE3aTDYm","000wVxhI2nFwoq","002BngOt1PzNGZ","004XmWlq2n1SnX","002LZ8Iv2bBWfu","003tqTBf17F7ed","002s34bV1k1W7M","004Vd5CG1YlRUU","002LNOds0rYvpK"],"songtype":[0,0,0,0,0,0,0,0,0,0,0],"uin":"1248959521","loginflag":1,"platform":"20"}}}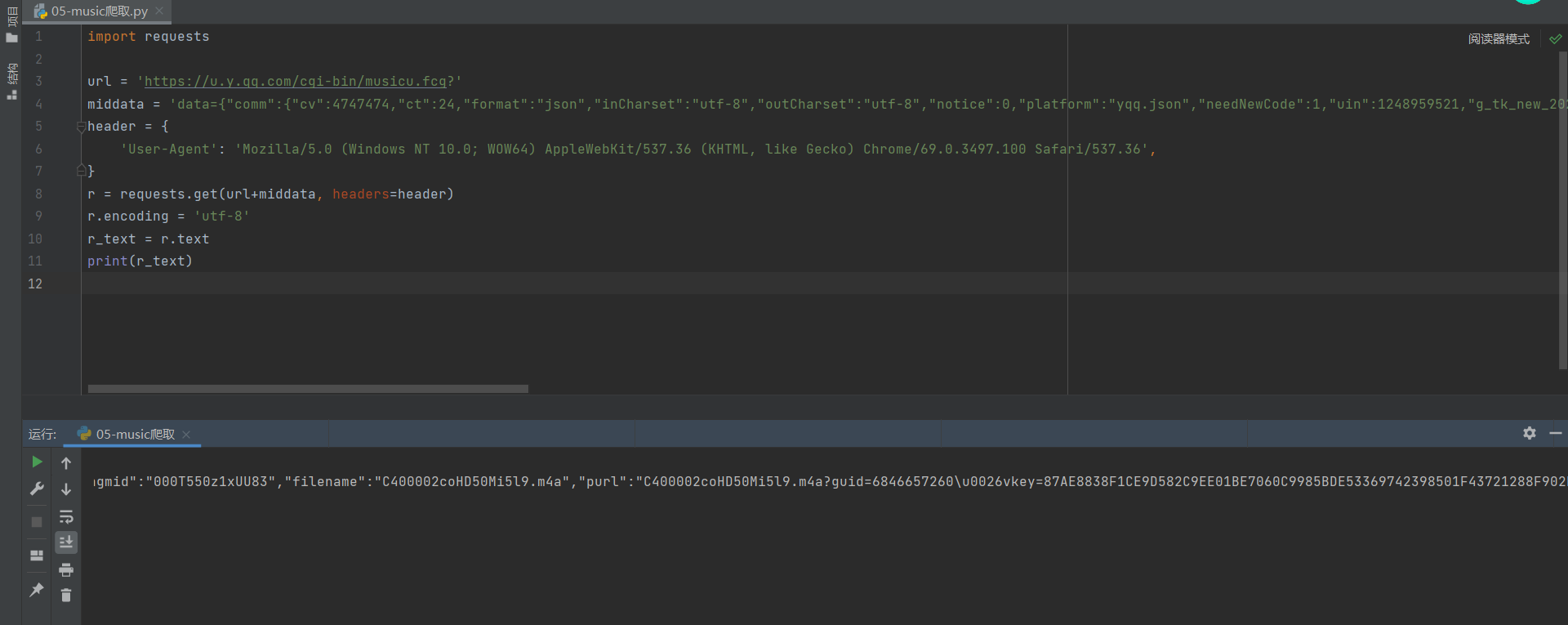
Well, it's successful directly, so all we need is purl. We use json module to obtain purl more conveniently.
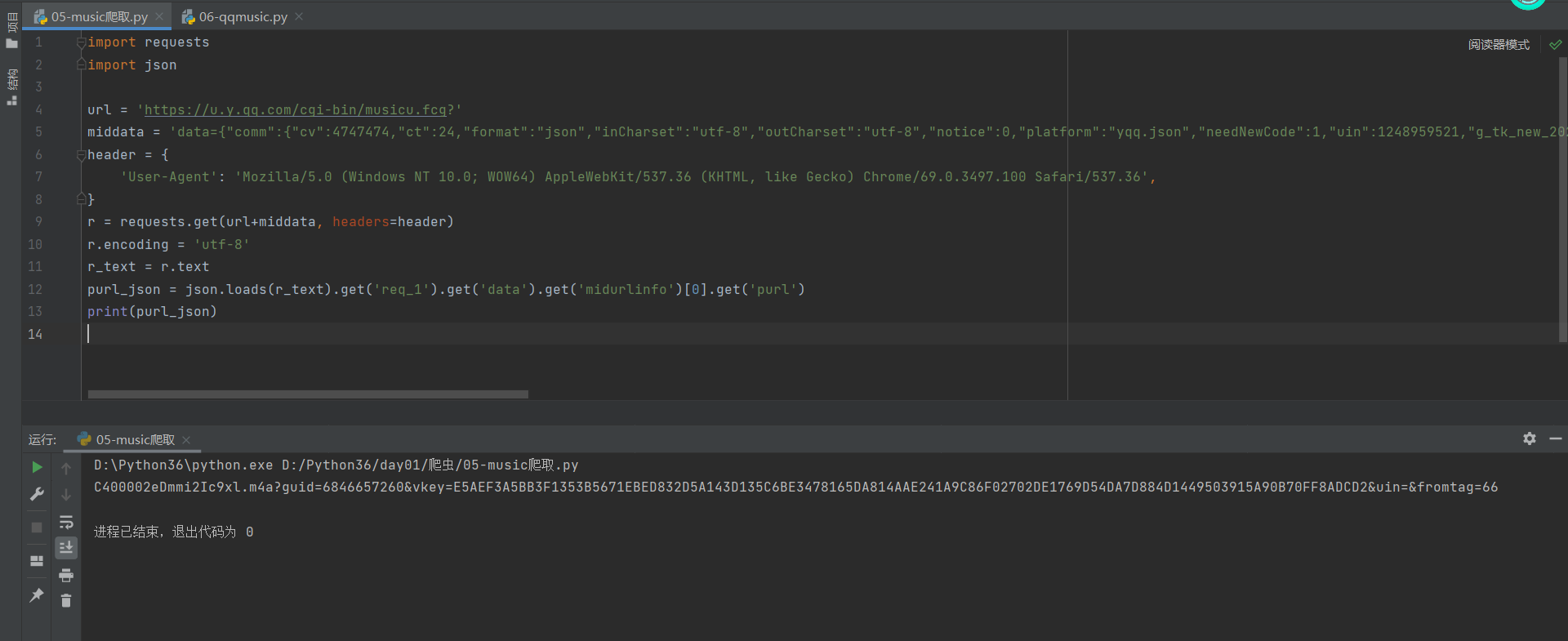
In this way, we can get the purl we need, and finally splice it to see if it can be downloaded normally.
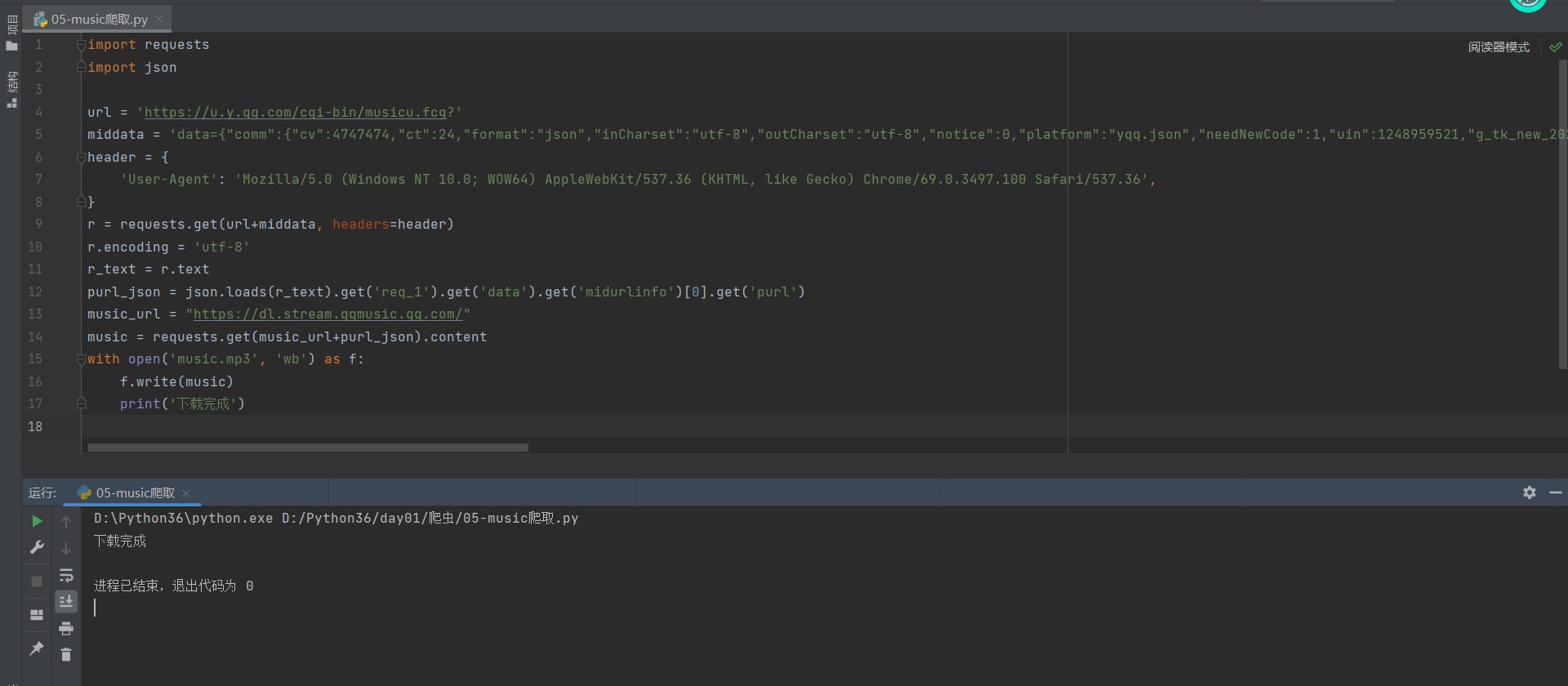
If the download is successful, we have straightened out the idea of downloading a song. We only need to obtain the song songmid to download it. Then what we need to do next is to obtain the songmid.
So where's songmid? I opened the song page and found that the string behind the song's website is songmid.
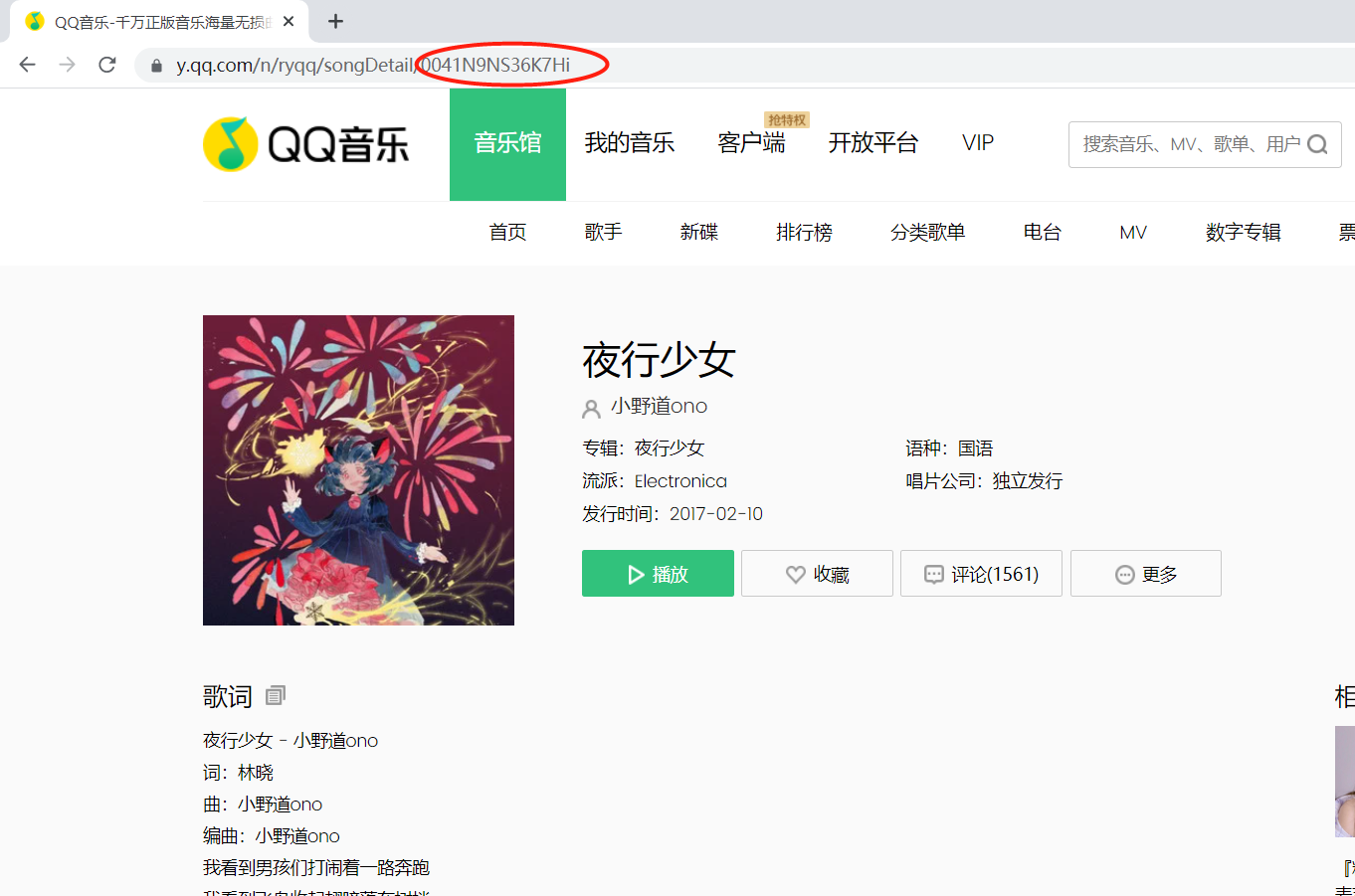
So how does this website come from? Of course, you can get it on the qq music search page.
Let's take a look at the qq music search interface.
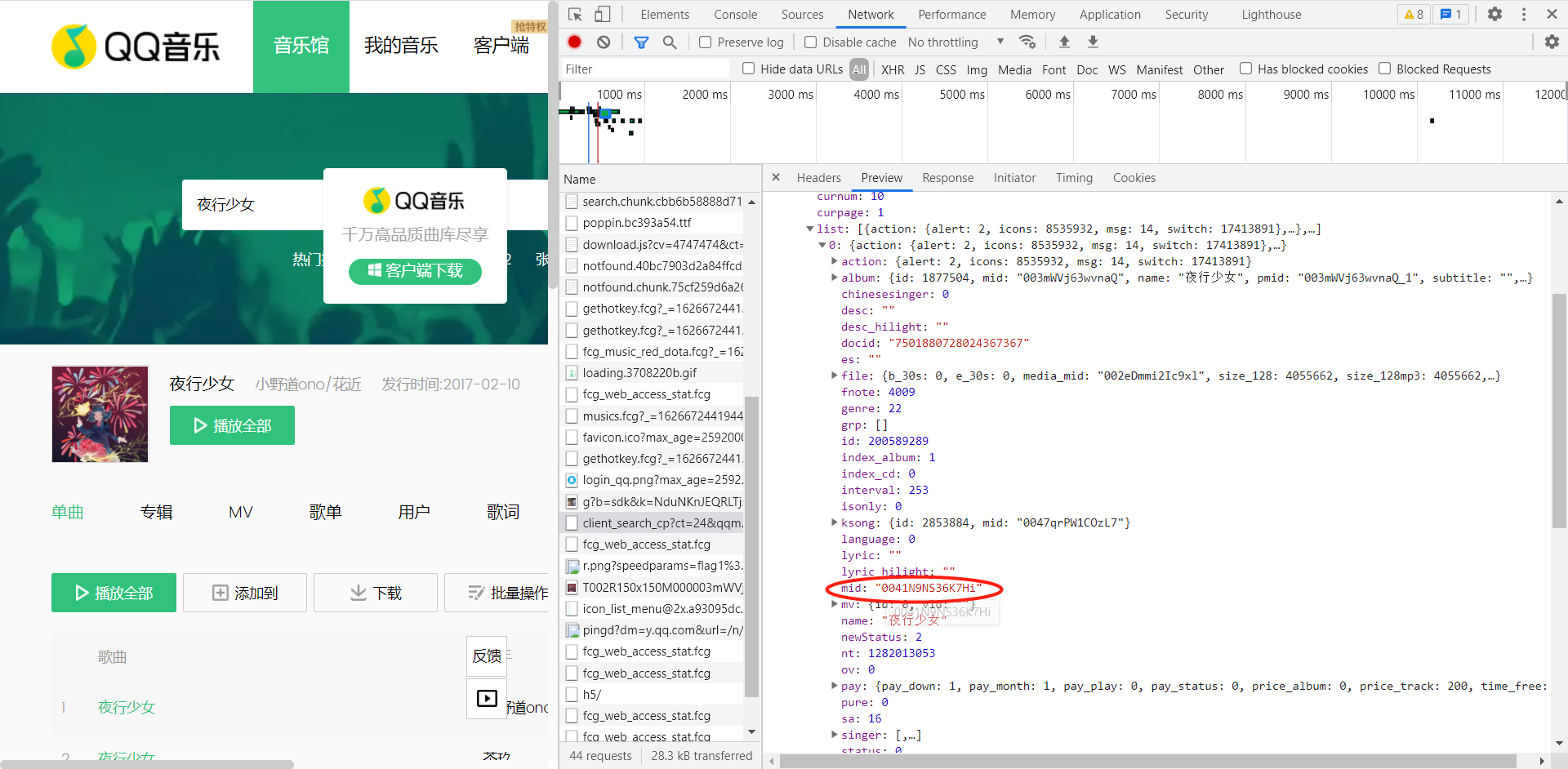
Now the idea is very obvious. We only need to use the same idea to obtain the song ID of the required song on the search page and download it.
Then I will simply optimize the code as follows:
import requests
import json
from bs4 import BeautifulSoup
import urllib.request
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
def get_purl(mid):
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?'
middata = 'data={"comm":{"cv":4747474,"ct":24,"format":"json","inCharset":"utf-8","outCharset":"utf-8","notice":0,"platform":"yqq.json","needNewCode":1,"uin":1248959521,"g_tk_new_20200303":1832066374,"g_tk":1832066374},"req_1":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"6846657260","songmid":["%s"],"songtype":[0],"uin":"1248959521","loginflag":1,"platform":"20"}}}' % (
mid)
try:
r = requests.get(url+middata, headers=header)
r.encoding = 'utf-8'
purl_json = json.loads(r.text).get('req_1').get('data').get('midurlinfo')[0].get('purl')
return purl_json
except:
print('obtain purl fail')
def get_mid(w):
url = "https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.top&searchid=58540219608212637&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%s&_=1626671326366&cv=4747474&ct=24&format=json&inCharset=utf-8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&uin=1248959763&g_tk_new_20200303=1832066374&g_tk=1832066374&hostUin=0&loginUin=0" % (urllib.request.quote(w))
r = requests.get(url, headers=header)
r.encoding = 'utf-8'
mid_json = json.loads(r.text).get('data').get('song').get('list')[0].get('mid')
return mid_json
if __name__ == '__main__':
music_url = "https://dl.stream.qqmusic.qq.com/"
w = input('Please enter the name of the song:')
mid = get_mid(w)
purl = get_purl(mid)
music = requests.get(music_url+purl).content
with open(f'music/{w}.mp3', 'wb') as f:
f.write(music)
print(f'{w}Download complete')