SkyWalking is an open source observable platform for collecting, analyzing, aggregating and visualizing data from services and cloud native infrastructure. SkyWalking provides an easy way to maintain a clear view of distributed systems, even across the cloud. It is a modern APM designed for cloud native, container based distributed systems.
Why?
SkyWalking provides a solution to observe and monitor distributed systems in many different scenarios. First, like the traditional way, SkyWalking is Java, c#, node JS, Go, PHP, Nginx LUA and other services provide automatic meter agents. (including calls for Python and C++ SDK contributions). In a multilingual and continuously deployed environment, the cloud native infrastructure becomes more powerful, but also more complex. SkyWalking's service grid receiver allows SkyWalking to receive telemetry data from service grid frameworks such as Istio/Envoy and Linkerd, so that users can understand the entire distributed system.
Download decompression
Official website: https://skywalking.apache.org/
Download link: https://skywalking.apache.org/downloads/
Because this is connected to elasticsearch7 x. So download apache-skywalking-apm-es7-8.5 tar. GZ installation package
decompression
/data/aimm/tools tar -zxvf apache-skywalking-apm-es7-8.5.tar.gz
oap configuration
Configure the application. Here, 'zookeeper', 'consumer', 'etcd', 'nacos', etc. are supported
vim apache-skywalking-apm-bin-es7/config/application.yml
elasticsearch7:
nameSpace: ${SW_NAMESPACE:"skywalking"}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:172.16.253.10:9200} #The address of es is configured here
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
dayStep: ${SW_STORAGE_DAY_STEP:1}
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1}
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1}
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1}
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5}
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0}
user: ${SW_ES_USER:"aimm_skywalking"} #User name for configuration
password: ${SW_ES_PASSWORD:"Pass!234"} #Configure the password for es
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""}
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:1000}
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10}For performance considerations, the official recommendation is in elasticsearch Add the following configuration to the YML configuration
thread_pool.index.queue_size: 1000 #ElasticSearch 6 only thread_pool.write.queue_size: 1000 #For ElasticSearch 6 and 7 index.max_result_window: 1000000 #Remember to set when there is an error on the trace page
webapp configuration
The webapp configuration file is in / webapp / webapp In YML
vim apache-skywalking-apm-bin-es7/webapp/webapp.yml
server:
port: 8080 #Port used to access the web
collector:
path: /graphql
ribbon:
ReadTimeout: 10000
# Point to all backend's restHost:restPort, split by ,
listOfServers: 127.0.0.1:12800By default, I use graphql to access the data collection port of oap, so I listen to port 12800. Because I deploy oap and webapp on the same server, the default address is 127.0 0.1. If it is deployed on different servers, it needs to be modified to the corresponding server address.
start-up
There are complete scripts in the / bin directory, which can be started through startup SH starts oap and webapp processes at the same time. What the script actually does is to call oapservice in the same directory SH and webappservice SH script. The script content is as follows. Therefore, if we consider deploying the two processes separately, we can call the corresponding script to run it separately.
vim apache-skywalking-apm-bin-es7/bin/startup.sh PRG="$0" PRGDIR=`dirname "$PRG"` OAP_EXE=oapService.sh WEBAPP_EXE=webappService.sh "$PRGDIR"/"$OAP_EXE" "$PRGDIR"/"$WEBAPP_EXE"
agent configuration
To use the agent, copy the entire directory of / agent to the corresponding server to be monitored, and modify the agent.config under / agent/config Config configuration
vim apache-skywalking-apm-bin-es7/agent/config/agent.config
# Different namespace s will cause the call link tracing to be interrupted
agent.namespace=${SW_AGENT_NAMESPACE:hmall}
# The name of the service displayed on the page can also be - dskywalking agent. service_ Name = XXX specified
agent.service_name=${SW_AGENT_NAME:gateway}
# The calling address of the platform can also be through - dskywalking collector. backend_ service=127.0. 0.1:80 specified
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:172.16.0.11:11800}
# Ignore request collection for specified suffix
agent.ignore_suffix=${SW_AGENT_IGNORE_SUFFIX:.jpg,.jpeg,.js,.css,.png,.bmp,.gif,.ico,.mp3,.mp4,.html,.svg}
# Sampling rate every 3 seconds, negative number represents 100%
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:-1}After modification, add - javaagent: / data / AIMM / tools / agent / skywalking agent when starting the java process jar=agent. service_ Name = ${project_name} to load the agent, where ${project_name} represents the corresponding project name.
For example, a complete startup command
java -jar -Xmx512m -Xms512m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/aimm/log/aimm-operation-trace-app/ -Djava.io.tmpdir=/data/aimm/tmp -javaagent:/data/aimm/tools/agent/skywalking-agent.jar=agent.service_name=aimm-operation-trace-app -Dspring.profiles.active=test /data/aimm/app/aimm-operation-trace-app-2.2.5-SNAPSHOT.jar
SkyWalking is logically divided into four parts: probe, platform backend, storage and UI.
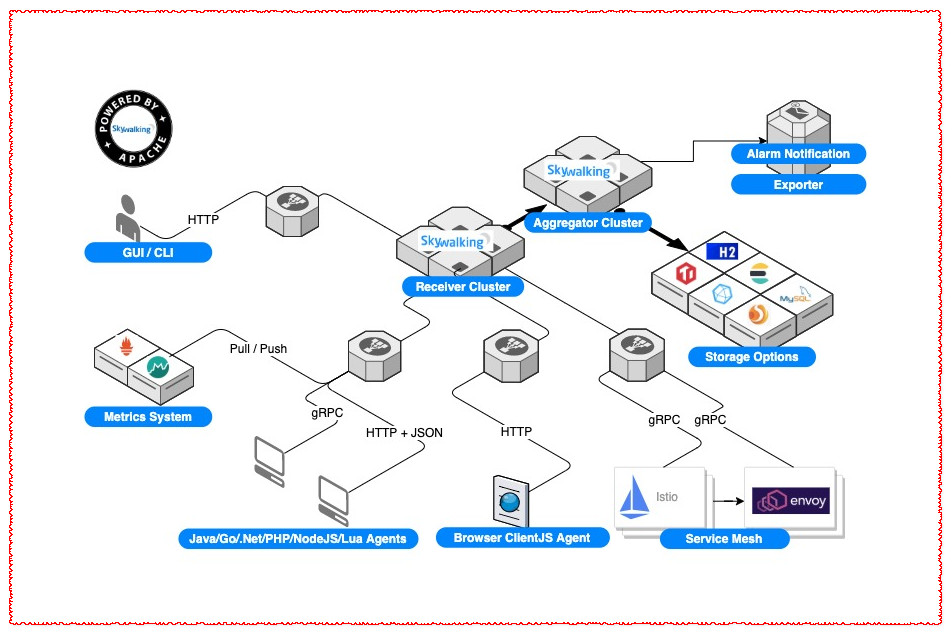
-
Probes: probes collect data and reformat them according to SkyWalking requirements (different probes support different sources).
-
Platform back end: the platform back end supports data aggregation, analysis and stream processing, including tracking, indicators and logs.
-
Storage: store SkyWalking data through an open / pluggable interface. You can choose an existing implementation, such as ElasticSearch, H2, MySQL, TiDB, InfluxDB, or implement your own. Welcome to the patch for the new storage implementer!
-
UI: UI is a highly customizable Web-based interface that allows SkyWalking end users to visualize and manage SkyWalking data.