Software Architecture Experiment 2
1. Simple Translator for Implementing Four Operations
1.1 Requirements
- Implements four operations of addition, subtraction, multiplication and division, allowing multiple operands at the same time, such as 4+6*5-8 resulting in 26;
- The operand is an integer, which can have multiple bits.
- Handle spaces;
- The input error displays the error prompt and returns the command status "CALC".
1.2 Ideas
Since multiplication and division are better than addition and subtraction, it is advisable to perform all multiplication and division operations first, and to put the integer values of these multiplication and division operations back to the corresponding position in the original expression, then the value of the entire expression will be equal to a series of integer values after addition and subtraction.
Based on this, we can use a stack to store the values of these integers (after multiplying and dividing), which are pushed directly into the stack for the number after the plus and minus sign, and for the number after the multiplying and dividing sign, which can be calculated directly with the top element of the stack, and the top element of the stack is the result of the calculation.
Specifically, traverse the expression string express and record the operator before each number with the variable preSign. For the first number, the operator before it is treated as a plus sign. Each time you traverse to the end of a number, you decide how to calculate based on preSign:
- Plus sign: Push numbers on the stack;
- Minus sign: push the opposite number of numbers onto the stack;
- Multiplication and division sign: Calculates the number and the top element of the stack, and replaces the top element with the result of the calculation.
In code implementation, reading an operator or traversing to the end of a string is considered to have traversed to the end of a number. After processing the number, update the preSign to the character currently traversed.
After traversing the expression string express, the elements in the stack are added together, which is the value of the expression.
import java.util.Deque;
import java.util.LinkedList;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
final String cmd = "CALC> ";
Scanner in = new Scanner(System.in);
while (true){
System.out.print(cmd);
String expression = in.nextLine();
System.out.println(calculate(expression));
}
}
public static int calculate(String expression) {
//Handle Spaces
expression.trim();
Deque<Integer> stack = new LinkedList<Integer>();
char preSign = '+';
int num = 0;
int n = expression.length();
for (int i = 0; i < n; ++i) {
if (Character.isDigit(expression.charAt(i))) {
num = num * 10 + expression.charAt(i) - '0';
}
if (!Character.isDigit(expression.charAt(i)) && expression.charAt(i) != ' ' || i == n - 1) {
switch (preSign) {
case '+':
stack.push(num);
break;
case '-':
stack.push(-num);
break;
case '*':
stack.push(stack.pop() * num);
break;
default:
stack.push(stack.pop() / num);
}
preSign = expression.charAt(i);
num = 0;
}
}
int ans = 0;
while (!stack.isEmpty()) {
ans += stack.pop();
}
return ans;
}
}
2. Set up Hadoop platform to implement wordcloud algorithm
-
Download Hadoop at: http://hadoop.apache.org/releases.html
-
Install JDK. Note: Hadoop relies on JDK and requires no spaces in the path, so install JDK in a directory without spaces (The default installation is in the Program file folder of the C drive, but this directory has spaces, so choose another directory. It is recommended to set up a Java folder on the D drive and install it in this folder. Of course, there is no problem under other files. Make sure there are no spaces in the path. If you install in the program files folder, take care to match it. Set 5)
-
Unzip the downloaded Hadoop, download winutils, and replace the bin file of Hadoop with the bin inside
-
Configure environment variables, increase the HADOOP_HOME variable, and increase the%HADOOP_HOME%\bin variable in the path variable
-
Hadoop configuration, modify these files under the hadoop-3.2.2/etc/hadoop/folder:
-
ore-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
Create a data directory under the hadoop-3.2.2 directory as the data store path
Create a datanode directory under the hadoop-3.2.2/data directory;
Create a namenode directory under the hadoop-3.2.2/data directory;
-
Configuration of hdfs-site.xml: ((Hadoop is set to its own path during configuration)
<configuration> <!-- This parameter is set to 1 because it is a standalone version hadoop --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/D:/hadoop-3.2.2/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/D:/hadoop-3.2.2/data/datanode</value> </property> </configuration> -
Setting Java_Home in Hadoop-env.cmd
-

If you have a jdk environment here, you can also leave it unchanged.
-
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <!-- Place to store intermediate results --> <name>yarn.nodemanager.local-dirs</name> <value>/D:/hadoop-3.2.2/tmp</value> </property> </configuration>Copy hadoop.dll from hadoop's bin file to the c-disk windows/system32 folder
-
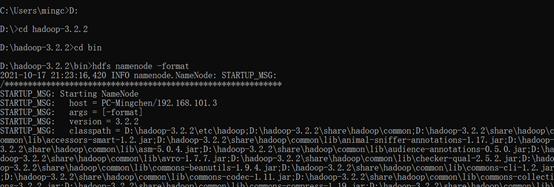
Once configuration is complete, open the cmd command line with administrator privileges, switch to the bin folder of hadoop, and start the HDFS namenode-format configuration file format
-
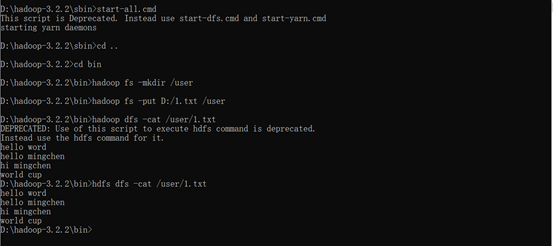
Starting the Hadoop service in the sbin folder start-all.cmd of Hadoop will result in four windows
-
\1.Reopen a cmd command line, enter Hadoop bin, run Hadoop fs-mkdir/user to create a new folder, create a new txt file, enter a piece of English text inside, use the command
Hadoop fs-put "File you created"/user
Upload your file and view the contents of the file with HDFS dfs-cat/user/input_file.txt as shown in the following image
-
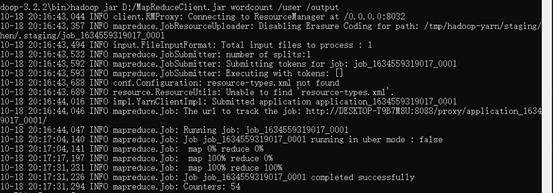
Download the MapReduceClient.jar file and run > Hadoop jar D:/MapReduceClient.jar wordcount/user/output on the command line just now to implement the wordcount algorithm. You will see the following results:
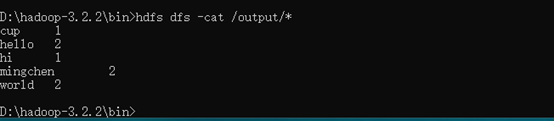
-
Finally, use the command HDFS dfs-cat/output/* to see the statistical results of words, as shown below