Table of contents
brief introduction
In this part, we will talk about some methods of sample balance. All content comes from the link below.
The following reference material is very good. It is highly recommended to check it: Resampling strategies for imbalanced datasets
Why sample balance
If the positive and negative samples are very different, or there is a great difference between categories, the model will prefer to predict the most common samples. At the same time, this can finally obtain a high accuracy, but this accuracy can not explain how good the model is.
In a dataset with highly unbalanced classes, if the classifier always "predicts" the most common class without performing any analysis of the features, it will still have a high accuracy rate, obviously illusory.
terms of settlement
There are two major directions to solve the problem of sample imbalance. One is under sampling and the other is over sampling. (A widely adopted technique for dealing with highly unbalanced datasets is called resampling. It consists of removing samples from the majority class (under-sampling) and / or adding more examples from the minority class (over-sampling).)
Under-sampling
Under sampling can be understood as taking some samples from more classifications, so that the number of more classifications is the same as that of fewer classifications. (there are many sampling methods here)
Over-sampling
The so-called over sampling can be understood as resampling a small part of the samples to make them more. (there are many resampling methods here)
The following picture summarizes the difference between under sampling and over sampling.
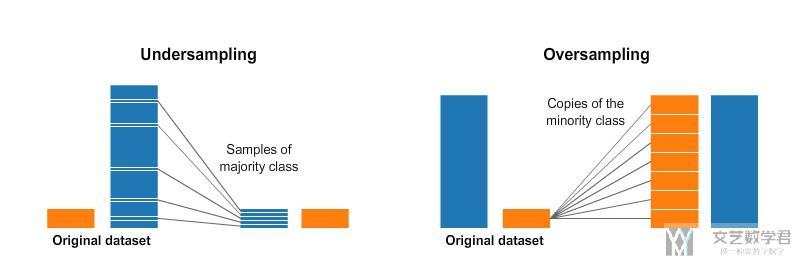
Of course, using the above two methods will have a price. If you use undersampling, you will lose information. If oversampling is used, the problem of over fitting will occur.
Despite the advantage of balancing classes, these techniques also have their weaknesses (there is no free lunch). The simplest implementation of over-sampling is to duplicate random records from the minority class, which can cause overfitting. In under-sampling, the simplest technique involves removing random records from the majority class, which can cause loss of information.
Simple experiment
Let's use the NSL-KDD data set to do a simple experiment. We only implement simple over sampling and under sampling here. For other sampling methods, please refer to the links above. I'll put them here again.
- Very good reference: Resampling strategies for imbalanced datasets
- Simple principle introduction: imbalanced-learn
Dataset preparation
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
Next, import the dataset
- COL_NAMES = ["duration", "protocol_type", "service", "flag", "src_bytes",
- "dst_bytes", "land", "wrong_fragment", "urgent", "hot", "num_failed_logins",
- "logged_in", "num_compromised", "root_shell", "su_attempted", "num_root",
- "num_file_creations", "num_shells", "num_access_files", "num_outbound_cmds",
- "is_host_login", "is_guest_login", "count", "srv_count", "serror_rate",
- "srv_serror_rate", "rerror_rate", "srv_rerror_rate", "same_srv_rate",
- "diff_srv_rate", "srv_diff_host_rate", "dst_host_count", "dst_host_srv_count",
- "dst_host_same_srv_rate", "dst_host_diff_srv_rate", "dst_host_same_src_port_rate",
- "dst_host_srv_diff_host_rate", "dst_host_serror_rate", "dst_host_srv_serror_rate",
- "dst_host_rerror_rate", "dst_host_srv_rerror_rate", "labels"]
- #Import dataset
- Trainfilepath = './NSL-KDD/KDDTrain+.txt'
- dfDataTrain = pd.read_csv(Trainfilepath, names=COL_NAMES, index_col=False)
Let's take a brief look at the distribution of various attacks.
- target_count = dfDataTrain.labels.value_counts()
- target_count.plot(kind='barh', title='Count (target)');

Here, we only try four attacks, namely back, neptune, smurf and teardrop. Let's take a brief look at the distribution of these four attacks.
- DataBack = dfDataTrain[dfDataTrain['labels']=='back']
- DataNeptune = dfDataTrain[dfDataTrain['labels']=='neptune']
- DataSmurf = dfDataTrain[dfDataTrain['labels']=='smurf']
- DataTeardrop = dfDataTrain[dfDataTrain['labels']=='teardrop']
- DataAll = pd.concat([DataBack, DataNeptune, DataSmurf, DataTeardrop], axis=0, ignore_index=True).sample(frac=1) #Merge into new data
- #View the distribution of various
- target_count = DataAll.labels.value_counts()
- target_count.plot(kind='barh', title='Count (target)');

Over-Sampling
We use simple oversampling, that is, repeated values, to increase the number of samples.
- from imblearn.over_sampling import RandomOverSampler
- #Simple oversampling
- ros = RandomOverSampler()
- X = DataAll.iloc[:,:41].to_numpy()
- y = DataAll['labels'].to_numpy()
- X_ros, y_ros = ros.fit_sample(X, y)
- print(X_ros.shape[0] - X.shape[0], 'new random picked points')
- #The format that makes up pandas
- DataAll = pd.DataFrame(X_ros, columns=COL_NAMES[:-1])
- DataAll['labels'] = y_ros
- #Visual display
- target_count = DataAll.labels.value_counts()
- target_count.plot(kind='barh', title='Count (target)');
Taking a brief look at the final results, we can see that the samples of each category are now 40000 +, which is equivalent to the same number of samples as before.

Under-Sampling
The following is a simple implementation of down sampling, which also directly removes the data in more classes.
- from imblearn.under_sampling import RandomUnderSampler
- rus = RandomUnderSampler(return_indices=True)
- X = DataAll.iloc[:,:41].to_numpy()
- y = DataAll['labels'].to_numpy()
- X_rus, y_rus, id_rus = rus.fit_sample(X, y)
- #The format that makes up pandas
- DataAll = pd.DataFrame(X_rus, columns=COL_NAMES[:-1])
- DataAll['labels'] = y_rus
- #Drawing
- target_count = DataAll.labels.value_counts()
- target_count.plot(kind='barh', title='Count (target)');
You can see that the number of each sample is 800 +, which completes under sampling

Here is a brief introduction to the methods of up sampling and down sampling. For other sampling methods, please refer to the links above.