Some experience on the use of HDFS
Write before:
I've been working on big data in the company for some time. Take time to sort out the problems encountered and some better optimization methods.
1.HDFS storage multi directory
1.1 production server disk
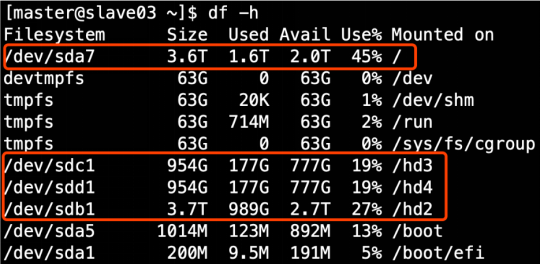
1.2 on HDFS site Configure multiple directories in the XML file, and pay attention to the access rights of the newly mounted disk.
The path to save data in the DataNode node of HDFS is determined by DFS DataNode. data. The dir parameter determines the default value of file://${hadoop.tmp.dir}/dfs/data. If the server has multiple disks, this parameter must be modified. Adjust the parameters according to the above figure, and the results are as follows:
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>
2. Cluster data balancing
1. Data balance between nodes
Enable data equalization command
start-balancer.sh -threshold 10
For parameter 10, it means that the disk space utilization rate of each node in the cluster does not exceed 10%, which can be adjusted according to the actual situation
Stop data equalization command
stop-balancer.sh
2. Data balance between disks
(1) Generate balance plan
hdfs diskbalancer -plan test-dj01
(2) Execute balanced plan
hdfs diskbalancer -execute test-dj01.plan.json
(3) view the execution of the current balancing task
hdfs diskbalancer -query test-dj01
(4) cancel the balancing task
hdfs diskbalancer -cancel hadoop103.plan.json
3. LZO create index
Create the index of lzo file. The slicability of lzo compressed file depends on its index, so we need to manually create the index for lzo compressed file. If there is no index, there is only one slice of lzo file;
The command to create the index is:
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo
4. Benchmark test
In the local virtual machine test, the company cluster is not used
1) Test HDFS write performance
Test content: write 10 128M files to HDFS cluster
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB 2020-04-16 13:41:24,724 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write 2020-04-16 13:41:24,724 INFO fs.TestDFSIO: Date & time: Thu Apr 16 13:41:24 CST 2020 2020-04-16 13:41:24,724 INFO fs.TestDFSIO: Number of files: 10 2020-04-16 13:41:24,725 INFO fs.TestDFSIO: Total MBytes processed: 1280 2020-04-16 13:41:24,725 INFO fs.TestDFSIO: Throughput mb/sec: 8.88 2020-04-16 13:41:24,725 INFO fs.TestDFSIO: Average IO rate mb/sec: 8.96 2020-04-16 13:41:24,725 INFO fs.TestDFSIO: IO rate std deviation: 0.87 2020-04-16 13:41:24,725 INFO fs.TestDFSIO: Test exec time sec: 67.61
2) Test HDFS read performance
Test content: read 10 128M files of HDFS cluster
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB 2020-04-16 13:43:38,857 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read 2020-04-16 13:43:38,858 INFO fs.TestDFSIO: Date & time: Thu Apr 16 13:43:38 CST 2020 2020-04-16 13:43:38,859 INFO fs.TestDFSIO: Number of files: 10 2020-04-16 13:43:38,859 INFO fs.TestDFSIO: Total MBytes processed: 1280 2020-04-16 13:43:38,859 INFO fs.TestDFSIO: Throughput mb/sec: 85.54 2020-04-16 13:43:38,860 INFO fs.TestDFSIO: Average IO rate mb/sec: 100.21 2020-04-16 13:43:38,860 INFO fs.TestDFSIO: IO rate std deviation: 44.37 2020-04-16 13:43:38,860 INFO fs.TestDFSIO: Test exec time sec: 53.61
3) Delete test generated data
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
4) Use Sort program to evaluate MapReduce
(1) RandomWriter is used to generate random numbers. Each node runs 10 Map tasks, and each Map generates binary random numbers with a size of about 1G
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data
(2) execute Sort program
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data
(3) verify whether the data are really in order
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
5.Hadoop parameter tuning
1)HDFS parameter tuning HDFS site xml
dfs.namenode.handler.count = [the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-ngyasnoe-1624345157754)( file:///C: \Users\wanyukun\AppData\Local\Temp\ksohtml20784\wps1. Jpg)], for example, when the cluster size is 8, this parameter is set to 41
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode There is a pool of worker threads to handle different tasks DataNode Concurrent heartbeat and concurrent metadata operations on the client.
For large clusters or clusters with a large number of clients, you usually need to increase the parameters dfs.namenode.handler.count The default value of 10.
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
2)yarnc parameter tuning yarn site xml
(1) Scenario Description: a total of 7 machines with hundreds of millions of data every day. Data source - > flume - > Kafka - > HDFS - > hive
Problems: HiveSQL is mainly used for data statistics. There is no data skew. Small files have been merged and reused by the opened JVM. Moreover, IO is not blocked and less than 50% of memory is used. However, it still runs very slowly, and when the peak of data volume comes, the whole cluster will go down. Based on this situation, there is no optimization scheme.
(2) Solution:
Insufficient memory utilization. This is generally caused by two configurations of Yarn. The maximum memory size that can be applied for by a single task and the available memory size of a single Hadoop node. Adjusting these two parameters can improve the utilization of system memory.
(a) yarn.nodemanager.resource.memory-mb Indicates on this node YARN The total amount of physical memory that can be used. The default is 8192( MB),Note that if your node memory resources are not enough 8 GB,You need to decrease this value, and YARN It will not intelligently detect the total physical memory of the node. (b) yarn.scheduler.maximum-allocation-mb The maximum amount of physical memory that can be applied for by a single task. The default is 8192( MB).
yarn.nodemanager.resource.memory-mb
Indicates the total amount of physical memory that can be used by YARN on the node. The default is 8192 (MB). Note that if your node memory resources are insufficient for 8GB, you need to reduce this value, and YARN will not intelligently detect the total amount of physical memory of the node.
(b) yarn.scheduler.maximum-allocation-mb
The maximum amount of physical memory that can be requested by a single task. The default is 8192 (MB).