 Rimeng Society
Rimeng Society
8.5 Sort Model Advancement-Wide&Deep
Learning Objectives
- target
- nothing
- application
- nothing
8.5.1 wide&deep
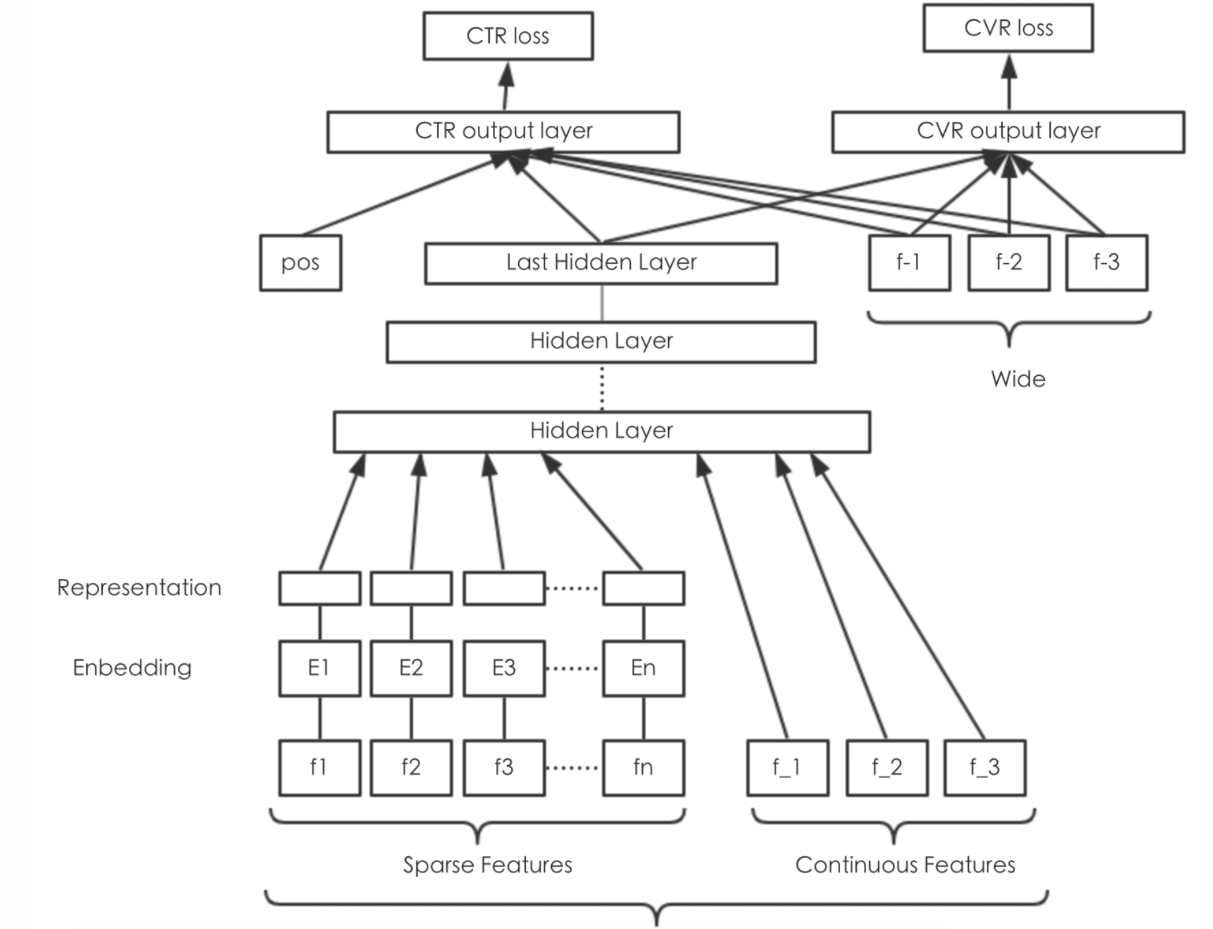
- Input characteristics of the Wide section:
- Discrete characteristics
- Combining discrete features
- It is used in the paper of W&D without input having continuous value characteristics.
-
Input characteristics of the Deep section:
- raw input+embeding processing
- Embedding features other than discontinuous values is the policy feature, which is multiplied by an embedding-matrix.The interface inside TensorFlow is:tf.feature_column.embedding_column, default trainable=True.
- The treatment of the continuous value feature is to compress it into [0,1] according to the cumulative distribution function P(X < x).
Note: Training: notice: Wide part uses FTRL to train; Deep part uses AdaGrad to train.
-
The API interface of Wide&Deep in TensorFlow is:tf.estimator.DNNLinearCombinedClassifier
- estimator = tf.estimator.DNNLinearCombinedClassifier()
- model_dir="",
- linear_feature_columns=wide_columns,
- dnn_feature_columns=deep_columns
- Dnn_Hidden_Units=[]: network structure of DNN layer
- estimator = tf.estimator.DNNLinearCombinedClassifier()
Tf.estimatorIncoming parameter principle
- LinearClassifier and LinearRegressor: Accept all types of feature columns.
- DNNClassifier and DNNRegressor: Only dense columns are accepted.Other types of columns must be encapsulated in indicator_column or embedding_column.
- DNNLinearCombinedClassifier and DNNLinearCombinedRegressor:
- Linear_Feature_The columns parameter accepts any type of feature column.
- Dnn_Feature_The columns parameter accepts only dense columns.
Code:
import tensorflow as tf
class WDL(object):
"""wide&deep Model
"""
def __init__(self):
pass
@staticmethod
def read_ctr_records():
# Define transformation functions, serialized at input
def parse_tfrecords_function(example_proto):
features = {
"label": tf.FixedLenFeature([], tf.int64),
"feature": tf.FixedLenFeature([], tf.string)
}
parsed_features = tf.parse_single_example(example_proto, features)
feature = tf.decode_raw(parsed_features['feature'], tf.float64)
feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])
# Feature Order 1 channel_Id, 100 article_Vector, 10 user_Weights, 10 article_Weights
# 1 channel_id-type features, 100-dimensional article vectors mean continuous features, 10-dimensional user weights mean continuous features
channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)
vector = tf.reduce_sum(tf.slice(feature, [0, 1], [1, 100]), axis=1)
user_weights = tf.reduce_sum(tf.slice(feature, [0, 101], [1, 10]), axis=1)
article_weights = tf.reduce_sum(tf.slice(feature, [0, 111], [1, 10]), axis=1)
label = tf.cast(parsed_features['label'], tf.float32)
# Construct Dictionary Name-tensor
FEATURE_COLUMNS = ['channel_id', 'vector', 'user_weigths', 'article_weights']
tensor_list = [channel_id, vector, user_weights, article_weights]
feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))
return feature_dict, label
dataset = tf.data.TFRecordDataset(["./train_ctr_201905.tfrecords"])
dataset = dataset.map(parse_tfrecords_function)
dataset = dataset.batch(64)
dataset = dataset.repeat()
return dataset
def build_estimator(self):
"""Modeling
:param dataset:
:return:
"""
# Discrete Classification
article_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)
# Continuous type
vector = tf.feature_column.numeric_column('vector')
user_weigths = tf.feature_column.numeric_column('user_weigths')
article_weights = tf.feature_column.numeric_column('article_weights')
wide_columns = [article_id]
# Embedding_A variable used by column to represent a type of category
deep_columns = [tf.feature_column.embedding_column(article_id, dimension=25),
vector, user_weigths, article_weights]
estimator = tf.estimator.DNNLinearCombinedClassifier(model_dir="./ckpt/wide_and_deep",
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[1024, 512, 256])
return estimator
if __name__ == '__main__':
wdl = WDL()
estimator = wdl.build_estimator()
estimator.train(input_fn=wdl.read_ctr_records)
eval_result = estimator.evaluate(input_fn=wdl.read_ctr_records)
print(eval_result)
8.5.2 Feature Data Processing Effect Comparison of Three Versions
| Processing effects with different characteristics | baseline | 1 Separate Three Features, Mean Article Vector, Mean User Weight, Mean Article Weight | 1 Discrete Feature, 1 111 Continuous Feature | 1 Discrete Feature, 100 Continuous Article Vectors, 10 Article Weights, 10 User Weights |
|---|---|---|---|---|
| accuracy | 0.9051438053097345 | 0.9046435 | 0.9046435 | 0.9046435 |
| auc | 0.719274521004087 | 0.57850575 | 0.5896939 | 0.62383443 |
Effect comparison summary:
- The number of discrete data for black horse headlines is too small, so the underlying model can solve the problem
- If the discrete or continuous characteristics increase, the use of WDL models will result in a certain degree of accuracy or AUC improvement.
Three Version Features Handle Data Functions and Build Models
- First version:
@staticmethod
def read_ctr_records_v1():
# Define transformation functions, serialized at input
def parse_tfrecords_function(example_proto):
features = {
"label": tf.FixedLenFeature([], tf.int64),
"feature": tf.FixedLenFeature([], tf.string)
}
parsed_features = tf.parse_single_example(example_proto, features)
feature = tf.decode_raw(parsed_features['feature'], tf.float64)
feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])
# Feature Order 1 channel_Id, 100 article_Vector, 10 user_Weights, 10 article_Weights
# 1 channel_id-type features, 100-dimensional article vectors mean continuous features, 10-dimensional user weights mean continuous features
channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)
vector = tf.reduce_mean(tf.slice(feature, [0, 1], [1, 100]), axis=1)
user_weights = tf.reduce_mean(tf.slice(feature, [0, 101], [1, 10]), axis=1)
article_weights = tf.reduce_mean(tf.slice(feature, [0, 111], [1, 10]), axis=1)
label = tf.cast(parsed_features['label'], tf.float32)
# Construct Dictionary Name-tensor
FEATURE_COLUMNS = ['channel_id', 'vector', 'user_weights', 'article_weights']
tensor_list = [channel_id, vector, user_weights, article_weights]
feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))
return feature_dict, label
dataset = tf.data.TFRecordDataset(["./ctr_train_20190706.tfrecords"])
dataset = dataset.map(parse_tfrecords_function)
dataset = dataset.batch(64)
dataset = dataset.repeat(100)
return dataset
def build_estimator(self):
"""
//Build a feature column to input into the model
:return:
"""
# Specify column characteristics
channel_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)
vector = tf.feature_column.numeric_column('vector')
user_weights = tf.feature_column.numeric_column('user_weights')
article_weights = tf.feature_column.numeric_column('article_weights')
# wide side
wide_columns = [channel_id]
# deep side
deep_columns = [
tf.feature_column.embedding_column(channel_id, dimension=25),
vector,
user_weights,
article_weights
]
# Construct Model
estimator = tf.estimator.DNNLinearCombinedClassifier(model_dir="./tmp/ckpt/wide_and_deep",
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[256, 128, 64])
return estimator
- Version 2:
@staticmethod
def read_ctr_records_v2():
# Define transformation functions, serialized at input
def parse_tfrecords_function(example_proto):
features = {
"label": tf.FixedLenFeature([], tf.int64),
"feature": tf.FixedLenFeature([], tf.string)
}
parsed_features = tf.parse_single_example(example_proto, features)
feature = tf.decode_raw(parsed_features['feature'], tf.float64)
feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])
channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)
label = tf.cast(parsed_features['label'], tf.float32)
# Construct Dictionary Name-tensor
FEATURE_COLUMNS = ['channel_id', 'feature']
tensor_list = [channel_id, feature]
feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))
return feature_dict, label
dataset = tf.data.TFRecordDataset(["./ctr_train_20190706.tfrecords"])
dataset = dataset.map(parse_tfrecords_function)
dataset = dataset.batch(64)
dataset = dataset.repeat(100)
return dataset
def build_estimator_v2(self):
"""
//Build a feature column to input into the model
:return:
"""
# Specify column characteristics
channel_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)
feature = tf.feature_column.numeric_column('feature', shape=[1, 121])
# wide side
wide_columns = [channel_id]
# deep side
deep_columns = [
tf.feature_column.embedding_column(channel_id, dimension=25),
feature
]
# Construct Model
estimator = tf.estimator.DNNLinearCombinedClassifier(model_dir="./tmp/ckpt/wide_and_deep_v2",
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[256, 128, 64])
return estimator
- Third Version
@staticmethod
def read_ctr_records_v3():
# Define transformation functions, serialized at input
def parse_tfrecords_function(example_proto):
features = {
"label": tf.FixedLenFeature([], tf.int64),
"feature": tf.FixedLenFeature([], tf.string)
}
parsed_features = tf.parse_single_example(example_proto, features)
feature = tf.decode_raw(parsed_features['feature'], tf.float64)
feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])
channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)
vector = tf.slice(feature, [0, 1], [1, 100])
user_weights = tf.slice(feature, [0, 101], [1, 10])
article_weights = tf.slice(feature, [0, 111], [1, 10])
label = tf.cast(parsed_features['label'], tf.float32)
# Construct Dictionary Name-tensor
FEATURE_COLUMNS = ['channel_id', 'vector', 'user_weights', 'article_weights']
tensor_list = [channel_id, vector, user_weights, article_weights]
feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))
return feature_dict, label
dataset = tf.data.TFRecordDataset(["./ctr_train_20190706.tfrecords"])
dataset = dataset.map(parse_tfrecords_function)
dataset = dataset.batch(64)
dataset = dataset.repeat(100)
return dataset
def build_estimator_v3(self):
"""
//Build a feature column to input into the model
:return:
"""
# Specify column characteristics
channel_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)
vector = tf.feature_column.numeric_column('vector', shape=[1, 100])
user_weights = tf.feature_column.numeric_column('user_weights', shape=[1, 10])
article_weights = tf.feature_column.numeric_column('article_weights', shape=[1, 10])
# wide side
wide_columns = [channel_id]
# deep side
deep_columns = [
tf.feature_column.embedding_column(channel_id, dimension=25),
vector,
user_weights,
article_weights
]
# Construct Model
estimator = tf.estimator.DNNLinearCombinedClassifier(model_dir="./tmp/ckpt/wide_and_deep_v3",
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[256, 128, 64])
return estimator