[source code analysis] how Facebook trains super large models -- - (5)
0x00 summary
As we mentioned earlier, Microsoft ZeRO can expand a trillion parameter model on 4096 NVIDIA A100 GPU s using 8-way model parallel, 64-way pipeline parallel and 8-way data parallel. FSDP (full sharded data parallel) is an upgraded version of PyTorch DDP proposed by Facebook after deeply learning from Microsoft ZeRO. It can be regarded as benchmarking Microsoft ZeRO, and its essence is parameter sharding. Parameter sharding is to divide model parameters into GPUs. We will use Google, Microsoft and Facebook papers, blogs and code for learning and analysis.
In the previous article, we mentioned that FSDP supports mixed accuracy training. In this article, let's take a look at activation recommendation.
Other articles in this series are as follows:
[Source code analysis] PyTorch distributed ZeroRedundancyOptimizer
[ZeRO of distributed training Parameter sharding
[Google Weight Sharding of distributed training Parameter Sharding
[[source code analysis] how Facebook trains super large models -- - (1)
[[source code analysis] how Facebook trains super large models -- - (2)
[[source code analysis] how Facebook trains super large models -- - (3)
[[source code analysis] how Facebook trains super large models -- - (4)
0x01 background
Activation recomputation, also known as "activation checkpointing" or "gradient checkpointing" (Chen et al, 2016) https://arvix.org/abs/1604.06174 ), the idea is to trade time for space, that is, sacrifice computing time for memory space. It reduces the memory overhead of deep neural network training layer at the cost of additional forward propagation calculation per batch.
For example, this method divides the m-layer network into d partitions on average, only saves the activation of the partition boundary, and exchanges these activation between workers. Because intermediate activations at intra partition layers are still needed to calculate the gradient during backward propagation, activation will be recalculated within the partition during backward propagation.
The following figure is the schematic diagram in the paper.
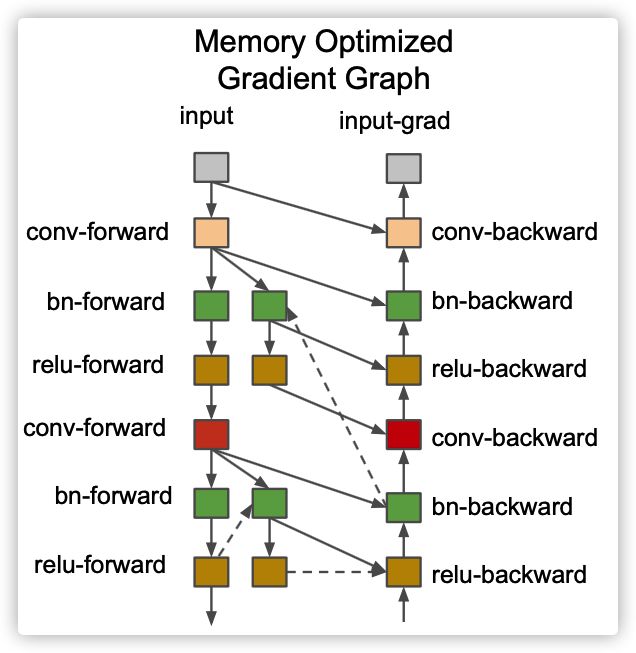
We introduced over calculation in the previous article[ Source code analysis] deep learning pipeline parallel GPipe(3) -- recalculation . This article will look at how FairScale further encapsulates and improves it.
0x02 train of thought
2.1 learning suggestions
Before looking at the ideas, let's talk about how to better analyze an open source framework or how to learn the source code. My personal opinion is to study in the order of paper -- > document -- > User Manual -- > notes -- > source code.
Why in this order? Because the order is:
- From abstract logic (or architecture) to concrete details.
- Papers are the result of refining, logicalizing and systematizing the author's ideas, followed by documents. And rereading classic papers, the harvest is multi-dimensional.
- The manual will help you understand the whole framework from the aspects of use or attention.
- The source code gives you a lot of details.
- From human thought to machine thought.
- Comments are given by the author to the reader, and code is given by the author to the machine.
- Comments will tell you Why and code will tell you How.
For us, we should first seek a change of thinking, update and sort out the knowledge framework, and then analyze and verify with code (after all, it is shallow on paper). Of course, most of the time we only have source code, we can only explore the details from the source code, reconstruct the author's thoughts, extract the essence, strive for a resonance with the author, and the more you resonate, the closer you get to the author.
2.2 specific ideas
Let's take a look at the idea introduction in the source code document.
Activating checkpoints is a technique used to reduce GPU memory usage during training. The specific measures are:
- Avoid storing intermediate activation tensors during forward propagation.
- In the backward propagation process, the forward propagation calculation is carried out again by tracking the original input.
The result is that the need to store large activation tensors is reduced with a slight increase in the computational cost (about 33%), so it allows us to increase the batch size, thereby increasing the net throughput of the model.
The checkpoint is activated by overloading torch autograd. Function.
- By using no in the forward function_ Grad, we can avoid the creation of forward calculation graph and the materialization of intermediate activation tensor for a long time (i.e. until the beginning of back propagation).
- During backward propagation, forward propagation is performed again, and then backward propagation is performed.
- The input propagated forward has been saved in the context object, so the original input can be obtained through the context object during backward propagation.
- Because it is used in some cases (dropout layouts), the forward and backward propagation Random Number Generator(RNG) states are also saved.
The above functions are in torch utils. checkpoint. checkpoint_ You can see its specific implementation in wrapper, and you can use this API to encapsulate the module in forward propagation. The wrapper in FairScale provides more functions than PyTorch API. For example, users can use FairScale nn. checkpoint. checkpoint_ Wrapper to wrap an NN Module, so you can process kwargs in the forward transfer, offload intermediate activation to the CPU, and process the non tensor output returned from the forward function.
2.3 best practices
Let's look at fairscale nn. checkpoint. checkpoint_ Best practices for wrapper.
- The effect of memory saving depends on how the model and checkpoint wrapping are segmented. That is, the benefit of memory savings depends on the memory usage of layer activation.
- When using BatchNormalization, you may need to freeze the calculation of statistics because in this case forward propagation is run twice.
- Ensure the requirements of the input tensor_ Set the grad property to True. By putting the requirements of the input tensor_ With the grad property set to True, we ensure that the input can be propagated to the output and trigger the backward function.
0x03 specific implementation
3.1 Wrapper
checkpoint_wrapper is a specific wrapper, which calls other functions internally. However, we found that its notes can let us further study, so the translation is as follows:
checkpoint_wrapper is a wrapper that executes activation checkpoints. It is more user-friendly than PyTorch version and has the following characteristics:
-
Pack a NN Module so that all subsequent calls will use checkpointing.
-
Process the keyword arguments in the forward procedure.
-
Process the non tensor output from the forward process.
-
Support uninstalling activation to CPU.
In order to better understand the benefits of checkpointing and "offload_to_cpu", we divide activation into two types:
- Internal activation. It relies on activation checkpointing to save.
- External activation, i.e. checkpoint module. It relies on offload_to_cpu to save.
In terms of GPU memory savings:
-
When the internal activation is large and the external activation is small, checkpoints will bring great benefits, offload_to_cpu may only bring small benefits.
-
When the internal activation is small and the external activation is large, the checkpoint help is small, offload_to_cpu will bring great benefits.
-
When both internal and external activation are large, checkpoint and offload_ to_ The benefits of CPU are superimposed.
In addition, the first and last layers are unlikely to benefit from offload_to_cpu flag because:
- The input of the first layer usually has other references, so the GPU memory will not be released;
- The input of the last layer will be immediately propagated back for use, which will not save memory.
def checkpoint_wrapper(
module: nn.Module, offload_to_cpu: bool = False, maintain_forward_counter: bool = False
) -> nn.Module:
"""
A friendlier wrapper for performing activation checkpointing.
Compared to the PyTorch version, this version:
- wraps an nn.Module, so that all subsequent calls will use checkpointing
- handles keyword arguments in the forward
- handles non-Tensor outputs from the forward
- supports offloading activations to CPU
Usage::
checkpointed_module = checkpoint_wrapper(my_module, offload_to_cpu=True)
a, b = checkpointed_module(x, y=3, z=torch.Tensor([1]))
To understand the benefits of checkpointing and the `offload_to_cpu` flag,
let's divide activations into 2 types: inner activations and outer
activations w.r.t. the checkpointed modules. The inner ones are saved
by activation checkpointing, the outer ones are saved by offload_to_cpu.
In terms of GPU memory savings:
- When inner ones are large in size and outer ones are small,
checkpointing helps a lot, offload_to_cpu may help a little.
- When inner ones are small and outer ones are large,
checkpointing helps little, offload_to_cpu helps a lot.
- When both inner and outer are large, both help and the
benefit is additive.
..Note::
The first and last layers are not likely to benefit from the `offload_to_cpu` flag
because (1) there are typically other references to the first layer's input, so
the GPU memory won't be freed; (2) the input to the last layer is immediately
used by the backward pass and won't result in memory savings.
Args:
module (nn.Module):
The module to be wrapped
offload_to_cpu (bool):
Whether to offload activations to CPU.
maintain_forward_counter (bool):
If True, maintain a forward counter per inner module. The counter will first
increases in forward calls of outer forward pass and then decreases in the
forward calls of outer backward pass. It is used by FullyShardedDataParallel.
Returns:
(nn.Module):
Wrapped module
"""
# Patch the batchnorm layers in case there are any in this module.
patch_batchnorm(module)
if maintain_forward_counter:
init_counter(module)
# The use of weakref here is to prevent creating a ref cycle: m -> m.forward -> m.
# When such cycle exists, gc won't collect the module when the module is freed.
# That causes GPU memory to be leaked. See the unit test for how we catch that.
#
# We prefer this over a class wrapper since the class wrapper would have to
# proxy a lot of fields and methods.
module.forward = functools.partial( # type: ignore
_checkpointed_forward, type(module).forward, weakref.ref(module), offload_to_cpu
)
return module # Pack a NN Module so that all subsequent calls will use checkpointing
3.2 how to use
We find some code from the source code, you can have a look.
self.layers = nn.Sequential(
nn.Sequential(nn.Linear(4, 4), nn.Linear(4, 4), nn.Linear(4, 8)),
nn.Sequential(nn.Linear(8, 4), nn.Linear(4, 4), nn.Linear(4, 4)),
nn.Sequential(nn.Linear(4, 6), nn.Linear(6, 8), nn.Linear(8, 2)),
)
if enable_checkpoint:
for i, layer in enumerate(self.layers):
# Only middle layer needs to have offloading
self.layers[i] = checkpoint_wrapper(layer, cpu_offload if i == 1 else False)
3.2 _checkpointed_forward
As mentioned earlier, compared with PyTorch version, FairScale has several benefits, which correspond to the following underlined two points:
-
Pack a NN Module so that all subsequent calls will use checkpointing.
-
Process the keyword arguments in the forward procedure.
-
Process the non tensor output from the forward process.
-
Support uninstalling activation to CPU.
The code logic is as follows:
- If disabled is disabled, use it directly forward() . This can also ensure that the internal fwd counter will not increase in the forward process, but this will be a problem in the eval process, because there will be no corresponding backward process to reduce the fwd counter.
- Because backward propagation must return a gradient (or None) for each input parameter, the Autograd function in PyTorch works best with location information parameters. Flattening keyword parameters can make this processing more convenient.
- Call the checkpoint function to complete activation checkpointing. Note here: when original_ When the input of forward is non tensor (i.e. a tuple), so the checkpoint function passes in a dummy tensor parameter with grad to ensure that backward propagation is called.
- When the input is tuple type, even if the tensor requires is set_ The grad flag also does not trigger backward propagation.
- Using this dummy tensor can avoid requiring the user to set the requirements of the input tensor_ Grad logo.
- Processing the output from the forward process as tuple is to package tensor and non tensor together.
The specific codes are as follows:
def _checkpointed_forward(
original_forward: Any, weak_self: Any, offload_to_cpu: bool, *args: Any, **kwargs: Any
) -> Any:
module = weak_self()
# If gradients are disabled, just use original `.forward()` method directly.
# Doing so also ensures the internal fwd counter is not incremented in the forward pass,
# which would be an issue during eval since there wouldn't be a corresponding backward pass
# to decrement the fwd counter.
# See https://github.com/facebookresearch/fairscale/pull/709.
if not torch.is_grad_enabled():
return original_forward(module, *args, **kwargs)
# Autograd Functions in PyTorch work best with positional args, since
# the backward must return gradients (or None) for every input argument.
# We can flatten keyword arguments to make this easier.
args = (module,) + args
kwarg_keys, flat_args = pack_kwargs(*args, **kwargs) # Processing input
parent_ctx_dict: Dict[str, Any] = {
"offload": offload_to_cpu,
}
# Dummy tensor with grad is used to ensure the backward pass is called. This is needed
# when original_forward's input are non-tensor (i.e. a tuple). Using this dummy tensor
# avoids requiring users to set their input tensors's requires_grad flag. In the case
# of tuple type inputs, setting the flag won't even trigger the backward pass.
output = CheckpointFunction.apply(
torch.tensor([], requires_grad=True), original_forward, parent_ctx_dict, kwarg_keys, *flat_args
)
# Processing non tensor output
if not isinstance(output, torch.Tensor):
# parent_ctx_dict["packed_non_tensor_outputs"] is returned by the checkpoint function
packed_non_tensor_outputs = parent_ctx_dict["packed_non_tensor_outputs"]
if packed_non_tensor_outputs:
# Unified processing into tuple
output = unpack_non_tensors(output, packed_non_tensor_outputs) # Processing output
return output
3.2.1 processing input
In the keyword arguments in the forward process, pack is used_ Kwargs is used to sort the key and value of parameters into two list s. For details, see the example.
def pack_kwargs(*args: Any, **kwargs: Any) -> Tuple[Tuple[str, ...], Tuple[Any, ...]]:
"""
Turn argument list into separate key list and value list (unpack_kwargs does the opposite)
Usage::
kwarg_keys, flat_args = pack_kwargs(1, 2, a=3, b=4)
assert kwarg_keys == ("a", "b")
assert flat_args == (1, 2, 3, 4)
args, kwargs = unpack_kwargs(kwarg_keys, flat_args)
assert args == (1, 2)
assert kwargs == {"a": 3, "b": 4}
"""
kwarg_keys: List[str] = []
flat_args: List[Any] = list(args)
for k, v in kwargs.items():
kwarg_keys.append(k)
flat_args.append(v)
return tuple(kwarg_keys), tuple(flat_args)
3.2.2 non tensor output
3.2.2.1 compressed non tensor
A tuple is divided into a tensor list and the information needed for subsequent reconstruction.
def split_non_tensors(
mixed: Union[torch.Tensor, Tuple[Any, ...]]
) -> Tuple[Tuple[torch.Tensor, ...], Optional[Dict[str, List[Any]]]]:
"""
Split a tuple into a list of tensors and the rest with information
for later reconstruction.
Usage::
x = torch.Tensor([1])
y = torch.Tensor([2])
tensors, packed_non_tensors = split_non_tensors((x, y, None, 3))
assert tensors == (x, y)
assert packed_non_tensors == {
"is_tensor": [True, True, False, False],
"objects": [None, 3],
}
recon = unpack_non_tensors(tensors, packed_non_tensors)
assert recon == (x, y, None, 3)
"""
if isinstance(mixed, torch.Tensor):
return (mixed,), None
tensors: List[torch.Tensor] = []
packed_non_tensors: Dict[str, List[Any]] = {"is_tensor": [], "objects": []}
for o in mixed:
if isinstance(o, torch.Tensor):
packed_non_tensors["is_tensor"].append(True)
tensors.append(o)
else:
packed_non_tensors["is_tensor"].append(False)
packed_non_tensors["objects"].append(o)
return tuple(tensors), packed_non_tensors
3.2.2.2 decompressing non tensor
unpack_non_tensors are used to restore non tensor lists to tuple s.
def unpack_non_tensors(
tensors: Tuple[torch.Tensor, ...], packed_non_tensors: Optional[Dict[str, List[Any]]]
) -> Tuple[Any, ...]:
"""See split_non_tensors."""
if packed_non_tensors is None:
return tensors
assert isinstance(packed_non_tensors, dict), type(packed_non_tensors)
mixed: List[Any] = []
is_tensor_list = packed_non_tensors["is_tensor"]
objects = packed_non_tensors["objects"]
obj_i = tnsr_i = 0
for is_tensor in is_tensor_list:
if is_tensor:
mixed.append(tensors[tnsr_i])
tnsr_i += 1
else:
mixed.append(objects[obj_i])
obj_i += 1
return tuple(mixed)
3.3 CheckpointFunction
Next, we analyze the checkpoint function, which is the business function of activation checkpointing. For the CheckpointFunction version of PyTorch, see[ Source code analysis] deep learning pipeline parallel GPipe(3) -- recalculation.
This corresponds to one of the advantages: support to unload the activation to the CPU.
3.3.1 forward propagation
The logic of forward propagation is as follows:
- Split the non tensor parameter list to obtain tensor input and non tensor input.
- If "offload" is set, the gradient demand is recorded in the context of the device, and the input tensor is put on the cpu.
- Save input for backward propagation.
- If activation checkpointing is set, the parameters will be processed for forward calculation.
- If the output is not tensor, because Autograd Functions does not like non tensor output. We can split it into non tensor and tensor output through parent_ ctx_ The dict reference returns the former, and then returns the latter directly.
class CheckpointFunction(torch.autograd.Function):
"""Similar to the torch version, but support non-Tensor outputs.
The caller is expected to provide a dict (*parent_ctx_dict*) that will hold
the non-Tensor outputs. These should be combined with the Tensor *outputs*
by calling :func:`unpack_non_tensors`.
"""
@staticmethod
def forward( # type: ignore
ctx: Any,
dummy_tensor_requires_grad: torch.Tensor,
run_function: Any,
parent_ctx_dict: Dict[str, Any],
kwarg_keys: Tuple[str, ...],
*args: Any,
**kwargs: Any
) -> Any:
torch_checkpoint.check_backward_validity(args)
ctx.run_function = run_function # Store forward propagation functions in context
ctx.kwarg_keys = kwarg_keys
ctx.fwd_rng_state = get_rng_state() # Store forward propagation state in context
ctx.had_autocast_in_fwd = is_autocast_enabled()
# Split the non tensor parameter list to obtain tensor input and non tensor input
tensor_inputs, packed_non_tensor_inputs = split_non_tensors(args)
if parent_ctx_dict["offload"]:
# In the context recording device, the gradient demand is recorded, and the input tensor is put on the cpu
ctx.fwd_device = tuple(x.device for x in tensor_inputs) # Forward propagation device in context storage
ctx.grad_requirements = tuple(x.requires_grad for x in tensor_inputs)
tensor_inputs = tuple(x.to("cpu", non_blocking=True) for x in tensor_inputs)
else:
ctx.fwd_device, ctx.grad_requirements = None, None
# Save input for backward propagation
ctx.save_for_backward(*tensor_inputs)
ctx.packed_non_tensor_inputs = packed_non_tensor_inputs
with torch.no_grad(), enable_checkpointing(): # If activation checkpointing is set
unpacked_args, unpacked_kwargs = unpack_kwargs(kwarg_keys, args) # Processing parameters
outputs = run_function(*unpacked_args, **unpacked_kwargs) # Forward calculation
the_module = unpacked_args[0]
inc_counter(the_module)
if not isinstance(outputs, torch.Tensor): # If the output is not a tensor
# Autograd Functions don't like non-Tensor outputs. We can split the
# non-Tensor and Tensor outputs, returning the former by reference
# through *parent_ctx_dict* and returning the latter directly.
# Autograd Functions does not like non tensor output. We can split it into non tensor and tensor output,
# Via parent_ ctx_ The dict reference returns the former, and then returns the latter directly.
outputs, packed_non_tensor_outputs = split_non_tensors(outputs)
parent_ctx_dict["packed_non_tensor_outputs"] = packed_non_tensor_outputs
return outputs
3.3.2 backward propagation
The logic of backward propagation is as follows:
- Get the tensor input stored in the context.
- If calculate on device is set, then:
- Move the off lad tensor onto the GPU.
- Find the gradient to be calculated.
- Deal with non tensor input and finally combine it with tensor input.
- Save the current state.
- The state when forward propagation is loaded from the context.
- Re do forward communication.
- Forward propagation output before processing.
- Restore the state of backward propagation.
- Find the tensor requiring gradient from the forward propagation output, and find the corresponding tensor from the backward propagation input.
- Backward propagation.
- Returns the gradient.
class CheckpointFunction(torch.autograd.Function):
"""Similar to the torch version, but support non-Tensor outputs.
The caller is expected to provide a dict (*parent_ctx_dict*) that will hold
the non-Tensor outputs. These should be combined with the Tensor *outputs*
by calling :func:`unpack_non_tensors`.
"""
@staticmethod
def backward(ctx: Any, *args: Any) -> Tuple[Optional[Tensor], ...]:
if not torch.autograd._is_checkpoint_valid():
raise RuntimeError("Checkpointing is not compatible with .grad(), please use .backward() if possible")
# Get the tensor input stored in the context
tensor_inputs: Tuple = ctx.saved_tensors
tensor_inputs = torch_checkpoint.detach_variable(tensor_inputs)
if ctx.fwd_device is not None: # If set, calculate on device
# Move the offload tensor onto the GPU
tensor_inputs = tuple(t.to(ctx.fwd_device[i], non_blocking=True) for i, t in enumerate(tensor_inputs))
for i, need_grad in enumerate(ctx.grad_requirements): # Find the gradient to be calculated
tensor_inputs[i].requires_grad = need_grad
# Deal with non tensor input and finally combine it with tensor input
inputs = unpack_non_tensors(tensor_inputs, ctx.packed_non_tensor_inputs)
# Store the current states.
bwd_rng_state = get_rng_state() # Get the current status saved before
# Set the states to what it used to be before the forward pass.
set_rng_state(ctx.fwd_rng_state) # State when loading forward propagation from context
with torch.enable_grad(), enable_recomputing(), autocast(ctx.had_autocast_in_fwd):
unpacked_args, unpacked_kwargs = unpack_kwargs(ctx.kwarg_keys, inputs)
outputs = ctx.run_function(*unpacked_args, **unpacked_kwargs) # Forward propagation again
tensor_outputs, _ = split_non_tensors(outputs) # Forward propagation output before processing
the_module = unpacked_args[0]
dec_counter(the_module)
# Set the states back to what it was at the start of this function.
set_rng_state(bwd_rng_state) # Restore the state of backward propagation
# Run backward() with only Tensors that require grad
outputs_with_grad = []
args_with_grad = []
# Find the tensor that needs gradient from the forward propagation output
for i in range(len(tensor_outputs)):
if tensor_outputs[i].requires_grad:
outputs_with_grad.append(tensor_outputs[i])
args_with_grad.append(args[i]) # Find the corresponding tensor in the input of backward propagation
if len(outputs_with_grad) == 0:
raise RuntimeError("None of the outputs have requires_grad=True, " "this checkpoint() is not necessary")
# Backward propagation
torch.autograd.backward(outputs_with_grad, args_with_grad)
# Get the gradient from inputs
grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else None for inp in inputs)
return (None, None, None, None) + grads # Return gradient
Our logic is as follows:
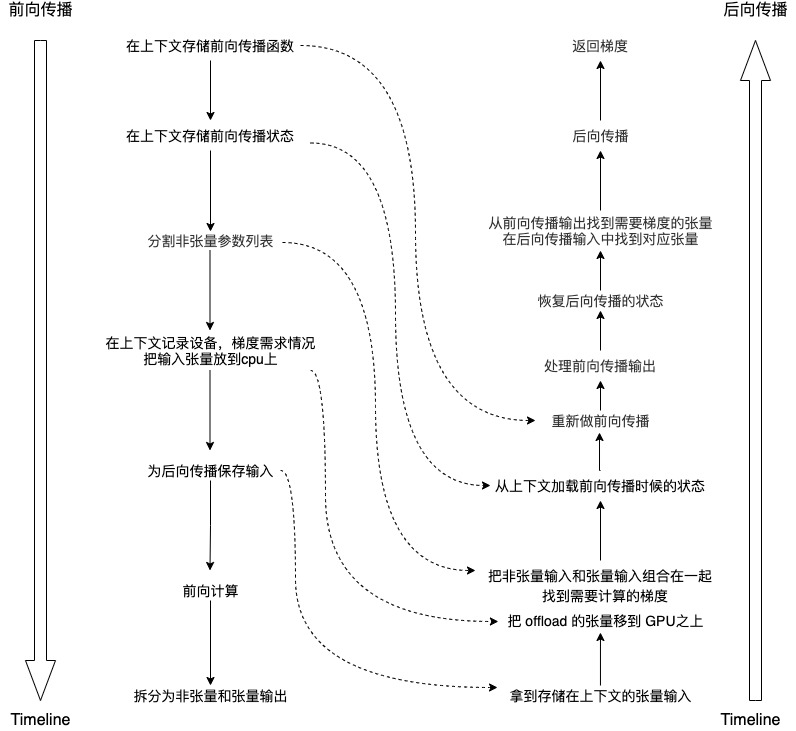
0x04 OffloadFunction
Previously, in the forward method of OffloadModel, if it is set_ checkpoint_activation, then call OffloadFunction to unload the activation checkpoint onto the CPU and return directly. Let's take a look at how OffloadFunction implements activation related operations.
This function overrides NN The forward and backward propagation of the module enables the middle activated checkpoint at the partition boundary. In this way, only the activation of the partition boundary is saved and exchanged between workers.
The main differences between this section and the previous section are:
- The checkpoint function just moves the input tensor between the GPU and the CPU, discarding the internal activation.
- OffloadFunction moves the activation (not discarded) and model between GPU and CPU, and because the partition is one or more layers, it only exchanges the activation of these partition boundaries between worker s.
4.1 forward propagation
In the FW process, it traverses each partition, deletes the parameters in the previous partition for each partition, loads the parameters of the next partition, and then performs the forward calculation of this partition. No calculation diagram was constructed during FW. This allows us to unload the intermediate activation on the partition boundary.
Here are some explanations:
- model_instance.model_slices are slices of a model. Each slice contains one or more layers.
- Except for the activation of the next partition, the activation between other partitions is stored on the CPU. Assuming that the target tensor is also located on the GPU performing the calculation, the output activation of the last layer of calculation should also be located on this GPU. If the output activation moves above the CPU, the back propagation may not find its gradient function.
The specific codes are as follows:
class OffloadFunction(torch.autograd.Function):
"""
This Function enables checkpointing of intermediate activations at
shard boundaries by overriding the forward and backward pass of the nn.Module.
- In the FW pass, it drops parameters in the previous shard and
loads parameters for the next shard. No graph is constructed in the FW pass.
This enables us to offload intermediate activations present at the shard
boundaries.
- In the BW pass, it does the reverse. We run the forward pass using the
saved intermediate activations and calculate gradients as needed.
The trade-off is latency vs memory when using activation checkpointing.
- Follows heavily from https://pytorch.org/docs/stable/_modules/torch/utils/checkpoint.html#checkpoint.
NOTE: see https://pytorch.org/docs/stable/autograd.html#torch.autograd.Function
"""
@staticmethod
@_conditional_amp_fwd_decorator # type: ignore
def forward(ctx: Any, inputs: Any, dummy_input: Any, model_instance: Any) -> Any:
inputs = inputs if isinstance(inputs, tuple) else (inputs,)
# Store the information needed for backward propagation in the context.
ctx.inputs = inputs
ctx.model_instance = model_instance
# TODO(anj-s): We might need to store this for each boundary activation.
# Currently we assume all boundary activation inputs require
ctx.grad_requirements = tuple(x.requires_grad for x in inputs)
ctx.fwd_rng_state = torch.get_rng_state()
# List of input activations starting with the given input.
model_instance._activations = [inputs]
# Enumerate through layer shards and apply activations from the previous shard.
for index, layer_shard in enumerate(model_instance.model_slices): # Traverse the partition of the model
with torch.autograd.profiler.record_function("fairscale.experimental.nn.offload:forward_load"):
# Bring in the current activations onto the device.
# Copy the current activation to the device
model_instance._activations[index] = tuple([a.cuda() for a in list(model_instance._activations[index])])
# Bring in the current layer shard onto the device.
# Load the current layer onto the device
layer_shard.forward_load()
# Apply the FP and store the activations on the CPU.
inputs = model_instance._activations[index]
with torch.autograd.profiler.record_function("fairscale.experimental.nn.offload:no_grad_forward_pass"):
with torch.no_grad(): # The following gradients are not tracked, only the activation is calculated
output_list: List[Any] = []
for given_input in inputs:
given_input_list = torch.chunk(given_input, model_instance._num_microbatches)
given_output_list = []
for inputs in given_input_list:
output = layer_shard(inputs) # Forward operation
given_output_list.append(output)
given_output = torch.cat(given_output_list).squeeze(-1)
output_list.append(given_output)
output = tuple(output_list) # Get output
output = output if isinstance(output, tuple) else (output,)
with torch.autograd.profiler.record_function("fairscale.experimental.nn.offload:forward_drop"):
# Move the activation used back for the curent shard back to the CPU.
# Move activation to CPU
model_instance._activations[index] = tuple([a.cpu() for a in list(model_instance._activations[index])])
# The newly computed activations remain on the GPU ready for the next shard computation.
model_instance._activations.append(output)
# Move the layer shard back to the CPU.
layer_shard.forward_drop() # Move layer to CPU
# The last instance will lose the gradient function if we move it to the CPU.
# This is because all grad function are present on the device that ran the FW pass.
# The last activation remains on the GPU and is the return value of this function.
# Note that this assumes that the target is also on the GPU which is required for calculating
# the loss.
result = model_instance._activations[-1] # Activation of the last layer
result = [r.cuda() for r in result] # Move the activation of the last layer to the device, and the rest have been moved to the CPU
for r in result:
r.requires_grad = True
return result[0] if len(result) == 1 else result
4.2 backward propagation
During BW, it performs the opposite operation. We use the saved intermediate activation to run forward propagation and calculate the gradient as needed. When using activation checkpoints, you need to weigh latency and memory. Because several built-in methods of PyTorch will be used here, we need to first look at its usage and principle.
4.2.1 no_grad
torch.no_grad() is a context manager, which is called No_ The code included in grad does not track its gradient. Let's take an example.
import torch
x = torch.tensor([2.2], requires_grad=True)
y = x * 3
print(y)
y.add_(2)
print(y)
with torch.no_grad():
y.div_(3)
print(y)
Output is:
tensor([6.6000], grad_fn=<MulBackward0>) # The gradient operation is recorded here tensor([8.6000], grad_fn=<AddBackward0>) # The add operation is tracked tensor([2.8667], grad_fn=<AddBackward0>) # Used no_grad, so div is not tracked
4.2.2 chunk
torch.chunk(tensor, chunk_num, dim) divides the tensor into chunks according to dimension (row or column)_ Num tensor blocks. This function will return a tuple, such as the following example.
x = torch.Tensor([[1,2,3]]) y = torch.Tensor([[4,5,6], [7,8,9], [10,11,12]]) z = torch.cat((x,y), dim=0) print(z) print(z.size()) c = torch.chunk(z,4,dim=0) print(c) print(len(c))
Output is:
# Output after cat
tensor([[ 1., 2., 3.],
[ 4., 5., 6.],
[ 7., 8., 9.],
[10., 11., 12.]])
torch.Size([4, 3])
# Output after chunk
(tensor([[1., 2., 3.]]), tensor([[4., 5., 6.]]), tensor([[7., 8., 9.]]), tensor([[10., 11., 12.]]))
4
4.2.3 back propagation
The backpropagation of OffloadFunction is as follows. Here is a reverse operation that needs attention.
- At the beginning of the code, the model will be divided into pieces and activated for reverse (note that the original allocation and activation are not reversed, here is the result returned after reverse, which will not affect the original data). Because the calculated gradient is from back to front, put - 1 in the first position, and so on, so it is convenient to use backward_load and backward_drop.
- At the end of the code, because the previous reverse has no effect on the model_instance._activations is modified, so you can directly return the gradient in the input.
The specific codes are as follows:
class OffloadFunction(torch.autograd.Function):
# Ignore the following function for code coverage since the backward pass
# is triggered by C++ code and cannot be calculated when overriding
# autograd.Function
@staticmethod
@_conditional_amp_bwd_decorator
def backward(ctx, *grad_outputs): # type: ignore # pragma: no cover
inputs = ctx.inputs
model_instance = ctx.model_instance
# Traverse the information stored in the context and set whether a gradient is required for the input
for i, need_grad in enumerate(ctx.grad_requirements):
inputs[i].requires_grad = need_grad
# Get back propagation input
all_grads = [grad_outputs]
# Divide the model into pieces and activate it to reverse (note that the original allocation and activation are not reversed, here is the result returned after reverse, which does not affect the original data). Because the calculated gradient is from back to front, put - 1 in the first position, and so on, so it is convenient to use backward_load and backward_drop.
# Then traverse the model partition and process each partition
for model_shard, activation in zip(
reversed(model_instance.model_slices), reversed(model_instance._activations[:-1])
):
with torch.autograd.profiler.record_function("fairscale.experimental.nn.offload:backward_load"):
# Move the activation to the GPU.
# Move the activation of the current partition to the GPU
activation = tuple([a.cuda() for a in list(activation)])
# Move the currently segmented model to GPU
# Move the model shard to the GPU.
model_shard.backward_load()
# Store the BW pass state.
# Temporary reverse propagation status
bwd_rng_state = torch.get_rng_state()
# TODO(anj-s): Why detach inputs?
activation = torch.utils.checkpoint.detach_variable(activation)
# Get the last gradient calculation.
final_grads = all_grads[-1] # This will be the final generated gradient
if isinstance(activation, torch.Tensor):
activation = (activation,)
if isinstance(final_grads, torch.Tensor):
final_grads = (final_grads,)
# Iterate through all the inputs/outputs of a shard (there could be multiple).
chunked_grad_list: List[Any] = []
# Chunk the activation and grad based on the number of microbatches that are set.
# Because there may be multiple micro batches, you need to chunk the gradient and activation respectively
for chunked_activation, chunked_grad in zip(
torch.chunk(*activation, model_instance._num_microbatches), # type: ignore
torch.chunk(*final_grads, model_instance._num_microbatches), # type: ignore
):
# Set the states to what it used to be before the forward pass.
torch.set_rng_state(ctx.fwd_rng_state) # Temporary use of forward propagation status
# Build as list
if isinstance(chunked_activation, torch.Tensor):
chunked_activation = (chunked_activation,) # type: ignore
if isinstance(chunked_grad, torch.Tensor):
chunked_grad = (chunked_grad,) # type: ignore
# Since we need a grad value of a non leaf element we need to set these properties.
for a in chunked_activation:
if a.dtype == torch.long:
continue
a.requires_grad = True # Because the non leaf node needs to be calculated, it is set to the required gradient
a.retain_grad()
with torch.autograd.profiler.record_function(
"fairscale.experimental.nn.offload:forward_pass_with_enable_grad"
):
with torch.enable_grad():
# calculate the output of the last shard wrt to the stored activation at the slice boundary.
outputs = model_shard(*chunked_activation) # Forward propagation
# Set the states back to what it was at the start of this function.
torch.set_rng_state(bwd_rng_state) # Restore state
with torch.autograd.profiler.record_function("fairscale.experimental.nn.offload:backward_pass"):
torch.autograd.backward(outputs, chunked_grad) # Back propagation
intermediate_grads = []
for a in chunked_activation:
if a.grad is not None:
intermediate_grads.append(a.grad)
if None not in intermediate_grads:
chunked_grad_list += intermediate_grads
# Add gradient list to all_ Above grads
if chunked_grad_list:
# Append the list of grads to the all_grads list and this should be on the GPU.
all_grads.append(torch.cat(chunked_grad_list).squeeze(-1)) # type: ignore
with torch.autograd.profiler.record_function("fairscale.experimental.nn.offload:backward_drop"):
# Move the shard back to the CPU. This should move all the grad tensors to CPU as well.
# We don't need to move activations since we are using a copy of the tensors on the GPU.
model_shard.backward_drop() # Move partition to CPU
# The previous reverse has no effect on the model_ instance._ Make changes to activations
detached_inputs = model_instance._activations[0]
# Get its gradient from the input
grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else inp for inp in detached_inputs)
return (None, None) + grads # Return gradient
The logical expansion is as follows:
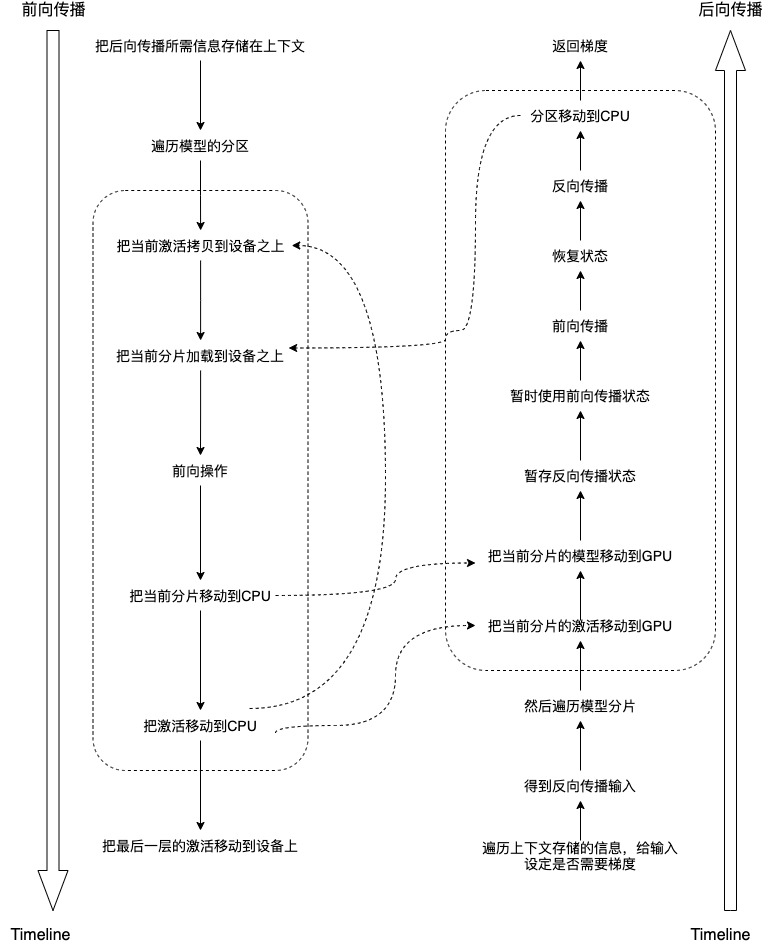
So far, FSDP analysis is completed. Our next series will introduce model parallelism through NVIDIA Megatron. Please look forward to it.
0xFF
https://arxiv.org/pdf/2101.06840.pdf
https://www.deepspeed.ai/tutorials/zero-offload/
DeepSpeed: Extreme-scale model training for everyone
[1] Li et al. "PyTorch Distributed: Experiences on Accelerating Data Parallel Training" VLDB 2020.
[2] Cui et al. "GeePS: Scalable deep learning on distributed GPUs with a GPU-specialized parameter server" EuroSys 2016
[3] Shoeybi et al. "Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism." arXiv preprint arXiv:1909.08053 (2019).
[4] Narayanan et al. "Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM." arXiv preprint arXiv:2104.04473 (2021).
[5] Huang et al. "GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism." arXiv preprint arXiv:1811.06965 (2018).
[6] Narayanan et al. "PipeDream: Generalized Pipeline Parallelism for DNN Training." SOSP 2019.
[7] Narayanan et al. "Memory-Efficient Pipeline-Parallel DNN Training." ICML 2021.
[8] Shazeer et al. "The Sparsely-Gated Mixture-of-Experts Layer Noam." arXiv preprint arXiv:1701.06538 (2017).
[9] Lepikhin et al. "GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding." arXiv preprint arXiv:2006.16668 (2020).
[10] Fedus et al. "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity." arXiv preprint arXiv:2101.03961 (2021).
[11] Narang & Micikevicius, et al. "Mixed precision training." ICLR 2018.
[12] Chen et al. 2016 "Training Deep Nets with Sublinear Memory Cost." arXiv preprint arXiv:1604.06174 (2016).
[13] Jain et al. "Gist: Efficient data encoding for deep neural network training." ISCA 2018.
[14] Shazeer & Stern. "Adafactor: Adaptive learning rates with sublinear memory cost." arXiv preprint arXiv:1804.04235 (2018).
[15] Anil et al. "Memory-Efficient Adaptive Optimization." arXiv preprint arXiv:1901.11150 (2019).
[16] Rajbhandari et al. "ZeRO: Memory Optimization Towards Training A Trillion Parameter Models Samyam." arXiv preprint arXiv:1910.02054 (2019).