[source code analysis] how PyTorch uses GPU
0x00 summary
During PyTorch DataParallel training, it will copy model copies on multiple GPUs before starting training. During the analysis, the author found that it is difficult to understand the process of copying the model of DataParallel without sorting out some basic knowledge related to GPU.
Other articles in this series are as follows:
Automatic differentiation of deep learning tools (1)
Automatic differentiation of deep learning tools (2)
[Source code analysis] automatic differentiation of deep learning tools (3) -- example interpretation
[Source code analysis] how PyTorch implements forward propagation (1) -- basic class (I)
[Source code analysis] how PyTorch implements forward propagation (2) -- basic classes (Part 2)
[Source code analysis] how PyTorch implements forward propagation (3) -- specific implementation
[Source code analysis] how pytoch implements backward propagation (1) -- call engine
[Source code analysis] how pytoch implements backward propagation (2) -- engine static structure
[Source code analysis] how pytoch implements backward propagation (3) -- engine dynamic logic
[Source code analysis] how PyTorch implements backward propagation (4) -- specific algorithm
[Source code analysis] PyTorch distributed (1) -- history and overview
0x01 problem
Before the forward propagation of DataParallel, it is necessary to disperse the data on the GPU and copy the model, as shown in the figure below.
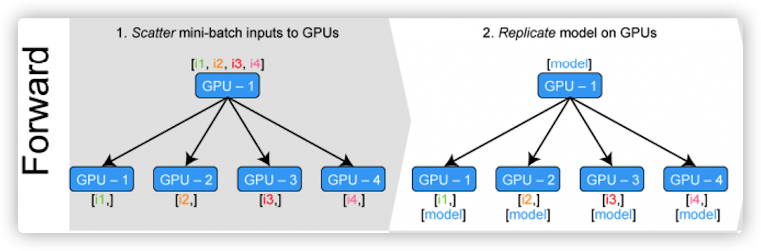
Therefore, we have several questions:
- What are the operations behind the action of moving the model to the GPU?
- How to call GPU operation on CPU?
- How to seamlessly switch between CPU and GPU operations?
- Do you need to move the loss function onto the GPU?
Let's analyze them one by one.
Note: CUDA and Dispatcher are only briefly introduced, so that readers can go through the whole process, and interested readers can conduct in-depth research by themselves.
0x02 move model to GPU
2.1 cuda operation
CUDA is a GPU Programming Model developed by NVIDIA company. It provides GPU Programming interface. Users can build applications based on GPU computing based on CUDA Programming.
Torch.cuda is used to set CUDA and run CUDA operations. It tracks the currently selected GPU, and by default, all CUDA tensors assigned by the user will be created on the device. You can use torch.cuda.device to modify the selected device. Once the tensor is assigned, you can perform operations on it regardless of the selected device, and PyTorch will put the running results on the same device as the original tensor.
By default, except ~ torch.Tensor.copy_ Except for other methods with similar replication functions (such as ~ torch.Tensor.to and ~ torch.Tensor.cuda), cross GPU operations are not allowed unless peer-to-peer memory access is enabled.
We find a specific example from the source code as follows. As you can see, tensors can be created and operated on the device.
cuda = torch.device('cuda') # Default CUDA device
cuda0 = torch.device('cuda:0')
cuda2 = torch.device('cuda:2') # GPU 2 (these are 0-indexed)
x = torch.tensor([1., 2.], device=cuda0)
# x.device is device(type='cuda', index=0)
y = torch.tensor([1., 2.]).cuda()
# y.device is device(type='cuda', index=0)
with torch.cuda.device(1):
# allocates a tensor on GPU 1
a = torch.tensor([1., 2.], device=cuda)
# transfers a tensor from CPU to GPU 1
b = torch.tensor([1., 2.]).cuda()
# a.device and b.device are device(type='cuda', index=1)
# You can also use ``Tensor.to`` to transfer a tensor:
b2 = torch.tensor([1., 2.]).to(device=cuda)
# b.device and b2.device are device(type='cuda', index=1)
c = a + b
# c.device is device(type='cuda', index=1)
z = x + y
# z.device is device(type='cuda', index=0)
# even within a context, you can specify the device
# (or give a GPU index to the .cuda call)
d = torch.randn(2, device=cuda2)
e = torch.randn(2).to(cuda2)
f = torch.randn(2).cuda(cuda2)
# d.device, e.device, and f.device are all device(type='cuda', index=2)
2.2 Module
The model of deep learning can be regarded as a container of parameters. In fact, the operation model is to do some basic matrix operations on the input parameters. Generally speaking, user-defined models are derived from the nn.modules.module class. Distributed training involves synchronously updating parameters and copying models to multiple worker s, so we first need to look at the status of the Module. It can be seen from the definition that the member variables of Module are mainly divided into state parameters and hooks functions.
class Module:
dump_patches: bool = False
_version: int = 1
training: bool
_is_full_backward_hook: Optional[bool]
def __init__(self):
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters = OrderedDict() # Parameters that will be updated with BP during training
self._buffers = OrderedDict() # Parameters that will not be updated with BP during training
self._non_persistent_buffers_set = set()
self._backward_hooks = OrderedDict()
self._is_full_backward_hook = None
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
self._modules = OrderedDict()
We mainly describe the state parameters. There are four main status parameters:
-
self.training
- Whether the network is training.
-
self._modules
- It is a sub module of the network, which is defined in an iterative way.
-
self._parameters
- Parameters of the network. It is the parameter that will be updated with BP in the training process, that is, the object of gradient update.
-
self._buffers
- In the training process, parameters that will not be updated with BP but need to be saved, such as moving mean and variance in BatchNorm. Their optimization is not through gradient back propagation, but through other ways.
In essence, when the network structure of a model is defined, self_ Parameters and self_ The combination of buffers is the specific state of a model. If you need to copy a model:
- self._modules are part of the network structure. When we copy models to other workers, they will be copied together.
- And self_ Parameters and self_ Buffers need to be explicitly copied to other worker s in order to maintain the same state in different Python processes.
So, does this mean that we only need to copy self_ modules,self._parameters and self_ Buffers, that's all? Let's move on.
2.3 movement
2.3.1 example
Having seen how to manipulate tensors on the GPU, let's take a look at how to place the model on the GPU.
First, we define a model.
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
Then use the model as follows.
model = ToyModel().cuda(device_ids[0]) # Here, copy the model to the GPU ddp_model = DDP(model, device_ids) loss_fn = nn.MSELoss() # Then train optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) optimizer.zero_grad() outputs = ddp_model(torch.randn(20, 10)) labels = torch.randn(20, 5).to(device_ids[0]) loss_fn(outputs, labels).backward() optimizer.step()
2.3.2 operation
In the example, the cuda method is used to copy the model to the GPU. The annotation indicates that the parameters and buffers of the model are moved to the GPU. The code actually uses self_ Apply to call cuda(device).
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:
r"""Moves all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So
it should be called before constructing optimizer if the module will
live on GPU while being optimized.
.. note::
This method modifies the module in-place.
Args:
device (int, optional): if specified, all parameters will be
copied to that device
Returns:
Module: self
"""
return self._apply(lambda t: t.cuda(device))
Let's look at some other familiar functions.
First, the essence of the to method is to use self_ Apply to call to(device), we omitted some verification code.
def to(self, *args, **kwargs):
r"""Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
.. function:: to(dtype, non_blocking=False)
.. function:: to(tensor, non_blocking=False)
.. function:: to(memory_format=torch.channels_last)
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point or complex :attr:`dtype`s. In addition, this method will
only cast the floating point or complex parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point or complex dtype of
the parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
memory_format (:class:`torch.memory_format`): the desired memory
format for 4D parameters and buffers in this module (keyword
only argument)
Returns:
Module: self
"""
device, dtype, non_blocking, convert_to_format = torch._C._nn._parse_to(*args, **kwargs)
def convert(t):
if convert_to_format is not None and t.dim() in (4, 5):
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None,
non_blocking, memory_format=convert_to_format)
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
return self._apply(convert)
Secondly, the cpu method also uses self_ Apply to call cpu(device).
def cpu(self: T) -> T:
r"""Moves all model parameters and buffers to the CPU.
.. note::
This method modifies the module in-place.
Returns:
Module: self
"""
return self._apply(lambda t: t.cpu())
Therefore, we need to analyze it_ apply method.
2.3.3 _apply method
We can see that the main logic is:
- Traversal_ parameters:
- Process the parameter call fn to get param_applied.
- Use param_applied resets the parameters.
- If the parameter has a gradient, then:
- Process the grad call fn of the parameter to get grad_applied.
- With grad_applied resets the gradient of the parameter.
- Process the parameter call fn to get param_applied.
- Traversal_ buffers:
- Process the buf call fn.
def _apply(self, fn):
for module in self.children():
module._apply(fn)
def compute_should_use_set_data(tensor, tensor_applied):
if torch._has_compatible_shallow_copy_type(tensor, tensor_applied):
# If the new tensor has compatible tensor type as the existing tensor,
# the current behavior is to change the tensor in-place using `.data =`,
# and the future behavior is to overwrite the existing tensor. However,
# changing the current behavior is a BC-breaking change, and we want it
# to happen in future releases. So for now we introduce the
# `torch.__future__.get_overwrite_module_params_on_conversion()`
# global flag to let the user control whether they want the future
# behavior of overwriting the existing tensor or not.
return not torch.__future__.get_overwrite_module_params_on_conversion()
else:
return False
# Traversal_ parameters
for key, param in self._parameters.items():
if param is not None:
# Tensors stored in modules are graph leaves, and we don't want to
# track autograd history of `param_applied`, so we have to use
# `with torch.no_grad():`
with torch.no_grad():
param_applied = fn(param) # Process the parameter call fn to get param_applied
should_use_set_data = compute_should_use_set_data(param, param_applied)
if should_use_set_data:
param.data = param_applied # Use param_applied reset
else:
assert isinstance(param, Parameter)
assert param.is_leaf
# # Use param_applied reset
self._parameters[key] = Parameter(param_applied, param.requires_grad)
if param.grad is not None: # If the parameter has a gradient
with torch.no_grad():
grad_applied = fn(param.grad) # Handle the grad call fn of the parameter
should_use_set_data = compute_should_use_set_data(param.grad, grad_applied)
if should_use_set_data:
param.grad.data = grad_applied # With grad_applied reset
else:
assert param.grad.is_leaf
self._parameters[key].grad = grad_applied.requires_grad_(param.grad.requires_grad) # With grad_applied reset
# Traversal_ buffers
for key, buf in self._buffers.items():
if buf is not None:
self._buffers[key] = fn(buf) # Process buf call fn
return self
Therefore, we can see that moving the model to the GPU is actually the self of the model_ Parameters and self_ The buffers are moved to the GPU and are not used for self_ Modules. We do. cuda() processing on the model, which is to put the parameters of the model into the video memory (these parameters are also used for operation in actual use).
For example, the original model is on the left of the figure below. After Module.cuda() operation, the model is shown on the right.
+
|
+---------------------------------+ | +----------------------------------+
| CPU | | | CPU |
| +--------------+ | | | +--------------------+ |
| |Module | | | | | Module | |
| | | | | | | | |
| | _parameters+----> Parameters | | | | _parameters ------+ |
| | | | | | | | | |
| | _buffers +------> Buffers | | | +-----+ _buffers | | |
| | | | | | | | | | |
| | _modules | | | | | | _modules | | |
| | | | | | | | | | |
| +--------------+ | | | | +--------------------+ | |
| | | | | | |
+---------------------------------+ | +----------------------------------+
| | |
+ | |
+-------------------------------> Module.cuda() +---------------------------------> Time
+ | |
| | |
+---------------------------------+ | +----------------------------------+
| GPU | | | GPU | | |
| | | | | | |
| | | | | Parameters <-----+ |
| | | | | |
| | | | | |
| | | | +----> Buffers |
| | | | |
| | | | |
+---------------------------------+ | +----------------------------------+
|
+
Why self_ modules have not been moved? This is because it is not necessary, because_ modules can be regarded as a list, which mainly acts as a bridge. Its recursive traversal can be used to obtain all the parameters of the network. This function is not necessary in subsequent operations.
DP broadcasts the parameters and buffer s on the master node to other nodes before each network propagation, so as to maintain the unity of state.
2.4 summary
Now we can answer the first question: what are the operations behind the action of moving the model to the GPU?
Answer: calling cuda or to method to move the model to GPU is actually the self_ Parameters and self_ The buffers are moved to the GPU and are not used for self_ Modules. This moving process is called recursively, which moves each leaf of the model to the GPU.
0x03 calling function on GPU
3.1 CUDA Programming Model Foundation
Let's first introduce the basis of CUDA Programming Model.
3.1.1 heterogeneous model
CUDA Programming model is a heterogeneous model. The program runs on a heterogeneous system, which is composed of CPU and GPU. They are separated by bus. When the program runs, CPU and GPU work together.
In CUDA, there are two important concepts: host and device.
-
Host: CPU and its memory.
-
Device: GPU and its memory.
Therefore, a program under CUDA architecture is also divided into two parts: host code and device code, which run on CPU and GPU respectively. host and device can communicate to copy data.
- Host Code: the part executed on the CPU and compiled with Linux (GNU gcc) and Windows (Microsoft Visual C) compilers. It can be roughly considered that the working objects of C language are CPU and memory module.
- Device Code: the part executed on the GPU and compiled by NVIDIA NVCC compiler. It can be roughly considered that the working objects of CUDA C are GPU and memory on GPU (also known as device memory).
+-------------------+ +--------------------+
| | | |
| +----------+ | | +----------+ |
| | | | | | | |
| | RAM | | | | RAM | |
| | | | | | | |
| +----+-----+ | | +----+-----+ |
| | +--------+ | |
| | | | | |
| +----+-----+ | | +----+-----+ |
| | | | | | | |
| | CPU | | | | GPU | |
| | | | | | | |
| +----------+ | | +----------+ |
| | | |
+-------------------+ +--------------------+
Host Device
3.1.2 parallel thinking
The idea of CUDA Programming is parallel, which is roughly as follows:
- Divide a large execution task into several simple and repeatable operations, and then use several threads to execute these operations respectively to achieve the purpose of parallelism.
- The data processed by the task should also be divided into multiple small data blocks. For example, a big data is divided into several GPU groups, and each GPU group is divided into multiple thread groups again. The tensor in the thread group may need to be subdivided into groups that can be processed by the tensor processor.
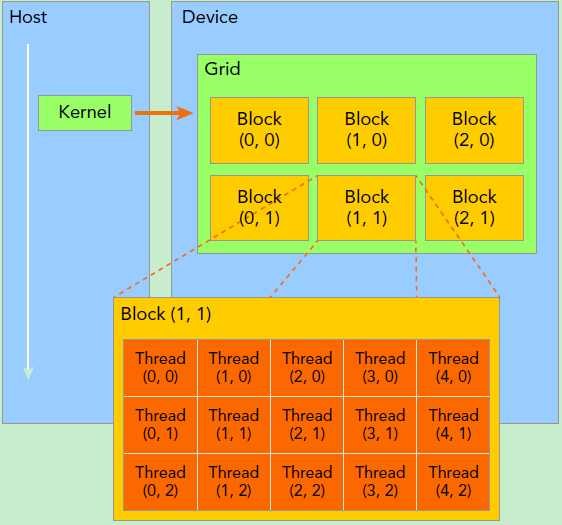
Therefore, a typical CUDA program includes serial code and parallel code.
- The serial code is the standard C code, which is executed by the host.
- Parallel code is CUDA C code, which is executed in device.
The CUDA main program starts with the CPU, that is, the program starts with the serial code executed by the host. When the part requiring data parallel processing is encountered, the device executes the parallel code as a supplement. Device can perform most operations independently of the host. When a device code is started, control will be immediately returned to the CPU to perform other tasks, so this is an asynchronous process.
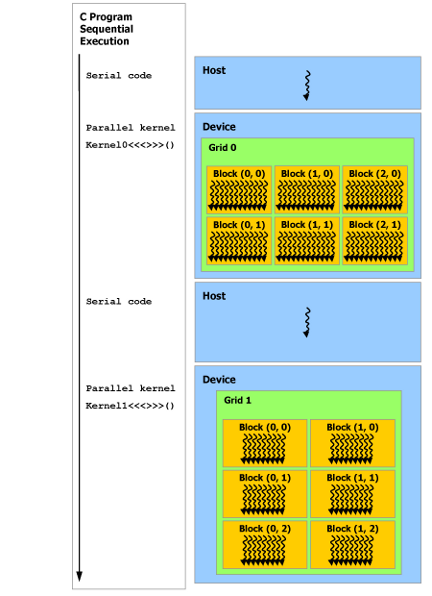
Figure from https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html.
3.1.3 treatment process
The execution flow of a typical CUDA program is as follows:
- Allocate host memory space and initialize data.
- Allocate device memory space.
- Copy the data to be calculated from the Host memory to the device video memory.
- Call CUDA kernel function to complete the operation specified by the user on device.
- Copy the calculated results from GPU memory to Host memory.
- Free the memory allocated on device and host.
See the figure below for details.
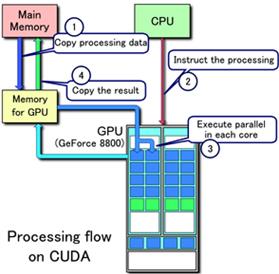
3.2 function
3.2.1 kernel function
Kernel functions are functions executed in parallel in the device thread. In CUDA program, the main program needs to configure the GPU kernel before calling it to determine the number of thread blocks, the number of threads in each thread block and the size of shared memory. For example, when calling, you need to use < < parameter 1, parameter 2 > > to specify the number of threads required by the kernel function and how the threads are organized. In this way, several threads will be started in the GPU to execute the kernel function in parallel, and each thread will be assigned a unique thread number.
CUDA uses function type qualifiers to distinguish functions on host and device. The three main function type qualifiers are:
| qualifier | implement | call | remarks |
|---|---|---|---|
| __global__ | Device side execution | It can be called from the host or from some specific device | Asynchronous operation. After the host sends the parallel computing task to the task call list of the GPU, it will not wait for the kernel to execute the next step |
| __device__ | Device side execution | Device side call | Not with__ global__ Simultaneous use |
| __host__ | Host side execution | Host call | It can be omitted and cannot be combined__ global__ Can be used at the same time__ device__ At the same time, the function is compiled in both device and host. |
The details are as follows:
The details are as follows:
+------------------------+ +------------------------+
| | | |
| | | |
| __host__ __global__ | | __device__ |
| + + | | |
| | | | | + |
| | | | | | |
| | v---------------> | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | +<--------------v | |
| | | | | | |
| | | | | | |
| | | | | | |
| v v | | v |
| | | |
+------------------------+ +------------------------+
Host Device
These three qualifiers are actually three common running scenarios in CUDA. Among them, the device function and global function cannot call some common C/C + + functions because they need to run on the GPU (because these functions have no corresponding GPU Implementation).
The following code is an example of NVIDIA. Using the built-in threadIdx variable, add the tensors A and B to get C. Therefore, each of the N threads executes VecAdd().
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
3.2.2 PyTorch example
We start from third_party/cub/cub/device/dispatch/dispatch_reduce.cuh find a kernel function example to see.
/**
* Reduce region kernel entry point (multi-block). Computes privatized reductions, one per thread block.
*/
template <
typename ChainedPolicyT, ///< Chained tuning policy
typename InputIteratorT, ///< Random-access input iterator type for reading input items \iterator
typename OutputIteratorT, ///< Output iterator type for recording the reduced aggregate \iterator
typename OffsetT, ///< Signed integer type for global offsets
typename ReductionOpT> ///< Binary reduction functor type having member <tt>T operator()(const T &a, const T &b)</tt>
__launch_bounds__ (int(ChainedPolicyT::ActivePolicy::ReducePolicy::BLOCK_THREADS))
__global__ void DeviceReduceKernel(
InputIteratorT d_in, ///< [in] Pointer to the input sequence of data items
OutputIteratorT d_out, ///< [out] Pointer to the output aggregate
OffsetT num_items, ///< [in] Total number of input data items
GridEvenShare<OffsetT> even_share, ///< [in] Even-share descriptor for mapping an equal number of tiles onto each thread block
ReductionOpT reduction_op) ///< [in] Binary reduction functor
{
// The output value type
typedef typename If<(Equals<typename std::iterator_traits<OutputIteratorT>::value_type, void>::VALUE), // OutputT = (if output iterator's value type is void) ?
typename std::iterator_traits<InputIteratorT>::value_type, // ... then the input iterator's value type,
typename std::iterator_traits<OutputIteratorT>::value_type>::Type OutputT; // ... else the output iterator's value type
// Thread block type for reducing input tiles
typedef AgentReduce<
typename ChainedPolicyT::ActivePolicy::ReducePolicy,
InputIteratorT,
OutputIteratorT,
OffsetT,
ReductionOpT>
AgentReduceT;
// Shared memory storage
__shared__ typename AgentReduceT::TempStorage temp_storage;
// Consume input tiles
OutputT block_aggregate = AgentReduceT(temp_storage, d_in, reduction_op).ConsumeTiles(even_share);
// Output result
if (threadIdx.x == 0)
d_out[blockIdx.x] = block_aggregate;
}
3.3 summary
At present, we know that PyTorch can actually be called__ global__ Method to perform parallel operations on the GPU. This answers our second question: how to invoke GPU operations on the CPU?
0x04 switch between GPU/CPU
Next, we analyze how to switch between GPU/CPU.
As can be seen from the example code, as long as the cuda function is called to move the model to the GPU, we can use the CUDA global kernel function to perform parallel operations on the GPU.
model = ToyModel().cuda(device_ids[0]) # Here, copy the model to the GPU ddp_model = DDP(model, device_ids) loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) optimizer.zero_grad() outputs = ddp_model(torch.randn(20, 10))
However, we have ignored a problem, that is, how does PyTorch know that the global kernel function corresponding to the GPU should be called at this time? Why doesn't PyTorch call CPU functions or functions of other devices? This is what we need to analyze next.
4.1 Dispatcher mechanism
Here we mainly learn from http://blog.ezyang.com/2020/09/lets-talk-about-the-pytorch-dispatcher/.
4.1.1 problems
In PyTorch, the expected behavior of the operator is caused by the joint action of many mechanisms, such as:
- The kernel that does the actual work.
- Whether reverse automatic differentiation is supported, for example, the flag bit that makes loss.backward() work properly.
- Whether torch.jit.trace is enabled.
- If you are calling vmap, the running operator will show different batch behavior.
Therefore, we know that there are too many different ways to interpret PyTorch operator differently. If we try to handle all behaviors in a single function called add, our implementation code will soon evolve into an unmaintainable mess.
Therefore, we need to have a mechanism to solve this problem. This mechanism is not just an if statement, but a very important abstraction inside PyTorch, and it must do this without reducing the performance of PyTorch as much as possible. This mechanism is the Dispatcher.
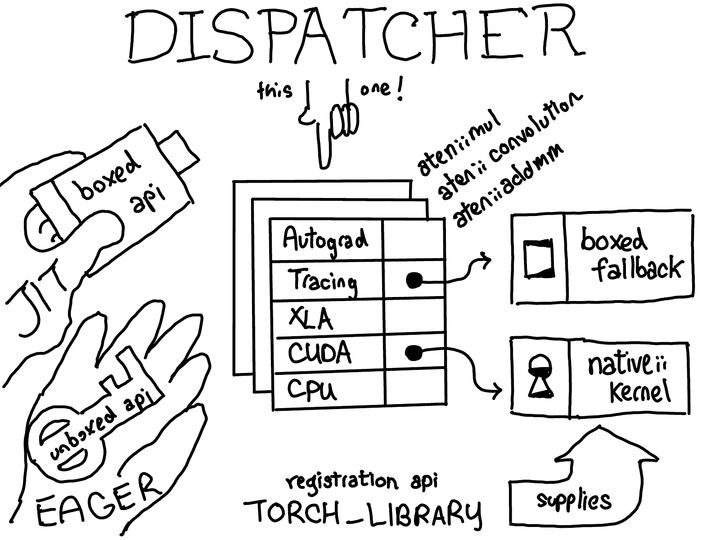
4.1.2 what is a Dispatcher
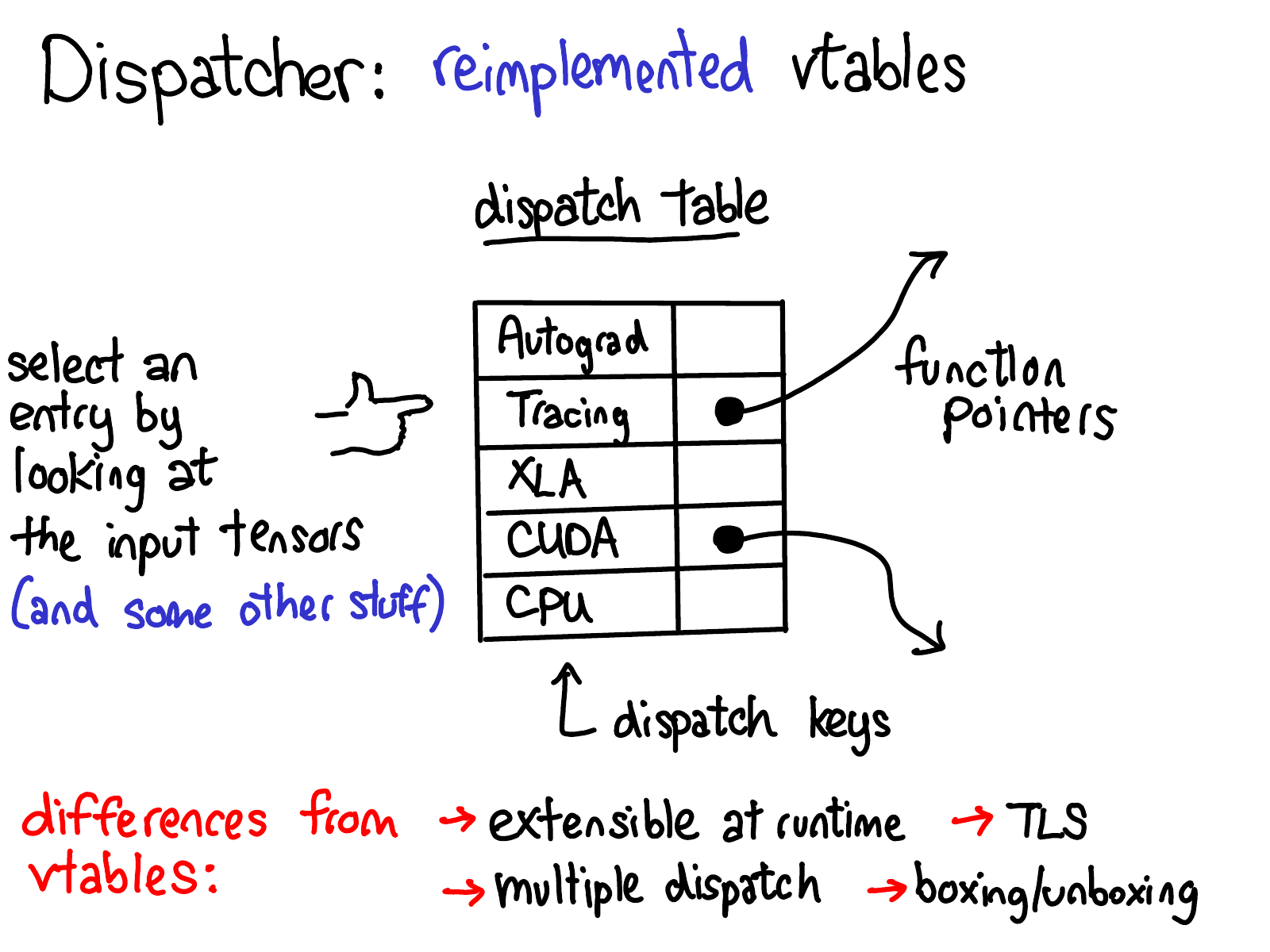
What is a dispatcher? The dispatcher maintains a function pointer table for each operator. These functions provide corresponding implementations for each dispatch key. This mechanism roughly corresponds to a crosscutting concern in PyTorch. In the figure above, you can see that there are dispatch entries for different backend (CPU, CUDA, XLA) and higher-level concepts (such as autograd and tracking) in this table. The dispatcher's job is to calculate a dispatch key according to the input tensor and other things, and then jump to the function pointed to by the function pointer table.
People familiar with C + + may notice that this function pointer table is very similar to the virtual table in C + +. In C + +, the virtual function of an object is realized by associating each object with the pointer of a virtual table, which contains the implementation of each virtual function on the object. In PyTorch, we basically re implemented the virtual table, but there are some differences.
- The dispatch table is allocated by operator, while the virtual table is allocated by class. This means that we can extend the set of supported operators by assigning a new dispatch table. The difference is that for a C + + object, you can extend the type by inheriting subclasses, but you can't easily add virtual functions. Unlike ordinary object-oriented systems, most of PyTorch's scalability lies in defining new operators (rather than new subclasses), so this trade-off is reasonable. In addition, the types of dispatch keys are not publicly extensible. We hope that users who want to add new dispatch keys can add their dispatch keys by submitting a patch to the PyTorch core team.
- The calculation of our dispatch key takes into account all the parameters of the operator (multiple dispatch) and the thread local state (TLS). This is different from the virtual table, where only the first object (this pointer) is important.
- Finally, dispatcher supports boxing and unboxing as part of the op's calling convention. There will be more about this in the last part of the article.
Interesting historical note: We used virtual functions to implement dynamic dispatch. When we realized that we needed more capabilities than virtual tables, we re implemented dynamic dispatch.
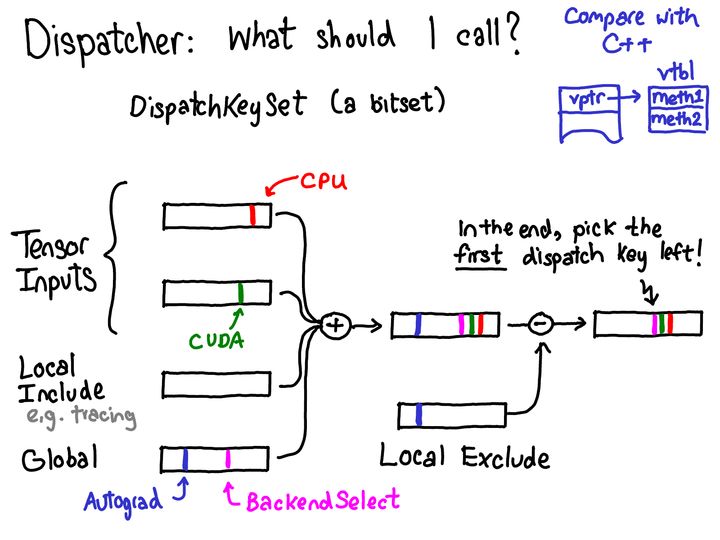
4.1.3 how to calculate key s
So, how do we calculate the dispatch key? We are based on the dispatch key set, which is a basic abstraction and a bitset of the dispatch key. Generally speaking, we synthesize the dispatch key sets from different sources (shielding some keys in some cases) to get a final dispatch key set. Then we select the key with the highest priority in this set (dispatch keys are implicitly sorted according to some priorities), which is the result we should call this time. So, what are the sources of these dispatch key sets?
- Each tensor input has a dispatch key set composed of all dispatch keys on the tensor (intuitively, the values of these dispatch keys will be something like "CPU" string, which tells us that the tensor is a CPU tensor, so it should be processed by the CPU handler in the dispatch table).
- We also have a local include set for the "modal" function, such as tracing. It is not associated with any tensor, but the local mode of a thread, which can be turned on or off by the user in some range.
- Finally, we have a global set, which contains the dispatch key that should always be considered (since writing this PPT, Autograd has moved from global set to tensor. However, the high-level structure of the system has not changed).
In addition to these, there is a local exclude set, which is used to exclude some dispatch key s from dispatch. A common scenario is that a handler is responsible for processing a key and then shielding itself through local exclude set, so that we won't try to re process the key in the future.
4.1.4 registration
Next, let's see how to register this dispatch key into the dispatch table. This process is implemented through the operator registration API. There are three main ways to register API operators:
- Define the schema for the operator.
- Then register the implementation on the corresponding key.
- Finally, there is a fallback method that users can use to define the same handler for all operators corresponding to a key.

In order to visualize the work of op erator registration, let's imagine that the dispatch tables of all OPS form a two-dimensional grid, like this:
- On the vertical axis is each op supported in PyTorch.
- On the horizontal axis are each dispatch key supported by the system.
The operator registration behavior is to fill in the corresponding implementation in the cells defined by the two axes.
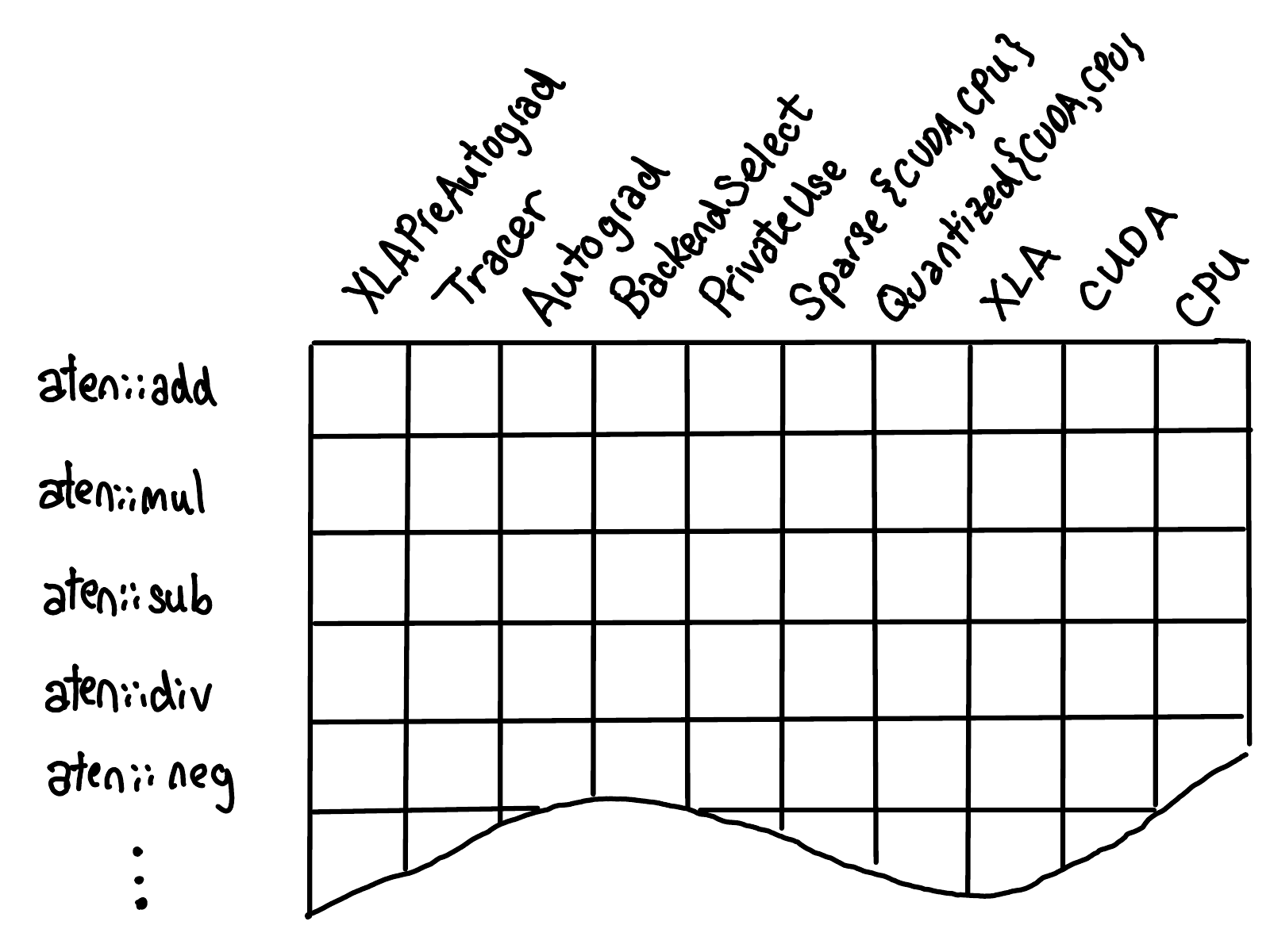
When registering the kernel function for an operator on a specific dispatch key, we will fill in the contents of a cell (blue below).
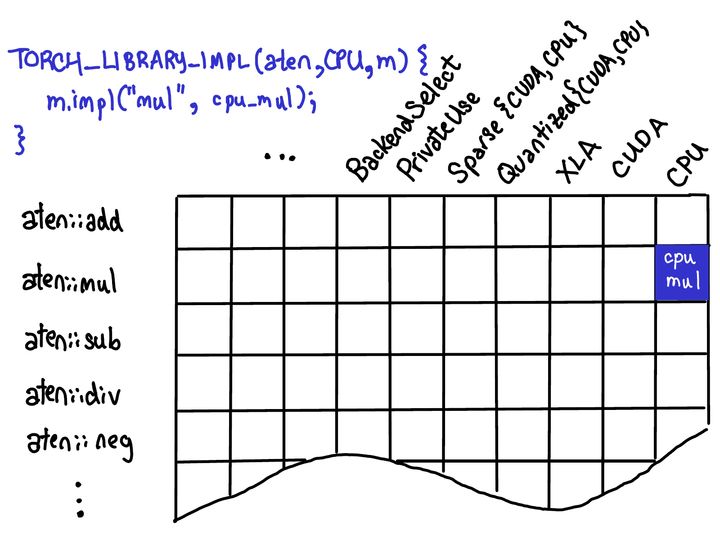
4.2 Dispatcher code
Let's take a look at the source code.
4.2.1 virtual function table
4.2.1.1 example
We can start from aten / SRC / aten / native / native_ Some examples of virtual functions are found in functions.yaml.
# Virtual function table corresponding to zero operation
- func: zero_(Tensor(a!) self) -> Tensor(a!)
device_check: NoCheck # TensorIterator
variants: method, function
dispatch:
CPU, CUDA: zero_
Meta: zero_meta_
SparseCPU, SparseCUDA: zero_sparse_
MkldnnCPU: mkldnn_zero_
# Virtual function table corresponding to sub.out
- func: sub.out(Tensor self, Tensor other, *, Scalar alpha=1, Tensor(a!) out) -> Tensor(a!)
device_check: NoCheck # TensorIterator
structured: True
structured_inherits: TensorIteratorBase
dispatch:
CPU, CUDA: sub_out
SparseCPU, SparseCUDA: sub_out_sparse
# Virtual function table corresponding to sub.Tensor
- func: sub.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor
device_check: NoCheck # TensorIterator
variants: function, method
structured_delegate: sub.out
dispatch:
SparseCPU, SparseCUDA: sub_sparse
4.2.1.2 implementation of operator
We can look at two implementations of zero. The following is the implementation of MkldnnCPU.
Tensor& mkldnn_zero_(Tensor& self) {
using Vec = vec::Vectorized<float>;
ideep::tensor& x = itensor_from_mkldnn(self);
auto n = x.get_nelems();
auto* x_ = static_cast<float*>(x.get_data_handle());
parallel_for(0, n, 2048, [x_](int64_t begin, int64_t end) {
vec::map(
[](Vec /* unused */) { return 0.0; },
x_ + begin,
x_ + begin,
end - begin);
});
return self;
}
For another example, the following is the corresponding implementation of sparsecpu and sparsecuda:
// --------------------------------------------------------------------
// zero_(SparseTensor)
// --------------------------------------------------------------------
// hummu hummu
SparseTensor& zero_sparse_(SparseTensor& self) {
AT_ASSERT(self.is_sparse());
at::zeros_out(self, get_sparse_impl(self)->sizes());
return self._coalesced_(true);
}
4.2.2 Dispatcher definition
Let's take a look at the definition of Dispatcher. Only some member variables are given here.
class TORCH_API Dispatcher final {
private:
// For direct access to backend fallback information
friend class impl::OperatorEntry;
struct OperatorDef final {
explicit OperatorDef(OperatorName&& op_name)
: op(std::move(op_name)) {}
impl::OperatorEntry op;
size_t def_count = 0;
size_t def_and_impl_count = 0;
};
friend class OperatorHandle;
template<class> friend class TypedOperatorHandle;
public:
static Dispatcher& realSingleton();
//All operators are stored, and different versions of each operator are stored in its member variables, such as cpu, cuda, autograd
std::list<OperatorDef> operators_;
//When registering an operator, the operator name and method will also be stored in this, so that the operator method (including the member OperatorDef) can be quickly found through the name
LeftRight<ska::flat_hash_map<OperatorName, OperatorHandle>> operatorLookupTable_;
// Map from namespace to debug string (saying, e.g., where the library was defined)
ska::flat_hash_map<std::string, std::string> libraries_;
std::array<impl::AnnotatedKernel, static_cast<uint8_t>(DispatchKey::NumDispatchKeys)> backendFallbackKernels_;
std::unique_ptr<detail::RegistrationListenerList> listeners_;
std::mutex mutex_;
};
4.2.3 registration
Next, we give a method to register the virtual function table.
RegistrationHandleRAII Dispatcher::registerImpl(
OperatorName op_name,
c10::optional<DispatchKey> dispatch_key,
KernelFunction kernel,
c10::optional<impl::CppSignature> cpp_signature,
std::unique_ptr<FunctionSchema> inferred_function_schema,
std::string debug
) {
std::lock_guard<std::mutex> lock(mutex_);
auto op = findOrRegisterName_(op_name);
auto handle = op.operatorDef_->op.registerKernel( // Register
*this,
dispatch_key,
std::move(kernel),
std::move(cpp_signature),
std::move(inferred_function_schema),
std::move(debug)
);
++op.operatorDef_->def_and_impl_count;
return RegistrationHandleRAII([this, op, op_name, dispatch_key, handle] {
deregisterImpl_(op, op_name, dispatch_key, handle);
});
}
4.2.3.1 registration form
OperatorEntry represents an operator and its dispatch table. Only member variables are given here.
class TORCH_API OperatorEntry final { //Represents an operator and its dispatch table
public:
OperatorName name_;
c10::optional<AnnotatedSchema> schema_;
//The operator implementation versions corresponding to different key s are stored, such as cpu, cuda, autograd, etc. all operator versions will be in this table
std::array<KernelFunction, static_cast<uint8_t>(DispatchKey::NumDispatchKeys)> dispatchTable_;
DispatchKeyExtractor dispatchKeyExtractor_;
//Different dispatchkeys correspond to different versions of kernel operator implementations
ska::flat_hash_map<DispatchKey, std::list<AnnotatedKernel>> kernels_;
};
4.2.3.2 registration behavior
The final registration behavior is to go to the dispatchTable_ Set in.
void OperatorEntry::updateDispatchTableEntry_(const c10::Dispatcher& dispatcher, DispatchKey dispatch_key) {
auto dispatch_ix = static_cast<uint8_t>(dispatch_key);
dispatchTable_[dispatch_ix] = computeDispatchTableEntry(dispatcher, dispatch_key);
dispatchKeyExtractor_.setOperatorHasFallthroughForKey(dispatch_key, dispatchTable_[dispatch_ix].isFallthrough());
}
4.2.4 how to dispatch
4.2.4.1 dispatching basis
In PyTorch, different operator s will be scheduled according to dtype, device and layout.
- Most types (such as int32) can be mapped directly by template, but some operator s do not support template function, so they need a dynamic scheduler such as dispatcher.
- The tensor of PyTorch can run not only on the CPU, but also on GPU, mkldnn, xla and other devices, which also requires dynamic scheduling.
- Layout refers to the arrangement of elements in tensor, which is different from striped layout and sparse layout, so dynamic scheduling is also required.
4.2.4.2 dispatching code
We are here to give part of the code, interested readers continue to go deep.
template<class Return, class... Args>
C10_DISPATCHER_INLINE_UNLESS_MOBILE Return Dispatcher::call(const TypedOperatorHandle<Return(Args...)>& op, Args... args) const {
detail::unused_arg_(args...);
// Get key set
auto dispatchKeySet = op.operatorDef_->op.dispatchKeyExtractor()
.template getDispatchKeySetUnboxed<Args...>(args...);
TORCH_INTERNAL_ASSERT_DEBUG_ONLY(!c10::isAliasDispatchKey(dispatchKeySet.highestPriorityTypeId()));
// Get operator
const KernelFunction& kernel = op.operatorDef_->op.lookup(dispatchKeySet.highestPriorityTypeId());
// Scheduling
#ifndef PYTORCH_DISABLE_PER_OP_PROFILING
bool pre_sampled = false;
if (C10_UNLIKELY(at::shouldRunRecordFunction(&pre_sampled))) {
return callWithDispatchKeySlowPath<Return, Args...>(op, pre_sampled, dispatchKeySet, kernel, std::forward<Args>(args)...);
}
#endif // PYTORCH_DISABLE_PER_OP_PROFILING
return kernel.template call<Return, Args...>(op, dispatchKeySet, std::forward<Args>(args)...);
}
4.2.4.3 key
Next, let's look at the definition of key. Because there are too many, we only give some values.
enum class DispatchKey : uint8_t {
CPU, // registered at build/aten/src/ATen/RegisterCPU.cpp
CUDA, // registered at build/aten/src/ATen/RegisterCUDA.cpp
HIP, // NB: I think this is not actually used, due to Note [Masquerading as
// CUDA]
FPGA, // Xilinx support lives out of tree at
// https://gitlab.com/pytorch-complex/vitis_kernels
MSNPU, // unused externally, but tested at
// test/cpp_extensions/msnpu_extension.cpp
XLA, // lives out of tree at https://github.com/pytorch/xla
MLC, // lives out of tree at https://github.com/pytorch/MLCompute
Vulkan,
Metal,
XPU, // For out of tree Intel's heterogeneous computing plug-in
HPU, // For out of tree & closed source integration of HPU / Habana
VE, // For out of tree & closed source integration of SX-Aurora / NEC
Lazy, // For lazy tensor backends
// A meta tensor is a tensor without any data associated with it. (They
// have also colloquially been referred to as tensors on the "null" device).
// A meta tensor can be used to dry run operators without actually doing any
// computation, e.g., add on two meta tensors would give you another meta
// tensor with the output shape and dtype, but wouldn't actually add anything.
Meta,
// Here are backends which specify more specialized operators
// based on the dtype of the tensor.
QuantizedCPU, // registered at build/aten/src/ATen/RegisterQuantizedCPU.cpp
QuantizedCUDA, // registered at build/aten/src/ATen/RegisterQuantizedCUDA.cpp
QuantizedXPU, // For out of tree Intel's heterogeneous computing plug-in
// This backend is to support custom RNGs; it lets you go
// to a different kernel if you pass in a generator that is not a
// traditional CPUGeneratorImpl/CUDAGeneratorImpl. To make use of this
// key:
// 1) set it as a second parameter of at::Generator constructor call in
// the user-defined PRNG class.
// 2) use it as a dispatch key while registering custom kernels
// (templatized kernels specialized for user-defined PRNG class)
// intended for out of tree use; tested by aten/src/ATen/test/rng_test.cpp
CustomRNGKeyId,
// Here are backends which specify more specialized operators
// based on the layout of the tensor. Note that the sparse backends
// are one case where ordering matters: sparse multi-dispatches with
// the corresponding dense tensors, and must be handled before them.
MkldnnCPU, // registered at build/aten/src/ATen/RegisterMkldnnCPU.cpp
// NB: not to be confused with MKLDNN, which is Caffe2 only
SparseCPU, // registered at build/aten/src/ATen/RegisterSparseCPU.cpp
SparseCUDA, // registered at build/aten/src/ATen/RegisterSparseCUDA.cpp
SparseHIP, // TODO: I think this is not actually used, due to Note
// [Masquerading as CUDA]
SparseXPU, // For out of tree Intel's heterogeneous computing plug-in
SparseVE, // For out of tree & closed source integration of SX-Aurora / NEC
SparseCsrCPU,
SparseCsrCUDA,
AutogradOther,
AutogradCPU,
AutogradCUDA,
AutogradXLA,
AutogradLazy,
AutogradXPU,
AutogradMLC,
AutogradHPU,
......
};
4.2.4.4 use of key
Due to space constraints, we cannot analyze each situation in depth. Here we only give the scenario starting from DeviceType. We can see how to map from DeviceType to DispatchKey from the following function.
template <typename Func>
inline CppFunction dispatch(c10::DeviceType type, Func&& raw_f) {
auto deviceTypeToDispatchKey = [](c10::DeviceType t){
switch (t) {
// This list is synchronized with the k-constants in c10/core/DeviceType.h
case c10::DeviceType::CPU:
return c10::DispatchKey::CPU;
case c10::DeviceType::CUDA:
return c10::DispatchKey::CUDA;
case c10::DeviceType::XLA:
return c10::DispatchKey::XLA;
case c10::DeviceType::Lazy:
return c10::DispatchKey::Lazy;
case c10::DeviceType::MLC:
return c10::DispatchKey::MLC;
case c10::DeviceType::Meta:
return c10::DispatchKey::Meta;
case c10::DeviceType::HIP:
return c10::DispatchKey::HIP;
case c10::DeviceType::MSNPU:
return c10::DispatchKey::MSNPU;
case c10::DeviceType::HPU:
return c10::DispatchKey::HPU;
default:
TORCH_CHECK(false,
"Device type ", t, " cannot be overloaded at dispatch time, "
"please file a bug report explaining what you were trying to do.");
}
};
return dispatch(deviceTypeToDispatchKey(type), std::forward<Func>(raw_f));
}
4.3 summary
So far, we know that through the Dispatcher mechanism, PyTorch can schedule different operator s according to dtype, device and layout. This answers our third question: how to seamlessly switch between CPU and GPU operations?
About the fourth question: do you need to move the loss function onto the GPU?, We also have an answer:
The parameters of the loss function are forward propagating outputs and labels. Outputs are already on the GPU (because the training data is already on the GPU), and the label is also manually set on the GPU by the user. Therefore, the parameters of the loss function are already on the GPU, so the dispatcher will call the operator corresponding to the GPU according to the device, so there is no need to move the loss function on the GPU.
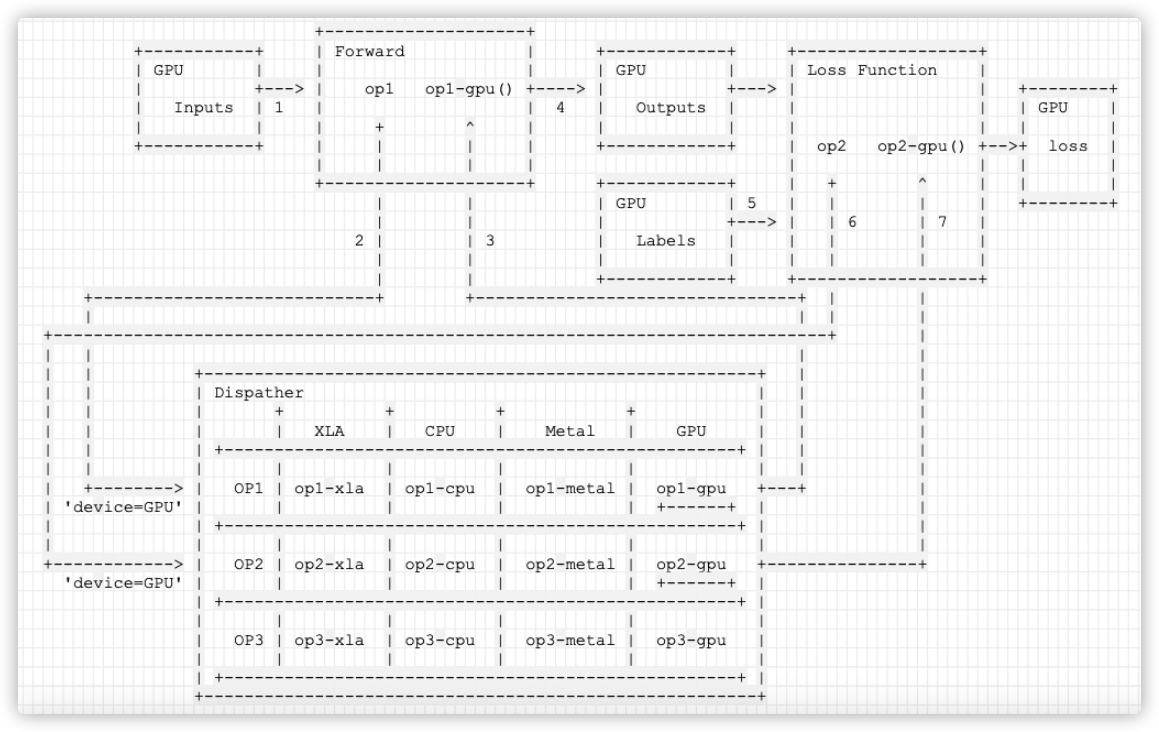
We sort out an overall logic as follows. The sequence is:
- Move the training data inputs to the GPU.
- For forward operation, assume that there is only one operator, op1, and use the dispatch key device='GPU 'to find the Dispatcher.
- The OP1 GPU operator is found and calculated to obtain outputs.
- outputs automatically exist on the GPU.
- Put Labels on the GPU, too.
- For the loss function operation, assume that there is only one operator, op2. At this time, the parameters of the loss function are all on the GPU, so use the dispatch key device= 'GPU' to find the Dispatcher.
- The op2 GPU operator is found and calculated to obtain loss.
+--------------------+
+-----------+ | Forward | +------------+ +------------------+
| GPU | | | | GPU | | Loss Function |
| +---> | op1 op1-gpu() +----> | +---> | | +--------+
| Inputs | 1 | | 4 | Outputs | | | | GPU |
| | | + ^ | | | | | | |
+-----------+ | | | | +------------+ | op2 op2-gpu() +-->+ loss |
| | | | | | | |
+--------------------+ +------------+ | + ^ | | |
| | | GPU | 5 | | | | +--------+
| | | +---> | | 6 | 7 |
2 | | 3 | Labels | | | | |
| | | | | | | |
| | +------------+ +------------------+
+----------------------------+ +--------------------------------+ | |
| | | |
+-----------------------------------------------------------------------------+ |
| | | |
| | +-------------------------------------------------------+ | |
| | | Dispather | | |
| | | + + + + | | |
| | | | XLA | CPU | Metal | GPU | | |
| | | +---------------------------------------------------+ | | |
| | | | | | | | | |
| +--------> | OP1 | op1-xla | op1-cpu | op1-metal | op1-gpu +---+ |
| 'device=GPU' | | | | | +------+ | |
| | +---------------------------------------------------+ | |
| | | | | | | |
+------------> | OP2 | op2-xla | op2-cpu | op2-metal | op2-gpu +---------------+
'device=GPU' | | | | | +------+ |
| +---------------------------------------------------+ |
| | | | | |
| OP3 | op3-xla | op3-cpu | op3-metal | op3-gpu |
| | | | | |
| +---------------------------------------------------+ |
+-------------------------------------------------------+
Mobile phones are as follows:
So far, the GPU correlation analysis is over. In the next article, we will start to analyze DataParallel. Please look forward to it.
0xFF reference
http://blog.ezyang.com/2020/09/lets-talk-about-the-pytorch-dispatcher/
https://pytorch.org/tutorials/advanced/dispatcher.html
Summary of GPU multi card parallel training (taking pytorch as an example)
Distributed training from getting started to giving up
On the initialization of PyTorch (Part I)
Extended pytoch: using CUDA to realize operator (2)
Dynamic generation of PyTorch ATen code
https://blog.csdn.net/qq_23858785/article/details/96476740
Introduction to CUDA C programming
CPU GPU parallel processing CUDA Programming from getting started to giving up
https://blog.csdn.net/weixin_42236014/article/details/116747358
https://blog.csdn.net/crazy_sunshine/article/details/97920534
Introduction to CPU, GPU, CUDA and CuDNN
CUDA Programming (III): learn about GPU architecture!
Introduction to CUDA Programming minimalist tutorial
What's the difficulty in writing CUDA?
Advanced development of pytoch (II): pytoch combines C + + and Cuda development
Advanced development of pytoch (I): pytoch combines C and Cuda languages