catalogue
- [source code analysis] NVIDIA HugeCTR, GPU version parameter server -- - (3)
0x00 summary
In this series, we introduce HugeCTR, an industry-oriented recommendation system training framework optimized for large-scale CTR models with model parallel embedding and data parallel intensive networks.
This paper mainly introduces the input data and some basic data structures that HugeCTR depends on. Which draws lessons from HugeCTR source code reading Thank you for this masterpiece. Because HugeCTR is actually a concrete and micro deep learning system, it also realizes many basic functions, which is worthy of careful study by friends who want to study the deep learning framework.
Other articles in this series are as follows:
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- (1)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- - (2)
0x01 review
First, let's return to the previous content. The logical relationship of the pipeline is as follows:
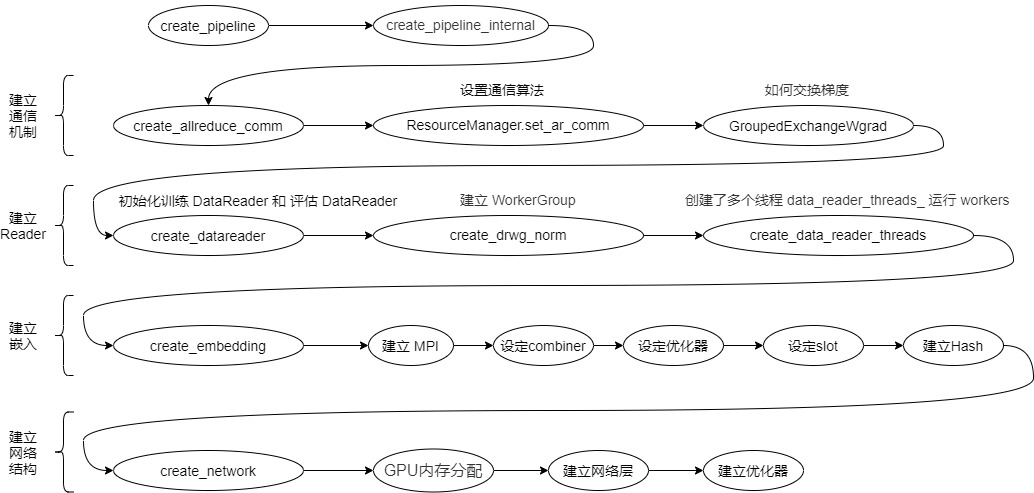
The training process is as follows:

Based on the above knowledge, let's take a look at how to process the data.
0x02 dataset
HugeCTR currently supports three data set formats, namely Norm,Raw and Parquet The specific format is as follows:
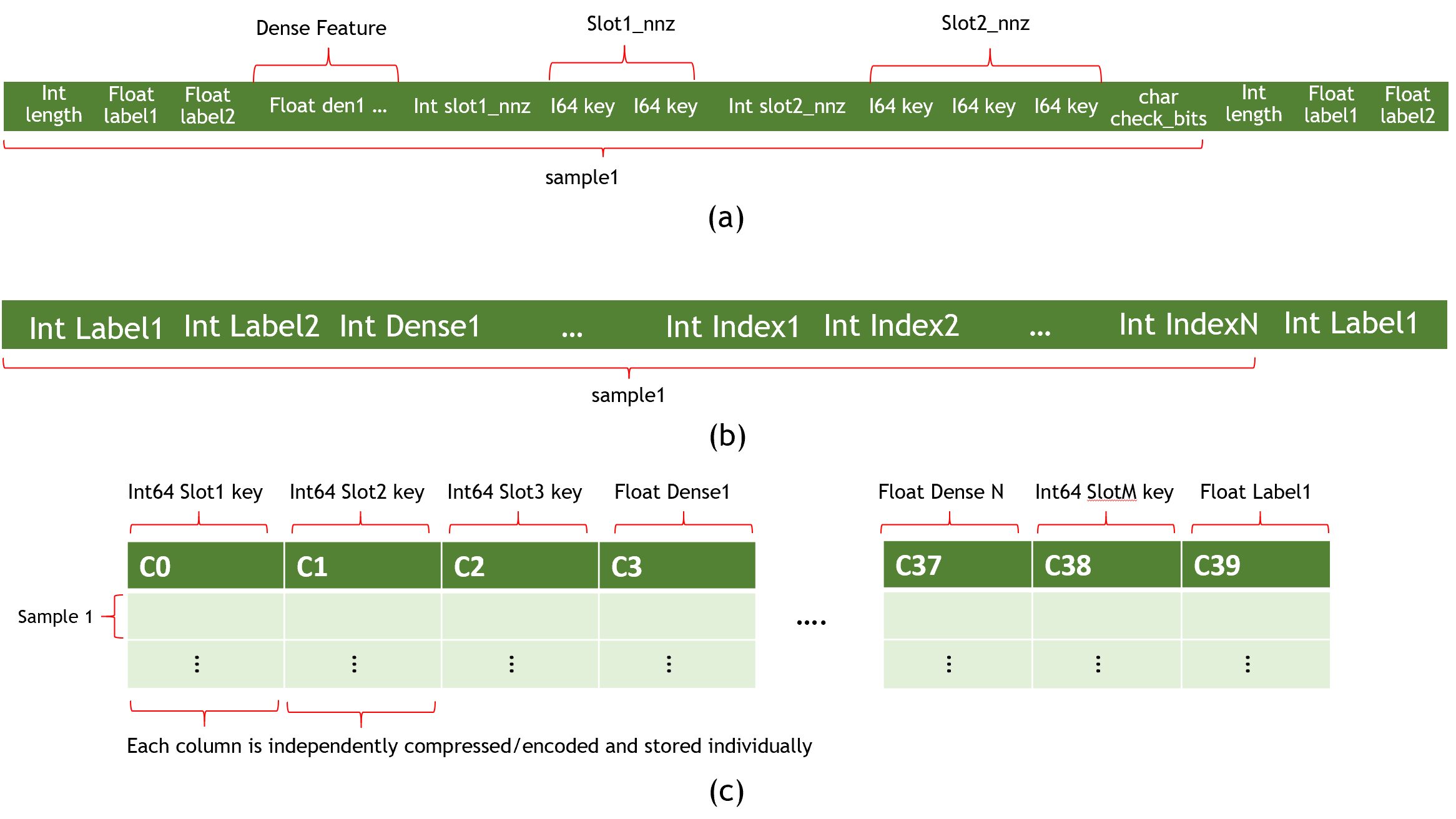
Fig. 1: (a) Norm (b) Raw (c) Parquet Dataset Formats
2.1 Norm
To maximize data loading performance and minimize storage, Norm dataset format consists of a set of binary data files and a list of files in ASCII format. The model file shall specify the file name of the training and test (evaluation) set, the maximum number of elements (keys) in the sample and the label dimension, as shown in Figure 1 (a).
2.1.1 data files
A data file is the minimum read granularity of a read thread, so at least 10 files in each file list are required to achieve the best performance. The data file consists of header and actual tabular data.
Header definition:
typedef struct DataSetHeader_ {
long long error_check; //0: no error check; 1: check_num
long long number_of_records; //Number of samples in this data file
long long label_dim; //Dimension of label
long long density_dim; //Dimension of dense features
long long slot_num; //Each embedded slot_num
long long reserved[ 3 ]; //Reserved for future use
Dataset header;Data definition (per sample):
typedef struct Data_ {
int length; //Number of bytes in this example (optional: only in check_sum mode)
float label[label_dim];
float dense[dense_dim];
Slot slots[slot_num];
char checkbits; //Check digit of this sample (optional: only in checksum mode)
} Data;
typedef struct Slot_ {
int nnz;
unsigned int* keys; //You can use "input_key_type" in the "solver" object of the configuration file to change it to "long long"`
} Slot;Data field s usually have many samples. Each sample starts with a label formatted as an integer, followed by nnz (non-zero number) and an input key in long long (or unsigned integer) format, as shown in Figure 1 (a).
The input keys of category are distributed into slots and cannot be overlapped. For example: slot[0] = {0,10,32,45}, slot[1] = {1,2,5,67}. If there is any overlap, it will lead to undefined behavior. For example, given that slot [0] = {0,10,32,45} and slot [1] = {1,10,5,67}, finding the table with 10 keys will produce different results, which depend on the way the slot is allocated to the GPU.
2.1.2 document list
The first line of the file list should be the number of data files in the dataset, and then the path of these files, as shown below:
$ cat simple_sparse_embedding_file_list.txt 10 ./simple_sparse_embedding/simple_sparse_embedding0.data ./simple_sparse_embedding/simple_sparse_embedding1.data ./simple_sparse_embedding/simple_sparse_embedding2.data ./simple_sparse_embedding/simple_sparse_embedding3.data ./simple_sparse_embedding/simple_sparse_embedding4.data ./simple_sparse_embedding/simple_sparse_embedding5.data ./simple_sparse_embedding/simple_sparse_embedding6.data ./simple_sparse_embedding/simple_sparse_embedding7.data ./simple_sparse_embedding/simple_sparse_embedding8.data ./simple_sparse_embedding/simple_sparse_embedding9.data
Examples are as follows:
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Norm,
source = ["./wdl_norm/file_list.txt"],
eval_source = "./wdl_norm/file_list_test.txt",
check_type = hugectr.Check_t.Sum)2.2 Raw
The difference between Raw dataset format and Norm dataset format is that the training data appears in a binary file and uses int32. Figure 1 (b) shows the structure of the original dataset sample.
Note: this format only accepts heat independence data.
Raw dataset format can only be used with embedded type LocalizedSlotSparseEmbeddingOneHot.
example:
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Raw,
source = ["./wdl_raw/train_data.bin"],
eval_source = "./wdl_raw/validation_data.bin",
check_type = hugectr.Check_t.Sum)2.3 Parquet
Parquet is a column oriented, open source data format. It can be used for any project in the Apache Hadoop ecosystem. In order to reduce the file size, it supports compression and encoding. Figure 1 (c) shows an example parquet dataset. For additional information, see parquet document.
Please note the following:
- The Parquet data loader does not currently support nested column types.
- No missing values are allowed in the column.
- Like Norm dataset format, labels and dense feature columns should use floating-point format.
- Slot feature columns should be in Int64 format.
- The data columns in the Parquet file can be arranged in any order.
- To obtain the required information from all rows in each parquet file and the column index mapping of each label, dense (numeric) and slot (classification) feature, a separate_ metadata.json file.
Examples_ metadata.json:
{
"file_stats": [{"file_name": "file1.parquet", "num_rows": 6528076}, {"file_name": "file2.parquet", "num_rows": 6528076}],
"cats": [{"col_name": "C11", "index": 24}, {"col_name": "C24", "index": 37}, {"col_name": "C17", "index": 30}, {"col_name": "C7", "index": 20}, {"col_name": "C6", "index": 19}],
"conts": [{"col_name": "I5", "index": 5}, {"col_name": "I13", "index": 13}, {"col_name": "I2", "index": 2}, {"col_name": "I10", "index": 10}],
"labels": [{"col_name": "label", "index": 0}]
}Use the following:
reader = hugectr.DataReaderParams(data_reader_type = hugectr.DataReaderType_t.Parquet,
source = ["./criteo_data/train/_file_list.txt"],
eval_source = "./criteo_data/val/_file_list.txt",
check_type = hugectr.Check_t.Non,
slot_size_array = [278899, 355877, 203750, 18573, 14082, 7020, 18966, 4, 6382, 1246, 49, 185920, 71354, 67346, 11, 2166, 7340, 60, 4, 934, 15, 204208, 141572, 199066, 60940, 9115, 72, 34])We provide an option through slot_size_array, you can add an offset for each slot. slot_size_array is an array whose length is equal to the number of slots. In order to avoid duplicate keys after adding offset, we need to ensure that the key range of the ith slot is 0 to slot_ size_ Between array [i]. We will offset in this way: for the ith slot key, we add the offset slot_size_array[0] + slot_size_array[1] + ... + slot_size_array[i - 1]. In the configuration fragment mentioned above, for slot 0, an offset of 0 will be added. For the first slot, an offset of 278899 is added. For the third slot, an offset of 634776 is added.
0x03 CSR format
The embedded layer is built on the basis of CSR format, so let's first look at CSR format.
3.1 what is CSR
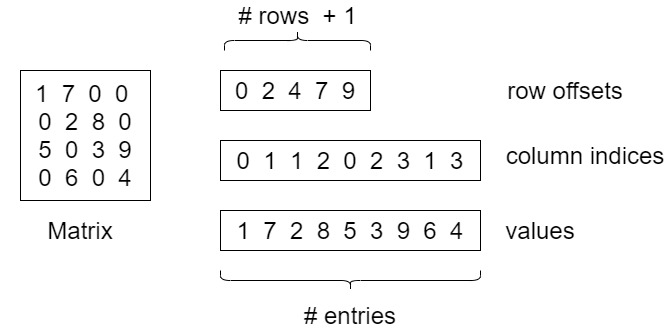
Sparse matrix refers to the matrix in which most of the elements in the matrix are 0. In fact, most large-scale matrices in real problems are sparse matrices. Therefore, there are many efficient storage formats for sparse matrices, and Compressed Sparse Row (CSR) is one of them.
This is the simplest format. Each element needs to be represented by a triplet, namely (row number, column number, numerical value), corresponding to the column on the right of the figure above. This method is simple, but the record sheet has more information (rows and columns), and each triplet can be located by itself, so the space is not optimal.
CSR needs three types of data to express: value, column number and row offset. It does not use triples to represent an element, but an overall coding method.
- Value: an element.
- Column number: the column number of the element,
- Line offset: the starting offset position of the first element of a line in values.
In the above figure, element 1 in the first row is offset 0, element 2 in the second row is offset 2, element 5 in the third row is offset 4, and element 6 in the fourth row is offset 7. Finally, the total number of elements of the matrix will be added after the row offset, which is 9 in this example.
3.2 CSR in hugectr
Let's find an example. Because it is only used to store the spark keys in a slot, there is no column number, because the spark keys in a slot can be stored directly and sequentially.
* For example data: * 4,5,1,2 * 3,5,1 * 3,2 * Will be convert to the form of: * row offset: 0,4,7,9 * value: 4,5,1,2,3,5,1,3,2
Let's find some information from the source code samples / NCF / preprocess-20m py.
def write_hugeCTR_data(huge_ctr_data, filename='huge_ctr_data.dat'):
print("Writing %d samples"%huge_ctr_data.shape[0])
with open(filename, 'wb') as f:
#write header
f.write(ll(0)) # 0: no error check; 1: check_num
f.write(ll(huge_ctr_data.shape[0])) # the number of samples in this data file
f.write(ll(1)) # dimension of label
f.write(ll(1)) # dimension of dense feature
f.write(ll(2)) # long long slot_num
for _ in range(3): f.write(ll(0)) # reserved for future use
for i in tqdm.tqdm(range(huge_ctr_data.shape[0])):
f.write(c_float(huge_ctr_data[i,2])) # float label[label_dim];
f.write(c_float(0)) # dummy dense feature
f.write(c_int(1)) # slot 1 nnz: user ID
f.write(c_uint(huge_ctr_data[i,0]))
f.write(c_int(1)) # slot 2 nnz: item ID
f.write(c_uint(huge_ctr_data[i,1]))3.3 operation
3.3.1 definitions
Only member variables are given here, which can be verified with the above csr format.
class CSR {
private:
const size_t num_rows_; /**< num rows. */
const size_t max_value_size_; /**< number of element of value the CSR matrix will have for
num_rows rows. */
Tensor2<T> row_offset_tensor_;
Tensor2<T> value_tensor_; /**< a unified buffer for row offset and value. */
T* row_offset_ptr_; /**< just offset on the buffer, note that the length of it is
* slot*batchsize+1.
*/
T* value_ptr_; /**< pointer of value buffer. */
size_t size_of_row_offset_; /**< num of rows in this CSR buffer */
size_t size_of_value_; /**< num of values in this CSR buffer */
size_t check_point_row_; /**< check point of size_of_row_offset_. */
size_t check_point_value_; /**< check point of size_of_value__. */
}3.3.2 constructor
In the constructor, memory will be allocated on the GPU.
/**
* Ctor
* @param num_rows num of rows is expected
* @param max_value_size max size of value buffer.
*/
CSR(size_t num_rows, size_t max_value_size)
: num_rows_(num_rows),
max_value_size_(max_value_size),
size_of_row_offset_(0),
size_of_value_(0) {
std::shared_ptr<GeneralBuffer2<CudaHostAllocator>> buff =
GeneralBuffer2<CudaHostAllocator>::create();
buff->reserve({num_rows + 1}, &row_offset_tensor_);
buff->reserve({max_value_size}, &value_tensor_);
buff->allocate();
row_offset_ptr_ = row_offset_tensor_.get_ptr();
value_ptr_ = value_tensor_.get_ptr();
}3.3.3 generate new line
new_ A new row will be generated in row, and the current total value will be set to row_offset.
/**
* Insert a new row to CSR
* Whenever you want to add a new row, you need to call this.
* When you have pushed back all the values, you need to call this method
* again.
*/
inline void new_row() { // call before push_back values in this line
if (size_of_row_offset_ > num_rows_) CK_THROW_(Error_t::OutOfBound, "CSR out of bound");
row_offset_ptr_[size_of_row_offset_] = static_cast<T>(size_of_value_);
size_of_row_offset_++;
}Insert data
Data will be inserted here and the total number of value s will be increased.
/**
* Push back a value to this object.
* @param value the value to be pushed back.
*/
inline void push_back(const T& value) {
if (size_of_value_ >= max_value_size_)
CK_THROW_(Error_t::OutOfBound, "CSR out of bound " + std::to_string(max_value_size_) +
"offset" + std::to_string(size_of_value_));
value_ptr_[size_of_value_] = value;
size_of_value_++;
}0x04 basic data structure
Because HugeCTR is actually a concrete and micro deep learning system, it also realizes many basic functions. In order to better analyze, we need to first introduce some basic data structures. Only the member variables and necessary functions of each class are given below.
4.1 tensor
The first is the most basic concept of tensor.
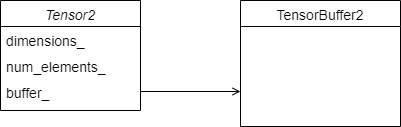
4.1.1 TensorBuffer2
TensorBuffer2 is the underlying data of tensor. It may be better understood by connecting with PyTorch's data or storage.
class TensorBuffer2 {
public:
virtual ~TensorBuffer2() {}
virtual bool allocated() const = 0;
virtual void *get_ptr() = 0;
};4.1.2 Tensor2
This corresponds to the tensor of TF or PyTorch.
template <typename T>
class Tensor2 {
std::vector<size_t> dimensions_;
size_t num_elements_;
std::shared_ptr<TensorBuffer2> buffer_;
}We introduce two member functions as follows:
static Tensor2 stretch_from(const TensorBag2 &bag) {
return Tensor2(bag.dimensions_, bag.buffer_);
}
TensorBag2 shrink() const {
return TensorBag2(dimensions_, buffer_, TensorScalarTypeFunc<T>::get_type());
}The details are as follows:
4.1.3 Tensors2
Tensors2 is a vector of Tensor2.
template <typename T> using Tensors2 = std::vector<Tensor2<T>>;
4.1.4 TensorBag2
PyTorch also has some classes with Bag suffix names, such as NN Embedding and NN EmbeddingBag. When building a Bag model, it is common to make an embedding to follow Sum or Mean. For variable length sequences, NN Embeddingbag provides a more efficient and faster processing method, especially for variable length sequences.
In HugeCTR, TensorBag2 can be regarded as a class that puts Tensor in a bag for unified processing.
class TensorBag2 {
template <typename T>
friend class Tensor2;
std::vector<size_t> dimensions_;
std::shared_ptr<TensorBuffer2> buffer_;
TensorScalarType scalar_type_;
};
using TensorBags2 = std::vector<TensorBag2>;For the relationship between Tensor and Bag, see the following function.
template <typename T>
Tensors2<T> bags_to_tensors(const std::vector<TensorBag2> &bags) {
Tensors2<T> tensors;
for (const auto &bag : bags) {
tensors.push_back(Tensor2<T>::stretch_from(bag));
}
return tensors;
}
template <typename T>
std::vector<TensorBag2> tensors_to_bags(const Tensors2<T> &tensors) {
std::vector<TensorBag2> bags;
for (const auto &tensor : tensors) {
bags.push_back(tensor.shrink());
}
return bags;
}4.1.5 SparseTensor
SparseTensor is a tensor of Sparse type, which was added in version 3.2 to uniformly process CSR format, or Sparse matrix, which can effectively store and process tensors with zero elements. Subsequent analysis will be performed when reading data to GPU. By comparing the CSR format, we can see that its internal mechanism corresponds to the rowoffset and value of CSR. Its specific definition is as follows:
template <typename T>
class SparseTensor {
std::vector<size_t> dimensions_;
std::shared_ptr<TensorBuffer2> value_buffer_;
std::shared_ptr<TensorBuffer2> rowoffset_buffer_;
std::shared_ptr<size_t> nnz_; // maybe size_t for FixedLengthSparseTensor
size_t rowoffset_count_;
};The schematic diagram is as follows:
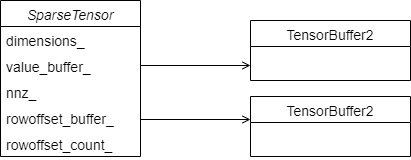
Let's find an example. Because it is only used to store the spark keys in a slot, there is no column number, because the spark keys in a slot can be stored directly and sequentially.
* For example data: * 4,5,1,2 * 3,5,1 * 3,2 * Will be convert to the form of: * row offset: 0,4,7,9 * value: 4,5,1,2,3,5,1,3,2
Corresponding to the following figure:
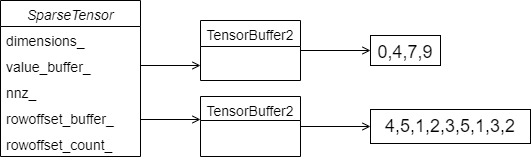
The member functions are described as follows:
static SparseTensor stretch_from(const SparseTensorBag &bag) {
return SparseTensor(bag.dimensions_, bag.value_buffer_, bag.rowoffset_buffer_, bag.nnz_,
bag.rowoffset_count_);
}
SparseTensorBag shrink() const {
return SparseTensorBag(dimensions_, value_buffer_, rowoffset_buffer_, nnz_, rowoffset_count_,
TensorScalarTypeFunc<T>::get_type());
}PyTorch
PyTorch has spark_ coo_ Tensor can achieve similar functions. PyTorch supports tensors of different layouts. You can use torch / CSR / utils / tensor_ layouts. CPP finds, for example, at:: layout:: striped, at:: layout:: spark, at::Layout::SparseCsr, at::Layout::Mkldnn, etc., which correspond to different memory layout modes.
When using sparse tensors, provide a pair of deny tensors: a value tensor, a two-dimensional indice tensor, and other auxiliary parameters.
>>> i = [[1, 1]]
>>> v = [3, 4]
>>> s=torch.sparse_coo_tensor(i, v, (3,))
>>> s
tensor(indices=tensor([[1, 1]]),
values=tensor( [3, 4]),
size=(3,), nnz=2, layout=torch.sparse_coo)TensorFlow
TensorFlow also has SparseTensor type to represent multidimensional sparse data. A SparseTensor is represented by three dense tensors:
- indices represents the non-zero element coordinates of the sparse tensor.
- values corresponds to the value of each non-zero element.
- Shape represents the shape after the sparse tensor is converted to dense form.
For example, the following code:
indices = tf.constant([[0, 0], [1, 1], [2,2]], dtype=tf.int64)
values = tf.constant([1, 2, 3], dtype=tf.float32)
shape = tf.constant([3, 3], dtype=tf.int64)
sparse = tf.SparseTensor(indices=indices,
values=values,
dense_shape=shape)
dense = tf.sparse_tensor_to_dense(sparse, default_value=0)
with tf.Session() as session:
sparse, dense = session.run([sparse, dense])
print('Sparse is :\n', sparse)
print('Dense is :\n', dense)Print out as follows:
Sparse is :
SparseTensorValue(indices=array([[0, 0],
[1, 1],
[2, 2]]), values=array([1., 2., 3.], dtype=float32), dense_shape=array([3, 3]))
Dense is :
[[1. 0. 0.]
[0. 2. 0.]
[0. 0. 3.]]4.1.6 SparseTensorBag
This function similar to TensorBag is as follows:
class SparseTensorBag {
template <typename T>
friend class SparseTensor;
std::vector<size_t> dimensions_;
std::shared_ptr<TensorBuffer2> value_buffer_;
std::shared_ptr<TensorBuffer2> rowoffset_buffer_;
std::shared_ptr<size_t> nnz_;
size_t rowoffset_count_;
TensorScalarType scalar_type_;
SparseTensorBag(const std::vector<size_t> &dimensions,
const std::shared_ptr<TensorBuffer2> &value_buffer,
const std::shared_ptr<TensorBuffer2> &rowoffset_buffer,
const std::shared_ptr<size_t> &nnz, const size_t rowoffset_count,
TensorScalarType scalar_type)
: dimensions_(dimensions),
value_buffer_(value_buffer),
rowoffset_buffer_(rowoffset_buffer),
nnz_(nnz),
rowoffset_count_(rowoffset_count),
scalar_type_(scalar_type) {}
public:
SparseTensorBag() : scalar_type_(TensorScalarType::None) {}
const std::vector<size_t> &get_dimensions() const { return dimensions_; }
};4.1.7 vector class
The following are two vector classes for user convenience.
using TensorBags2 = std::vector<TensorBag2>; template <typename T> using SparseTensors = std::vector<SparseTensor<T>>;
4.2 memory
Let's take a look at some memory related classes.
4.2.1 Allocator
First, let's see how to allocate memory for variables such as tensor.
4.2.1.1 HostAllocator
HostAllocator is used to manage memory on the host.
class HostAllocator {
public:
void *allocate(size_t size) const { return malloc(size); }
void deallocate(void *ptr) const { free(ptr); }
};The latter implementations call CUDA functions to allocate memory, such as cudaHostAlloc. Interested readers can learn more.
4.2.1.2 CudaHostAllocator
Call the CUDA method to allocate memory on the host
class CudaHostAllocator {
public:
void *allocate(size_t size) const {
void *ptr;
CK_CUDA_THROW_(cudaHostAlloc(&ptr, size, cudaHostAllocDefault));
return ptr;
}
void deallocate(void *ptr) const { CK_CUDA_THROW_(cudaFreeHost(ptr)); }
};4.2.1.3 CudaManagedAllocator
cudaMallocManaged allocates memory intended for use by host or device code, which is a unified method of allocating memory.
class CudaManagedAllocator {
public:
void *allocate(size_t size) const {
void *ptr;
CK_CUDA_THROW_(cudaMallocManaged(&ptr, size));
return ptr;
}
void deallocate(void *ptr) const { CK_CUDA_THROW_(cudaFree(ptr)); }
};4.2.1.4 CudaAllocator
This class allocates memory on the device.
class CudaAllocator {
public:
void *allocate(size_t size) const {
void *ptr;
CK_CUDA_THROW_(cudaMalloc(&ptr, size));
return ptr;
}
void deallocate(void *ptr) const { CK_CUDA_THROW_(cudaFree(ptr)); }
};4.2.2 GeneralBuffer2
After analyzing how to allocate memory, let's take a look at how to encapsulate memory, which is completed through GeneralBuffer2. General buffer 2 can be considered as a unified package for large memory, and there can be several tensors on it.
4.2.2.1 definition
Member functions are ignored here, and the inner class also ignores member functions.
- Allocator: specific memory allocator, which also distinguishes between GPU allocation and CPU allocation.
- ptr_ : Points to the allocated memory;
- total_size_in_bytes_ : Memory size;
- reserved_buffers_ : The buffer is reserved in the early stage and will be allocated uniformly in the future;
The specific internal classes are:
- BufferInternal is the interface.
- Tensorbuffeimpl is the buffer implementation corresponding to Tensor2.
- BufferBlockImpl is used when building the network.
The specific codes are as follows:
template <typename Allocator>
class GeneralBuffer2 : public std::enable_shared_from_this<GeneralBuffer2<Allocator>> {
class BufferInternal {
public:
virtual ~BufferInternal() {}
virtual size_t get_size_in_bytes() const = 0;
virtual void initialize(const std::shared_ptr<GeneralBuffer2> &buffer, size_t offset) = 0;
};
class TensorBufferImpl : public TensorBuffer2, public BufferInternal {
size_t size_in_bytes_;
std::shared_ptr<GeneralBuffer2> buffer_;
size_t offset_;
};
template <typename T>
class BufferBlockImpl : public BufferBlock2<T>, public BufferInternal {
size_t total_num_elements_;
std::shared_ptr<TensorBufferImpl> buffer_impl_;
Tensor2<T> tensor_;
bool finalized_;
std::vector<std::shared_ptr<BufferInternal>> reserved_buffers_;
};
Allocator allocator_;
void *ptr_;
size_t total_size_in_bytes_;
std::vector<std::shared_ptr<BufferInternal>> reserved_buffers_;
}4.2.2.2 TensorBufferImpl
It points to a GeneralBuffer2, and then sets its own offset and size.
void initialize(const std::shared_ptr<GeneralBuffer2> &buffer, size_t offset) {
buffer_ = buffer;
offset_ = offset;
}4.2.2.2 BufferBlockImpl key functions
BufferBlockImpl and tensorbuffeimpl can be compared.
BufferBlock2 is the interface class of BufferBlockImpl.
template <typename T>
class BufferBlock2 {
public:
virtual ~BufferBlock2() {}
virtual void reserve(const std::vector<size_t> &dimensions, Tensor2<T> *tensor) = 0;
virtual Tensor2<T> &as_tensor() = 0;
};BufferBlockImpl is a continuous set of tensors. Some specific implementations require continuous memory, such as weights.
std::shared_ptr<BufferBlock2<float>> train_weight_buff = blobs_buff->create_block<float>(); // Omit other codes network->train_weight_tensor_ = train_weight_buff->as_tensor();
BufferBlockImpl adds a reserve method to reserve memory space and generate internal tensor s on this space.
void reserve(const std::vector<size_t> &dimensions, Tensor2<T> *tensor) override {
if (finalized_) {
throw std::runtime_error(ErrorBase + "Buffer block is finalized.");
}
size_t num_elements = get_num_elements_from_dimensions(dimensions);
size_t size_in_bytes = num_elements * TensorScalarSizeFunc<T>::get_element_size();
std::shared_ptr<TensorBufferImpl> buffer_impl =
std::make_shared<TensorBufferImpl>(size_in_bytes);
reserved_buffers_.push_back(buffer_impl);
*tensor = Tensor2<T>(dimensions, buffer_impl);
total_num_elements_ += num_elements;
}initialize configures the internal
void initialize(const std::shared_ptr<GeneralBuffer2> &buffer, size_t offset) {
size_t local_offset = 0;
for (const std::shared_ptr<BufferInternal> &buffer_impl : reserved_buffers_) {
buffer_impl->initialize(buffer, offset + local_offset);
local_offset += buffer_impl->get_size_in_bytes();
}
reserved_buffers_.clear();
if (!finalized_) {
buffer_impl_ = std::make_shared<TensorBufferImpl>(
total_num_elements_ * TensorScalarSizeFunc<T>::get_element_size());
tensor_ = Tensor2<T>({total_num_elements_}, buffer_impl_);
finalized_ = true;
}
buffer_impl_->initialize(buffer, offset);
}4.2.2.3 general buffer2 key functions
The reserve method will record the memory requirements corresponding to a tensor in the reserved in the form of TensorBufferImpl_ buffers_ And then generate this tensor, which is generated with TensorBufferImpl.
template <typename T>
void reserve(const std::vector<size_t> &dimensions, Tensor2<T> *tensor) {
if (allocated()) {
throw std::runtime_error(ErrorBase + "General buffer is finalized.");
}
size_t size_in_bytes =
get_num_elements_from_dimensions(dimensions) * TensorScalarSizeFunc<T>::get_element_size();
std::shared_ptr<TensorBufferImpl> buffer_impl =
std::make_shared<TensorBufferImpl>(size_in_bytes);
reserved_buffers_.push_back(buffer_impl);
*tensor = Tensor2<T>(dimensions, buffer_impl);
}create_block will be created for BufferBlock2.
template <typename T>
std::shared_ptr<BufferBlock2<T>> create_block() {
if (allocated()) {
throw std::runtime_error(ErrorBase + "General buffer is finalized.");
}
std::shared_ptr<BufferBlockImpl<T>> block_impl = std::make_shared<BufferBlockImpl<T>>();
reserved_buffers_.push_back(block_impl);
return block_impl;
}allocate traverses the registered BufferInternal, accumulates its total size, and finally calls allocator_. allocate memory.
void allocate() {
if (ptr_ != nullptr) {
throw std::runtime_error(ErrorBase + "Memory has already been allocated.");
}
size_t offset = 0;
for (const std::shared_ptr<BufferInternal> &buffer : reserved_buffers_) {
// Configure BufferInternal (such as tensorbuffeimpl)
buffer->initialize(this->shared_from_this(), offset);
size_t size_in_bytes = buffer->get_size_in_bytes();
if (size_in_bytes % 32 != 0) {
size_in_bytes += (32 - size_in_bytes % 32);
}
offset += size_in_bytes;
}
reserved_buffers_.clear();
total_size_in_bytes_ = offset;
if (total_size_in_bytes_ != 0) {
ptr_ = allocator_.allocate(total_size_in_bytes_);
}
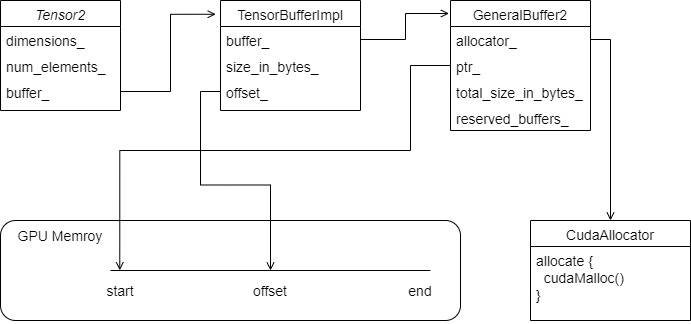
}4.2.4 summary
So far, Tensor's logic is expanded:
- Tensorbuffeimpl's buffer is GeneralBuffer2;
- ptr of general buffer2 is allocated by CudaAllocator in GPU; General buffer 2 can be considered as a unified package of large memory, on which there can be several tensors. These tensors first reserve memory and then allocate it uniformly.
- Offset of TensorBufferImpl_ It points to a specific memory offset in the ptr of GeneralBuffer2;
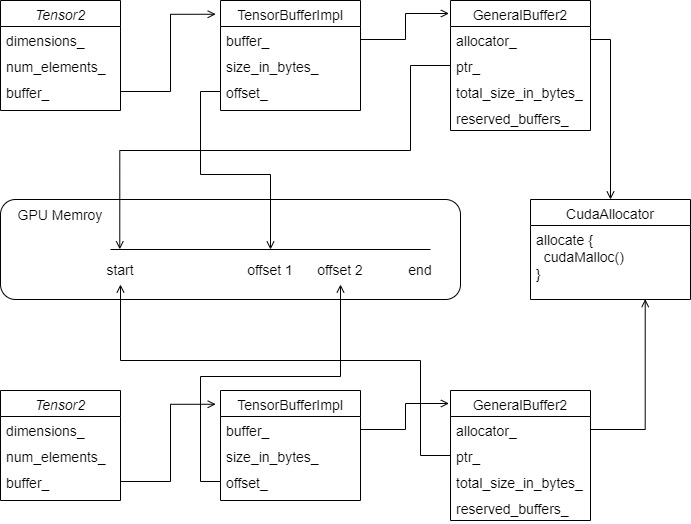
- BufferBlockImpl is used to implement a continuous Tensor memory.
If there is another Tensor2, its tensorbufferimpl Offset will point to another offset in GPU memory. For example, there are two tensors, Tensor 1 and Tensor 2.
0xFF reference
How does the embedding layer back propagate
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html
Sparse matrix storage format summary + storage efficiency comparison: COO,CSR,DIA,ELL,HYB