Inside Kafka, there is a__ consumer_ The topic of offsets. This topic mainly saves the offset of each consumption group to the consumption of the partition under the topic, that is, to which offset it is consumed. In order to realize the function of offset management of consumption group, when a consumer obtains a message, it is necessary for the consumer to submit offsets using the offset commit request API. We let brokers record offset messages to disk and use the replication characteristics of messages to achieve persistence and availability. Therefore, in fact, the offset submission processing on the broker side is the same logic as the processing of producer requests. Refactoring code on the broker side allows us to reuse existing code.
The OffsetManager module provides the management function of this offset, mainly including
- (1) Cache latest offset
- (2) provide query of offset
- (3) compact keeps the latest offset to control the log size of the Topic
offsetsCache provides the saving and query of Consumer offsets, and compact is executed regularly as a scheduled task.
1. Saving of Consumer offset
After receiving the message, the Consumer generates the offset of the current message to__ consumer_offsets: when the Broker Server receives messages, it will save them to the log. An offset submission message includes the following fields:
| fields | content |
|---|---|
| Key | Consumer Group, topic, partition |
| Payload | Offset, metadata, timestamp |
The key includes consumer group, topic and partition. Payload includes Offset. metadata,timestamp.
When the Broker Server receives a message, in addition to saving the message to the log, it also calls the putOffset method provided by OffsetManager to save the message to offsetsCache. The code is as follows:
def putOffsets(group: String, offsets: Map[TopicAndPartition, OffsetAndMetadata]) {
offsets.foreach { case (topicAndPartition, offsetAndMetadata) =>
putOffset(GroupTopicPartition(group, topicAndPartition), offsetAndMetadata)
}
}
private def putOffset(key: GroupTopicPartition, offsetAndMetadata: OffsetAndMetadata) {
offsetsCache.put(key, offsetAndMetadata)
}2. Reading of Consumer offset
When the Broker Server receives the request to query the offset, if it finds that the offset is saved in Kafka, it calls the getOffsets method in OffsetManager to take out the offset. The code is as follows:
def getOffsets(group: String, topicPartitions: Seq[TopicAndPartition]):
Map[TopicAndPartition, OffsetMetadataAndError] = {
//Calculate where the group is located__ consumer_ Which partition of offsets
val offsetsPartition = partitionFor(group)
followerTransitionLock synchronized {
//Only partition provides query services for the Broker Server where the leader is located
if (leaderIsLocal(offsetsPartition)) {
//If the data of the target partition is being loaded, its offset cannot be obtained. It will only occur in the Broker Server startup phase because the data needs to be loaded from the specified primary partition
if (loadingPartitions synchronized loadingPartitions.contains(offsetsPartition)){
topicPartitions.map { topicAndPartition =>
val groupTopicPartition = GroupTopicPartition(group, topicAndPartition)
(groupTopicPartition.topicPartition, OffsetMetadataAndError.OffsetsLoading)
}.toMap
} else {
if (topicPartitions.size == 0) {
// If the size of topicPartitions is 0, all offset messages of the group are obtained
offsetsCache.filter(_._1.group == group).map { case(groupTopicPartition, offsetAndMetadata) =>
(groupTopicPartition.topicPartition, OffsetMetadataAndError(offsetAndMetadata.offset, offsetAndMetadata.metadata, ErrorMapping.NoError))
}.toMap
} else {
//If the size of topicPartitions is not 0, the specified offset is returned
topicPartitions.map { topicAndPartition =>
val groupTopicPartition = GroupTopicPartition(group, topicAndPartition)
(groupTopicPartition.topicPartition, getOffset(groupTopicPartition))
}.toMap
}
}
} else {
//The partition is not a leader and does not provide external services
topicPartitions.map { topicAndPartition =>
val groupTopicPartition = GroupTopicPartition(group, topicAndPartition)
(groupTopicPartition.topicPartition, OffsetMetadataAndError.NotOffsetManagerForGroup)
}.toMap
}
}
}Note how Kafka saves the offset generated by the Consumer Group in__ consumer_ On different partitions of offsets? Its essence is to calculate the hash value and hash value of different consumer groups__ consumer_offsets is the modulus of the number of partitions, and the result is used as the index of the specified partition. Therefore, the modulo operation is started in the first step of getOffsets.
def partitionFor(group: String): Int =
Utils.abs(group.hashCode) % config.offsetsTopicNumPartitionsOffset information corresponding to different group s__ consumer_ The format stored in the Topic of offsets is as follows:
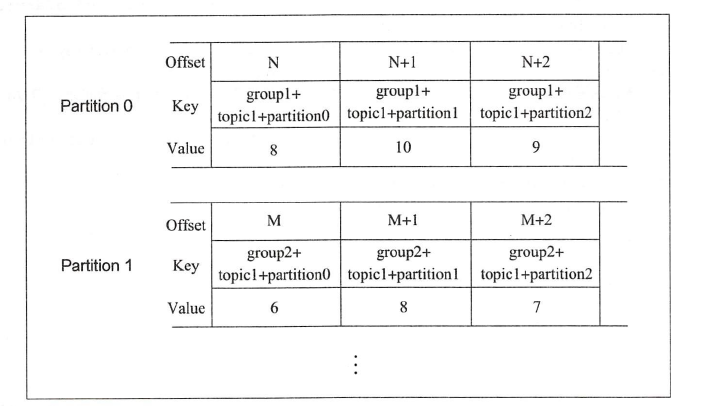
The key includes group+topic+partition, and the Value is the consumption offset of the consumption group
3. Compact policy
When the Consumer Group does not generate offset after running for a long time, it is likely that it does not need to be saved in__ consumer_ When the offset information in offsets, the Broker Server needs to have a mechanism to clean up the previously saved offset, which is the so-called Compact strategy. This policy will clear the offset corresponding to the Consumer Group that has not been updated for a long time, and keep the offset of the Consumer Group that is constantly updated. The specific implementation process is as follows:
private def compact() {
val startMs = SystemTime.milliseconds
//Determine the activity of each value by subtracting the current time from the last update time, and filter out those that have not been updated for a long time
val staleOffsets = offsetsCache.filter(startMs - _._2.timestamp > config.offsetsRetentionMs)
//Record the offset that has not been consumed for a long time, and then delete it from the cache
// delete the stale offsets from the table and generate tombstone messages to remove them from the log
val tombstonesForPartition = staleOffsets.map { case(groupTopicAndPartition, offsetAndMetadata) =>
//Filter out partition indexes
val offsetsPartition = partitionFor(groupTopicAndPartition.group)
//Delete from memory
offsetsCache.remove(groupTopicAndPartition)
//Then the tombstone record is generated, that is, the bytes are null. Only the key is passed in to generate an empty record. Finally, it is grouped by partition
val commitKey = OffsetManager.offsetCommitKey(groupTopicAndPartition.group,
groupTopicAndPartition.topicPartition.topic, groupTopicAndPartition.topicPartition.partition)
(offsetsPartition, new Message(bytes = null, key = commitKey))
}.groupBy{ case (partition, tombstone) => partition }
//Write the tombstone record into the log file. If the log merge thread is started, the latest record, that is, the record with null Value, will be retained
val numRemoved = tombstonesForPartition.flatMap { case(offsetsPartition, tombstones) =>
val partitionOpt = replicaManager.getPartition(OffsetManager.OffsetsTopicName, offsetsPartition)
partitionOpt.map { partition =>
val appendPartition = TopicAndPartition(OffsetManager.OffsetsTopicName, offsetsPartition)
val messages = tombstones.map(_._2).toSeq
try {
partition.appendMessagesToLeader(new ByteBufferMessageSet(config.offsetsTopicCompressionCodec, messages:_*))
tombstones.size
}
catch {
......
}
}
}.sum
}When the log merge thread is turned on, only null records will be retained in the end
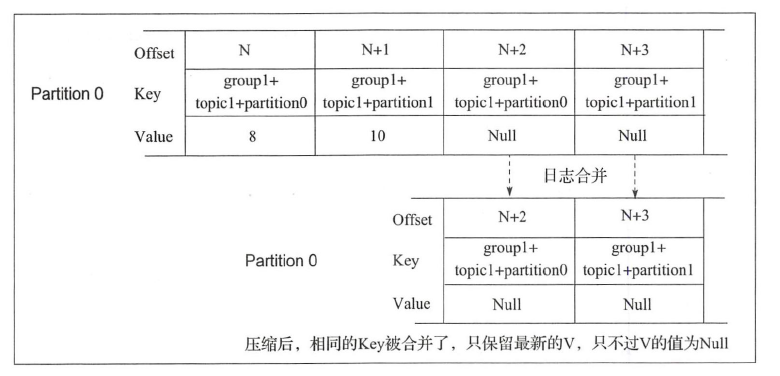
4. Summary
In short, the Kafka cluster provides the function of recording and querying offset offset through the OffsetManager module. At the same time, it regularly cleans up the offset that has not been updated for a long time through the compact function, controls the size of the Topic, and provides support for the continuous consumption of messages by the Consumer Group.