Gongzong No.: black palm
A blogger who focuses on sharing network security, hot spots in the hacker circle and hacker tool technology area!
Webfinger
brief introduction
This is a very small tool, written by Python 2, using Fofa's fingerprint library
Github address: https://github.com/se55i0n/Webfinger
Please refer to the official screenshot:
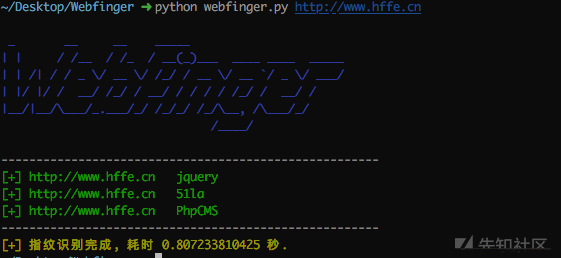
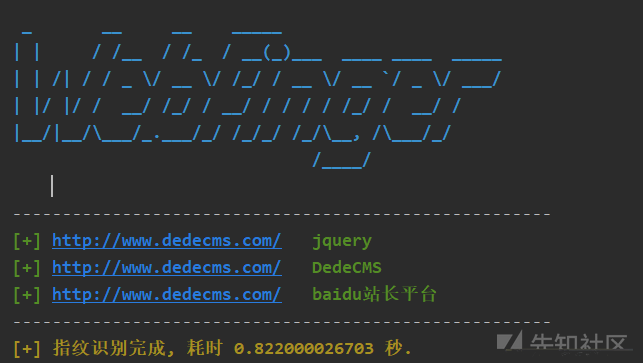
The use experience of this tool is very unfriendly. It uses outdated Python 2, and there are errors in the code connecting to the database. I have to help him change the BUG. After dealing with a series of problems, I ran successfully. I tested it on the dedecms official website, and the effect is good:
Source code analysis
The code is relatively simple. Before matching, connect to the database to query the total number and each information, and use a simple SQL statement:
def check(_id):
with sqlite3.connect('./lib/web.db') as conn:
cursor = conn.cursor()
result = cursor.execute('SELECT name, keys FROM `fofa` WHERE id=\'{}\''.format(_id))
for row in result:
return row[0], row[1]
def count():
with sqlite3.connect('./lib/web.db') as conn:
cursor = conn.cursor()
result = cursor.execute('SELECT COUNT(id) FROM `fofa`')
for row in result:
return row[0]
To view the Fofa library using Navicat:
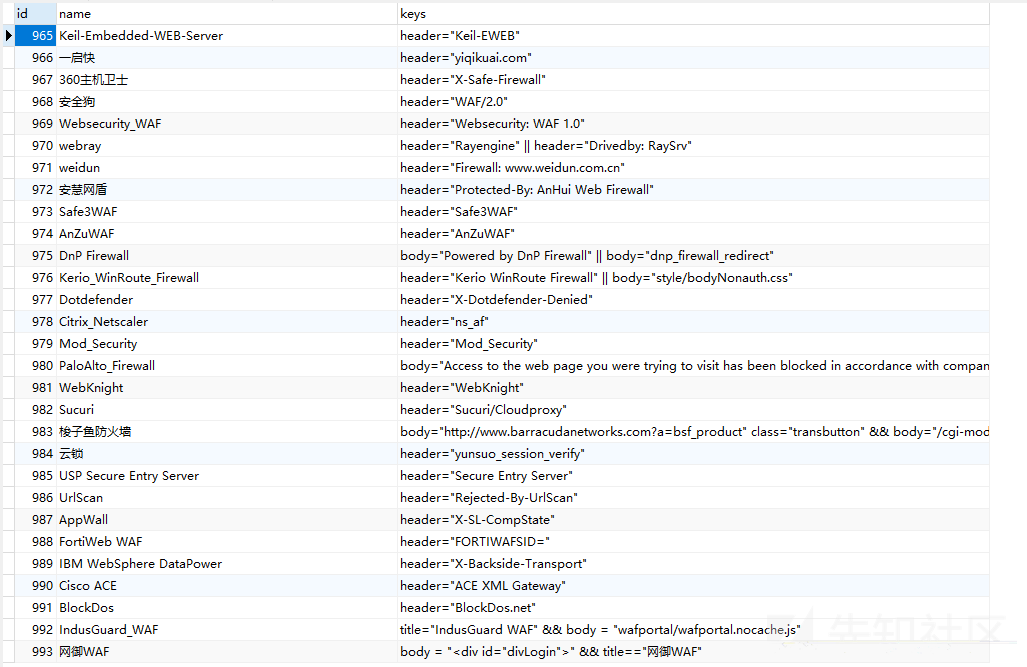
A thousand rules, quite complete. If you want to make fingerprint identification tools, you may be able to borrow this Fofa Library
After obtaining the information of Fofa fingerprint database, parse the syntax:
if '||' in key and '&&' not in key and '(' not in key:
for rule in key.split('||'):
if self.check_rule(rule, header, body, title):
print '%s[+] %s %s%s' %(G, self.target, name, W)
break
Verify the rules after parsing the syntax:
def check_rule(self, key, header, body, title):
try:
if 'title="' in key:
if re.findall(rtitle, key)[0].lower() in title.lower():
return True
elif 'body="' in key:
if re.findall(rbody, key)[0] in body: return True
else:
if re.findall(rheader, key)[0] in header: return True
except Exception as e:
pass
The rules are as follows:
rtitle = re.compile(r'title="(.*)"') rheader = re.compile(r'header="(.*)"') rbody = re.compile(r'body="(.*)"') rbracket = re.compile(r'\((.*)\)')
The body and header are also relatively simple: use the requests request to obtain the response header and body, and use bs4 to parse the body to obtain the title information
r = requests.get(url=self.target, headers=agent,
timeout=3, verify=False)
content = r.text
try:
title = BeautifulSoup(content, 'lxml').title.text.strip()
return str(r.headers), content, title.strip('\n')
except:
return str(r.headers), content, ''
This is the overall situation. What is worth seeing is the semantic analysis, such as the analysis of paragraph 1 | 2 | (3 & &4) below:
And operations take priority. Divide them to get 3 and 4. Use num count to ensure that each item in the and operations passes the check, and then check the or operations in turn. Finally, Fofa's rules are successfully parsed
if '&&' in re.findall(rbracket, key)[0]:
for rule in key.split('||'):
if '&&' in rule:
num = 0
for _rule in rule.split('&&'):
if self.check_rule(_rule, header, body, title):
num += 1
if num == len(rule.split('&&')):
print '%s[+] %s %s%s' % (G, self.target, name, W)
break
else:
if self.check_rule(rule, header, body, title):
print '%s[+] %s %s%s' % (G, self.target, name, W)
break
summary
- A small tool with few codes and practical functions
- sqlite database makes it difficult to customize rules, which is not conducive to expansion
- Perhaps we can use multithreading and multi process technology to improve efficiency
- Fofa fingerprint library may be able to borrow to complete its own tools
Cmscan
introduce
Similar to Webfinger, this is also a small tool
https://github.com/ldbfpiaoran/cmscan
Source code analysis
From the perspective of development, the code of this tool is not very standard. Let's simply analyze it:
The first is the analysis of title, using bs4: title = bresponse findAll('title')
A large dictionary is defined as the rule database:
title = {'phpMyAdmin':'phpMyAdmin',
'seacms':'ocean CMS',
'Powered by ASPCMS':'ASPCMS',
'Powered by CmsEasy':'CmsEasy',
.....
}
Then use regular to search directly. There is a little doubt that the above title rule is not a regular format, but a simple string. Why not use if key lower() in title. The simpler method, lower (), is not as efficient as this method in theory
def scan_title():
titlerule = rule.title
web_information = 0
for key in titlerule.keys():
req = re.search(key,title,re.I)
if req:
web_information = titlerule[key]
break
else:
continue
return web_information
Similarly, the same is true for analyzing response headers. The simple addition of & symbol parsing is not as good as that written by websinger; The content of the analysis body is similar to this, so we don't copy it anymore
def scan_head():
headrule = rule.head
web_information = 0
for key in headrule.keys():
if '&' in key:
keys = re.split('&',key)
if re.search(keys[0],header,re.I) and re.search(keys[1],response,re.I) :
web_information = headrule[key]
break
else:
continue
else:
req = re.search(key,header,re.I)
if req:
web_information = headrule[key]
break
else:
continue
return web_information
For the acquisition of file headers, it is only simple requests:
response = requests.get(url=url, headers=headers)
bresponse = BeautifulSoup(response.text, "lxml")
title = bresponse.findAll('title')
for i in title:
title = i.get_text()
head = response.headers
response = response.text
header = ''
for key in head.keys():
header = header+key+':'+head[key]
It is found that it also provides a script for downloading rules. The general content is to crawl the Fofa library and parse it with bs4 to get the rules:
response = requests.get(url=url,headers=headers)
response = BeautifulSoup(response.text,"lxml")
rules = response.findAll('div',{'class':'panel panel-default'})
rule = {}
for i in rules:
rule_len = len(i.findAll('a'))
if rule_len > 0 :
rulelist = i.findAll('a')
temporary = {}
for b in rulelist:
s = un_base(b.attrs['href'])
temporary[b.get_text()] = s
rule[i.find('label').get_text()] = temporary
Then save it to mysql for subsequent use:
def saverule(types,name,rules):
try:
conn = pymysql.connect(host='127.0.0.1',user='root',passwd='521why1314',db='mysql',charset='utf8')
conn = conn.cursor()
conn.execute('use rules')
savesql = 'insert into `fofarule` (`types`,`name`,`rules`) VALUES (%s,%s,%s)'
conn.execute(savesql,(types,name,rules))
except:
conn.close()
summary
A very simple gadget. The code quality is not high. It can be seen that it is a novice's work. The principle is similar to that of the previous webfinder, which matches the keywords in the header, title and body. Here it is written in the code, and the webfinder is written into the sqlite database
Gwhatweb
introduce
Simple CMS identification tool, relatively standardized code, and the use of CO process technology greatly improve the efficiency of programs with more IO operations
https://github.com/boy-hack/gwhatweb
Source code analysis
Let's first look at the rules, mainly the fingerprint identification of url and md5, excluding the response header
{
"url": "/images/admin/login/logo.png",
"re": "",
"name": "Phpwind Website program",
"md5": "b11431ef241042379fee57a1a00f8643"
},
Use thread safe Queue to read rules into the Queue
def __init__(self,url):
self.tasks = Queue()
self.url = url.rstrip("/")
fp = open('data.json')
webdata = json.load(fp, encoding="utf-8")
for i in webdata:
self.tasks.put(i)
fp.close()
print("webdata total:%d"%len(webdata))
Record the execution time and start the collaboration
def _boss(self):
while not self.tasks.empty():
self._worker()
def whatweb(self,maxsize=100):
start = time.clock()
allr = [gevent.spawn(self._boss) for i in range(maxsize)]
gevent.joinall(allr)
end = time.clock()
print ("cost: %f s" % (end - start))
The following are the key functions of rule matching: first, get the rules from the queue, send requests, and then get the response body. First, use regular matching, and then use MD5 matching (is it reasonable to directly match the MD5 of the body? The probability of the body is different. Even a small change will lead to a huge change in the MD5 value, so is this wrong logic?)
def _worker(self):
data = self.tasks.get()
test_url = self.url + data["url"]
rtext = ''
try:
r = requests.get(test_url,timeout=10)
if (r.status_code != 200):
return
rtext = r.text
if rtext is None:
return
except:
rtext = ''
if data["re"]:
if (rtext.find(data["re"]) != -1):
result = data["name"]
print("CMS:%s Judge:%s re:%s" % (result, test_url, data["re"]))
self._clearQueue()
return True
else:
md5 = self._GetMd5(rtext)
if (md5 == data["md5"]):
result = data["name"]
print("CMS:%s Judge:%s md5:%s" % (result, test_url, data["md5"]))
self._clearQueue()
return True
summary
Using CO process is a technological progress, but is there a problem with the matching method of rules?
FingerPrint
introduce
Written in Perl language, using the Wappalyzer tool library. The code is very standard and the comments are complete. It seems that the author's github information seems to be Baidu's little sister. There are really few safe sisters, not to mention the big brother of BAT. Stop talking nonsense and keep looking at the code
https://github.com/tanjiti/FingerPrint
Source code analysis
For the functions introduced at the beginning, you need to install cpan -i WWW::Wappalyzer yourself
use WWW::Wappalyzer qw(detect get_categories add_clues_file);
The core code is very short. Send a request, pass the response content into the interface provided by wapalyzer, and then output the result
sub getFP{
my ($url,$rule_file) = @_;
my $response = sendHTTP($url);
#add your new finger print rule json file
add_clues_file($rulefile) if $rulefile and -e $rulefile;
my %detected = detect(
html => $response->decoded_content,
headers => $response->headers,
url => $uri,
# cats => ["cms"],
);
my $result = jsonOutput($url,\%detected);
return $result;
}
Official documents:
https://metacpan.org/pod/WWW::Wappalyzer
Official Code:
https://metacpan.org/release/WWW-Wappalyzer/source/lib/WWW/Wappalyzer.pm
After a brief look, it is a bit like the wapalyzer code logic in JavaScript format, which is equivalent to being implemented in Perl
summary
Simple and compact tools. I don't know why Perl is used. Python/Golang is a better choice
Yujian WEB fingerprint identification system
brief introduction
Domestic tools are not open source. It seems that they should be written in C++/C# and use multithreading technology to detect and identify in an active way similar to directory scanning. They are friendly to novices

Source code analysis
This tool is not open source. Let's take a brief look at its rule library. It only matches the keywords and rules of the response Body. The number of libraries is not very large. It is a regular gadget
#Example: link ----- keyword ----- CMS nickname #Example: connection ----- regular expression ----- matching keyword ----- CMS nickname /install/------aspcms------AspCMS /about/_notes/dwsync.xml------aspcms------AspCMS /admin/_Style/_notes/dwsync.xml------aspcms------AspCMS /apply/_notes/dwsync.xml------aspcms------AspCMS /config/_notes/dwsync.xml------aspcms------AspCMS /fckeditor/fckconfig.js------aspcms------AspCMS /gbook/_notes/dwsync.xml------aspcms------AspCMS /inc/_notes/dwsync.xml------aspcms------AspCMS /plug/comment.html------aspcms------AspCMS
summary
Yujian has been a famous web directory scanning tool, and the fingerprint identification is also good, which is suitable for novices
Test404 lightweight CMS fingerprint identification
brief introduction
Similar to Yujian, the interface is C + + style, but its rules are more perfect

Source code analysis
There is no open source. Let's take a look at the rule base:
The first is the key url, which is inferred according to the status code
The second is the content of the title, which should be judged according to the inclusion relationship
The third is MD5. I guess it is MD5 of ICO file
/include/fckeditor/fckstyles.xml|phpmaps|6d188bfb42115c62b22aa6e41dbe6df3 /plus/bookfeedback.php|dedecms|647472e901d31ff39f720dee8ba60db9 /js/ext/resources/css/ext-all.css|Pan micro OA|ccb7b72900a36c6ebe41f7708edb44ce
summary
Similar to the imperial sword, it is suitable for novices, and the rules are more perfect
Source: https://xz.aliyun.com/t/9498
Author: 4ra1n

That's all for today's sharing. My favorite friends remember to click three times. I have a public Zong number [black palm], which can get more hacker secrets for free. Welcome to play!